Warehouse: Search reindex task leaves empty index.
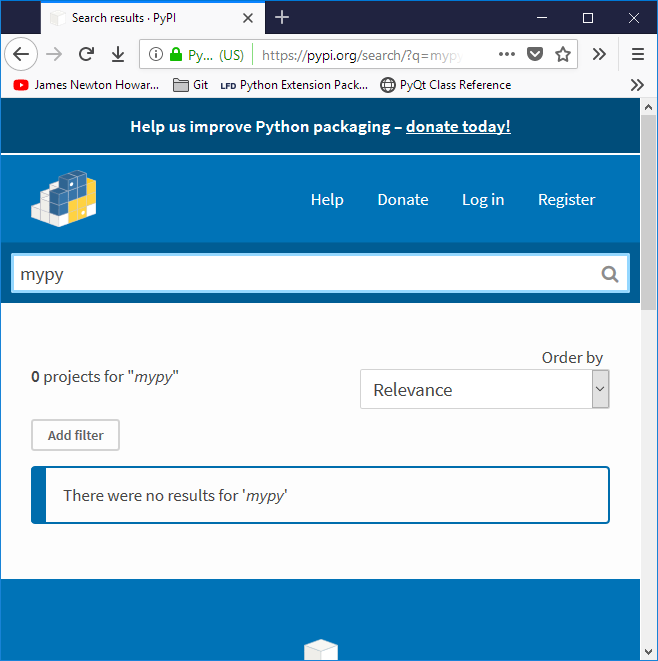
The 'Search projects' function does not work for me on https://pypi.org. Irrespective of the query, the search does not return any results. (Example: https://pypi.org/search/?q=numpy)
 padix-key
padix-key
All 19 comments
Me, too.
 UlionTse
on 18 Apr 2018
UlionTse
on 18 Apr 2018
+1
 danielhrisca
on 18 Apr 2018
danielhrisca
on 18 Apr 2018
+1
 klaaskooistra
on 18 Apr 2018
klaaskooistra
on 18 Apr 2018
Neither pip 10.0.0 nor pip 9.0.1 showing any results at the moment:
pip search pip -v
Starting new HTTPS connection (1): pypi.python.org
https://pypi.python.org:443 "POST /pypi HTTP/1.1" 200 108
 olf42
on 18 Apr 2018
olf42
on 18 Apr 2018
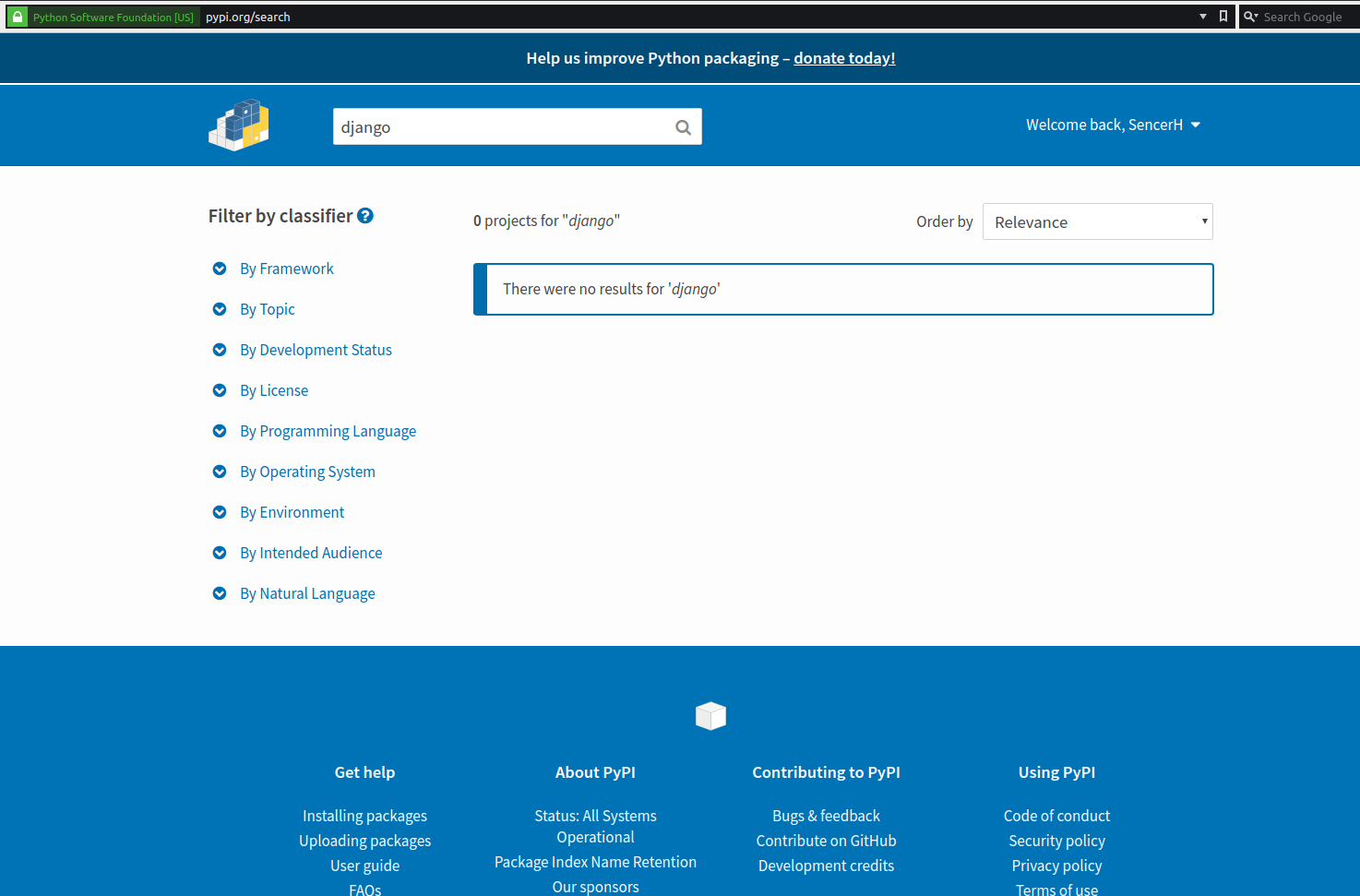
Same here;
Tested with pip 10, 8, 7
$ pip search django -v
Starting new HTTPS connection (1): pypi.python.org
https://pypi.python.org:443 "POST /pypi HTTP/1.1" 200 108
 RecNes
on 18 Apr 2018
RecNes
on 18 Apr 2018
Neither the website search nor pip search returning any results but pip install & pip list -o (which has to query the versions) all seem to be working ok so it looks to be just the search interface.
 GadgetSteve
on 18 Apr 2018
GadgetSteve
on 18 Apr 2018
Same here,
Critical functionality is broken!
 piotr-gomola
on 18 Apr 2018
piotr-gomola
on 18 Apr 2018
I'm sure people are already working to solve this
danielhrisca
on 18 Apr 2018
Appears to be solved in web and cli (which probaly use the same endpoint) :+1:
olf42
on 18 Apr 2018
We seem to have some kind of issue in the task that runs every 3 hours to update the index. It was aggravated by changes reverted in #3716, but the underlying issue seems to still be in play.
Something seems to clearly be going wrong in the "swap" in this code: https://github.com/pypa/warehouse/blob/b463af8aac4c778fe5fd1d7abe6e52c00bd06a13/warehouse/search/tasks.py#L131-L167
 ewdurbin
on 18 Apr 2018
ewdurbin
on 18 Apr 2018
This seems to be related to running the indexing job as a Celery task. I'm unable to reproduce when running the reindex job from CLI, even kicking two of them off "in competition".
ewdurbin
on 18 Apr 2018
Our ElasticSearch cluster has been upgraded to the latest available release in the 5.x series (5.6.9) from a very early release (5.0).
This was optimistic, aside from being generally a good idea. Perhaps we were hitting some bug that has been resolved.
We also disabled automatic index creation, which _may_ have been leading to the issues encountered leading to #3716.
Aside from this one observation: In our handling of the index swap, we do not wait for a "green" status on the new index before swapping the alias and deleting the old index. Perhaps we should?
ewdurbin
on 19 Apr 2018
Occurred again in prod on the last index task. New index being created, grabbed logs to investigate.
ewdurbin
on 19 Apr 2018
State found:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open production-39b6225ea1 yWEfL5Q6RGu8IlnHvCTvsA 1 2 0 0 486b 162b
So the index job attempted to create the new index, but the result was empty. It nevertheless continued on to delete the previous index and take the alias.
ewdurbin
on 19 Apr 2018
logs:
[2018-04-19 15:00:00,792: INFO/ForkPoolWorker-5] PUT https://<redacted>.us-east-1.aws.found.io:<redacted>/production-39b6225ea1?wait_for_active_shards=1 [status:200 request:0.712s]
[2018-04-19 15:15:22,702: INFO/ForkPoolWorker-5] POST https://<redacted>.us-east-1.aws.found.io:<redacted>/production-39b6225ea1/_forcemerge [status:200 request:0.020s]
[2018-04-19 15:15:22,786: INFO/ForkPoolWorker-5] PUT https://<redacted>.us-east-1.aws.found.io:<redacted>/production-39b6225ea1/_settings [status:200 request:0.083s]
[2018-04-19 15:15:22,837: INFO/ForkPoolWorker-5] HEAD https://<redacted>.us-east-1.aws.found.io:<redacted>/_alias/production [status:200 request:0.051s]
[2018-04-19 15:15:22,854: INFO/ForkPoolWorker-5] GET https://<redacted>.us-east-1.aws.found.io:<redacted>/_alias/production [status:200 request:0.017s]
[2018-04-19 15:15:23,067: INFO/ForkPoolWorker-5] POST https://<redacted>.us-east-1.aws.found.io:<redacted>/_aliases [status:200 request:0.213s]
[2018-04-19 15:15:23,682: INFO/ForkPoolWorker-5] DELETE https://<redacted>.us-east-1.aws.found.io:<redacted>/production-c7d6538b0d [status:200 request:0.614s]
excluded _bulk calls for clarity, but there were plenty of them!
grep <redacted> worker-recent | grep '2018-04-19 15:' | grep _bulk | wc
270 2430 54810
comparing to two previous runs:
grep <redacted> worker-recent | grep '2018-04-19 12' | grep _bulk | wc
274 2466 55641
grep <redacted> worker-recent | grep '2018-04-19 09' | grep _bulk | wc
269 2421 54607
it seems #3774 may have helped... which leads me to believe some state was being cached by the celery worker...
ewdurbin
on 20 Apr 2018
haven't had any issues since #3774 deployed... continuing to keep an eye on things. added metric for search result counts in #3772 to alert us when index is empty.
ewdurbin
on 23 Apr 2018
we've been going steady for 3 days. closing.
ewdurbin
on 26 Apr 2018
The problem is that Project doesn't have the new index associated with it when running in celery - the Index.doc_type method only sets the index name on the DocType if no index is set. That would explain why it runs fine from CLI but not from celery - CLI starts with fresh objects that don't have an index associated with it while celery is a long running process where it might happen that the previous reindex run has already registered an index name with the Project doc type. Should be a simple fix, PR incoming
 HonzaKral
on 15 May 2018
HonzaKral
on 15 May 2018
Related issues
 gcochard
·
3Comments
gcochard
·
3Comments
 mbakke
·
3Comments
mbakke
·
3Comments
 ewjoachim
·
3Comments
ewjoachim
·
3Comments
 nlhkabu
·
4Comments
nlhkabu
·
4Comments
 mahmoud
·
4Comments
mahmoud
·
4Comments
Most helpful comment
we've been going steady for 3 days. closing.