Wav2letter: Cannot figure out how to decode
I'm trying to decode a single audio file using the released models.
This is my test file:
1 /work/audio.wav 4.46 did you know that mohammed was so good
And this is the decode.cfg file:
--lexicon=/work/decoder-unigram-10000-nbest10.lexicon
--lm=/work/lm_librispeech_kenlm_word_4g_200kvocab.bin
--tokens=/work/librispeech-train-all-unigram-10000.tokens
--am=/work/am_resnet_ctc_librispeech_dev_clean.bin
--test=/work/w2l_test.lst
--lmweight=2.5
--wordscore=1
--beamsize=500
--beamthreshold=25
--silweight=-0.5
--nthread_decoder=4
--smearing=max
--show=true
With the lexicon, lm and am downloaded from the sota/2019 models page.
(The dl link to the non beam search lexicon is broken btw.)
This is the result:
root@f427b0972235:~/wav2letter# build/Decoder --flagsfile /work/decode.cfg
I0128 12:37:28.102018 10 Decode.cpp:116] Gflags after parsing
--flagfile=; --fromenv=; --tryfromenv=; --undefok=; --tab_completion_columns=80; --tab_completion_word=; --help=false; --helpfull=false; --helpmatch=; --helpon=; --helppackage=false; --helpshort=false; --helpxml=false; --version=false; --adambeta1=0.90000000000000002; --adambeta2=0.999; --am=/work/am_resnet_ctc_librispeech_dev_clean.bin; --am_decoder_tr_dropout=0; --am_decoder_tr_layerdrop=0; --am_decoder_tr_layers=1; --arch=arch-resnet19-saug-b-cl; --archdir=/private/home/locronan/libri++/arch2; --attention=content; --attentionthreshold=0; --attnWindow=no; --attnconvchannel=0; --attnconvkernel=0; --attndim=0; --batchsize=4; --beamsize=500; --beamsizetoken=250000; --beamthreshold=25; --blobdata=false; --channels=1; --criterion=ctc; --critoptim=sgd; --datadir=/checkpoint/locronan/datasets/librispeech/lists; --dataorder=input; --decoderattnround=1; --decoderdropout=0; --decoderrnnlayer=1; --decodertype=wrd; --devwin=0; --emission_dir=; --enable_distributed=true; --encoderdim=0; --eosscore=0; --eostoken=false; --everstoredb=false; --fftcachesize=1; --filterbanks=80; --flagsfile=/work/decode.cfg; --framesizems=25; --framestridems=10; --gamma=1; --gumbeltemperature=1; --input=flac; --inputbinsize=100; --inputfeeding=false; --iter=500; --itersave=false; --labelsmooth=0.050000000000000003; --leftWindowSize=50; --lexicon=/work/decoder-unigram-10000-nbest10.lexicon; --linlr=-1; --linlrcrit=-1; --linseg=0; --lm=/work/lm_librispeech_kenlm_word_4g_200kvocab.bin; --lm_memory=5000; --lm_vocab=; --lmtype=kenlm; --lmweight=2.5; --localnrmlleftctx=0; --localnrmlrightctx=0; --logadd=false; --lr=0.40000000000000002; --lrcosine=true; --lrcrit=0; --maxdecoderoutputlen=200; --maxgradnorm=1; --maxisz=9223372036854775807; --maxload=-1; --maxrate=10; --maxsil=50; --maxtsz=9223372036854775807; --maxword=-1; --melfloor=1; --memstepsize=10485760; --mfcc=false; --mfcccoeffs=13; --mfsc=true; --minisz=200; --minrate=3; --minsil=0; --mintsz=2; --momentum=0.59999999999999998; --netoptim=sgd; --noresample=false; --nthread=4; --nthread_decoder=4; --numattnhead=8; --onorm=target; --optimepsilon=1e-08; --optimrho=0.90000000000000002; --outputbinsize=5; --pctteacherforcing=100; --pcttraineval=100; --pow=false; --pretrainWindow=0; --replabel=0; --reportiters=2000; --rightWindowSize=50; --rndv_filepath=; --rundir=/checkpoint/locronan/libri++/resnet-gang-wp; --runname=lr0.4_fb80_bsz4_mm0.6_mgn1_archarch-resnet19-saug-b-cl_cos500_g8; --samplerate=16000; --sampletarget=0.01; --samplingstrategy=rand; --sclite=; --seed=0; --show=true; --showletters=false; --silscore=0; --smearing=max; --smoothingtemperature=1; --softwoffset=10; --softwrate=5; --softwstd=5; --sqnorm=true; --stepsize=1000000; --surround=; --tag=; --target=ltr; --test=/work/w2l_test.lst; --tokens=librispeech-train-all-unigram-10000.tokens; --tokensdir=/private/home/locronan/libri++/run2-wp; --train=train-clean-100.lst,train-clean-360.lst,train-other-500.lst; --trainWithWindow=false; --transdiag=0; --unkscore=-inf; --use_memcache=false; --uselexicon=true; --usewordpiece=true; --valid=dev-clean.lst,dev-other.lst,test-clean.lst,test-other.lst; --weightdecay=0; --wordscore=1; --wordseparator=_; --world_rank=0; --world_size=1; --alsologtoemail=; --alsologtostderr=false; --colorlogtostderr=false; --drop_log_memory=true; --log_backtrace_at=; --log_dir=; --log_link=; --log_prefix=true; --logbuflevel=0; --logbufsecs=30; --logemaillevel=999; --logmailer=/bin/mail; --logtostderr=true; --max_log_size=1800; --minloglevel=0; --stderrthreshold=2; --stop_logging_if_full_disk=false; --symbolize_stacktrace=true; --v=0; --vmodule=;
terminate called after throwing an instance of 'std::runtime_error'
what(): Invalid dictionary filepath specified.
*** Aborted at 1580215048 (unix time) try "date -d @1580215048" if you are using GNU date ***
PC: @ 0x7fdbc1cde428 gsignal
*** SIGABRT (@0xa) received by PID 10 (TID 0x7fdbcd0a5bc0) from PID 10; stack trace: ***
@ 0x7fdbc2b54390 (unknown)
@ 0x7fdbc1cde428 gsignal
@ 0x7fdbc1ce002a abort
@ 0x7fdbc262184d __gnu_cxx::__verbose_terminate_handler()
@ 0x7fdbc261f6b6 (unknown)
@ 0x7fdbc261f701 std::terminate()
@ 0x7fdbc261f919 __cxa_throw
@ 0x418973 main
@ 0x7fdbc1cc9830 __libc_start_main
@ 0x489669 _start
@ 0x0 (unknown)
Aborted (core dumped)
I also tried greedy decoding as described in the docs:
build/Test --am /work/am_resnet_ctc_librispeech_dev_clean.bin --test /work/w2l_test.lst --maxload -1
Which resulted in the same error Invalid dictionary filepath specified.
I'm guessing I'm not setting --tokens and/or --lexicon correctly. But I don't know how to fix it, the files passed all exist.
 RuABraun
RuABraun
All 22 comments
The failure is probably at:
https://github.com/facebookresearch/wav2letter/blob/ecbd33f175a89d211541737ac471416ad2101d39/Decode.cpp#L121
Please check the file exits for the combination of the flags below:
--tokens=librispeech-train-all-unigram-10000.tokens;
--tokensdir=/private/home/locronan/libri++/run2-wp;
 avidov
on 28 Jan 2020
avidov
on 28 Jan 2020
Now I get it. tokens has to be a file, not a file path, and tokensdir specifies the directory.
Now I'm getting an error because it's prepending some defaulted directory to my test file. Guess I'll have to look through all the args to see which one I also have to change.
RuABraun
on 28 Jan 2020
So I got it to decode with the following decode config:
--lexicon=/work/decoder-unigram-10000-nbest10.lexicon
--lm=/work/lm_librispeech_kenlm_word_4g_200kvocab.bin
--am=/work/am_resnet_ctc_librispeech_dev_clean.bin
--tokens=librispeech-train-all-unigram-10000.tokens
--tokensdir=/work
--datadir=/work
--test=w2l_test.lst
--lmweight=2.5
--wordscore=1
--beamsize=500
--beamthreshold=25
--silweight=-0.5
--nthread_decoder=4
--smearing=max
--show=true
But something has gone wrong (WER nan and no output despite --show):
root@f427b0972235:~/wav2letter# build/Decoder --flagsfile /work/decode.cfg
I0128 17:18:10.604858 386 Decode.cpp:116] Gflags after parsing
--flagfile=; --fromenv=; --tryfromenv=; --undefok=; --tab_completion_columns=80; --tab_completion_word=; --help=false; --helpfull=false; --helpmatch=; --helpon=; --helppackage=false; --helpshort=false; --helpxml=false; --version=false; --adambeta1=0.90000000000000002; --adambeta2=0.999; --am=/work/am_resnet_ctc_librispeech_dev_clean.bin; --am_decoder_tr_dropout=0; --am_decoder_tr_layerdrop=0; --am_decoder_tr_layers=1; --arch=arch-resnet19-saug-b-cl; --archdir=/private/home/locronan/libri++/arch2; --attention=content; --attentionthreshold=0; --attnWindow=no; --attnconvchannel=0; --attnconvkernel=0; --attndim=0; --batchsize=4; --beamsize=500; --beamsizetoken=250000; --beamthreshold=25; --blobdata=false; --channels=1; --criterion=ctc; --critoptim=sgd; --datadir=/work; --dataorder=input; --decoderattnround=1; --decoderdropout=0; --decoderrnnlayer=1; --decodertype=wrd; --devwin=0; --emission_dir=; --enable_distributed=true; --encoderdim=0; --eosscore=0; --eostoken=false; --everstoredb=false; --fftcachesize=1; --filterbanks=80; --flagsfile=/work/decode.cfg; --framesizems=25; --framestridems=10; --gamma=1; --gumbeltemperature=1; --input=flac; --inputbinsize=100; --inputfeeding=false; --iter=500; --itersave=false; --labelsmooth=0.050000000000000003; --leftWindowSize=50; --lexicon=/work/decoder-unigram-10000-nbest10.lexicon; --linlr=-1; --linlrcrit=-1; --linseg=0; --lm=/work/lm_librispeech_kenlm_word_4g_200kvocab.bin; --lm_memory=5000; --lm_vocab=; --lmtype=kenlm; --lmweight=2.5; --localnrmlleftctx=0; --localnrmlrightctx=0; --logadd=false; --lr=0.40000000000000002; --lrcosine=true; --lrcrit=0; --maxdecoderoutputlen=200; --maxgradnorm=1; --maxisz=9223372036854775807; --maxload=-1; --maxrate=10; --maxsil=50; --maxtsz=9223372036854775807; --maxword=-1; --melfloor=1; --memstepsize=10485760; --mfcc=false; --mfcccoeffs=13; --mfsc=true; --minisz=200; --minrate=3; --minsil=0; --mintsz=2; --momentum=0.59999999999999998; --netoptim=sgd; --noresample=false; --nthread=4; --nthread_decoder=4; --numattnhead=8; --onorm=target; --optimepsilon=1e-08; --optimrho=0.90000000000000002; --outputbinsize=5; --pctteacherforcing=100; --pcttraineval=100; --pow=false; --pretrainWindow=0; --replabel=0; --reportiters=2000; --rightWindowSize=50; --rndv_filepath=; --rundir=/checkpoint/locronan/libri++/resnet-gang-wp; --runname=lr0.4_fb80_bsz4_mm0.6_mgn1_archarch-resnet19-saug-b-cl_cos500_g8; --samplerate=16000; --sampletarget=0.01; --samplingstrategy=rand; --sclite=; --seed=0; --show=true; --showletters=false; --silscore=0; --smearing=max; --smoothingtemperature=1; --softwoffset=10; --softwrate=5; --softwstd=5; --sqnorm=true; --stepsize=1000000; --surround=; --tag=; --target=ltr; --test=w2l_test.lst; --tokens=librispeech-train-all-unigram-10000.tokens; --tokensdir=/work; --train=train-clean-100.lst,train-clean-360.lst,train-other-500.lst; --trainWithWindow=false; --transdiag=0; --unkscore=-inf; --use_memcache=false; --uselexicon=true; --usewordpiece=true; --valid=dev-clean.lst,dev-other.lst,test-clean.lst,test-other.lst; --weightdecay=0; --wordscore=1; --wordseparator=_; --world_rank=0; --world_size=1; --alsologtoemail=; --alsologtostderr=false; --colorlogtostderr=false; --drop_log_memory=true; --log_backtrace_at=; --log_dir=; --log_link=; --log_prefix=true; --logbuflevel=0; --logbufsecs=30; --logemaillevel=999; --logmailer=/bin/mail; --logtostderr=true; --max_log_size=1800; --minloglevel=0; --stderrthreshold=2; --stop_logging_if_full_disk=false; --symbolize_stacktrace=true; --v=0; --vmodule=;
I0128 17:18:10.607852 386 Decode.cpp:137] Number of classes (network): 9998
I0128 17:18:12.457038 386 Decode.cpp:144] Number of words: 200001
I0128 17:18:13.577536 386 W2lListFilesDataset.cpp:141] 1 files found.
I0128 17:18:13.577565 386 Utils.cpp:102] Filtered 1/1 samples
I0128 17:18:13.577574 386 W2lListFilesDataset.cpp:62] Total batches (i.e. iters): 0
I0128 17:18:13.577577 386 Decode.cpp:158] [Serialization] Running forward pass ...
I0128 17:18:13.734843 386 Decode.cpp:205] [Dataset] Number of samples per thread: 0
I0128 17:18:20.812523 386 Decode.cpp:316] [Decoder] LM constructed.
I0128 17:18:25.644471 386 Decode.cpp:340] [Decoder] Trie planted.
I0128 17:18:26.135022 386 Decode.cpp:352] [Decoder] Trie smeared.
I0128 17:18:26.257906 386 Decode.cpp:612] ------
[Decode w2l_test.lst (0 samples) in 0.007268s (actual decoding time -nans/sample) -- WER: -nan, LER: -nan]
Hi @RuABraun,
Yep, there are flags datadir and tokensdir which are using as prefix for test and for tokens. You can set them as datadir='' and then put full path for the test. All info about this is listed in the docs.
About you nan WER: in the log Filtered 1/1 samples, so your sample is filtered (there are settings on min and max size of audio duration), and at the last roq of log you have (0 samples) so it means no samples decoded. To prevent filtering add the following flags --maxtsz=1000000000 --maxisz=1000000000 --minisz=0 --mintsz=0.
 tlikhomanenko
on 28 Jan 2020
tlikhomanenko
on 28 Jan 2020
Thanks, that made it get further, but it crashed:
I0128 19:22:25.487639 427 Decode.cpp:137] Number of classes (network): 9998
I0128 19:22:27.310488 427 Decode.cpp:144] Number of words: 200001
I0128 19:22:27.935518 427 W2lListFilesDataset.cpp:141] 1 files found.
I0128 19:22:27.935546 427 Utils.cpp:102] Filtered 0/1 samples
I0128 19:22:27.935562 427 W2lListFilesDataset.cpp:62] Total batches (i.e. iters): 1
I0128 19:22:27.935566 427 Decode.cpp:158] [Serialization] Running forward pass ...
*** Error in `build/Decoder': corrupted double-linked list: 0x00000000476f3c60 ***
======= Backtrace: =========
[.. skipping ..]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
*** Aborted at 1580239348 (unix time) try "date -d @1580239348" if you are using GNU date ***
PC: @ 0x7ff561900428 gsignal
*** SIGABRT (@0x1ab) received by PID 427 (TID 0x7ff56ccc7bc0) from PID 427; stack trace: ***
@ 0x7ff562776390 (unknown)
@ 0x7ff561900428 gsignal
@ 0x7ff56190202a abort
@ 0x7ff5619427ea (unknown)
@ 0x7ff5619496ed (unknown)
@ 0x7ff56194ccde (unknown)
@ 0x7ff56194f184 __libc_malloc
@ 0x7ff562240420 __cxa_allocate_exception
@ 0x7ff56b136917 af::array::array()
@ 0x6ba5b0 fl::batchnorm()
@ 0x6bc141 fl::batchnorm()
@ 0x6775b5 fl::LayerNorm::forward()
@ 0x67e80f fl::UnaryModule::forward()
@ 0x66e552 fl::Sequential::forward()
@ 0x41ae1c main
@ 0x7ff5618eb830 __libc_start_main
@ 0x489669 _start
@ 0x0 (unknown)
Aborted (core dumped)
```
RuABraun
on 28 Jan 2020
Could you try to run the same for librispeech audio file (just make sure that model is not broken)?
tlikhomanenko
on 29 Jan 2020
I copied a file and changed w2l_test.lst to:
/work/1089-134686-0001.flac 3.27 did you know that mohammed was so good
Didn't work, same error, also happens when I use a wav version.
RuABraun
on 29 Jan 2020
Could you try this inside docker image so I would be able at least reproduce your error (and also this is sanity check that the problem is not in your env)?
tlikhomanenko
on 31 Jan 2020
Hi @tlikhomanenko ! I get the same error.
I am running the decoder inside a docker (CPU), after following the steps described here.
I am using the following decoding configuration (from here):
# Replace `[...]`, `[DATA_DST]`, `[MODEL_DST]` with appropriate paths
# for test-clean (best params for dev-clean))
--am=models/am/am_resnet_ctc_librivox_dev_clean.bin
--tokensdir=models/am
--tokens=librispeech-train-all-unigram-10000.tokens
--lexicon=models/decoder/decoder-unigram-10000-nbest10.lexicon
--lm=models/decoder/lm_librispeech_kenlm_word_4g_200kvocab.bin
--datadir=.
--test=test-librispeech-test-clean.lst
--uselexicon=true
--sclite=decoding
--decodertype=wrd
--lmtype=kenlm
--silscore=0
--beamsize=500
--beamsizetoken=100
--beamthreshold=100
--nthread_decoder=8
--smearing=max
--show
--showletters
--lmweight=0.4949587668714
--wordscore=-0.075559487659085
where test-librispeech-test-clean.lst is a file with the following line (the wav file is from LibriSpeech test clean data):
1 ./1089-134686-0037.wav 5.21 in the silence their dark fire kindled the dusk into a tawny glow
I run the following command:
./wav2letter/build/Decoder --flagsfile wav2letter/recipes/models/sota/2019/librivox/decode_resnet_ctc_ngram_clean_test.cfg --minloglevel=0 --logtostderr=1 --maxtsz=1000000000 --maxisz=1000000000 --minisz=0 --mintsz=0
and I get the error:
.
.
.
I0131 09:52:11.991870 18919 Decode.cpp:137] Number of classes (network): 9998
I0131 09:52:13.826335 18919 Decode.cpp:144] Number of words: 200001
I0131 09:52:14.422116 18919 W2lListFilesDataset.cpp:141] 1 files found.
I0131 09:52:14.422145 18919 Utils.cpp:102] Filtered 0/1 samples
I0131 09:52:14.422168 18919 W2lListFilesDataset.cpp:62] Total batches (i.e. iters): 1
I0131 09:52:14.422176 18919 Decode.cpp:158] [Serialization] Running forward pass ...
*** Aborted at 1580464334 (unix time) try "date -d @1580464334" if you are using GNU date ***
PC: @ 0x7f2b1f735de2 opal_memory_ptmalloc2_int_malloc
*** SIGSEGV (@0x0) received by PID 18919 (TID 0x7f2b2d81fbc0) from PID 0; stack trace: ***
@ 0x7f2b230ac390 (unknown)
@ 0x7f2b1f735de2 opal_memory_ptmalloc2_int_malloc
@ 0x7f2b1f7366bc opal_memory_ptmalloc2_malloc
@ 0x7f2b22b76420 __cxa_allocate_exception
@ 0x7f2b2b6e9714 retain()
@ 0x7f2b2b6ea6e0 af_retain_array
@ 0x7f2b2ba6c81f af::array::array()
@ 0x6b9ac9 fl::batchnorm()
@ 0x6bc151 fl::batchnorm()
@ 0x6775c5 fl::LayerNorm::forward()
@ 0x67e81f fl::UnaryModule::forward()
@ 0x66e562 fl::Sequential::forward()
@ 0x41ae2c main
@ 0x7f2b22221830 __libc_start_main
@ 0x489679 _start
@ 0x0 (unknown)
Segmentation fault (core dumped)
And I get the same error when doing greedy decoding when running:
../wav2letter/build/Test --am models/am/am_resnet_ctc_librispeech_dev_clean.bin --tokensdir=models/am --tokens=librispeech-train-all-unigram-10000.tokens --lexicon=models/decoder/decoder-unigram-10000-nbest10.lexicon --uselexicon=false --datadir=. --test=test-librispeech-test-clean.lst --minloglevel=0 --logtostderr=1 --maxtsz=1000000000 --maxisz=1000000000 --minisz=0 --mintsz=0 --show --showletters
Thanks !
 lenassero
on 31 Jan 2020
lenassero
on 31 Jan 2020
I also tried the transformer model inside a Docker as well with the following configuration (from here):
# Replace `[...]`, `[DATA_DST]`, `[MODEL_DST]` with appropriate paths
# for test-other (best params for dev-other)
--am=models/am/am_transformer_ctc_librivox_dev_other.bin
--tokensdir=models/am
--tokens=librispeech-train-all-unigram-10000.tokens
--lexicon=models/decoder/decoder-unigram-10000-nbest10.lexicon
--lm=models/decoder/lm_librispeech_kenlm_word_4g_200kvocab.bin
--datadir=.
--test=test-librispeech-test-clean.lst
--uselexicon=true
--sclite=decoding
--decodertype=wrd
--lmtype=kenlm
--silscore=0
--beamsize=500
--beamsizetoken=100
--beamthreshold=100
--nthread_decoder=8
--smearing=max
--show
--showletters
--lmweight=0.61603454256618
--wordscore=0.96560269382887
Decoding seems to work but the hypothesis is very different from the transcript (too long, does not make sense):
I0131 10:05:25.182816 18961 Decode.cpp:137] Number of classes (network): 9998
I0131 10:05:27.108224 18961 Decode.cpp:144] Number of words: 200001
I0131 10:05:27.748078 18961 W2lListFilesDataset.cpp:141] 1 files found.
I0131 10:05:27.748106 18961 Utils.cpp:102] Filtered 0/1 samples
I0131 10:05:27.748132 18961 W2lListFilesDataset.cpp:62] Total batches (i.e. iters): 1
I0131 10:05:27.748143 18961 Decode.cpp:158] [Serialization] Running forward pass ...
I0131 10:05:33.978998 18961 Decode.cpp:205] [Dataset] Number of samples per thread: 1
I0131 10:05:34.587199 18961 Decode.cpp:316] [Decoder] LM constructed.
I0131 10:05:37.306722 18961 Decode.cpp:340] [Decoder] Trie planted.
I0131 10:05:37.776062 18961 Decode.cpp:352] [Decoder] Trie smeared.
I0131 10:05:37.895026 18984 Decode.cpp:454] [Decoder] Lexicon decoder with word-LM loaded in thread: 0
|T|: in the silence their dark fire kindled the dusk into a tawny glow
|P|: rubbish any lynde valjean heroic misunderstood it's romayne slightest he's dove anybody one's anybody robber budd enthusiasm conscientious handwriting sierra paula aroused baronet shrugged sidney resentment conviction thump katy mustn't he's opportunities claims income sincerity subscription assassin alliance knows regards budd identify soften wept charles undress he's deference earnestly eyelids urgent one's romayne extend eyelids throughout passenger proclaim reached
|t|: i n _ t h e _ s i l e n c e _ t h e i r _ d a r k _ f i r e _ k i n d l e d _ t h e _ d u s k _ i n t o _ a _ t a w n y _ g l o w
|p|: _ r u b b i s h _ a n y _ l y n d e _ v a l j e a n _ h e r o i c _ m i s u n d e r s t o o d _ i t ' s _ r o m a y n e _ s l i g h t e s t _ h e ' s _ d o v e _ a n y b o d y _ o n e ' s _ a n y b o d y _ r o b b e r _ b u d d _ e n t h u s i a s m _ c o n s c i e n t i o u s _ h a n d w r i t i n g _ s i e r r a _ p a u l a _ a r o u s e d _ b a r o n e t _ s h r u g g e d _ s i d n e y _ r e s e n t m e n t _ c o n v i c t i o n _ t h u m p _ k a t y _ m u s t n ' t _ h e ' s _ o p p o r t u n i t i e s _ c l a i m s _ i n c o m e _ s i n c e r i t y _ s u b s c r i p t i o n _ a s s a s s i n _ a l l i a n c e _ k n o w s _ r e g a r d s _ b u d d _ i d e n t i f y _ s o f t e n _ w e p t _ c h a r l e s _ u n d r e s s _ h e ' s _ d e f e r e n c e _ e a r n e s t l y _ e y e l i d s _ u r g e n t _ o n e ' s _ r o m a y n e _ e x t e n d _ e y e l i d s _ t h r o u g h o u t _ p a s s e n g e r _ p r o c l a i m _ r e a c h e d
[sample: 1, WER: 453.846%, LER: 647.692%, slice WER: 453.846%, slice LER: 647.692%, progress (slice 0): 100%]
I0131 10:05:38.552809 18961 Decode.cpp:612] ------
[Decode test-librispeech-test-clean.lst (1 samples) in 0.727742s (actual decoding time 0.53s/sample) -- WER: 453.846, LER: 647.692]
I have also tried greedy decoding and results are similar.
Not sure what is wrong here..
Thanks !
lenassero
on 31 Jan 2020
I am using the CPU docker image.
RuABraun
on 31 Jan 2020
i am getting error like this luks similar to to above error any one has any idea what went wrng
E0225 10:43:29.861795 3925 Serial.h:74] Error while loading: basic_string::_M_replace_aux
E0225 10:43:30.863404 3925 Serial.h:74] Error while loading: basic_string::_M_replace_aux
E0225 10:43:32.863991 3925 Serial.h:74] Error while loading: basic_string::_M_replace_aux
E0225 10:43:36.864491 3925 Serial.h:74] Error while loading: basic_string::_M_replace_aux
E0225 10:43:44.865150 3925 Serial.h:74] Error while loading: basic_string::_M_replace_aux
E0225 10:44:00.865705 3925 Serial.h:74] Error while loading: basic_string::_M_replace_aux
terminate called after throwing an instance of 'std::length_error'
what(): basic_string::_M_replace_aux
*** Aborted at 1582627440 (unix time) try "date -d @1582627440" if you are using GNU date ***
PC: @ 0x7f9b964c5428 gsignal
*** SIGABRT (@0xf55) received by PID 3925 (TID 0x7f9ba188cbc0) from PID 3925; stack trace: ***
@ 0x7f9b9733b390 (unknown)
@ 0x7f9b964c5428 gsignal
@ 0x7f9b964c702a abort
@ 0x7f9b96e0884d __gnu_cxx::__verbose_terminate_handler()
@ 0x7f9b96e066b6 (unknown)
@ 0x7f9b96e06701 std::terminate()
@ 0x7f9b96e06969 __cxa_rethrow
@ 0x48904e _ZN3w2l16retryWithBackoffIRFvRKNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEERSt13unordered_mapIS6_S6_St4hashIS6_ESt8equal_toIS6_ESaISt4pairIS7_S6_EEERSt10shared_ptrIN2fl6ModuleEERSJ_INS_17SequenceCriterionEEEJS8_SI_SN_SQ_EEENSt9result_ofIFT_DpT0_EE4typeENSt6chrono8durationIdSt5ratioILl1ELl1EEEEdlOSU_DpOSV_.constprop.6300
@ 0x41848a main
@ 0x7f9b964b0830 __libc_start_main
@ 0x487509 _start
@ 0x0 (unknown)
Aborted (core dumped)
 vigneshmj1997
on 25 Feb 2020
vigneshmj1997
on 25 Feb 2020
@RuABraun, @lenassero, This is CPU out of memory error. I tested on my machine it is using 20 GB of memory. Please check how your memory behaves.
@lenassero
I also tried the transformer model inside a Docker as well with the following configuration (from here):
# Replace `[...]`, `[DATA_DST]`, `[MODEL_DST]` with appropriate paths # for test-other (best params for dev-other) --am=models/am/am_transformer_ctc_librivox_dev_other.bin --tokensdir=models/am --tokens=librispeech-train-all-unigram-10000.tokens --lexicon=models/decoder/decoder-unigram-10000-nbest10.lexicon --lm=models/decoder/lm_librispeech_kenlm_word_4g_200kvocab.bin --datadir=. --test=test-librispeech-test-clean.lst --uselexicon=true --sclite=decoding --decodertype=wrd --lmtype=kenlm --silscore=0 --beamsize=500 --beamsizetoken=100 --beamthreshold=100 --nthread_decoder=8 --smearing=max --show --showletters --lmweight=0.61603454256618 --wordscore=0.96560269382887Decoding seems to work but the hypothesis is very different from the transcript (too long, does not make sense):
I0131 10:05:25.182816 18961 Decode.cpp:137] Number of classes (network): 9998 I0131 10:05:27.108224 18961 Decode.cpp:144] Number of words: 200001 I0131 10:05:27.748078 18961 W2lListFilesDataset.cpp:141] 1 files found. I0131 10:05:27.748106 18961 Utils.cpp:102] Filtered 0/1 samples I0131 10:05:27.748132 18961 W2lListFilesDataset.cpp:62] Total batches (i.e. iters): 1 I0131 10:05:27.748143 18961 Decode.cpp:158] [Serialization] Running forward pass ... I0131 10:05:33.978998 18961 Decode.cpp:205] [Dataset] Number of samples per thread: 1 I0131 10:05:34.587199 18961 Decode.cpp:316] [Decoder] LM constructed. I0131 10:05:37.306722 18961 Decode.cpp:340] [Decoder] Trie planted. I0131 10:05:37.776062 18961 Decode.cpp:352] [Decoder] Trie smeared. I0131 10:05:37.895026 18984 Decode.cpp:454] [Decoder] Lexicon decoder with word-LM loaded in thread: 0 |T|: in the silence their dark fire kindled the dusk into a tawny glow |P|: rubbish any lynde valjean heroic misunderstood it's romayne slightest he's dove anybody one's anybody robber budd enthusiasm conscientious handwriting sierra paula aroused baronet shrugged sidney resentment conviction thump katy mustn't he's opportunities claims income sincerity subscription assassin alliance knows regards budd identify soften wept charles undress he's deference earnestly eyelids urgent one's romayne extend eyelids throughout passenger proclaim reached |t|: i n _ t h e _ s i l e n c e _ t h e i r _ d a r k _ f i r e _ k i n d l e d _ t h e _ d u s k _ i n t o _ a _ t a w n y _ g l o w |p|: _ r u b b i s h _ a n y _ l y n d e _ v a l j e a n _ h e r o i c _ m i s u n d e r s t o o d _ i t ' s _ r o m a y n e _ s l i g h t e s t _ h e ' s _ d o v e _ a n y b o d y _ o n e ' s _ a n y b o d y _ r o b b e r _ b u d d _ e n t h u s i a s m _ c o n s c i e n t i o u s _ h a n d w r i t i n g _ s i e r r a _ p a u l a _ a r o u s e d _ b a r o n e t _ s h r u g g e d _ s i d n e y _ r e s e n t m e n t _ c o n v i c t i o n _ t h u m p _ k a t y _ m u s t n ' t _ h e ' s _ o p p o r t u n i t i e s _ c l a i m s _ i n c o m e _ s i n c e r i t y _ s u b s c r i p t i o n _ a s s a s s i n _ a l l i a n c e _ k n o w s _ r e g a r d s _ b u d d _ i d e n t i f y _ s o f t e n _ w e p t _ c h a r l e s _ u n d r e s s _ h e ' s _ d e f e r e n c e _ e a r n e s t l y _ e y e l i d s _ u r g e n t _ o n e ' s _ r o m a y n e _ e x t e n d _ e y e l i d s _ t h r o u g h o u t _ p a s s e n g e r _ p r o c l a i m _ r e a c h e d [sample: 1, WER: 453.846%, LER: 647.692%, slice WER: 453.846%, slice LER: 647.692%, progress (slice 0): 100%] I0131 10:05:38.552809 18961 Decode.cpp:612] ------ [Decode test-librispeech-test-clean.lst (1 samples) in 0.727742s (actual decoding time 0.53s/sample) -- WER: 453.846, LER: 647.692]I have also tried greedy decoding and results are similar.
Not sure what is wrong here..Thanks !
Which exact docker image version you are using? Is it latest (we update decoding algorithm, so decoder parameters are optimized for the new version)?
tlikhomanenko
on 25 Feb 2020
@vigneshmj1997,
check the paths of all files that they exist, Error while loading means it cannot find the path to your model.
tlikhomanenko
on 26 Feb 2020
@RuABraun @lenassero,
I reproduced the error and the output of transformer decoding with CPU bakcend. With CUDA backend everything is working correctly, so for now please switch to CUDA version for transformers at least.
Thanks for pointing to the steps of reproducing and catching the error. We will investigate.
tlikhomanenko
on 26 Feb 2020
Thank you for the update!
RuABraun
on 2 Mar 2020
Right now when I train on 4 GPUs, it takes 6 weeks. Won't retraining on CPU take ages?
 therahulprasad
on 28 Jun 2020
therahulprasad
on 28 Jun 2020
I have trained my acoustic model on wav2letter cuda docker using gpus. But when I am trying to reproduce the decoding results which I am getting from cuda docker, to cpu docker, I am getting the following error. Can you please give a solution for this.
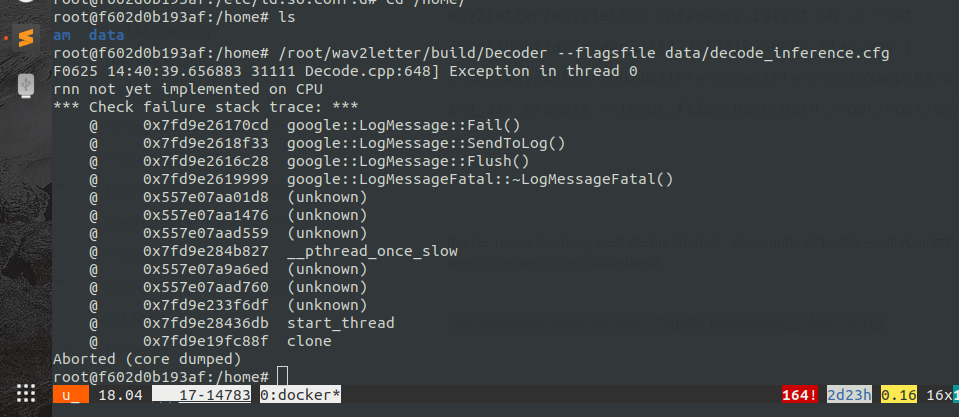
 gopesh97
on 29 Jun 2020
gopesh97
on 29 Jun 2020
We don't support some modules on CPU yet, for example RNN, so you can use CPU docker only for modules which are implemented on CPU.
tlikhomanenko
on 2 Jul 2020
When I try to train the ctc_transformer model in CPU docker, I got an error as:
terminate called after throwing an instance of 'af::exception'
what(): ArrayFire Exception (Invalid input size:203):
In function dim_t af::calcDim(const af_seq&, const dim_t&)
In file src/backend/common/dim4.cpp:135
Invalid dimension for argument 1
Expected: seq.end < parentDim ,
but in the GPU docker, it can run, what need to do for the CPU docker model training?
 sdkdzq2020
on 27 Aug 2020
sdkdzq2020
on 27 Aug 2020
Can you confirm that you running exactly the same command (with the same config params) in GPU and CPU docker and have this error in CPU while in GPU it is working?
tlikhomanenko
on 27 Aug 2020
The issue if fixed and solved in latest flashlight (we improved CPU backend with using now onednn and now there is full consistency with running GPU trained model to do inference on CPU). Check https://github.com/facebookresearch/flashlight.
tlikhomanenko
on 1 Mar 2021
Related issues
 tarang-jain
·
3Comments
tarang-jain
·
3Comments
 abhinavkulkarni
·
3Comments
abhinavkulkarni
·
3Comments
 megharangaswamy
·
5Comments
megharangaswamy
·
5Comments
 smolendawid
·
3Comments
smolendawid
·
3Comments
 pzelasko
·
6Comments
pzelasko
·
6Comments
Most helpful comment
@RuABraun @lenassero,
I reproduced the error and the output of transformer decoding with CPU bakcend. With CUDA backend everything is working correctly, so for now please switch to CUDA version for transformers at least.
Thanks for pointing to the steps of reproducing and catching the error. We will investigate.