Vector: Harmonize event field accessor formatting
Currently Vector has robust JSON support, and also robust field flattening. However the way those interact across Vector can be a bit disorienting!
Overview
While the examples below highlight add_fields this problem is consistent across Vector.
Docs
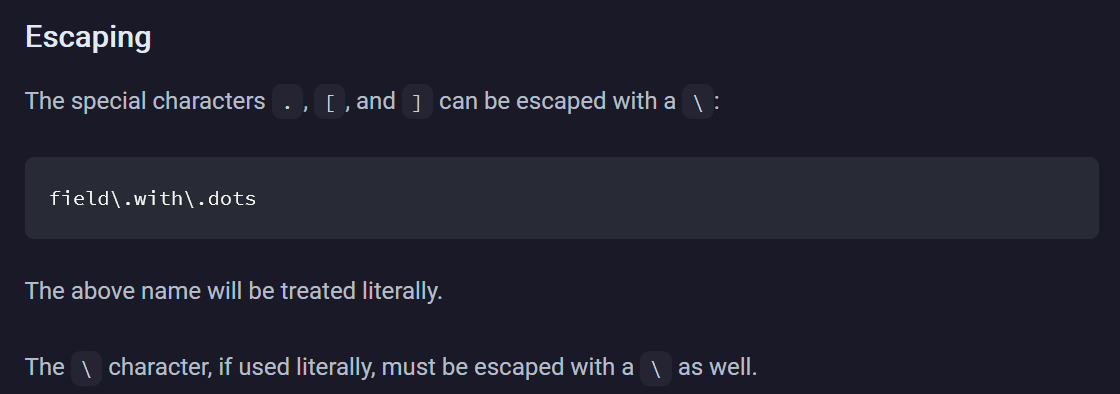
Our docs do exist on this topic, however they are not exhaustive. It does not describe escaping or some edge cases.
https://vector.dev/docs/about/data-model/log/#dot-notation
Our docs do describe how to access fields using escaping on https://vector.dev/docs/reference/field-path-notation/#escaping
Perhaps a good first step is linking these pages more clearly.
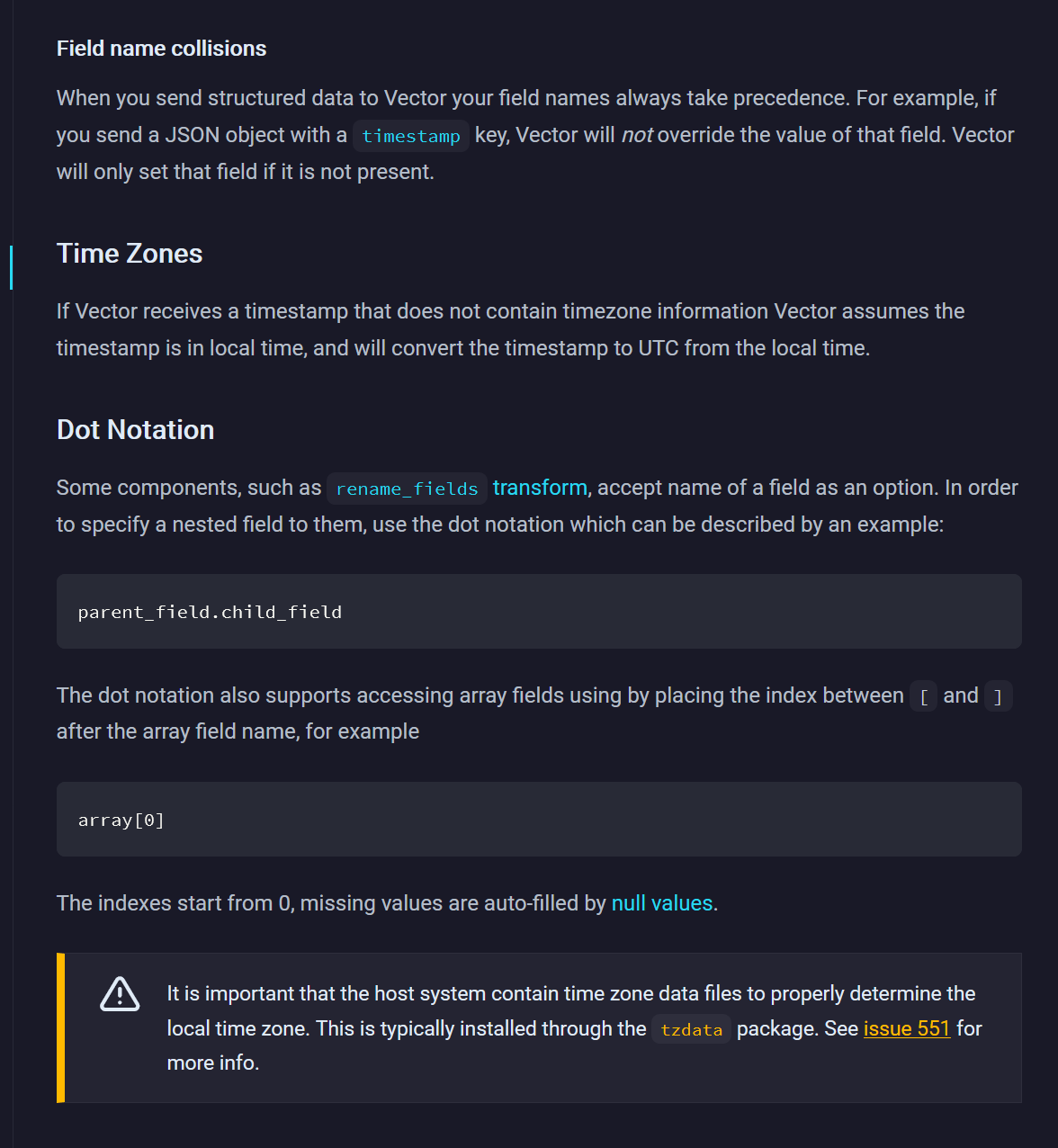
Table Fields with .s
Imagine an incoming JSON log:
{
"a": { "b": { "c": 0 } },
"a.b": { "c": 0 },
"a.b.c": 0,
}
Here you can see for add_fields inserting "a.b" is the same as inserting a.b:
Array-looking table fields
Imagine an incoming JSON log:
{
"a": [{
"b": [[{
"c": 0
}]],
}],
"a[0]": {
"b": [[{
"c": 0
}]],
},
"a[0].b": [[{
"c": 0
}]],
"a[0].b[0]": [{
"c": 0
}],
"a[0].b[0][0]": {
"c": 0
},
"a[0].b[0][0].c": 0
}
Here you can see that add_fields doesn't make much of a distinction either.
Resolution
The resolution of this issue requires a specification. We should come up with a good way to let users express and work with these fields.
Particular care should be paid to how these changes reflect in our behavior tests and in both casual/normal use as well as those cases detailed above.
Possible areas to explore::
- Use JSON pointers for field names exclusively: https://tools.ietf.org/html/rfc6901
- JSON reference: https://json-spec.readthedocs.io/reference.html
- Similar syntax to the JQ tool: https://stedolan.github.io/jq/
 Hoverbear
Hoverbear
All 6 comments
@binarylogic @lukesteensen Can you help spec this? I know you have opinions.
Hoverbear
on 15 Apr 2020
Docs for Benthos, which uses an adapted version of JSON pointers: https://www.benthos.dev/docs/configuration/field_paths
JSON pointers are great because they're explicit, unobtrusive and also easy to parse. The problem with it is that it's different to what users will expect. For the doc:
{
"foo": {
"bar": "baz"
}
}
999999.9% of users will reach for foo.bar as it's consistent with JS and most other tools. In JSON pointers this is /foo/bar. In Benthos I made two changes in order to support foo.bar:
- Changed the separator to
., this is harmless to the spec as it's an arbitrary character. - Removed the prefixing separator, so that
.foo.barbecomesfoo.bar.
The key reason for the prefix is that it makes it possible to query:
{
"": "bar"
}
Which in the case of Benthos I was more than content with not supporting.
Changing to this spec would be backwards compatible for the vast majority of existing configs. We would need clear documentation regarding the escape sequences ~0 and ~1 as they're not common and most users will have never seen/used it.
One major problem with JSON pointers is that it's primarily aimed at querying data, and therefore indexes are implicit (just a number), and therefore the array must already exist in the object as a reference point.
When mutating data it's therefore possible to express a desire to:
- set an element in an array (
foo.bar.1 = "baz") - append an element to an array (
foo.bar.- = "baz")
But it is NOT possible to express with a path that you wish to create a new array containing an element, in that case an object would be created with a key matching the specified index.
For the purposes of our transforms I think that's acceptable, and in a case where arrays need to be constructed we can support that in other (more appropriate) ways.
 Jeffail
on 15 Apr 2020
Jeffail
on 15 Apr 2020
@Hoverbear
It does not describe escaping or some edge cases.
The docs describe escaping here: https://vector.dev/docs/reference/field-path-notation/#escaping.
 a-rodin
on 15 Apr 2020
a-rodin
on 15 Apr 2020
@a-rodin Nice! I Missed that, I've added that above.
Hoverbear
on 15 Apr 2020
I only have a few small opinions here and strongly defer to those with more experience building these things (e.g. @Jeffail and @a-rodin).
That said, my opinions are roughly as follows:
- The _vast_ majority of users are only going to use simple
foo.bar-style paths. Making these easy to understand and unambiguous with respect to nesting should be the priority. - Array support is a real bummer and also an extremely niche use case. It's totally fine if we don't support every possible thing, and we probably shouldn't if it helps keep things simple for the majority of users. If you need to do something fancy with arrays, you're likely better off using something like Lua anyway.
- Leaning on an existing spec seems like a great idea, mostly so we can spend less time thinking through these edge cases ourselves. My preference would likely be to match
jq, since it seems to best match our use case (i.e. both querying and construction/assignment) but I worry it might be more complex than we need. I would also be perfectly happy with the adapted version of JSON pointers used by Benthos.
 lukesteensen
on 16 Apr 2020
lukesteensen
on 16 Apr 2020
I agree with @lukesteensen. I'd like to add a few points as well:
I do not want to conflate the TOML syntax with the data structure we expect users to provide. To clarify, it is possible we'll support YAML in the future. Would we want users to supply nested YAML structures to insert fields? I'm indifferent, but thinking about this through YAML lens helps to separate the concerns.
How do hybrid structures work? What if a user did this?
[transform.add_fields] type = "add_fields" fields.ec2."container.id" = "abcd1234"At first glance, I would expect the quoting means that the key is literal, but it is not.
As @lukesteensen said, 99.9% of cases will be simple
foo.barstyle paths. We should make this simple and hard to mess up.
From a consistency and simplicity standpoint, I'm leaning towards requiring quotes and not allowing the nested TOML syntax. I'm curious what others thing about my example in point 2.
 binarylogic
on 16 Apr 2020
binarylogic
on 16 Apr 2020
Related issues
 LucioFranco
·
3Comments
LucioFranco
·
3Comments
 trK54Ylmz
·
3Comments
LucioFranco
·
3Comments
a-rodin
·
3Comments
trK54Ylmz
·
3Comments
LucioFranco
·
3Comments
a-rodin
·
3Comments
 MOZGIII
·
3Comments
MOZGIII
·
3Comments