Vector: Metrics routing and fast path to integrate Vector
First of all, Vector is an amazing tool and we found a huge value on Logs which helps us a lot but we love to see integration with Tracing and Metrics on the same level.
As for now moving to Vector with metrics is very hard. For me the main issues that stop me from mowing for example from Telegraf in a metrics layer.
Metrics routing:
- lack of sources that support - only Prometheus and statsd sources
- Some issues exist that statsd source does not support fully DogStatsd format
- lack of generic HTTP source or other specific sources that supports internal parsers to many formats - something similar as Telegraf have - https://github.com/influxdata/telegraf/tree/master/plugins/parsers
- lack of aggregations and more features focused on metrics processing inside transformations - same here with Telegraf https://github.com/influxdata/telegraf/tree/master/plugins/aggregators
- lack processors in transformations https://github.com/influxdata/telegraf/tree/master/plugins/processors
Idea:
We could parse data from any agent, for example, proxy Datadog Agent metrics traffic (that one that originally goes to Datadog endpoints) or Telegraf specified format into Vector HTTP/HTTPs source and transform data from existing infrastructure, routing through Vector to another store with full transformations on the path.
We will be able to move existing infrastructure also start slow migration to Vector native when they come in.
Another Idea:
Allow passing through statsd metrics without any aggregation like original values - for example, statsd in Dogstasd format metrics pass on the source and then deliver them through Vector to Kafka and do the aggregation on the Vector reading from Kafka that will just write aggregated data from multiple agents to destination store.
Also, any static sharding is a nice idea here to have always guarantee that specific metric type always goes to the same Vector agent that send to the vendor store.
Now we can do something similar using simple sidecar https://github.com/jjneely/statsrelay which will have static sharding to for example Vector agents, but we miss here Kafka transport layer (before aggregation) in a huge setup and lack of some features in Vector statsd/transformations to enrich tags.
But have the ability to pass through from the beginning vector and enrich tags for example from aws_ec2_metadata and more static values would be awesome and send it to Kafka pipe on other Vector get from Kafka and aggregate by transformations before final storage write, based on defined intervals. We will then have all histograms, percentiles calculated from all for example service pods in k8s as one service. We will lose some information about source tags. dimensions but we can send fewer data aggregated in high throughput traffic.
Metrics inputs:
- source that can be used as external exec command that on stdout report metric in the format accepted to parse to Vector internal metrics format same as on HTTP source for ingesting metrics.
This is minimal to start moving into Vector and the next step is to introduce internal Vector inputs and slowly add more native integrations. To have as many native integrations comparing to that from DatadogAgent or Telegraf will take time but we can make Vector very elastic to integrate with the third party much before.
 szibis
szibis
All 6 comments
Hi @szibis, thanks for the thoughtful feedback. It's very valuable to us and we appreciate you taking the time to share.
Vector is an amazing tool and we found a huge value on Logs which helps us a lot but we love to see integration with Tracing and Metrics on the same level.
❤️ - and I agree about Vector's metrics support! Metrics development has been on a slow pace and we plan to address that in the near term. Multiple people on the team will be focusing on that within the next month. Broadly speaking, we plan to solve the basics first: more fundamental metrics integrations and server-level metrics collection. Then we'll develop a maturity plan and prioritize. We'll definitely be looking to Telegraf as a baseline.
Some issues exist that statsd source does not support fully DogStatsd format
Do you have more info here? I thought we might have solved this in https://github.com/timberio/vector/pull/1263. We probably need to perform an audit on this.
lack of generic HTTP source
Good point, we've discussed how we would support metrics in the http source, but the solution was never clear. A few questions for you:
- How would you envision this working for metrics?
- Have you seen CloudWatch's embedded metrics format? I'm curious if that's what you're thinking?
- Would a GRPC source be better for you? That would expose Protobufs describing our metrics schema.
other specific sources that supports internal parsers to many formats
Agree, we'll prioritize this as I think it's fundamental to supporting metrics.
lack of aggregations and more features focused on metrics processing inside transformations
Agree!
lack processors in transformations
We'll audit these. Are there any in particular that you need?
source that can be used as external exec command that on stdout report metric in the format accepted to parse to Vector internal metrics format same as on HTTP source for ingesting metrics.
This is interesting. It's very similar to https://github.com/timberio/vector/issues/992.
@szibis, we plan to focus on metrics features in the near term and will reference this issue for our planning. It's likely that we'll focus first on more integrations, then server-level collection of metrics, and then improving our transforms. But we'll be sure to tag in anything relevant. Thanks again.
 binarylogic
on 30 Apr 2020
binarylogic
on 30 Apr 2020
Good point, we've discussed how we would support metrics in the HTTP source, but the solution was never clear. A few questions for you:
How would you envision this working for metrics?
Have you seen CloudWatch's embedded metrics format? I'm curious if that's what you're thinking?
Would a GRPC source be better for you? That would expose Protobufs describing our metrics schema.
For me and for most of the integrations, we need a simple HTTP server source like that one in Telegraf - https://github.com/influxdata/telegraf/tree/master/plugins/inputs/http_listener_v2 and also in future, we may like to have pull HTTP input for some endpoints.
Also, this needs to support various data format parsers. Same as HTTP sink - https://github.com/influxdata/telegraf/tree/master/plugins/outputs/http and this output I would like to integrate with Vector HTTP source for metrics and also may be useful for Logs and other like tracing and here also an example.
We can use the feature in Datadog agent and set Vector as proxy endpoint and pass through Vector all Logs, Metrics and Traces in future - https://docs.datadoghq.com/agent/proxy/?tab=agentv6v7
This allows us to use all Vector features like Kafka Pipeline from Vector -> Vector and at the end send data to proper sinks also all additional transformations and for example, more advanced log2metrics feature.
For logs now DD agents use also HTTPS (as I mention in https://github.com/timberio/vector/issues/2504) also for Metrics and Traces.
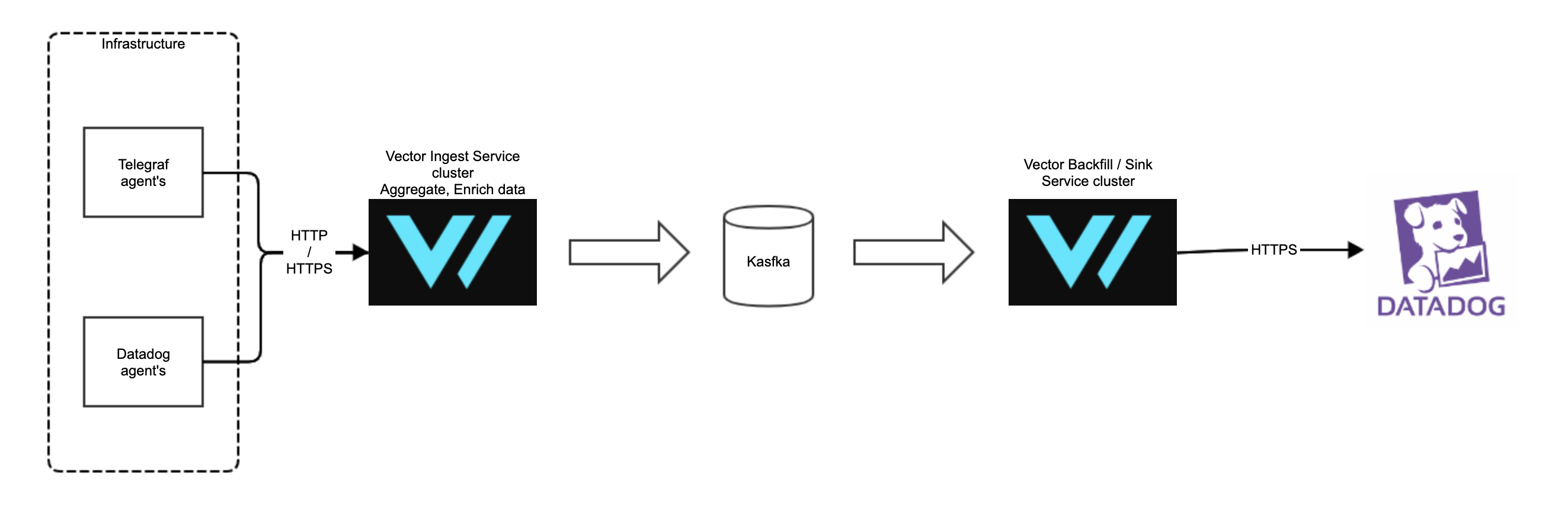
In the future, as you mention more internals from Vector exposed inside this or another HTTP source with GRPC or other features (or maybe Vector specific source) would be a nice addition. But now we can Fast integrate Vector and start moving internal sources for metrics and custom collectors from inside of Telegraf also we can use Datadog Agent and enrich data in Vector also making them even more valuable with Kafka pipeline as scaling and buffer/backfill feature.
Do you have more info here? I thought we might have solved this in #1263. We probably need to perform an audit on this.
We will test it still no time to make full tests of this.
We'll audit these. Are there any in particular that you need?
For Transformations, we would like to have most of the features now available for metrics to have the ability to change tags, fields, measurements (regexp match/replace, add tags, remove, rename, split some keys or values, overwrite some keys from other values or generate new one fro mother, add from env variables) also aggregate particular fields (aggregate fields data in metrics with various options - percentiles, histograms, min, max, avg and more in specific time window) of data and some not (just pass through), dynamically generated tags from ec2_metadata and from ec2_tags. Groups some tags based on pattern and replace matched patterns with some strings - for example, if we have a random URI path in tags we can replace some patterns with same strings (with _some_id) and have grouped URI to have less cardinality on metrics and usable flow.
I think we can ad some because I don't remember right now all options we use.
This is interesting. It's very similar to #992.
For the exec minimal scope for me is to run the source command (script) in intervals that will produce any supported internal metrics format as the output. we will have metrics inside the Vector structure ready to go through the pipelines with support for all format and vector features.
Also, Telegraf now implements a nice feature https://github.com/influxdata/telegraf/tree/master/plugins/inputs/execd this feature saves some resources by not running the script on intervals just make it daemon like with reloads on signals and read from stdout.
szibis
on 8 May 2020
@szibis thank you again for this wonderful feedback. We've broken this down into a metrics roadmap which will be our main focus over the next month or so. Would you be interested in chatting with our team about it? We'd love to pick your brain on some ideas we have and make sure we're focused on the right changes. If so, feel free to email me at [email protected]. Would love to set something up, or even setup a shared Slack channel if that's easier. Thanks!
binarylogic
on 24 Aug 2020
@jamtur01 can you close this once the feedback is broken down into epics/issues?
binarylogic
on 31 Aug 2020
@szibis thank you again for this wonderful feedback. We've broken this down into a metrics roadmap which will be our main focus over the next month or so. Would you be interested in chatting with our team about it? We'd love to pick your brain on some ideas we have and make sure we're focused on the right changes. If so, feel free to email me at [email protected]. Would love to set something up, or even setup a shared Slack channel if that's easier. Thanks!
@binarylogic I send you back email for any contact to talk.
szibis
on 15 Sep 2020
This has been broken into issues.
 jamtur01
on 26 Oct 2020
jamtur01
on 26 Oct 2020
Related issues
 valyala
·
3Comments
valyala
·
3Comments
 Hoverbear
·
3Comments
Hoverbear
·
3Comments
 a-rodin
·
3Comments
binarylogic
·
4Comments
a-rodin
·
3Comments
binarylogic
·
4Comments
 LucioFranco
·
3Comments
LucioFranco
·
3Comments
Most helpful comment
For me and for most of the integrations, we need a simple HTTP server source like that one in Telegraf - https://github.com/influxdata/telegraf/tree/master/plugins/inputs/http_listener_v2 and also in future, we may like to have pull HTTP input for some endpoints.
Also, this needs to support various data format parsers. Same as HTTP sink - https://github.com/influxdata/telegraf/tree/master/plugins/outputs/http and this output I would like to integrate with Vector HTTP source for metrics and also may be useful for Logs and other like tracing and here also an example.
We can use the feature in Datadog agent and set Vector as proxy endpoint and pass through Vector all Logs, Metrics and Traces in future - https://docs.datadoghq.com/agent/proxy/?tab=agentv6v7
This allows us to use all Vector features like Kafka Pipeline from Vector -> Vector and at the end send data to proper sinks also all additional transformations and for example, more advanced log2metrics feature.
For logs now DD agents use also HTTPS (as I mention in https://github.com/timberio/vector/issues/2504) also for Metrics and Traces.
In the future, as you mention more internals from Vector exposed inside this or another HTTP source with GRPC or other features (or maybe Vector specific source) would be a nice addition. But now we can Fast integrate Vector and start moving internal sources for metrics and custom collectors from inside of Telegraf also we can use Datadog Agent and enrich data in Vector also making them even more valuable with Kafka pipeline as scaling and buffer/backfill feature.
We will test it still no time to make full tests of this.
For Transformations, we would like to have most of the features now available for metrics to have the ability to change tags, fields, measurements (regexp match/replace, add tags, remove, rename, split some keys or values, overwrite some keys from other values or generate new one fro mother, add from env variables) also aggregate particular fields (aggregate fields data in metrics with various options - percentiles, histograms, min, max, avg and more in specific time window) of data and some not (just pass through), dynamically generated tags from ec2_metadata and from ec2_tags. Groups some tags based on pattern and replace matched patterns with some strings - for example, if we have a random URI path in tags we can replace some patterns with same strings (with _some_id) and have grouped URI to have less cardinality on metrics and usable flow.
I think we can ad some because I don't remember right now all options we use.
For the exec minimal scope for me is to run the source command (script) in intervals that will produce any supported internal metrics format as the output. we will have metrics inside the Vector structure ready to go through the pipelines with support for all format and vector features.
Also, Telegraf now implements a nice feature https://github.com/influxdata/telegraf/tree/master/plugins/inputs/execd this feature saves some resources by not running the script on intervals just make it daemon like with reloads on signals and read from stdout.