Yolov5: Distributed training in cluster not correct.
The model can be trained correctly on single machine multi gpus.
However, It can't be trained on multi machines multi gpus.
 XinyuDu
XinyuDu
All 13 comments
Hello @XinyuDu, thank you for your interest in our work! Please visit our Custom Training Tutorial to get started, and see our Jupyter Notebook ![]() , Docker Image, and Google Cloud Quickstart Guide for example environments.
, Docker Image, and Google Cloud Quickstart Guide for example environments.
If this is a bug report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you.
If this is a custom model or data training question, please note that Ultralytics does not provide free personal support. As a leader in vision ML and AI, we do offer professional consulting, from simple expert advice up to delivery of fully customized, end-to-end production solutions for our clients, such as:
- Cloud-based AI systems operating on hundreds of HD video streams in realtime.
- Edge AI integrated into custom iOS and Android apps for realtime 30 FPS video inference.
- Custom data training, hyperparameter evolution, and model exportation to any destination.
For more information please visit https://www.ultralytics.com.
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 19 Jun 2020
github-actions[bot]
on 19 Jun 2020
@XinyuDu I can not train my custom data with multi-gpu. What the environment (pytorch, torchvision, cuda, cudnn version) you used? How much of gpu you training?
 xjohnxjohn
on 19 Jun 2020
xjohnxjohn
on 19 Jun 2020
@XinyuDu if you could submit a PR for the corrections you had in mind, that would be great!
At the moment and for the foreseeable future multi-machine training is not something we will be able to debug ourselves.
 glenn-jocher
on 19 Jun 2020
glenn-jocher
on 19 Jun 2020
@XinyuDu @xjohnxjohn @glenn-jocher I have solved this problem, this is a bug of PyTorch.I have fixed it for this and he is running as expected. If you manually build the existing version of PyTorch, this will not go wrong. This may have many bugs that have not been tested in detail. I suggest you execute the following command
run
pip install torch==1.4.0+cu100 torchvision==0.5.0+cu100 -f https://download.pytorch.org/whl/torch_stable.html
More details see: https://github.com/pytorch/pytorch/pull/36503
 Lornatang
on 20 Jun 2020
Lornatang
on 20 Jun 2020
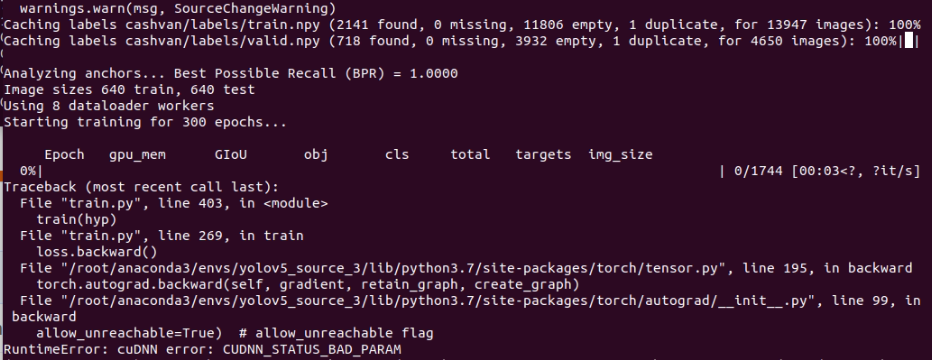
@Lornatang It show error "RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM". (I use cuda v.10.0)
xjohnxjohn
on 20 Jun 2020
@xjohnxjohn What command do you use, will he get this kind of error?
Lornatang
on 20 Jun 2020
@xjohnxjohn What command do you use, will he get this kind of error?
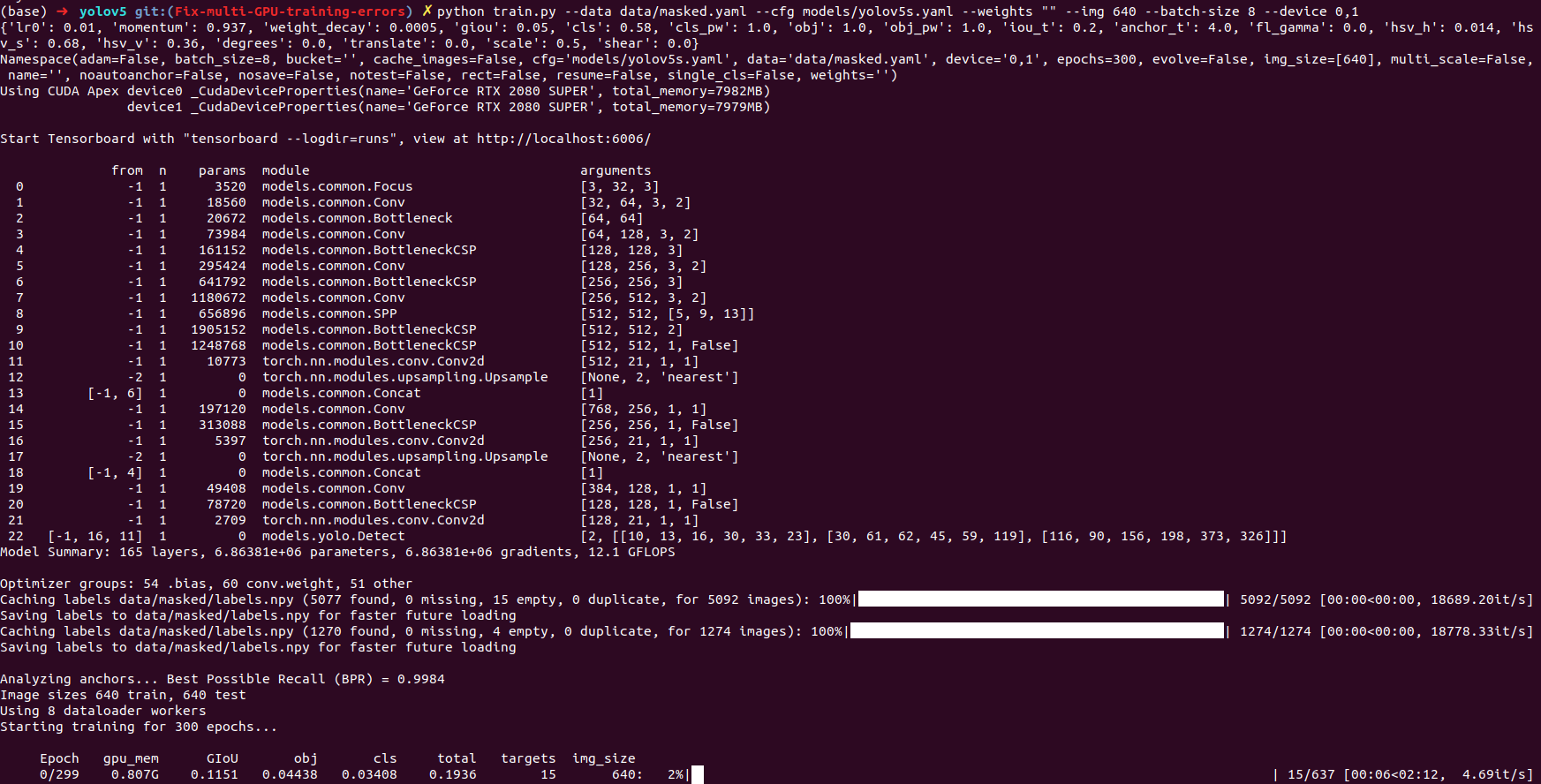
python train.py --data data/xx.yaml --cfg models/xx_yolov5s.yaml --weights weights/last.pt --img 640 --batch-size 8 --device 0,1
xjohnxjohn
on 20 Jun 2020
xjohnxjohn
on 20 Jun 2020
Please print your conda list
Lornatang
on 20 Jun 2020
Please print yourconda list
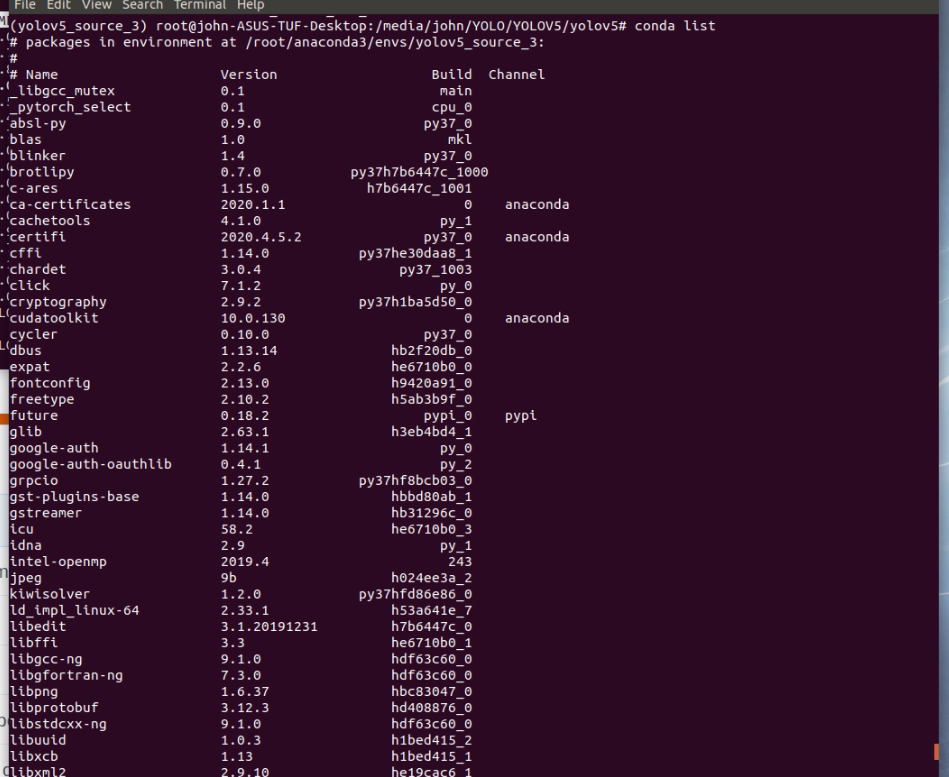
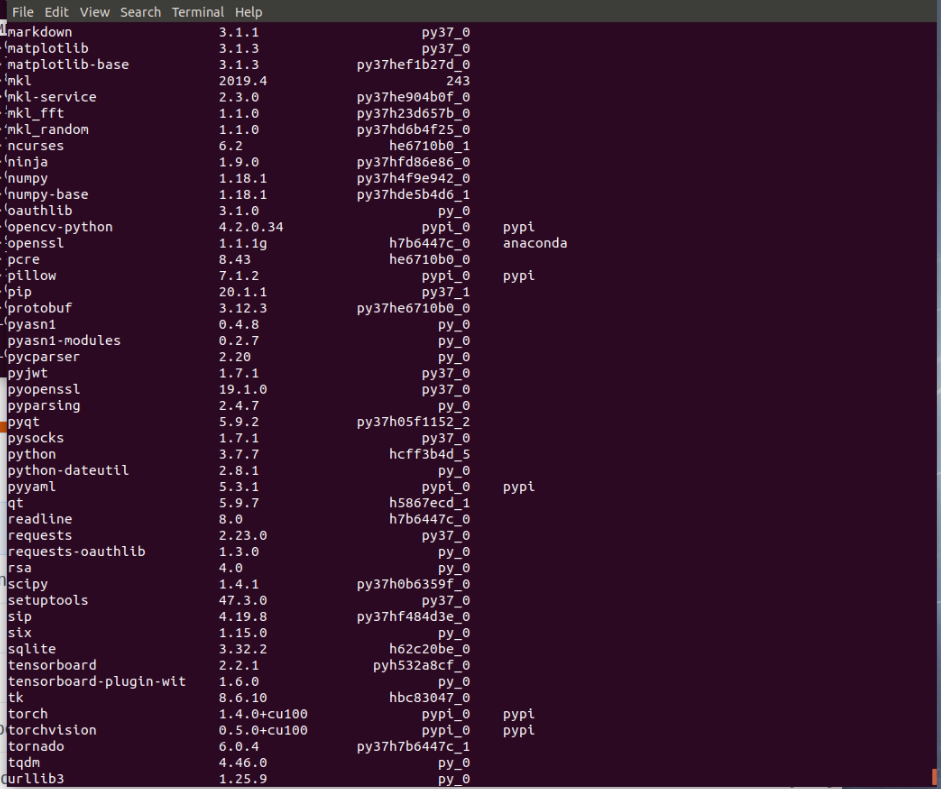
I used different model of gpu, 1 is RTX-2080(8GB) and the other GTX-1080Ti(11 GB)
xjohnxjohn
on 20 Jun 2020
I have the notice in the line that I masked.
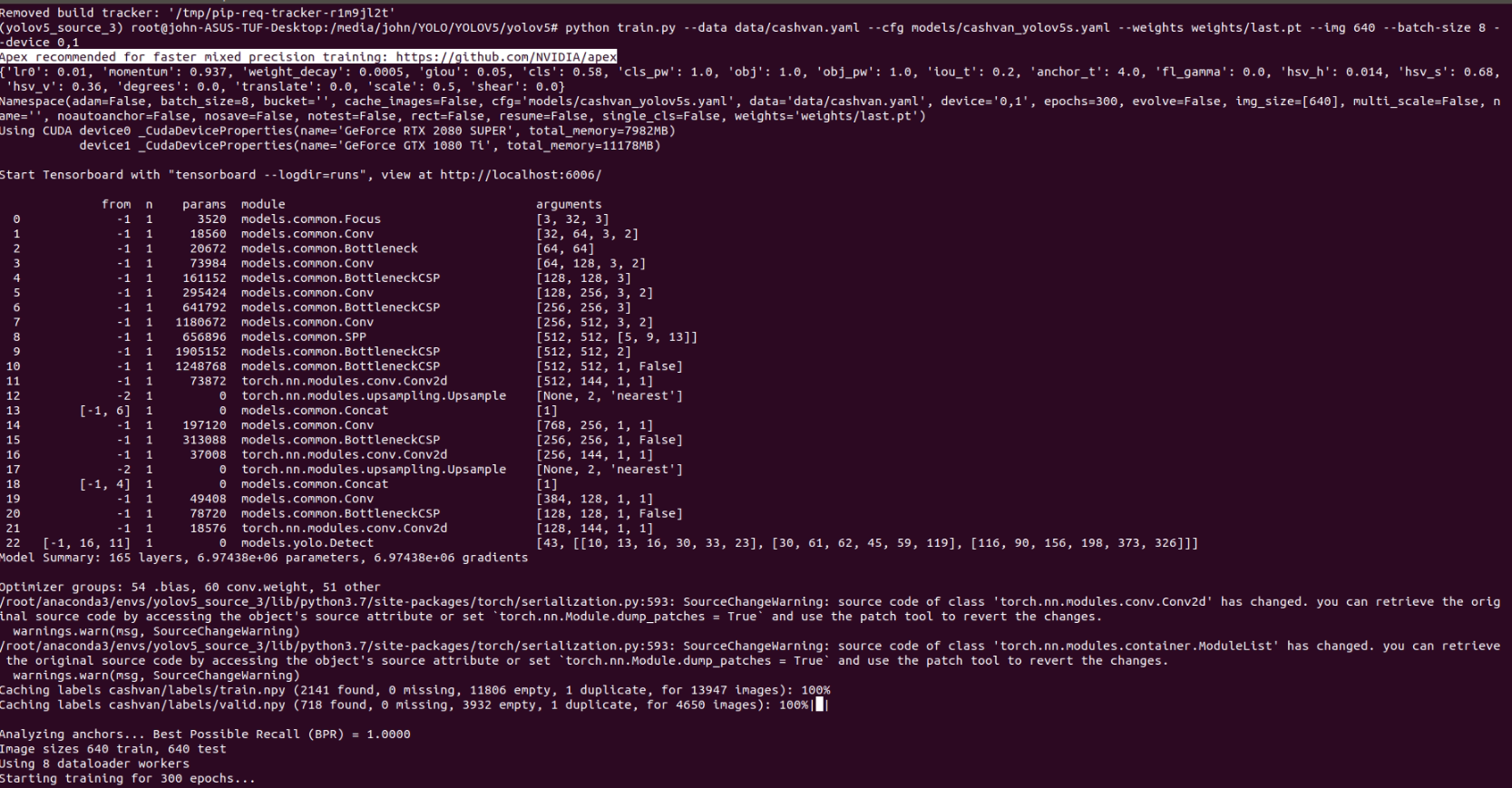
xjohnxjohn
on 20 Jun 2020
Every time you modify the PyTorch version, you need to recompile Apex...
run
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
@XinyuDu if you could submit a PR for the corrections you had in mind, that would be great!
At the moment and for the foreseeable future multi-machine training is not something we will be able to debug ourselves.
Thank you for your replay.
In multi machines multi gpus scenario, the DistributedSampler should be used for distributing the data. However, I didn't find it in train.py.
XinyuDu
on 23 Jun 2020
Related issues
 e-shawakri
·
34Comments
e-shawakri
·
34Comments
 yxxxqqq
·
29Comments
yxxxqqq
·
29Comments
 ChristopherSTAN
·
33Comments
ChristopherSTAN
·
33Comments
 DENESTY
·
41Comments
glenn-jocher
·
48Comments
DENESTY
·
41Comments
glenn-jocher
·
48Comments
Most helpful comment
Every time you modify the PyTorch version, you need to recompile Apex...
run