Vector: Strategy device_and_inode does not work properly
Hi
vector version 0.8.2
I have few logs files, for example:
$ ls
logfile_json.log
logfile_json.1
logfile_json.2
logfile_json.3
When logfile_json.log reaching 100MB it will be renamed to logfile_json.1 as well as other log files to next number.
Also, my vector config:
[sources.in_logs]
type = "file"
include = ["/var/log/myapp/logfile_json*"]
exclude = ["*gz"]
glob_minimum_cooldown = 1000
ignore_older = 86400
max_read_bytes = 4096
[sources.in_logs.fingerprinting]
strategy = "device_and_inode"
When vector starts - it detects all files and starts to read each of them and saves offsets properly.
I checked inode number after renaming - new file gets new inode, renamed file saves his inode.
Also, after renaming files vector detects changes and logs new_path and old_path properly.
However, vector does not read logs from those files, that were detected by device_and_inode strategy.
debug log level did not clarify situation, because renaming detection shows even in info log level
After changing strategy to checksum it works well.
Ask me to provide something else, if you will need more information.
 mikhno-s
mikhno-s
All 14 comments
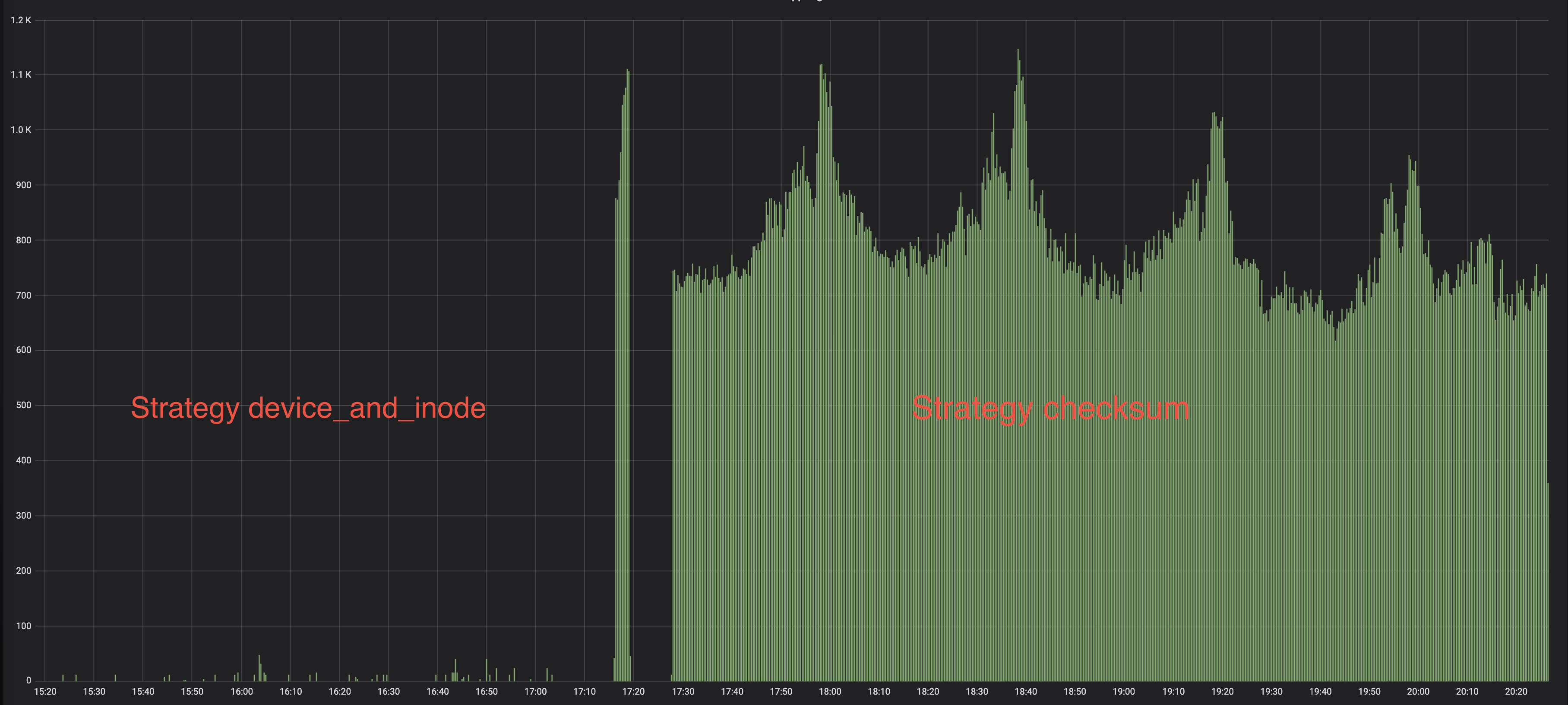
Read logs count before and after changing strategy
mikhno-s
on 27 Mar 2020
Thank you for the detailed issue @mikhno-s! Our behavior definitely shouldn't vary like that between different fingerprinting strategies.
Do you see the same behavior from device_and_inode if you set start_at_beginning = true?
 lukesteensen
on 27 Mar 2020
lukesteensen
on 27 Mar 2020
What FS and OS is this on? I know some OS (like Windows) have some strange semantics around moving files.
 Hoverbear
on 30 Mar 2020
Hoverbear
on 30 Mar 2020
@Hoverbear it's linux - timberio/vector:0.8.2-debian
mikhno-s
on 30 Mar 2020
Cool! Thanks! And this file is on an EXT4 filesystem? Is it a docker volume? Which Docker driver are you using? (https://docs.docker.com/storage/storagedriver/select-storage-driver/)
Hoverbear
on 30 Mar 2020
@Hoverbear Actually there are few kubernetes clusters (gke and self-deployed), with overlay2 as storage driver.
mikhno-s
on 31 Mar 2020
@mikhno-s what file system is used on the k8s nodes for /var/log/pods/* (at the host, not inside the docker container)? It's most likely either ext4 or xfs. If it's overlayfs2, 99% chance you're looking at the wrong place.
 MOZGIII
on 28 May 2020
MOZGIII
on 28 May 2020
@MOZGIII docker - overlay2, ext4 - host
mikhno-s
on 29 May 2020
We've been busy adding first-class integration with k8s. There's a new kubernetes_logs source, and we made sure to address the issue you've encountered here in that source. More specifically, we're using a new implementation of the fingerprinter that checksums just the first line.
We're going to ship this in the next release (0.11).
MOZGIII
on 8 Aug 2020
We write logs to files to hostDir volume (mounted to host filesystem) and then vector also has that hostDir volume in pod definition. We don't use standard stdout and stderr to write logs from pod.
In last version (0.10) it has been still happening.
Vector detects new files after rotation, but does not read them. (file_position=0)
Have returned all sources to checksum strategy.
mikhno-s
on 10 Sep 2020
We're implemented https://github.com/timberio/vector/pull/2904 specifically for use within out kubernetes_logs source (we're going to ship it in the next release). You can check the relevant issue with the discussion here: https://github.com/timberio/vector/issues/2890
It's not available in the file source, this is tracked at https://github.com/timberio/vector/issues/2926.
We're also working on architectural improvements, and those should help with this issue.
The quickest remediation/workaround I see right now is to use the kubernetes_logs source in nightly. Have you tried it?
MOZGIII
on 15 Sep 2020
No, because it's not our case.
Because architecturally we have logs system out of kubernetes. I mean, that apps write logs to files (that are written to dir mounted to host), not to stdout, as usual k8s apps. And vector reads that files, because vector runs in host namespace.
mikhno-s
on 16 Sep 2020
I see, that is unfortunate. Well, add your :+1: and subscribe to https://github.com/timberio/vector/issues/2926 - it looks like solving that issue would be the quickest fix we can do for this matter in the near future. Does it look like it'll solve your issue?
MOZGIII
on 16 Sep 2020
Yes. If we get such option - it will be extremely cool!
Our case - we have huge stacktraces in the logs, and it's usual thing, when first hundreds or even thousands bytes the same for such files, because those stacktraces are the same.
So, I am voting for a function (as I rightly understood) which calculates checksum using whole first line.
mikhno-s
on 21 Sep 2020
Related issues
 raghu999
·
3Comments
raghu999
·
3Comments
 jamtur01
·
3Comments
jamtur01
·
3Comments
 leebenson
·
3Comments
Hoverbear
·
3Comments
leebenson
·
3Comments
Hoverbear
·
3Comments
 LucioFranco
·
3Comments
LucioFranco
·
3Comments