The original darknet learning rate (LR) scheduler parameters are set in a model's *.cfg file:
learning_rate: initial LRburn_in: number of batches to ramp LR from 0 tolearning_ratein epoch 0max_batches: the number of batches to train the model topolicy: type of LR schedulersteps: batch numbers at which LR is reducedscales: LR multiple applied atsteps(gammain PyTorch)

In this repo LR scheduling is set in train.py. We set the initial and final LRs as hyperparameters hyp['lr0'] and hyp['lrf'], where the final LR = lr0 * (10 ** lrf) . For example, if the initial LR is 0.001 and the final LR is 100 times (1e-2) smaller, hyp['lrf']=0.001 and hyp['lrf']=-2. This plot shows two of the available PyTorch LR schedulers, with the MultiStepLR scheduler following the original darknet implementation (at batch_size=64 on COCO). To learn more please visit:
https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate

The LR hyperparameters are tunable, along with all the rest of the model hyperparmeters in train.py:
https://github.com/ultralytics/yolov3/blob/1771ffb1cf293ef176ac6ef2ddb7af7ca672c0e7/train.py#L13-L25
Actual LR scheduling is set further down in train.py, and has been tuned for COCO training. You may want to set your own scheduler according to your specific custom dataset and training requirements, and also adjust it's hyperparameters accordingly.
https://github.com/ultralytics/yolov3/blob/bd2378fad1578e7d7722ad846458ad7a2bb43442/train.py#L102-L109
 glenn-jocher
glenn-jocher
All 55 comments
Hello glenn-jocher
Sorry to interrupt you .
But I am confusing about the following learning rate decay function .
lf = lambda x: 1 - 10 ** (hyp['lrf'] * (1 - x / epochs))
How did you get this function ?
Thank you for reply
 announce1
on 4 May 2019
announce1
on 4 May 2019
@announce1 this equation corresponds to the orange and green curves above. It's an inverse exponential that decays the LR to zero by the value epochs. This type of curve is tunable with a single hyperparameter, hyp['lrf']. We selected it due to this simple tunability, it's continuous nature, and from good performance comparisons vs other functions, such as linear, exponential, and steps.
glenn-jocher
on 4 May 2019
Hi glenn-jocher
Thank you for your reply .
I had got your mind in tuning this function and these hpyer . Thank you very much .
What also confuse me is where did you get this function ?
From other people's paper or other loss-calculate model ?
Thanks a lot .
announce1
on 5 May 2019
@announce1 the function is a simple exponential, its very common in statistics.
glenn-jocher
on 5 May 2019
Hi glenn-jocher,
I'm trying to train it on my custom dataset containing roughly 160K images and around 50 classes with batch size = 48.
I was using the default values of hyper-parameter as mentioned in the train.py file.
which are
hyp = {'xy': 0.2, # xy loss gain
'wh': 0.1, # wh loss gain
'cls': 0.04, # cls loss gain
'conf': 4.5, # conf loss gain
'iou_t': 0.5, # iou target-anchor training threshold
'lr0': 0.001, # initial learning rate
'lrf': -4., # final learning rate = lr0 * (10 ** lrf)
'momentum': 0.90, # SGD momentum
'weight_decay': 0.0005}.
During the first epoch itself, I got 'WARNING: nan loss detected, ending training' message.
I've trained yolov2 on similar dataset with learning_rate = 0.00001 and it converged quite well with out using any momentum etc.
So, If I use 'lr0': 0.00001, # initial learning rate with your code, then what are the other hyper parameter values you suggest, like the values for momentum, lrf and weight_decay etc.
Thanks
 abhinav3
on 6 Jun 2019
abhinav3
on 6 Jun 2019
@abhinav3 your wh loss is likely diverging. See https://github.com/ultralytics/yolov3/issues/307
You should probably lower your hyp['wh'] gain, or increase your burnin period.
glenn-jocher
on 6 Jun 2019
LR burnin (burn-in) during first 1000 batches:
https://github.com/ultralytics/yolov3/blob/1a9aa30efcf7cf17b79736542a8c3f77c03d4854/train.py#L221-L226

glenn-jocher
on 21 Jun 2019
@glenn-jocher
I have a question about the epochs, when I set different epochs, the Ir of the previous epochs processes is the same, why are AP's so different for the same IR (I have only one class)
 H-YunHui
on 29 Aug 2019
H-YunHui
on 29 Aug 2019
@www12345678 Hello, thank you for your interest in our work! Please note that most technical problems are due to:
- Your changes to the default repository. If your issue is not reproducible in a fresh
git cloneversion of this repository we can not debug it. Before going further run this code and ensure your issue persists:
sudo rm -rf yolov3 # remove exising repo
git clone https://github.com/ultralytics/yolov3 && cd yolov3 # git clone latest
python3 detect.py # verify detection
python3 train.py # verify training (a few batches only)
# CODE TO REPRODUCE YOUR ISSUE HERE
- Your custom data. If your issue is not reproducible with COCO data we can not debug it. Visit our Custom Training Tutorial for exact details on how to format your custom data. Examine
train_batch0.jpgandtest_batch0.jpgfor a sanity check of training and testing data. - Your environment. If your issue is not reproducible in a GCP Quickstart Guide VM we can not debug it. Ensure you meet the requirements specified in the README: Unix, MacOS, or Windows with Python >= 3.7, Pytorch >= 1.1, etc. You can also use our Google Colab Notebook to test your code in working environment.
If none of these apply to you, we suggest you close this issue and raise a new one using the Bug Report template, providing screenshots and minimum viable code to reproduce your issue. Thank you!
glenn-jocher
on 29 Aug 2019
https://github.com/ultralytics/yolov3/blob/74b57500c717f1d43e34c7cd9eb41a5846d86a73/train.py#L254-L263
Why "burn in" is disabled now?
 mozpp
on 21 Nov 2019
mozpp
on 21 Nov 2019
@mozpp burn-in is unneeded anymore. GIoU stabilizes the unbounded wh loss.
glenn-jocher
on 21 Nov 2019
@mozpp burn-in is unneeded anymore. GIoU stabilizes the unbounded wh loss.
Could you explain how does "prebias" work? I think it is similar to "burn in".
mozpp
on 21 Nov 2019
@mozpp no, prebias attempts to aggressively optimize neuron biases on Conv2d() layes preceding each YOLO layer. There are only 765 of these in yolov3-spp, the rest of the network is frozen and unaffected. There is no relation with burnin. Burnin is reduced LR in initial batches.
glenn-jocher
on 21 Nov 2019
@glenn-jocher Sorry I'm still confused about what prebias does.
I check the full model_info under prebias mode, it seems all parameters are set to gradient = True. Does it copy the weights from pre-trained model and fine tune on all parameters?
 yujianll
on 5 Dec 2019
yujianll
on 5 Dec 2019
@yujianll see https://github.com/ultralytics/yolov3/issues/460
glenn-jocher
on 5 Dec 2019
@glenn-jocher Thanks!
Do you have any suggestion about avoiding GPU memory issue?
I'm using yolov3-spp model with 13 classes, batch size 32, prebias, and no transfer learning. I encountered CUDA out of memory in training step.
It seems simply reducing batch size fix it.
yujianll
on 5 Dec 2019
@yujianll reduce --batch-size
glenn-jocher
on 6 Dec 2019
@yujianll
use group normalization instead of batch normalization, you can train the model with small batch size
 developer0hye
on 10 Dec 2019
developer0hye
on 10 Dec 2019
@developer0hye Thanks! Is there an argument that I can set to use group normalization?
yujianll
on 10 Dec 2019
@yujianll
There is no argument for it... That's a shame... We need to implement it! But, it is easy to implement.
@glenn-jocher
Do you have the plan for using group normalization??
developer0hye
on 10 Dec 2019
This would be a great addition!
 FranciscoReveriano
on 10 Dec 2019
FranciscoReveriano
on 10 Dec 2019
@FranciscoReveriano
Yeah, I think so!
developer0hye
on 10 Dec 2019
@developer0hye @FranciscoReveriano my understanding of groupnorm is that yes it can approach the results of batchnorm with smaller batch sizes, but not exceed them. I don't have any plans for it at the moment, but if you implement and compare results on coco_64img.data it might be a worthwhile PR.
glenn-jocher
on 10 Dec 2019
Have you considered trying some of the different learning rates? I am looking at trying Cosine Annealing. Or trying to apply reduce ReduceLROnPlateaue?
FranciscoReveriano
on 22 Feb 2020
@FranciscoReveriano yes I've tried cosine annealing and different LRs, without much success. Note though that when using SGD LR and momentum both affect the optimizer updates, so you really have a 2D search space I believe there.
I think the best improvement would be to simply leave the LR and momentum alone (as they have already been evolved to their current values), but to implement the cosine lr scheduler from https://github.com/ultralytics/yolov3/issues/848#issuecomment-587286848, as it's already been shown to improve upon our current scheduler.
glenn-jocher
on 23 Feb 2020
Si es el metodo que MXNet esta usando ahorita en su API.
Mire que pytorch apenas puso el CosineAnnealingWarmRestarts que es el metodo que dise ese papel.
La unica cosa que estoy mirando que el codigo clears the gradients cada 4 epochs. Y luego esstas scaling la loss function por 1/4 = 16/64. Crees que eso lo afecte? Porque estaba considerado quitar el scaling y clear los gradients cada epoch. Y ver si alomejor asin el modelo daba un smoother training.
FranciscoReveriano
on 23 Feb 2020
@FranciscoReveriano implementarlo aqui es facil, es que tarda mucho en entrenar COCO para averiguar los nuevos resultados. Usando LambdaLR scheduler puedes programar cualquier tipo de curva:
https://github.com/ultralytics/yolov3/blob/bc741f30e893706ed70374fefdb2cd7884a3cdc3/train.py#L138-L139
glenn-jocher
on 23 Feb 2020
Voy ah tratar el Cosine Annealing cuando termine de entrenar el modelo at 640. Me interesaria ver como funciona. Y mas importante ver como trabaja con mi custom data.
Dime si quieres las weights/.txt/ file de los resultados. Creo que vah ah terminar manana.
FranciscoReveriano
on 23 Feb 2020
@FranciscoReveriano Ok! Implemente el cosine scheduler (sin el warmup) ahora. EQN 1 en https://arxiv.org/pdf/1812.01187.pdf es:

lf = lambda x: 0.5 * (1 + math.cos(x * math.pi / epochs)) # cosine https://arxiv.org/pdf/1812.01187.pdf
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)

Podemos probar esta scheduler ahora para comparar directamente con el default step scheduler.
glenn-jocher
on 23 Feb 2020
* bI am always wondering what does burn in mean, you mentioned it controls the lr in the first epoch, i also read your code, it works only under the condition that epoch==0. In the original setting burn in =1000, but the first epoch covers up to 1838 batches. My dataset consists of 666 images, the first epoch should finish by the 11th batches. However, i tried different burn in settings before read your commit, resulting in a remarkable shift of loss curve as below:
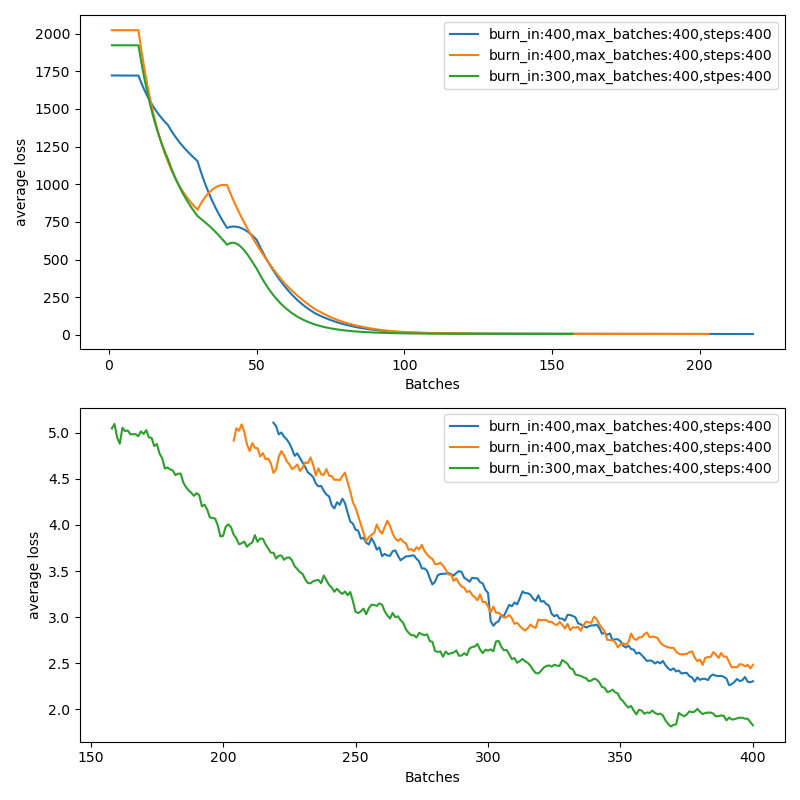
We see that it makes quite big difference at the very beginning, but the burn in was set to be 300, far away from 11 batches in the first epoch. Also, burn in was the only difference in my settings. I think maybe burn in works but not limited within the epoch 0.
 aaron-wang-de
on 23 Feb 2020
aaron-wang-de
on 23 Feb 2020
@glenn-jocher
Interesante creo que voy ah tratar los dos. El que tu hicites. Y tambien el que esta en PyTorch que tiene warm restarts.
Y referiendome ah la otra pregunta. Cres que el codigo haga un poco mejor si hucamos cada epoch tu clear the gradients. Y no husamos el scaling the la loss function.
FranciscoReveriano
on 23 Feb 2020
@aaron-wang-de it looks like you may simply have 3 very different initial losses responsible for what you are seeing. For example orange starts at over 2000 while blue starts below 1750. In any case your plots show an extremely small number of iterations, and incomplete training as the losses are still decreasing.
The original darknet implementation burnin period was 1000 batches on COCO, which trains to 500,000 batches total at bs 64.
glenn-jocher
on 24 Feb 2020
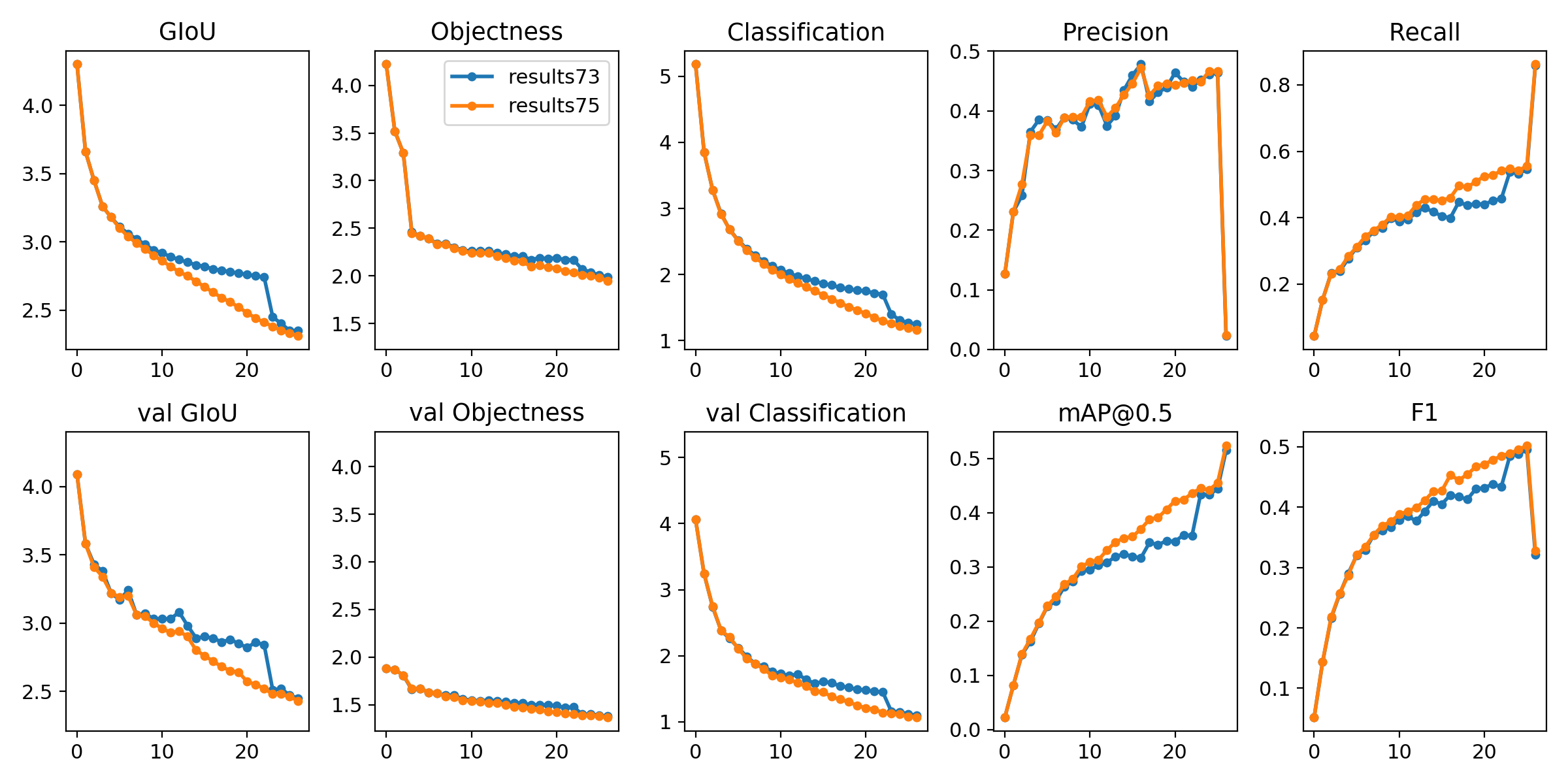
@FranciscoReveriano good results with the new cosine scheduler (orange) vs the default scheduler (blue):
n=73 && t=ultralytics/coco:v$n && sudo docker pull $t && sudo docker run -it --gpus all --ipc=host -v "$(pwd)"/coco:/usr/src/coco $t python3 train.py --data coco2014.data --img-size 512 608 --epochs 27 --batch 16 --accum 4 --weights '' --device 0 --cfg yolov3-sppa.cfg --nosave --name $n --multi && sudo shutdown
glenn-jocher
on 24 Feb 2020
That's actually extremely impressive @glenn-jocher !
Estoy esperando que mi COCO en regular ah 640 termine en mis dos GPUS para que trate este scheduler.
FranciscoReveriano
on 24 Feb 2020
@FranciscoReveriano si parece ser superior el nuevo cosine scheduler. Ayuda en la mitad de training, y tambien ayuda un poco el mAP final. Voy a probarlo en un full training de full COCO esta semana, y si tambien ayuda ayi lo convertire en el default scheduler. :)
glenn-jocher
on 24 Feb 2020
Cosine LR scheduler is the new default. See https://github.com/ultralytics/yolov3/issues/238#issuecomment-590027408
https://github.com/ultralytics/yolov3/blob/84371f68117cae975eabfa78cdf8a2aa1b78e4ba/train.py#L144-L145
glenn-jocher
on 2 Mar 2020
@glenn-jocher I saw that you also made a declining Pre-bias
FranciscoReveriano
on 3 Mar 2020
@FranciscoReveriano yes, I updated it to vary smoothly from the initial prebias conditions (lr and momentum) at epoch 0, to the normal conditions over 3 epochs. I think this might help a bit.
glenn-jocher
on 3 Mar 2020
@glenn-jocher Yo eh visto que cuando hago un prebias de una magnitude mas alta ah la initial me ayuda con los gradients.
FranciscoReveriano
on 3 Mar 2020
@glenn-jocher
Good works!
I have questions, actually pytorch already has their own cosine scheduler, but why do you re-implement this?
Learning Rate warmup with cosine scheduler
It's my own implementation for learning rate warmup with pytorch official cosine lr scheduler!
Have you ever tried to apply learning rate warmup for stable training in early epoch?
developer0hye
on 6 Mar 2020
@developer0hye yes this is true, perhaps we should use a warmup period, or 'burnin' as some people call it.
I'm a bit confused about how to handle the initial iterations because right now we have a prebias period where we actually use much higher LRs for the model biases (weight LRs stay the same) for the first few epochs, which is somewhat opposite of a warmup:
https://github.com/ultralytics/yolov3/blob/65eeb1bae5ea1f7d7249c0caf581e95de0dc1637/train.py#L216-L229
The main problem is that particularly for the yolo output biases, the obj and classification biases should be extremely negative to reflect a very low chance of being predicted. For example, for the classification on COCO, the mean output bias should be math.log(1 / (80 - 1)) = -4.6, to reflect a 1/80 probability, but this assumes a well balanced dataset. Class imbalances can skew this significantly, i.e. in COCO most of the objects are people I think, so the bias outputs are severely skewed, causing serious instabilities in early iterations, especially with momentum optimizers.
https://github.com/ultralytics/yolov3/blob/65eeb1bae5ea1f7d7249c0caf581e95de0dc1637/models.py#L88-L92
glenn-jocher
on 6 Mar 2020
I am finding that doing a stable larger learning rate for a longer period avoids nan later down the road.
FranciscoReveriano
on 6 Mar 2020
@glenn-jocher
have you tried the hard negative mining method used in SSD to cover the imbalance problem of objectness?
I think it can be the solution for that to use the hard negative mining method with focal loss.
developer0hye
on 7 Mar 2020
@developer0hye Do you have a paper? Or article discussing it?
FranciscoReveriano
on 7 Mar 2020
@developer0hye I've seen focal loss to accelerate the training and produce higher mAPs sooneer, but I found that it also accelerates _over_training and results in a lower final mAPs. I could never get it to help out on COCO.
I think towards the end of training the main challenge is suppressing overtraining (keeping the validation losses from increasing). If we could manage that, then longer training would result in better mAPs.
glenn-jocher
on 7 Mar 2020
@FranciscoReveriano
There are some explanations for the hard negative mining method in official SSD paper!
ssd paper
And... the method (the hard negative mining with focal loss) I mentioned is just my opinion.
Recently, I've implemented my own yolov3 tiny and tried to train the model from scratch on VOC2007 dataset, but I failed to train the model. I am trying to search for the reason for this.
@glenn-jocher
Thank you for your good opinion!
With my experience, the burn-in learning rate warmup for 5 epochs (updated as per iteration)worked well.
developer0hye
on 7 Mar 2020
@developer0hye Thanks. I am going to look more into it. I tried focal loss on my dataset but did't get very good results. Maybe this will help with Focal Loss.
FranciscoReveriano
on 7 Mar 2020
@FranciscoReveriano
Thanks, This repository showed the focal loss improvements in the performance of YOLOv3.
But... when I applied Focal loss to my dataset with my own yolov3, it harms the performance.
developer0hye
on 7 Mar 2020
@developer0hye label smoothing seems like an easy update, and it seems to help in the repo you pointed to. For the positive labels, I'm assigning the GIoU value to them rather than 1.0, as I thought this would help sort the boxes more by IOU for NMS rather than by confidence alone.
At the lower end though, I assign all negative examples a target of 0.0. We could modify this to 0.1 as in the label smoothing example to see the effect.
glenn-jocher
on 7 Mar 2020
@developer0hye wait I got myself confused. Can we apply labelsmoothing to nn.BCEWithLogitsLoss() as well as nn.CrossEntropyLoss()? In this repo we only use nn.BCEWithLogitsLoss() now for both obj and cls.
glenn-jocher
on 7 Mar 2020
@glenn-jocher yeah, I think so. We can apply label smoothing to nn.BCEWithLogitsLoss().
developer0hye
on 8 Mar 2020
Just a note, per https://github.com/WongKinYiu/CrossStagePartialNetworks/issues/6#issuecomment-596160944 label smoothing should only be applied to class loss, not obj loss.
From https://arxiv.org/pdf/1902.04103.pdf we have this, but they neglect to state the value of epsilon unfortunately.

glenn-jocher
on 8 Mar 2020
I found in the TensorFlow code two different implementations of label smoothing:
- Categorical Cross Entropy:
y_true * (1.0 - label_smoothing) + (label_smoothing / num_classes) - Binary Cross Entropy
y_true * (1.0 - label_smoothing) + 0.5 * label_smoothing
where I assume label_smoothing=0.1 is a typical smoothing value
glenn-jocher
on 12 Mar 2020
@glenn-jocher
I think so. label _smoothing value is set to 0.1 in many repositories that use the method.
developer0hye
on 14 Mar 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![github-actions[bot] picture](https://avatars.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 1 Aug 2020
github-actions[bot]
on 1 Aug 2020
Related issues
 Blddwkb
·
4Comments
Blddwkb
·
4Comments
 MichaelCong
·
4Comments
MichaelCong
·
4Comments
 mehrdadazizi72
·
3Comments
mehrdadazizi72
·
3Comments
 Deep-Learner
·
5Comments
Deep-Learner
·
5Comments
 JiahongXue
·
5Comments
JiahongXue
·
5Comments
Most helpful comment
@FranciscoReveriano Ok! Implemente el cosine scheduler (sin el warmup) ahora. EQN 1 en https://arxiv.org/pdf/1812.01187.pdf es:
Podemos probar esta scheduler ahora para comparar directamente con el default step scheduler.