Yolov3: Interesting Behaviour of Training [NOT a bug/issue]
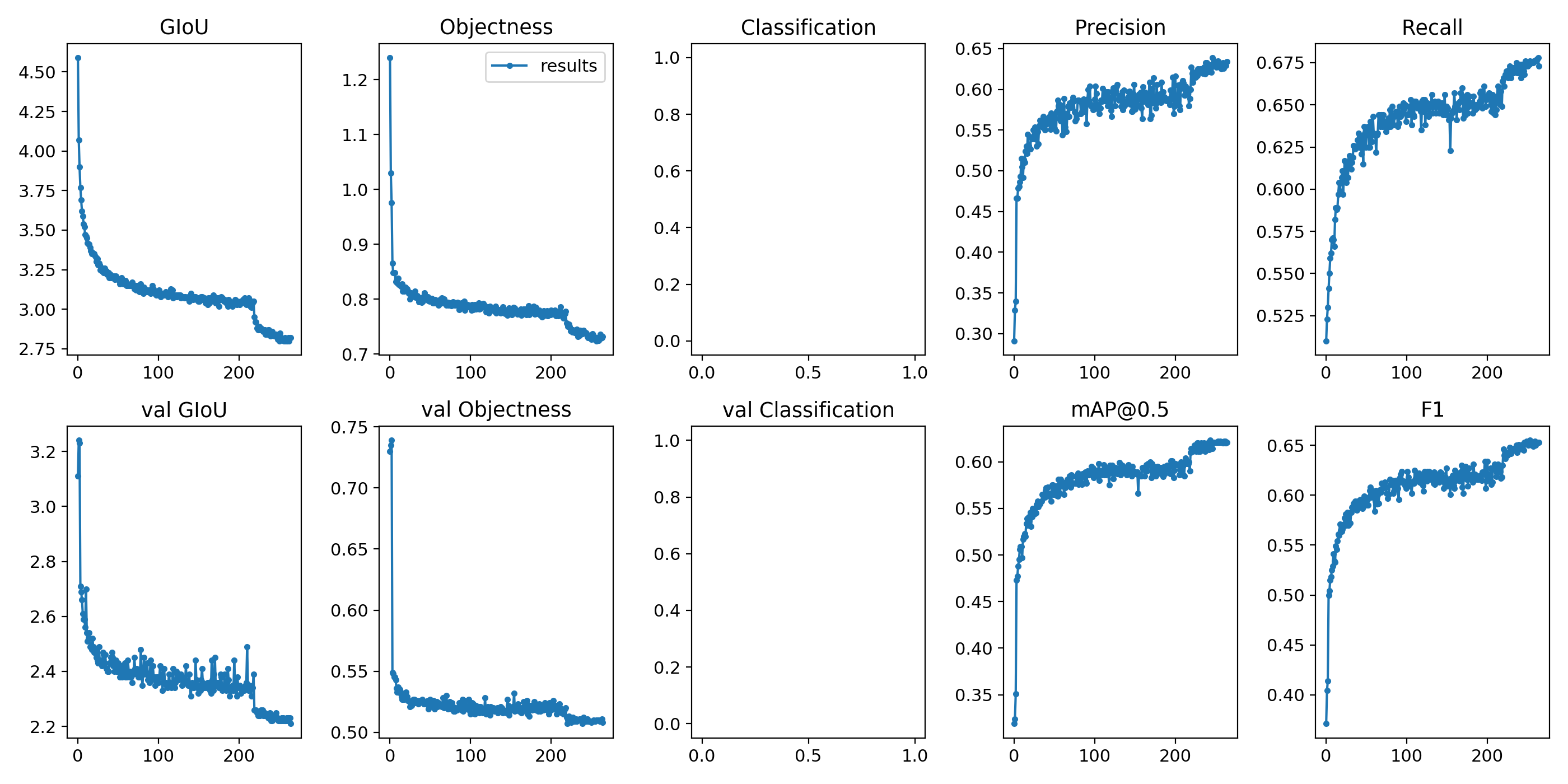
I just wondered why would that jump happen right after ~200. Epoch.
 orcund
orcund
All 7 comments
@orcund there is an LR scheduler that mulitplies the LR by a gain of 0.1 at 80% and 90% of total epochs:
https://github.com/ultralytics/yolov3/blob/11bcd0f9885ce548c7c123c611921fe63bebe592/train.py#L144
 glenn-jocher
on 13 Feb 2020
glenn-jocher
on 13 Feb 2020
Thanks !!
orcund
on 13 Feb 2020
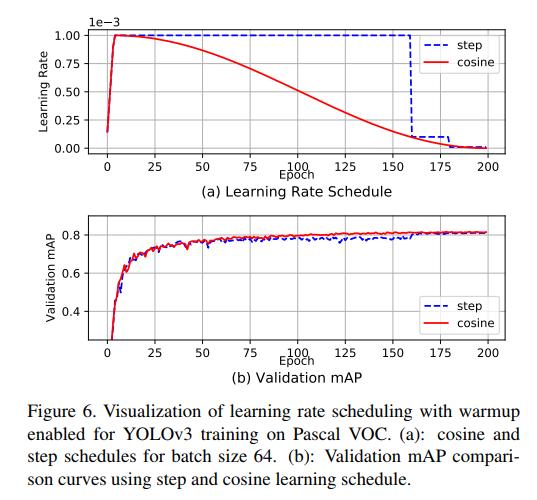
This reminds me of an alternative training schedule. Instead of reducing the steps suddenly at the end, you can achieve the sudden gain in mAP gradually but earlier using the cosine schedule.
It also improves mAP slightly!
 gnefihs
on 18 Feb 2020
gnefihs
on 18 Feb 2020
@gnefihs yes this would be a good addition to the repo. We currently use the step scheduler (blue line). If you have time you could submit a PR. The relevant section of the code is here:
https://github.com/ultralytics/yolov3/blob/ddd892dc205c36c029ac9272e92be56fe654415b/train.py#L138-L146
glenn-jocher
on 19 Feb 2020
This is something I am looking at right now @gnefihs
Would love to see your ideas.
 FranciscoReveriano
on 20 Feb 2020
FranciscoReveriano
on 20 Feb 2020
@glenn-jocher i saw that you commented out the burn-in section of your code. did you intentionally leave it out because it doesn't seem to help much?
edit: sorry just saw your comment here. https://github.com/ultralytics/yolov3/issues/238#issuecomment-556840559
How does GIoU remove the need for burn-in?
gnefihs
on 23 Feb 2020
@gnefihs the burn-in seemed to help training stability when we used seperate MSE losses for the xywh terms of the boxes, as the wh losses were unbounded, but the switch to GIoU for the box regression loss had a side effect of removing the regression instability, so yes as you said it didn't seem to help much any longer.
glenn-jocher
on 23 Feb 2020
Related issues
 mehrdadazizi72
·
3Comments
mehrdadazizi72
·
3Comments
 Aria20155
·
3Comments
Aria20155
·
3Comments
 acburigo
·
4Comments
acburigo
·
4Comments
 Alex1101a
·
5Comments
Alex1101a
·
5Comments
 MichaelCong
·
4Comments
MichaelCong
·
4Comments
Most helpful comment
@orcund there is an LR scheduler that mulitplies the LR by a gain of 0.1 at 80% and 90% of total epochs:
https://github.com/ultralytics/yolov3/blob/11bcd0f9885ce548c7c123c611921fe63bebe592/train.py#L144