Victoriametrics: remove_resets() loses state when input becomes stale
Describe the bug
remove_resets() output becomes undefined and loses state when when input becomes stale
It seems normal that a series a may become momentarily stale when there is a restart event, and in general there may be occasional staleness due to connectivity.
Expected behavior
For remove_resets() to be useful, it should hold the output when the input disappears. In the example below, output of remove_resets() should not become undefined, and should settle at a value of 2 (since input series incremented at 10:30 and 11:05).
Screenshots
single series x vs. remove_resets(x)

Version
victoria-metrics-20201116-192030-tags-v1.47.0-0-g1c477bc2f
 belm0
belm0
All 17 comments
remove_resets() is applied individually and independently to each time series. It doesn't lose state if time series contains gaps. Try the following query as a proof: remove_resets(rand() < 0.1). It looks like you have distinct time series on the graph above, so remove_resets() doesn't accumulate values across these time series.
As for the suggestion that remove_resets() should return the last available value during gaps in time series, it cannot be applied, since it goes against PromQL data model - the majority of PromQL functions don't return data points if source time has a gap on the given time range.
 valyala
on 18 Nov 2020
valyala
on 18 Nov 2020
Additional notes, which may be relevant here:
- MetricsQL provides
keep_last_value()function for filling gaps. - If distinct time series don't intersect, then they can be summed before applying
remove_resets()in order to get expected results. Tryremove_resets(sum(x))for your case.
valyala
on 18 Nov 2020
@valyala my example above is a single time series. It becomes unavailable a few times, and then returns.
This is exactly the use case for increase() and remove_resets(). If the target becomes unavailable, and the returns, these functions should not lose state.
belm0
on 18 Nov 2020
text above the screenshot stated it clearly: "single series x vs. remove_resets(x)"
belm0
on 18 Nov 2020
@belm0 , could you share the original query that uses remove_resets()?
valyala
on 18 Nov 2020
query: remove_resets(my_metric{...label selectors matching a single series...})
belm0
on 18 Nov 2020
OK, then could you provide labels for all the time series returned from the query my_metric{...label selectors matching a single series...}? Note that a time series is uniquely identified by its name plus a set of all its labels. If at least a single label value doesn't match, then this is considered as a new time series.
valyala
on 18 Nov 2020
The query my_metric{...} is exactly the green series in my screenshot. If there were multiple series, grafana would show multiple series with different colors. There is only one series, I'm certain, otherwise I wouldn't have filed the bug.
belm0
on 18 Nov 2020
remove_resets(rand()) exhibits the same problem

belm0
on 18 Nov 2020
is it possible that remove_resets() is misdocumented, and expecting m[d] instead of q?
should my query be this?
remove_resets(my_metric{...}[$__range])
so I believe remove_resets() is working as intended:
- it will not have output when there is no input (unless
m[d]form is used?) - it does preserve state within a series
- in my example screenshot, the second occurrence of value "1" after the gap isn't actually a rising edge, so it isn't counted as an increment. Therefore we see
remove_resets()output returning to 1 whenever the input returns, and it doesn't advance to 2.
Here is another example series:
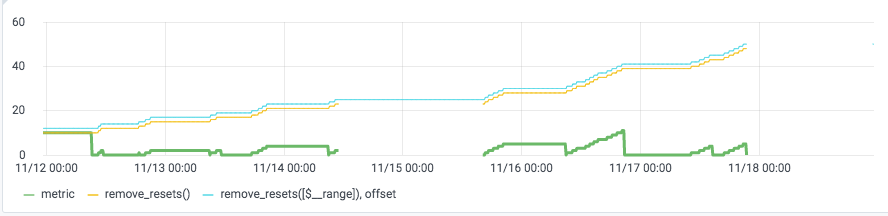
I'd still like remove_resets() to have valid output at the end of the range. Perhaps:
keep_last_value(remove_resets(my_metric{...}))
This kind of query doesn't work well as an instant query, however.
belm0
on 18 Nov 2020
I noticed that increase() does connect gaps and have output at the end of range even when input is gone. It's not obvious why increase() and remove_resets() behave differently.
should remove_resets() perform keep_last_value() implicitly?
other than that question, it's OK to close this bug-- sorry for the noise
belm0
on 19 Nov 2020
increase(m[d]) is e.g. range function, i.e. it performs calculations over underlying data points on the time range [d] before each returned data point. The underlying datapoints are usually read from the database, but they can also be calculated when subqueries are used. If the [d] is missing inside increase() or any other range function, then VictoriaMetrics automatically puts [step] there, where step is obtained from query arg passed to /api/v1/query_range. Grafana automatically calculates and passes step query arg to VictoriaMetrics depending on graph size and its settings.
remove_resets(m) isn't a range function, i.e. it performs calculations on calculated datapoints returned from range function. If range function is missing, then last_over_time() range function from MetricsQL is implicitly used. I.e. remove_resets(m) is equivalent to remove_resets(last_over_time(m)).
When VictoriaMetrics calculates range function results, then it automatically detects interval between data points per each time series (this interval is named scrape_interval in Prometheus terms). The detected interval is then used for determining the start of time series gap (aka staleness calculations). VictoriaMetrics considers that the gap starts if it has no data points for up to 2x scrape_interval. This gives good (expected) results for time series with almost constant interval between data points. Prometheus and VictoriaMetrics data model works the best for such time series. If the interval between data points in a time series varies significantly, then results can be unexpected, since VictoriaMetrics may improperly determine scrape_interval. It is likely that you hit this case.
valyala
on 19 Nov 2020
Thank you for the explanations, I'm still learning.
If the [d] is missing inside increase() or any other range function, then VictoriaMetrics automatically puts [step] there
I raised it previously, but it's usually a trap for a novice query author. If he writes increase(metric), it's likely he wants the increase over the query range, and isn't aware that increase() is a range function that considers a window of history for each point. And in that case, [step] is almost certainly not what he wants. Since there is no error, he'll just be puzzled why the query output is not as expected.
I think here, explicit is better than implicit. It's better to not automatically insert [step], and raise an error, so that the user can correctly learn what the function expected input is, and why. PQL got this part right.
This gives good (expected) results for time series with almost constant interval between data points.
The original increase() function as well as remove_resets() should be considered in the context of counter resets. Resets typically happen when a scrape target is restarted. Some systems have a long initialization time, so these events could exceed 2x scrape interval.
So in practice, if someone is using remove_resets(), they may need to wrap it in keep_last_value(). Since remove_resets is holding the state of a series even when the input disappears, I don't know why it doesn't just output the that state implicitly in all cases (without needing keep_last_value()).
belm0
on 19 Nov 2020
It's better to not automatically insert [step], and raise an error, so that the user can correctly learn what the function expected input is, and why. PQL got this part right.
Both cases have their pros and cons. I agree with your arguments on why explicit [window] for range queries is better than implicit. But if you look at PromQL queries for typical Grafana dashboard, then you'll notice many [$__interval] occurrences in these queries like rate(metric[$__interval]), increase(metric[$__interval]), etc. MetricsQL allows simplifying such queries to just rate(metric) or increase(metric). Moreover, many users don't understand how [window] works and why it is needed - they just copy'n'paste [$__interval] or [5m] there.
Unfortunately it is impossible to make [window] non-optional inside range functions now, since this will break existing MetricsQL queries.
Resets typically happen when a scrape target is restarted. Some systems have a long initialization time, so these events could exceed 2x scrape interval.
If the reset exceeds 2x scrape interval, then it will be visible as a gap on graph. This is expected and well understood behavior for Prometheus data model.
I don't know why it doesn't just output the that state implicitly in all cases (without needing keep_last_value()).
Because remove_resets() is non-range function. All the non-range functions in PromQL (and MetricsQL) leave gaps if the source data has gaps.
valyala
on 19 Nov 2020
maybe I understand, there are the function types:
- no input - e.g.
pi() - aggregating - reduces the number of series e.g.
sum() - instant vector - applies function to a vector of data points, e.g.
remove_resets() - range vector - applies function to a vector of vectors, e.g.
rate()
remove_resets(metric) is somehow underspecified, because it doesn't say which raw data points of metric will be processed. So it implicitly becomes remove_resets(last_over_time(metric)) --> remove_resets(last_over_time(metric[step])), which effectively means a sampling of data points suitable for the display resolution.
belm0
on 20 Nov 2020
I think here, explicit is better than implicit. It's better to not automatically insert
[step], and raise an error, so that the user can correctly learn what the function expected input is, and why. PQL got this part right.
My 2 cents: Not requiring a range vector, and VM dynamically using [step] has simplified writing queries tremendously for my users. It's one less decision to make, and a convention over configuration approach that satisfies 95% of use cases - 1 big reason for me to switch to VM.
 raags
on 20 Nov 2020
raags
on 20 Nov 2020
Related issues
 genericgithubuser
·
4Comments
genericgithubuser
·
4Comments
 prdatur
·
3Comments
valyala
·
4Comments
prdatur
·
3Comments
valyala
·
4Comments
 isality
·
3Comments
isality
·
3Comments
 jelmd
·
3Comments
jelmd
·
3Comments
Most helpful comment
maybe I understand, there are the function types:
pi()sum()remove_resets()rate()remove_resets(metric)is somehow underspecified, because it doesn't say which raw data points ofmetricwill be processed. So it implicitly becomesremove_resets(last_over_time(metric))-->remove_resets(last_over_time(metric[step])), which effectively means a sampling of data points suitable for the display resolution.