Vision: Load pre-trained fasterrcnn with AnchorGenerator()
Hi I am trying to run the following:
import torchvision
from torchvision.models.detection.rpn import AnchorGenerator
anchor_generator = AnchorGenerator(sizes=((16, 32, 64, 128, 256, 512),),
aspect_ratios=((0.25, 0.5, 1.0, 2.0),))
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True, rpn_anchor_generator=anchor_generator)
and getting the following error:
RuntimeError Traceback (most recent call last)
5 aspect_ratios=((0.25, 0.5, 1.0, 2.0),))
6
----> 7 model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True, rpn_anchor_generator=anchor_generator)
/data/anaconda/envs/torchdetect/lib/python3.7/site-packages/torchvision/models/detection/faster_rcnn.py in fasterrcnn_resnet50_fpn(pretrained, progress, num_classes, pretrained_backbone, **kwargs)
334 state_dict = load_state_dict_from_url(model_urls['fasterrcnn_resnet50_fpn_coco'],
335 progress=progress)
--> 336 model.load_state_dict(state_dict)
337 return model
/data/anaconda/envs/torchdetect/lib/python3.7/site-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
775 if len(error_msgs) > 0:
776 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
--> 777 self.__class__.__name__, "\n\t".join(error_msgs)))
778 return _IncompatibleKeys(missing_keys, unexpected_keys)
779
RuntimeError: Error(s) in loading state_dict for FasterRCNN:
size mismatch for rpn.head.cls_logits.weight: copying a param with shape torch.Size([3, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([24, 256, 1, 1]).
size mismatch for rpn.head.cls_logits.bias: copying a param with shape torch.Size([3]) from checkpoint, the shape in current model is torch.Size([24]).
size mismatch for rpn.head.bbox_pred.weight: copying a param with shape torch.Size([12, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([96, 256, 1, 1]).
size mismatch for rpn.head.bbox_pred.bias: copying a param with shape torch.Size([12]) from checkpoint, the shape in current model is torch.Size([96]).
Can you please let me know what the problem is and how to fix? I am trying to use a different set of anchors on a model pre-trained on coco, to later train for num_classes=2 with the following like in the official tutorial provided:
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
num_classes = 2
get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
Thank you.
 fboylu
fboylu
All 11 comments
Hi,
The number / type of anchors will affect how the layout of the weights are setup in the rpn_head, so you'll also need to reset from scratch the rpn_head.
I'd recommend first loading the pre-trained model without modifications, and then change the anchor_generator and the rpn_head accordingly, because the number of anchors will affect the number of input channels to the rpn_head.
Also, because you only want to use a single feature map for the RPN (I think you don't want to use FPN, is that right?), I'd expect that you also want to use a single feature map for the detection heads, so I'd also change the MultiScaleRoIAlign to only take one feature map into account, as explained in
https://github.com/pytorch/vision/blob/3d5610391eaef38ae802ffe8b693ac17b13bd5d1/torchvision/models/detection/faster_rcnn.py#L119-L131
Let me know if you have further questions.
 fmassa
on 3 Jun 2019
fmassa
on 3 Jun 2019
@fmassa thank you. I actually do want to use FPN. I initially tried
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
anchor_generator = AnchorGenerator(sizes=((16, 32, 64, 128, 256, 512),),
aspect_ratios=((0.25, 0.5, 1.0, 2.0),))
model.rpn.anchor_generator = anchor_generator
but then I get the following:
RuntimeError Traceback (most recent call last)
16 for epoch in range(num_epochs):
17 # train for one epoch, printing every 10 iterations
---> 18 train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
19 # update the learning rate
20 lr_scheduler.step()
/datadrive/torchvisionOD/engine.py in train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq)
28 targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
29
---> 30 loss_dict = model(images, targets)
31
32 losses = sum(loss for loss in loss_dict.values())
/data/anaconda/envs/torchdetect/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, input, *kwargs)
491 result = self._slow_forward(input, *kwargs)
492 else:
--> 493 result = self.forward(input, *kwargs)
494 for hook in self._forward_hooks.values():
495 hook_result = hook(self, input, result)
/data/anaconda/envs/torchdetect/lib/python3.7/site-packages/torchvision/models/detection/generalized_rcnn.py in forward(self, images, targets)
49 if isinstance(features, torch.Tensor):
50 features = OrderedDict([(0, features)])
---> 51 proposals, proposal_losses = self.rpn(images, features, targets)
52 detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
53 detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
/data/anaconda/envs/torchdetect/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, input, *kwargs)
491 result = self._slow_forward(input, *kwargs)
492 else:
--> 493 result = self.forward(input, *kwargs)
494 for hook in self._forward_hooks.values():
495 hook_result = hook(self, input, result)
/data/anaconda/envs/torchdetect/lib/python3.7/site-packages/torchvision/models/detection/rpn.py in forward(self, images, features, targets)
407 # note that we detach the deltas because Faster R-CNN do not backprop through
408 # the proposals
--> 409 proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
410 proposals = proposals.view(num_images, -1, 4)
411 boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
/data/anaconda/envs/torchdetect/lib/python3.7/site-packages/torchvision/models/detection/_utils.py in decode(self, rel_codes, boxes)
166 concat_boxes = torch.cat(boxes, dim=0)
167 pred_boxes = self.decode_single(
--> 168 rel_codes.reshape(sum(boxes_per_image), -1), concat_boxes
169 )
170 return pred_boxes.reshape(sum(boxes_per_image), -1, 4)
RuntimeError: shape '[3225600, -1]' is invalid for input of size 2148552
So I suspect this is something with the rpn head? Can you help me understand how to change the rpn head?
thanks
Fidan
fboylu
on 3 Jun 2019
If you want to use the FPN, then you should specify as many tuples as the number of feature maps that you want to extract the RoIs from.
So I'd change the code to be
from torchvision.models.detection.rpn import AnchorGenerator
from torchvision.models.detection.rpn import RPNHead
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# create an anchor_generator for the FPN
# which by default has 5 outputs
anchor_generator = AnchorGenerator(
sizes=tuple([(16, 32, 64, 128, 256, 512) for _ in range(5)]),
aspect_ratios=tuple([(0.25, 0.5, 1.0, 2.0) for _ in range(5)]))
model.rpn.anchor_generator = anchor_generator
# 256 because that's the number of features that FPN returns
model.rpn.head = RPNHead(256, anchor_generator.num_anchors_per_location()[0])
Let me know if this works for you
fmassa
on 3 Jun 2019
This works, Thank you! I was originally planning to use maskrcnns but my custom dataset does not have masks. If I used the following instead of the fasterrcnn_resnet50_fpn above, how can I turn the masks off?
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
I suppose you are using maskrcnn_resnet50_fpn instead of fasterrcnn_resnet50_fpn because it gives better results for detection?
Anyway, here is the check that sees if masks are available
https://github.com/pytorch/vision/blob/04188377c54aa9073e4c2496ddd9996da9fda629/torchvision/models/detection/roi_heads.py#L375-L382
So if you do
model.roi_heads.mask_roi_pool = None
it should stop computing the head branch.
fmassa
on 3 Jun 2019
Yes, that's correct using maskrcnn for better predictions. I have seen that check before while I was debugging the error I was getting but using that you still get an error with coco_eval.py, how can I fix that? Thank you...
KeyError Traceback (most recent call last)
20 lr_scheduler.step()
21 # evaluate on the test dataset
---> 22 evaluate(model, data_loader_test, device=device)
23
24 print("That's it!")
/data/anaconda/envs/torchdetect/lib/python3.7/site-packages/torch/autograd/grad_mode.py in decorate_no_grad(args, *kwargs)
41 def decorate_no_grad(args, *kwargs):
42 with self:
---> 43 return func(args, *kwargs)
44 return decorate_no_grad
45
/datadrive/torchvisionOD/engine.py in evaluate(model, data_loader, device)
93 res = {target["image_id"].item(): output for target, output in zip(targets, outputs)}
94 evaluator_time = time.time()
---> 95 coco_evaluator.update(res)
96 evaluator_time = time.time() - evaluator_time
97 metric_logger.update(model_time=model_time, evaluator_time=evaluator_time)
/datadrive/torchvisionOD/coco_eval.py in update(self, predictions)
36
37 for iou_type in self.iou_types:
---> 38 results = self.prepare(predictions, iou_type)
39 coco_dt = loadRes(self.coco_gt, results) if results else COCO()
40 coco_eval = self.coco_eval[iou_type]
/datadrive/torchvisionOD/coco_eval.py in prepare(self, predictions, iou_type)
64 return self.prepare_for_coco_detection(predictions)
65 elif iou_type == "segm":
---> 66 return self.prepare_for_coco_segmentation(predictions)
67 elif iou_type == "keypoints":
68 return self.prepare_for_coco_keypoint(predictions)
/datadrive/torchvisionOD/coco_eval.py in prepare_for_coco_segmentation(self, predictions)
102 scores = prediction["scores"]
103 labels = prediction["labels"]
--> 104 masks = prediction["masks"]
105
106 masks = masks > 0.5
KeyError: 'masks'
fboylu
on 3 Jun 2019
I think this check below is doing that:
I worked around by commenting out
if isinstance(model_without_ddp, torchvision.models.detection.MaskRCNN):
iou_types.append("segm")
Let me know if there is a better way.
thanks
fboylu
on 3 Jun 2019
For now this is the best way as a workaround.
I'm closing this issue as it seems that you have fixed your issues, let me know if you have further questions
fmassa
on 4 Jun 2019
Thanks both of you
 circlesun
on 21 Mar 2020
circlesun
on 21 Mar 2020
If you want to use the FPN, then you should specify as many tuples as the number of feature maps that you want to extract the RoIs from.
So I'd change the code to befrom torchvision.models.detection.rpn import AnchorGenerator from torchvision.models.detection.rpn import RPNHead model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True) # create an anchor_generator for the FPN # which by default has 5 outputs anchor_generator = AnchorGenerator( sizes=tuple([(16, 32, 64, 128, 256, 512) for _ in range(5)]), aspect_ratios=tuple([(0.25, 0.5, 1.0, 2.0) for _ in range(5)])) model.rpn.anchor_generator = anchor_generator # 256 because that's the number of features that FPN returns model.rpn.head = RPNHead(256, anchor_generator.num_anchors_per_location()[0])Let me know if this works for you
Though the issue is closed ... there is a small editing required in @fmassa solution as provided above .. in line number 8 .. The correct way is as follow
anchor_generator = AnchorGenerator(
sizes= ((16,), (32,), (64,), (128,), (256,), (512,))
aspect_ratios=tuple([(0.25, 0.5, 1.0, 2.0) for _ in range(5)]))
@fmassa solutions generates redundant _cell_anchors_ i-e 5x the same set of values, as shown here:
https://github.com/pytorch/vision/blob/e92b5155d7d78363826a822ccacf7c046d19245a/torchvision/models/detection/rpn.py#L100-107
This is not required.The 5 set of tuples of aspect_ratio are enough to cater for FPN output requirements. Doing same with anchor sizes only adds redudancy. Though its not an error but it produces two issue :
suffocates the memory of GPU , e-g
Using only 4 anchor scales [16,32,64,128,256] ,for image size of 1024 x 1024 , batch size 2 , GPU Tesla P100-PCIE, Epoch 0, memory consumption with redundant anchors via @fmassa method during training :
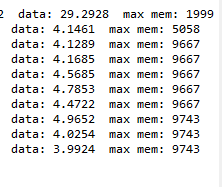
and the same after editing as shown in above code
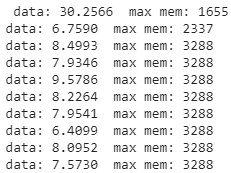
it produces instablity during training, or in other words , the loss reaches inf , for higher values of learning rate. for my dataset it went unstable even at 0.02 i-e the default learning rate.
Hope this helps ...
 ham952
on 24 Jun 2020
ham952
on 24 Jun 2020
i'm just reading you guys discussion and solved my problem...
just wanna thank github community.
thank you guys all!
 Yonggie
on 5 Nov 2020
Yonggie
on 5 Nov 2020
Related issues
 datumbox
·
3Comments
datumbox
·
3Comments
 ArashJavan
·
3Comments
ArashJavan
·
3Comments
 feiyangsuo
·
3Comments
feiyangsuo
·
3Comments
 300LiterPropofol
·
3Comments
300LiterPropofol
·
3Comments
 bodokaiser
·
3Comments
bodokaiser
·
3Comments
Most helpful comment
If you want to use the FPN, then you should specify as many tuples as the number of feature maps that you want to extract the RoIs from.
So I'd change the code to be
Let me know if this works for you