Wgpu-rs: 10x Performance issues from gfx-memory 0.1.1 -> 0.1.3
Moving discussion from matrix to here.
In my batch gif generation project I have observed upgrading from gfx-memory 0.1.1 to 0.1.3 has caused the project to run 10x slower.
Caused by these two commits:
https://github.com/gfx-rs/gfx-extras/commit/1bcf805bb81f7b43e83b644aa0d2fcebf60afd67
https://github.com/gfx-rs/gfx-extras/commit/035e3a39bceb9d5b66a4519ebcc0fca5f4330ef9
Relevant code
https://github.com/rukai/brawllib_rs/blob/master/src/renderer/gif.rs
https://github.com/rukai/brawllib_rs/blob/master/src/renderer/draw.rs
gfx_memory=trace
gfx_memory 0.1.1

gfx_memory 0.1.3
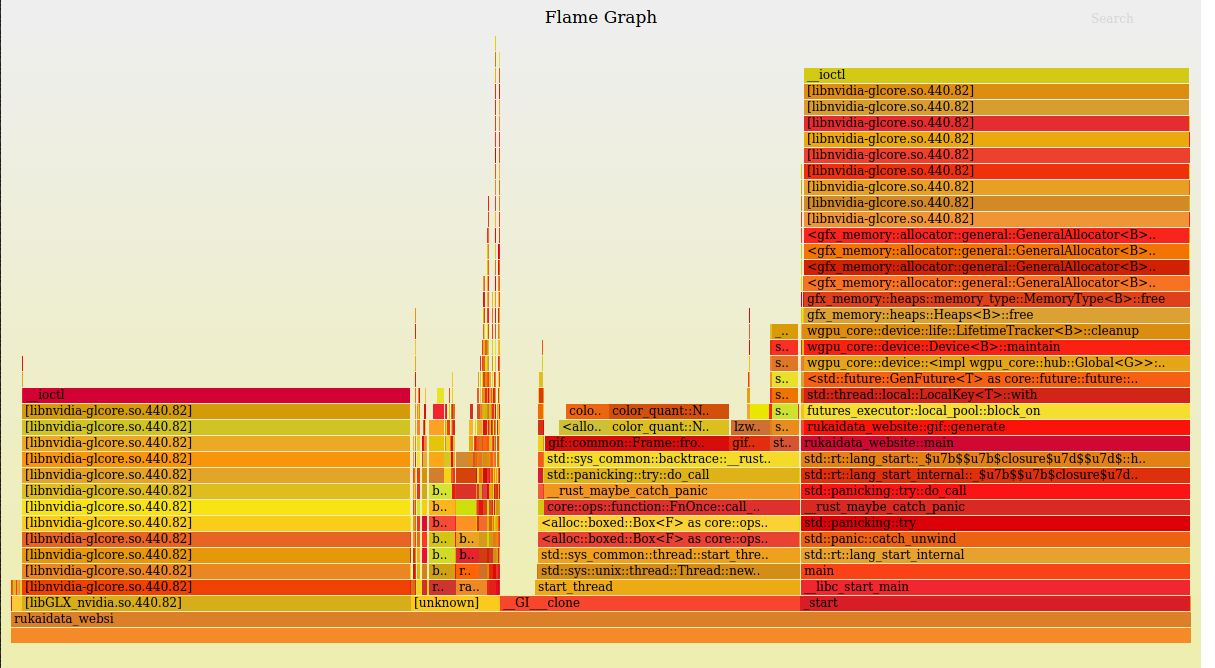
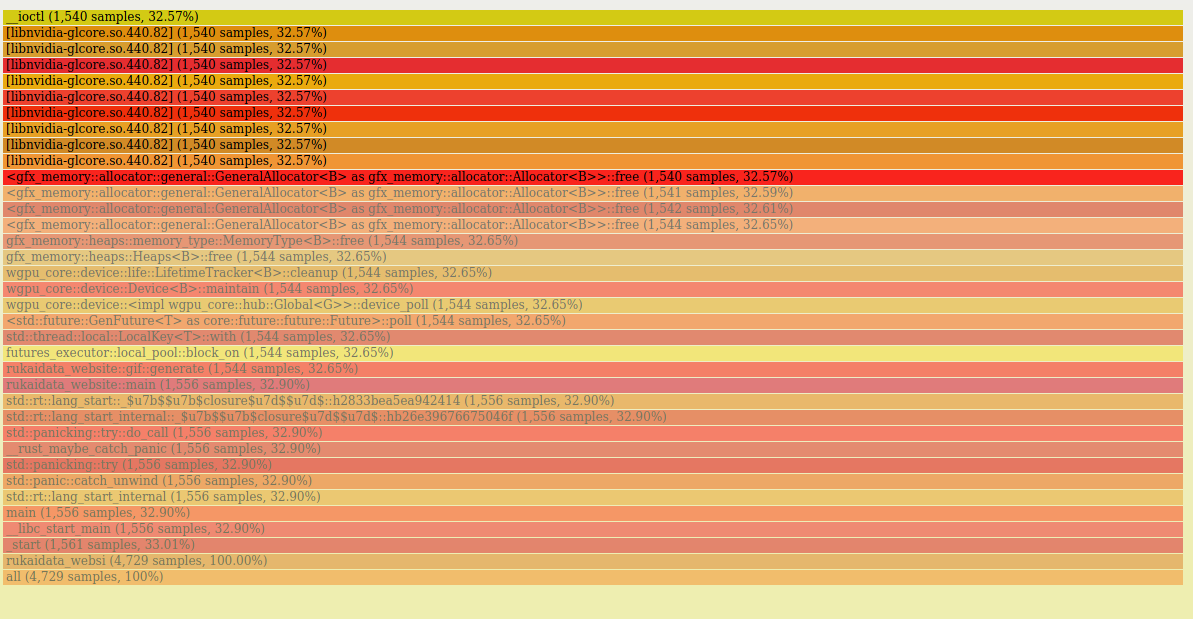
the BufferUsage's look fine?
I noticed that the uniforms have a COPY_DST which doesnt look important, but removing it has no observable effect.
Although I'd rather not go to the effort, let me know if I need to provide an easily runnable example for you.
 rukai
rukai
All 5 comments
So far it looks like we are just to eager to free chunks of memory, which results in constant re-allocation. It was faster at some point because our tracking was broken, and we weren't freeing memory at a ll. What we need to try doing in gfx-memory is retaining the memory for some time before freeing.
 kvark
on 19 Apr 2020
kvark
on 19 Apr 2020
I looked at the general allocator a bit, and it looks like it also only ever increments the total_blocks counter for each block size, which is used to create new chunk sizing. So it seems like it progressively allocates and frees bigger chunks, even if all you do is repeatedly allocate and free a chunk of the same size.
Seems like the easiest option is to just turn off freeing. And then an easy fix to get freeing back is to have a max pool size and dump chunks in LRU fashion as soon as the total pool hits the max. But until then I think it is better to have a monotonically growing pool size rather than a monotonically growing per-iteration allocation size.
Could reference what VMA does for its default memory allocation.
 glalonde
on 6 May 2020
glalonde
on 6 May 2020
Great analysis @glalonde ! Would you be interested in experimenting with the implementation?
kvark
on 6 May 2020
I added a couple of allocation benchmarks to https://github.com/kvark/wgpu-bench/ in an attempt to have something to help us optimizing, in addition to your app.
kvark
on 15 Jun 2020
It looks like this was already mostly fixed before my changes to the linear allocator!
When I made this issue it was taking 30 mins to render one characters gifs.
However before updating to the new linear allocator its taking 3mins to do one characters gifs.
After updating to the new linear allocator its taking 2.5mins to do one characters gifs.
So I'm guessing at some point wgpu was changed to use the linear allocator less, preventing it from making the allocator free memory, thus providing most of the improvements.
Still clearly some improvement from the linear allocator change which is nice to see.
rukai
on 22 Jun 2020
Related issues
 m4b
·
5Comments
m4b
·
5Comments
 Lokathor
·
3Comments
Lokathor
·
3Comments
 inguar
·
5Comments
inguar
·
5Comments
 dmilford
·
3Comments
dmilford
·
3Comments
 gzp-crey
·
3Comments
gzp-crey
·
3Comments
Most helpful comment
I looked at the general allocator a bit, and it looks like it also only ever increments the
total_blockscounter for each block size, which is used to create new chunk sizing. So it seems like it progressively allocates and frees bigger chunks, even if all you do is repeatedly allocate and free a chunk of the same size.Seems like the easiest option is to just turn off freeing. And then an easy fix to get freeing back is to have a max pool size and dump chunks in LRU fashion as soon as the total pool hits the max. But until then I think it is better to have a monotonically growing pool size rather than a monotonically growing per-iteration allocation size.
Could reference what VMA does for its default memory allocation.