Vapor: Persistent issues with graceful server shutdown on multiple platforms
It seems that in Vapor 4.30.0 I can't stop the app by pressing Ctrl+C in console.
It just shows ^C and doing nothing. After several attempts I decided to downgrade to 4.29.1 and Ctrl+C works fine on it.
To make sure my theory I updated back to latest 4.30.0 and Ctrl+C is broken again here.
Steps to reproduce
- define
.exact("4.30.0")for vapor package inPackage.swift - run
swift package update && swift run - try to terminate the app by pressing
Ctrl+Cand see that it just prints^Con the screen - then define
.exact("4.29.1")for vapor package inPackage.swift - run
swift package update && swift run - try to terminate the app by pressing
Ctrl+Cand it terminates the app
Expected behavior
Ctrl+C should terminate the app
Actual behavior
It just prints ^C on the screen and doesn't terminate the app
Environment
- Vapor Framework version: 4.30.0
- Vapor Toolbox version: n/a
- OS version: Ubuntu 20.04
- Swift version: swift-5.2.5-RELEASE
 MihaelIsaev
MihaelIsaev
All 78 comments
@tanner0101 I was able to recreate this as well on all supported Ubuntu versions 16.04, 18.04 and 20.04 with Swift 5.25 and Swift 5.3. Furthermore, CTRL-C in 4.31.0 displays the prompt without actually terminating the process. Running ps after CTRL-C will show you the process continuing to run in the background. This can also be confirmed by attempting to run the server again on the same port after CTRL-C, which will result in an Address already in use (errno: 98) error. I don't think this has to do with an earlier similar error which was triggered by open web sockets. Graceful shutdown seems to have been broken somewhere since that fix and for a different reason this time.
Whatever is triggering this may also explain an unexplained error that I and a minor handful of other people also seem to be having on the Mac. Previously, I randomly received a -1 exit status code instead of the typical 9 exit status code I received from Xcode when terminating the project. When that happens, the LLDB debugger cites an RPC server issue, without offering any further details. I have to manually terminate the Run process in order to be able to run the server again on the same IP:port combination with the -b option. Now, it happens each and every time I run the project.
 fouadhatem
on 4 Oct 2020
fouadhatem
on 4 Oct 2020
Here is lines from supervisord.log when I tried to stop Vapor 4.29.4 on Ubuntu 18.04:
2020-10-05 09:57:02,268 INFO waiting for vapor to stop
2020-10-05 09:57:02,291 INFO stopped: vapor (exit status 0)
and Vapor 4.30.0:
2020-10-05 09:56:23,286 INFO waiting for vapor to stop
2020-10-05 09:56:25,286 INFO waiting for vapor to stop
2020-10-05 09:56:27,286 INFO waiting for vapor to stop
2020-10-05 09:56:29,286 INFO waiting for vapor to stop
2020-10-05 09:56:31,286 INFO waiting for vapor to stop
2020-10-05 09:56:33,286 WARN killing 'vapor' (25243) with SIGKILL
2020-10-05 09:56:33,286 INFO waiting for vapor to stop
2020-10-05 09:56:33,294 INFO stopped: vapor (terminated by SIGKILL)
It seems that vapor doesn't accept/listen the SIGTERM signal.
 Maxim-Inv
on 5 Oct 2020
Maxim-Inv
on 5 Oct 2020
@MihaelIsaev I suggest you rename the topic of this issue to: Persistent issues with graceful server shutdown on multiple platforms.
fouadhatem
on 6 Oct 2020
This is baffling. I just tried the following:
I built a skeleton project on a laptop running a desktop version of Ubuntu 20.04 with 4GB of memory and graceful shutdown worked fine each time.
I ran the same skeleton project on a 2019 MacBook Pro with 16GB of memory running Catalina and the project terminates just fine on Xcode with exit code 9 and not with a -1 and an RPC server failure as I consistently get on my own MacBook (2013 MacBook Air with 4GB of memory running Catalina).
When I ran the steps above to reproduce the error that @MihaelIsaev filed the issue for, I was able to reproduce it each time with the following setup: I am running VMWare on my MacBook Air (4GB of RAM). The tests were conducted on Ubuntu Server VMs (varying flavors) with 1 processor core and 1GB of RAM for each VM. The running process could not be terminated with
CTRL-Cor withkill <PID>. It could only be killed withkill -9 <PID>. Attempting to build and run again on those VMs result in the same scenario and needed anotherkill -9to end the process.Today, I picked one of these VMs, added a processor core and 1GB of RAM to its existing configuration and ran the same skeleton project and it initially failed to gracefully shut down. However, after only one
kill -9and a 2nd attempt to run, it terminated fine and continued to do so even after I rebooted the VM. Here's the kicker, shrinking the VMs config back down to 1 processor core and 1GB of RAM seemed to cause the same issue to recur again.
This might be a problem that is specific to my machine, or it might indicate a pattern where running Vapor on machines with specific configurations results in this kind of behavior. The only variations I can think of are limited memory or processing capability, with my hunch leaning more towards memory issues and could potentially be related to #2493 .
This might explain why @tanner0101 and @0xTim were unable to reproduce these errors, as they are probably using far more capable Macs with generous helpings of memory and abundant processing power. Also, reporting of similar errors were sporadic and far between and were easy to miss or ignore as they may not have been widespread, which leads me to believe that this may be the case, unless I'm missing something.
@Maxim-Inv and @MihaelIsaev can you please share the configurations of your computers/VMs that you were using to reproduce these errors?
fouadhatem
on 7 Oct 2020
@fouadhatem Thank you for the investigation!
I'm not able to reproduce it on macOS, Ctrl+C works here. My machine is MacBook Pro 2017 15" 16Gb RAM.
My Ubuntu server is 1Gb cheapest machine on DigitalOcean with Ubuntu 20.04. When I run my app there are 800Mb of free RAM.
MihaelIsaev
on 7 Oct 2020
So the issue appears on your DigitalOcean VM running on 1GB of RAM? What kind of processing power does it have and how many cores does it give you?
fouadhatem
on 8 Oct 2020
Alright I'm now pretty sure that this is a resource allocation issue, most likely some kind of memory management problem. I decided to test this in a more standardized approach, using EC2 instances on AWS. Below are the details of the test:
Methodology
I created 4 instances with the following configurations:
Ubuntu 20.04 Server instance with 1 processor and 1GB of RAM.
Ubuntu 20.04 Server instance with 1 processor and 2GB of RAM.
Ubuntu 20.04 Server instance with 2 processors and 4GB of RAM.
Ubuntu 20.04 Server instance with 2 processors and 1GB of RAM.
All instances had 30GB of SSD storage. After updating each instance with apt update and apt upgrade, installing Swift 5.3 and its dependencies and the Vapor toolbox, I executed the following sequence of commands on each instance:
vapor new -n Mark1cd Mark1vapor buildvapor runCTRL-Cps// to see if theRunprocess is still there.vapor run// to see if we can run the server again afterCTRL-C. Do not proceed if successful.kill <PID>// to attempt to kill theRunprocess, if it's still running.ps// to see if we managed to kill it. Proceed if it still exists.kill -9 <PID>// to put a bullet between its eyes.ps// to make sure it's really dead this time.vapor runCTRL-Cps
Results
The results are below for each instance, showing you the screen from Step 4 onwards. Some steps were repeated on some instances for demonstration purposes:
One processor with 1GB of memory - failed to terminate
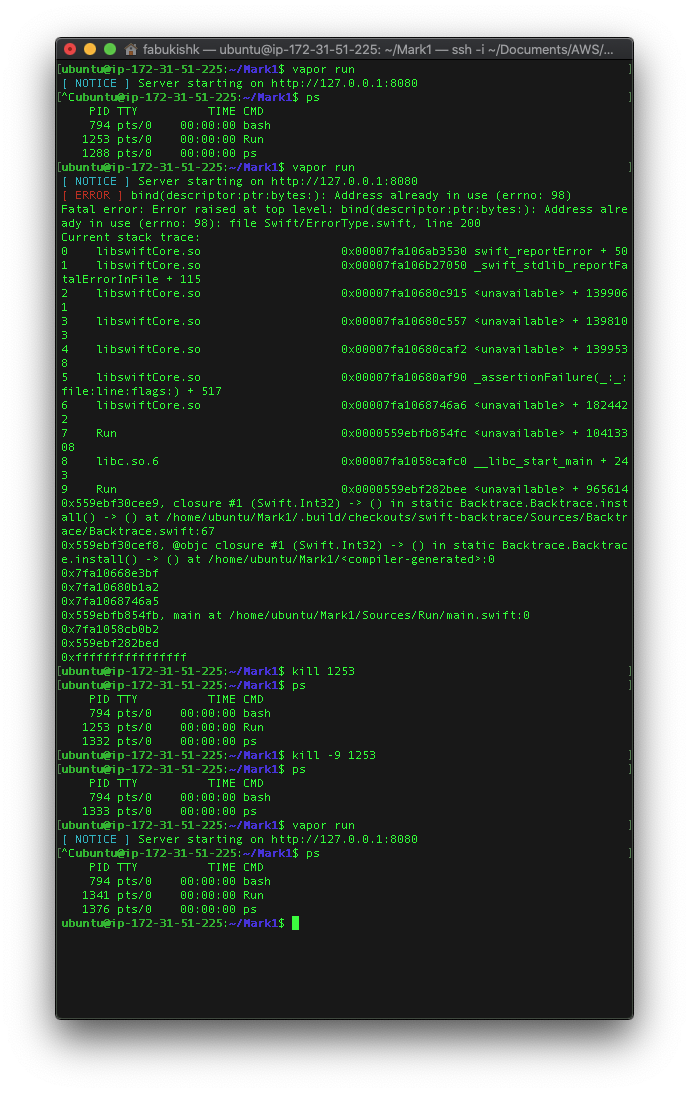
One processor with 2GB of memory - failed to terminate
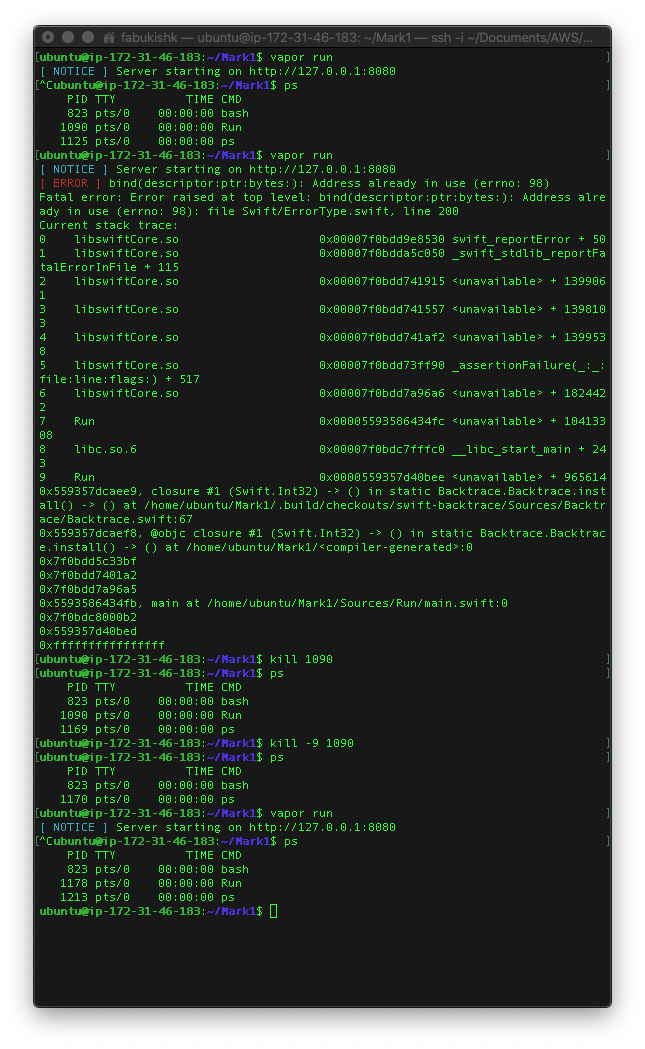
Two processors with 4GB of memory - successful
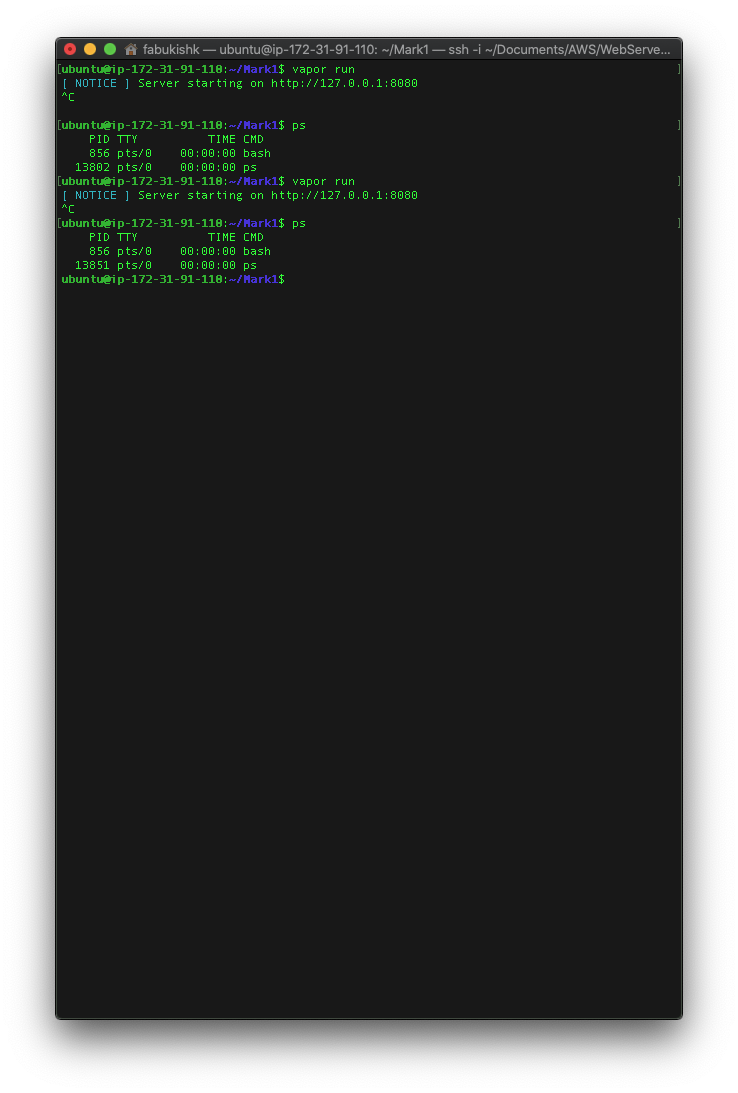
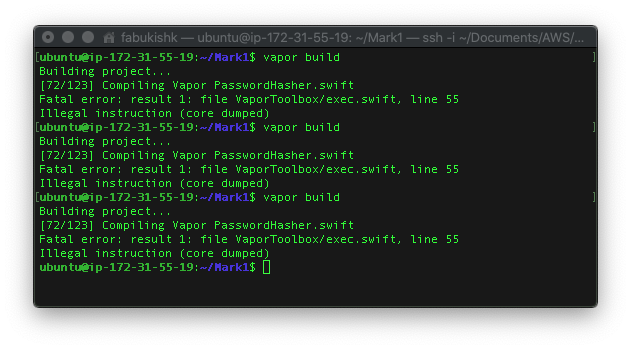
Two processors with 1GB of memory - fails to build project repeatedly
It kept failing at PasswordHasher.swift, even after a reboot.
Conclusion
I am able to reasonably conclude that this seemingly minor problem has uncovered some kind of resource management issue (most likely memory) with either Vapor or Swift-NIO, which could also be related to #2493 .
Hope this helps!
fouadhatem
on 8 Oct 2020
@fouadhatem Memory issue sounds weird since Vapor app eats only 12Mb of RAM 🤷♂️
I tested that theory with my apps on DigitalOcean by increasing resources of droplet from 1 to 5
1) Shared CPU 1 vCPU 1 GB RAM $5/mo (my regular droplet)
2) Shared CPU 1 vCPU 2 GB RAM $10/mo
3) Shared CPU 2 vCPUs 2 GB RAM $15/mo
4) Shared CPU 2 vCPUs 4 GB RAM $20/mo
5) Shared CPU 4 vCPUs 8 GB RAM $40/mo
Results:
1,2,3) Ctrl+C and kill failed, kill -9 works
4,5) Ctrl+C and kill works
So yeah, I can confirm that on VPS with more resources it works for some reason 🧐
MihaelIsaev
on 8 Oct 2020
@fouadhatem I encountered this issue on AWS t3.small server (2 vCPU, 2 GB RAM). And it works fine on the much more might server with 64 GB RAM.
Maxim-Inv
on 8 Oct 2020
@MihaelIsaev and @Maxim-Inv thanks for confirming the tests on Linux. The same issue seems to happen with me on my 2013 MacBook Air, which has 4GB of RAM. When I try it on a more capable Mac, the issue goes away. Does anyone have an older Mac lying around that we can test this with?
fouadhatem
on 8 Oct 2020
Just wanted to chime in that my iMac has a quad core i7 4.0 with 32 GB of ram. I have still randomly
encountered this issue. I also encountered it on my droplets, whether 1 vCPU or 2, 1 GB RAM or 4 GB RAM.
In my tests it seemed related to if the server received requests or not, but I was not able to confirm that.
I don’t think memory allocation is the issue.
On Oct 8, 2020, at 7:56 AM, Fouad Hatem notifications@github.com wrote:
@MihaelIsaev https://github.com/MihaelIsaev and @Maxim-Inv https://github.com/Maxim-Inv thanks for confirming the tests on Linux. The same issue seems to happen with me on my 2013 MacBook Air, which has 4GB of RAM. When I try it on a more capable Mac, the issue goes away. Does anyone have an older Mac lying around that we can test this with?
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub https://github.com/vapor/vapor/issues/2502#issuecomment-705548746, or unsubscribe https://github.com/notifications/unsubscribe-auth/AAL5QCON66NCBG3NTDXT6LDSJWZHFANCNFSM4SCR3XXA.
 jhoughjr
on 8 Oct 2020
jhoughjr
on 8 Oct 2020
@jhoughjr how long ago was this? There indeed was a previous issue with the server failing to shutdown when it had received requests (see #2451). This was resolved in 4.28.0. Could that be what you were referring to? That issue was not related to memory or resource capacities as this one seems to be.
fouadhatem
on 8 Oct 2020
I think I need to bring in some heavy guns over from Discord for this...
fouadhatem
on 9 Oct 2020
Okay so long story short, this seems to be a symptom of a larger and deeper problem that has to do partly with Vapor and partly with Swift-NIO. It is currently being evaluated by someone at Swift-NIO. Expect a PR to address this in the coming days (or weeks, depending on how deep it is).
fouadhatem
on 10 Oct 2020
I dont think I have seen it simce then but ive not been working on server much.
I can try this weekend to see if it still happens.
Sent from my iPhone
On Oct 8, 2020, at 11:10 AM, Fouad Hatem notifications@github.com wrote:
@jhoughjr how long ago was this? There indeed was a previous issue with the server failing to shutdown when it had received requests (see #2451). This was resolved in 4.28.0. Could that be what you were referring to? That issue was not related to memory or resource capacities as this one seems to be.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
jhoughjr
on 10 Oct 2020
Just to add a datapoint, I am consistently seeing this both in Xcode 12.0.1 and in Ubuntu 18.04 under Docker (Engine v19.03.13) on a 2017 1.4 GHz Dual-Core Intel Core i7 MacBook 12" with 8 GB RAM running macOS 10.15.4.
 mikecsh
on 10 Oct 2020
mikecsh
on 10 Oct 2020
@mikecsh yeah the issue seems to have been tracked down, at least partially. Both the Vapor and NIO teams need to sort it out.
It seems trivial at first, but this situation is actually like attempting to pull a seemingly harmless nail out of the wall in your living room, only to end up having your neighbor's bedroom on the other side of the wall flooded with water and drowning his hamster.
fouadhatem
on 10 Oct 2020
Was this compiled as DEBUG or RELEASE binary? I know that futures are held by SwiftNIO for a while as part of promise leak detection, which indirectly leads to appearant leaks.
 Joannis
on 16 Oct 2020
Joannis
on 16 Oct 2020
In my case it was compiled in DEBUG
MihaelIsaev
on 16 Oct 2020
It compiled as Release binary
Maxim-Inv
on 16 Oct 2020
Release in all tests. I intentionally didn't include debug.
fouadhatem
on 16 Oct 2020
@Joannis Just to clarify... All my tests on Linux were tested using both vapor build and vapor run commands, as well as swift build -c release and swift run --enable-test-discovery commands. All exhibited the exact same behavior on all configurations, with one exception: CTRL-C after vapor run gave me back the command prompt at the CLI, while swift run did not. It just keeps typing ^C repeatedly without accepting any further commands.
On the Mac (the one discussed above with relatively lower available resources), Xcode would not be able to terminate the Run process when attempting to stop the server, while it was possible to do so every time with CTRL-C in a terminal window with both vapor run and swift run --enable-test-discovery.
fouadhatem
on 18 Oct 2020
Thanks for the clarification all of you! I'll keep you up to date with anything I find.
Joannis
on 18 Oct 2020
@Joannis There was a slightly more technical discussion here about this topic in the NIO channel on Vapor's discord.
It was also mentioned here in that same discussion that more CPU cores/memory affect the execution of this codepath, hence a potential (and currently only) explanation regarding this occurrence.
fouadhatem
on 18 Oct 2020
Here are the snippets of the discussion from Discord about this issue, as quoted from @TypeBeta:
Okay, I think I see something. There's an extremely subtle and obscure way for the signal handler Vapor sets up to get sidetracked in a fashion that prevents it from being handled properly... More CPU cores or memory would definitely affect the occurrence of this little codepath.
You're encountering a particularly interesting bizarre edge case at the intersection between libdispatch's DispatchQueues and NIO's EventLoops - Vapor does this to trigger a shutdown on SIGINT (slightly simplified):
let promise = context.application.eventLoopGroup.next().makePromise(of: Void.self)
context.application.running = .start(using: promise)
let signalQueue = DispatchQueue(label: "codes.vapor.server.shutdown")
func makeSignalSource(_ code: Int32) {
let source = DispatchSource.makeSignalSource(signal: code, queue: signalQueue)
source.setEventHandler { promise.succeed(()) }
source.resume()
signal(code, SIG_IGN)
}
makeSignalSource(SIGINT)
(several lines snipped, but these are the important bits)
The promise used to actually trigger the shutdown is associated with application.eventLoopGroup.next(), in other words "the next event loop that happens to be handy at the moment" - and by default, there are only as many event loops as there are CPU cores.
However, the signal is delivered to and the promise is signaled from a completely separate dispatch queue, which exists totally outside of the event loop system (at least in Vapor's normal usage); NIO event loops are directly bound to threads, but dispatch queues are an entire separate (and one step higher) layer of abstraction. This means that the process.succeed(()) call must notify the promise's associated event loop by queuing a task on that event loop for execution when the loop can next get to it.
Normally, this is a reasonable thing to do. Promises are used to translate execution between queues and threads in several instances, it's a tested codepath...
But, a dispatch signal source's event handler, while it isn't taking place in the extremely dangerous "async-signal-safe" context of a raw signal handler, is still a side effect of a signal that may well have been originally delivered on the thread belonging to the promise's event loop. The fewer number of threads and event loops there are in general (i.e. the fewer CPU cores and the less RAM the kernel treats as easily spread into thread-specific working set), the more possible it is to subtly "wedge" the promise's event loop so the promise result delivery does not trigger the future result's callback chain - it happens when EventLoop.inEventLoop returns an inaccurate result due to the behaviors of dispatch queues. I expounded upon inEventLoop's problems in that regard at quite some length in a PR I got merged into NIO itself that dealt with some somewhat related issues.
The problem normally doesn't arise because signal delivery interrupts an executing thread in a unique fashion that never occurs by any other mechanism.
Of course, the most interesting question is how to work around, avoid, fix, sidestep, or otherwise deal with the problem... That's the part I'm still working on; it's a very messy issue, and it's not possible to (safely) remove either queues or event loops from the logic involved.
fouadhatem
on 19 Oct 2020
I don't think @gwynne's diagnosis here is right.
Signal sources on Linux are essentially a wrapper around signalfd. This means that Dispatch does not do what @gwynne suggests (catch the signal in any random thread and then do a weird self-pipe or something). Instead, what Dispatch does is...much weirder.
The problem with signalfd is that it sucks. The specific problem Dispatch has to deal with is that signalfd is lower priority than regular signal delivery and so if Linux can find _any_ thread that it can safely deliver the signal to, it'll do that in priority to delivering it to the signalfd (this is not a good behaviour, incidentally).
Dispatch does its best to work around this by, whenever you register a signal source, also installing a regular signal handler. This regular signal handler catches the signal if delivered to that thread, masks off the signal on that thread, and then re-delivers the signal in the hope that this time it'll get delivered to the signalfd instead. This is all reasonably kosher, at least in principle, as pthread_sigmask and pthread_kill are both signal-safe on Linux.
The upshot here is that whatever reason this is failing is not the result of the interaction of the signal and the event loop. Dispatch queues cannot run on event loop threads, dispatch signal sources always run on dispatch queues, so this is always an across-thread concern. Wherever the issue is, it's elsewhere.
 Lukasa
on 20 Oct 2020
Lukasa
on 20 Oct 2020
@Lukasa Does this in any way apply to macOS as well? I know that Linux and macOS handle signals differently, but for some very elusive (and persistent reason), the behavior seems to be somewhat similar on both platforms, as I have seen. The reason it remains undetected (and irreproducible) for so long is because (and I hypothesize here) most senior devs working on addressing these issues have an abundance of resources on their local machines (CPU cores/RAM) and only work on macOS (including Docker).
I am able to successfully reproduce this issue now on both macOS and Linux whenever there are limited resources on the machines (2 cores or less on both platforms/ 4GB of RAM on Mac - 2GB or less of RAM on Linux). The ONLY exception to all this at the moment is the ability to terminate the server from the CLI on macOS with CTRL-C. However, it fails to terminate on Xcode every single time. The application fails to shutdown, with LLDB citing an RPC server error and a status code of -1.
It took me a while to try and identify a pattern of behavior that could help finally kill this issue once and for all, since there has been a steady stream of reports on the exact same issue going as far back as Vapor 3.
Here are two issues from earlier this year:
If you like, maybe you can show me how to capture the information you need from my machine to help trace down this issue?
fouadhatem
on 20 Oct 2020
Yes, all of the analysis applies to macOS as well. macOS doesn't have signalfd so you don't have to deal with the fact that it's bad, and managing signals on macOS is a bit saner and that kqueue is better than signalfd. However, when push comes to shove the signal handlers from DispatchSource still run on non-EventLoop threads, and so there cannot be a concern with them "blocking" an event loop thread. Whatever the issue is, it isn't as described above.
Lukasa
on 20 Oct 2020
As to tracing down the issue, the first place I'd look is that I'd look very hard at _how_ Vapor waits for the event loops to be closed.
Lukasa
on 20 Oct 2020
The code here is really quite unclear. Application.start seems to wait on the future from running. The flow control here is really uncertain but assuming that we successfully block there, simply notifying the promise should be sufficient.
I think the right diagnostics to perform are to set breakpoints in Application.run to see if onStop.wait() actually happens, and to set one in the signal handler. If you don't want to use breakpoints on Linux, you can also just add print statements after each thing we wonder about.
Lukasa
on 20 Oct 2020
@Lukasa FWIW, I wasn't suggesting that an EventLoop was being blocked by a signal handler running on its thread per se - I was speculating (it doesn't deserve any more definite term than that) more that the signal delivery might be happening in such a way as to cause EventLoop.inEventLoop to be inaccurate, disrupting the completion of the promise which Vapor uses as a termination signal (due to SelectableEventLoop.schedule0(_:) taking the wrong branch).
The behavior of inEventLoop is already a problem for NIOTSEventLoop in general (see my comments in https://github.com/apple/swift-nio-transport-services/blob/main/Sources/NIOTransportServices/NIOTSEventLoop.swift#L77-L94), though that implementation takes care to fail closed so that tasks take longer to run at worst - the misbehavior I was thinking of in this case (and I must emphasize again I have no evidence other than pure speculation) would not have that safeguard. My (unproven, untested) theory goes that, if inEventLoop incorrectly returned true when it shouldn't, SelectableEventLoop.schedule0(_:) would be misled in such a way that it would _not_ call self._wakeupSelector(). In turn, given that the cases of this issue that have been reported have been regarding failure to shut down a server with Ctrl-C (etc.), the odds are high that no further requests to the server in general are likely to arrive - meaning there would also be no external reason for the event loop to be awoken either. End result, callbacks attached to the promise's future result are never run.
If this (unsubstantiated) theory were correct, machines with more CPU cores would have more event loops in the default event loop group - I imagine there would exist a derivation showing that any number of cores greater than a particular threshold could never encounter the necessary conditions to trigger the problem (or the probability falls below some meaningful percentage, etc.). I would further wildly theorize that additional RAM is a red herring, specifically because in all the tests I've seen posted to this issue's discussion thus far, more RAM always also means more CPU cores.
By the way, in case I haven't said it enough times already, this is all totally wild theory, I have no concrete evidence regarding any of it 😆
 gwynne
on 20 Oct 2020
gwynne
on 20 Oct 2020
It's a wild and impossible theory, sadly, mostly because this prominently happens on Linux. :smile:
On Linux, inEventLoop is implemented in terms of pthread_self comparisons. This requires that the caller literally be running on the same thread as the event loop. While Dispatch Queues can behave weirdly, it is never possible for a dispatch source callback to execute on a NIO event loop thread on Linux. This is because there are only two places such a call could hypothetically execute. The first option is that it could be async'd to the queue and execute on a thread dedicated to that queue: that thread cannot be an event loop thread because it's dedicated to that queue. The other option is it could be sync'd or async'd to that queue and run on the thread that did the read from the signalfd. That thread _also_ cannot be an event loop thread, as it is currently issuing a read syscall!
In general Dispatch can never arrange to run a block on a SelectableEventLoop because to do so it would have to know that SelectableEventLoop exists, and it doesn't. There are no false positives for SelectableEventLoop.inEventLoop, and so this theory cannot occur. Sadly we have to look closer to home, at how exactly Vapor cleans itself up.
Lukasa
on 20 Oct 2020
@Lukasa what continues to confuse me is the relationship between resources (CPU cores/RAM) and the occurrence of this issue. What parts of Vapor do you think do this? There might be a clue found here, though this isn't dependent on web sockets at all.
fouadhatem
on 20 Oct 2020
@gwynne is right about the guess that this is likely related to the number of event loop threads.
Lukasa
on 21 Oct 2020
@Lukasa Okay so I am assuming that a fix needs to be done on Vapor then, not NIO, since it is Vapor that handles that. Is this a correct assumption?
fouadhatem
on 21 Oct 2020
Well, in the sense that Vapor is probably the culprit in general, yes. It would not make sense to change the number of event loops, though.
gwynne
on 21 Oct 2020
Cool so we seem to have a consensus that this is probably not a NIO issue and most likely a Vapor issue. We do not seem to have a consensus on what on Vapor's side is causing this.
@Lukasa suspects it might be related to how Vapor waits for it's event loops to close and that it could be related to the number of event loop threads.
@gwynne doesn't think that it might be sensible on Vapor's part to change the number of event loops. I'm guessing you're also leaning towards re-examining how event loops are handled in Vapor as well?
@0xTim and @siemensikkema this discussion might finally point us in the right direction to address this issue, as it seems to rear it's head every once in a while. What do you think?
fouadhatem
on 21 Oct 2020
Sorry to spam here, but on the off chance our data point helps:
We use systemctl to control our instances and I have noticed that this issue (same as described) only happens if the Vapor process has been running more than a few minutes.
We started seeing it about 5 weeks ago, before that we were using Vapor 4 but never saw it. We upgrade our deps about once a week.
 mxcl
on 23 Oct 2020
mxcl
on 23 Oct 2020
Let's compare the changes from 4.29.1 and 4.30.0 https://github.com/vapor/vapor/compare/vapor:4.29.1...4.30.0. I see a possible culprit in the way environment files are being loaded. There is a bug there that the EventloopGroupProvider is not forwarded from one DotEnvFile.load overload to another. This is a very common bug I see in more and more places. In this case the result of the issue is that it will erroneously create another ELGP. I will open a PR for this one. If this is the cause then the issue should not appear in 4.29.4.
 siemensikkema
on 26 Oct 2020
siemensikkema
on 26 Oct 2020
@fouadhatem @MihaelIsaev @Maxim-Inv Could any of you test if the issue still persists with 4.32.1?
siemensikkema
on 26 Oct 2020
@siemensikkema on it
fouadhatem
on 26 Oct 2020
Yikes, if so this was my fault :/ I see a fix was made to pass in the actual eventloopGroup, but now that I take a second look, I think we also need a fix in the loaddotenv.swift file for when we don't pass an eventloopgroup so that it is shut down after use.
 JaapWijnen
on 26 Oct 2020
JaapWijnen
on 26 Oct 2020
Ah no, double checked, it should shut down the eventLoopGroup in case of a .createNew EventLoopGroupProvider
JaapWijnen
on 26 Oct 2020
@siemensikkema I think you're on the right path. Preliminary testing on my end shows successful server shutdown on some instance configurations, but not all. It still fails on a limited capacity MacBook Air and a few other Linux instances. I am continuing to test as I type this. Will report in more detail once I have the full picture. However, it seems to me that if this is a widespread issue across multiple areas of Vapor, then I think that this issue would be at the very least partially resolved, if not entirely, if similar bugs are dealt with across the project.
@JaapWijnen this seems to be most definitely related to what @Lukasa mentioned earlier regarding how many event loops are created, how they are closed and what might cause this process to be interrupted, as event loops seem to have a strong correlation with narrowing availability of system resources.
fouadhatem
on 26 Oct 2020
Yeah, I just missed that I wasn't passing the eventLoopGroupProvider to the function that does the actual dotEnvFileLoading so it was creating two new EventLoopGroups before 4.30.1 (one for every .env file) 😓Fixed now by #2514 luckily. Shouldn't be a problem in itself indeed, but shouldn't have happened ofc.
JaapWijnen
on 26 Oct 2020
Don't sweat it. That wasn't the root cause of it, but it did make it a little worse. However, it seems that this is what might have led @siemensikkema to detect the pattern of errors causing it in the first place. So thanks! :)
fouadhatem
on 26 Oct 2020
@siemensikkema also, you are right in that the issue did not appear on Linux on 4.29.4 and before. However, 4.28.0 fixed an issue that caused a similar effect but because of an entirely different reason (open web sockets as a result of browser keep-alive).
However, failure to gracefully shutdown the server seemed to sporadically appear on Xcode on Macs with smaller capacities (MacBook Air 2013 with 4GB RAM in my case for example) throughout this time and it only seemed to get worse with every new tag, until it entirely stopped terminating successfully on Xcode, always complaining about:
Message from debugger: The LLDB RPC server has exited unexpectedly. Please file a bug if you have reproducible steps.
Program ended with exit code: -1
This may be happening for a different reason, but the previous randomness of its occurrence always seemed to point to resource availability issues. For example, if I had more open programs running in the background, it would fail to terminate, leading me initially to believe that this may be an issue of memory leaks.
fouadhatem
on 26 Oct 2020
@siemensikkema Here's more info on how the issue responds to 4.32.1 as compared to 4.32.0:
(Y = Successful shutdown, N = Unsuccessful shutdown)
Linux (Ubuntu 20.04 on VMWare):
- 1 CPU Core - 1GB RAM: 4.32.0 = N, 4.32.1 = N ( No change )
- 1 CPU Core - 2GB RAM: 4.32.0 = N, 4.32.1 = N ( No change )
- 2 CPU Cores - 1GB RAM: 4.32.0 = N, 4.32.1 = Y ( Improvement )
- 2 CPU Cores - 2GB RAM: 4.32.0 = N*, 4.32.1 = Y ( Improvement )
- 2 CPU Cores - 4GB RAM: 4.32.0 = Y, 4.32.1 = Y ( Improvement )
*The 4.32.0 instance with 2 CPU cores and 2GB RAM produced the following error when attempting to shutdown:
ERROR: Cannot schedule tasks on an EventLoop that has already shutdown. This will be upgraded to a forced crash in future SwiftNIO versions.
Mac (macOS 10.15.7 and Xcode 12.1):
- MacBook Air (2013) with 2 CPU Cores(i5) - 4GB RAM: 4.32.0 = N, 4.32.1 = N ( No change )
- MacBook Pro (2019) with 6 CPU Cores(i7) - 16GB RAM: 4.32.0 = Y, 4.32.1 = Y ( No change )
This pattern seems to confirm that this is indeed an issue directly relating to incorrect creation/closing of different event loops across the platform. It seems that the more occurrences we have of erroneous handling of event loops, the more prevalent this issue is. You eradicated one instance of them, which seems to improve the situation somewhat, while simultaneously giving more credence to this theory.
fouadhatem
on 26 Oct 2020
@fouadhatem I found some more likely culprits which are now fixed and deployed and available in 4.34.0. Would you mind having another look?
siemensikkema
on 27 Oct 2020
@siemensikkema on it
fouadhatem
on 27 Oct 2020
@siemensikkema Here's more info on how the issue responds to 4.34.0 as compared to 4.32.1:
(Y = Successful shutdown, N = Unsuccessful shutdown)
Linux (Ubuntu 20.04 on VMWare):
- 1 CPU Core - 1GB RAM: 4.32.1 = N, 4.34.0 = Y ( Improvement )
- 1 CPU Core - 2GB RAM: 4.32.1 = N, 4.34.0 = Y ( Improvement )
- 2 CPU Cores - 1GB RAM: 4.32.1 = Y, 4.34.0 = Y ( No change )
- 2 CPU Cores - 2GB RAM: 4.32.1 = Y, 4.34.0 = Y ( No change )
- 2 CPU Cores - 4GB RAM: 4.32.1 = Y, 4.34.0 = Y ( No change )
All VMWare tests passed. Testing may be required to confirm success on cloud-based/container-based deployments (Docker, AWS, DigitalOcean, Heroku - with swap enabled - , etc.).
@Maxim-Inv @mxcl @MihaelIsaev @jhoughjr can you kindly test and confirm these findings on your resources? Particularly, @mxcl can you check if the issue persists if you run Vapor instances for more than 10 minutes?
Additional testing may shed more light on additional recurrences of similar bugs in other areas of Vapor.
Mac (macOS 10.15.7 and Xcode 12.1)*:
- MacBook Air (2013) with 2 CPU Cores(i5) - 4GB RAM: 4.32.1 = N, 4.34.0 = N ( No change )
- MacBook Pro (2019) with 6 CPU Cores(i7) - 16GB RAM: 4.32.1 = Y, 4.34.0 = Y ( No change )
*The MacBooks continue to be able to build, run and terminate any Vapor 4 project successfully from the Terminal. This was even noted in 4.32.1 and most of the earlier tags.
The MacBook Pro displays random intermittent failures to shutdown the server from Xcode, particularly on the very first run of a project, or when attempting to run the project for the first time after a system reboot. This happens an average of 2 times for every 10 runs of the same unchanged project (assuming one system reboot).
This is the same pattern that was first observed on the MacBook Air when the issue first started presenting itself ever since I started using Vapor 4.
@mikecsh can you try out 4.34.0 on your MacBook and confirm what you see?
This overall pattern continues to confirm that this is indeed an issue directly relating to incorrect creation/closing of different event loops across the platform, as shown by 4.34.0 which quashed a few more of these bugs.
I continue to note that the issue on macOS could be (but as of now is not yet definitely) unrelated to the cause of these issues on Linux (erroneous creation/closing of event loops). Advice is needed on extracting information from Xcode to identify the source of the issue and confirm whether it is indeed related to the above.
fouadhatem
on 27 Oct 2020
I've just tested 4.34.0 on Ubuntu 20.04 on DigitalOcean and Ctrl+C seems working now.
Droplet config: Shared 1 vCPU 1GB RAM $5/mo
MihaelIsaev
on 27 Oct 2020
@fouadhatem thanks for the detailed analysis! So we can conclude that the issue is reduced to happening only on Xcode on macOS and that this is not a recently introduced issue? Would it be outlandish to suspect if Xcode itself might the problem?
siemensikkema
on 27 Oct 2020
@fouadhatem Could you please try to run your app using just swift run and try to press Ctrl+C in terminal on your MacBook Air (2013) with 2 CPU Cores(i5) - 4GB RAM to exclude possible problems with Xcode
MihaelIsaev
on 27 Oct 2020
@MihaelIsaev if I understand correctly, that has been working fine:
The MacBooks continue to be able to build, run and terminate any Vapor 4 project successfully from the Terminal.
siemensikkema
on 27 Oct 2020
Sorry, I missed that part 🙂
MihaelIsaev
on 27 Oct 2020
@MihaelIsaev projects build, run and terminate (with CTRL-C) just fine on the MacBook Air using both vapor run and swift run from the terminal.
@siemensikkema about Xcode, it certainly is a possibility that Xcode could be the culprit here, though I'm not sure why.
One pattern of behavior that I did not mention before, which may indicate Xcode as being the source of the problem, is the fact that earlier tags of Vapor were in fact able to terminate successfully most of the time on earlier releases of Xcode. With Xcode 12.1 and even slightly earlier versions, this is no longer possible. Projects consistently fail to terminate on the MacBook Air. I can investigate this by downloading an earlier release of Xcode and experimenting on 4.34.0 to see if it terminates. If this works, then we can start attempting to nail down why it happens.
I'm not very well-versed with the inner workings of Xcode or Vapor to be certain. I would be happy to follow any instructions on how to dig deeper into Xcode to investigate this, which incidentally may spare this poor MacBook Air the torture of multiple downloads and installs of previous versions of Xcode.
On a parallel note, potential culprits similar to the ones you have been locating so far in Vapor that relate to this issue may be found in the following files:
Sources/Vapor/HTTP/Headers/HTTPHeaders+Connection.swiftSources/Vapor/HTTP/Server/HTTPServer.swiftSources/Vapor/HTTP/Server/HTTPServerHandler.swiftSources/Vapor/HTTP/Server/HTTPServerRequestDecoder.swiftTests/VaporTests/ServerTests.swiftTests/VaporTests/WebSocketTests.swift
The reason I suspect them is because these are the files that were changed as part of 4.28.0. They directly control HOW a server is terminated, rather than the indirect impact of erroneous event loops that you have been finding so far. Would you kindly take a look?
fouadhatem
on 27 Oct 2020
Might be related to the weird change in SIGCONT behavior in LLDB. See also https://twitter.com/stuartcarnie/status/1316765381923491847
gwynne
on 27 Oct 2020
Nothing like hitting the close issue button by accident 😓
gwynne
on 27 Oct 2020
@gwynne ye who wieldith thy powereth shall deployeth it wisely..eth...
Great... Now I have to wipe my screen LOL.
And how the hell did you find that SIGCONT thing?? It feels relevant because it's always LLDB that complains about an RPC server quitting unexpectedly when I attempt to terminate any Vapor project on Xcode on that downtrodden MacBook Air of mine.
Do you have a theory as to why it might not be an issue on more powerful macs, while still being an issue on less resourceful ones?
Update: Just tried it. Didn't work unfortunately :(
fouadhatem
on 27 Oct 2020
Didn’t seem to help us either unfortunately.
mxcl
on 28 Oct 2020
@fouadhatem Thanks for the prod - I'm still seeing the issue with 4.34.0 on my 12" MacBook both under docker and XCode.
mikecsh
on 28 Oct 2020
@mikecsh can you remind me please what the specs of your machine are, particularly processor type, number of cores, RAM and which version of macOS/Xcode you're running?
fouadhatem
on 28 Oct 2020
@fouadhatem
Xcode 12.0.1 and Xcode 12.2 beta-3 and Ubuntu 18.04 under Docker (Engine v19.03.13) on a 2017 1.4 GHz Dual-Core Intel Core i7 MacBook 12" with 8 GB RAM running macOS 11.0 Beta (20A5395g).
This was occurring before upgrading to the macOS 11 Beta also on 10.15.4.
mikecsh
on 28 Oct 2020
@mikecsh Thanks.
Just so I'm clear: you're running Docker and Ubuntu 18.04 on the same machine?
fouadhatem
on 28 Oct 2020
@fouadhatem Sorry, that wasn't too clear.
I tend to develop, build, and test my Vapor app under Xcode/macOS for a quicker dev cycle due to very slow compile times under Linux
After each significant stage of development I update a version of it running under Ubuntu 18.04 inside Docker (on the same machine) where the Vapor app is integrated with other components of my system.
After that it is deployed to a $5 DO droplet. I have no data points from there as that is still running a version based on Vapor v3
mikecsh
on 28 Oct 2020
@mikecsh okay that makes more sense. So if I understand this correctly, you still face the issue when attempting to compile and run on Xcode during your dev phase?
fouadhatem
on 28 Oct 2020
@fouadhatem Yes that is what I was seeing earlier, however I've just tried to reproduce it again (in Xcode 12.2 Beta-3) and I'm not able to. I have tried both terminating within a few seconds of launching and having let it run for 10 minutes. I'll report back if I see the issue again under Xcode.
I am still seeing it under Docker/Ubuntu 18.04.
Thanks for looking into this.
mikecsh
on 28 Oct 2020
@mikecsh my pleasure! It affects me as well so I kind of have to as well lol.
This is very interesting! Xcode 12.2 Beta-3 does NOT show the issue, but earlier (stable) versions of Xcode do.
As for Ubuntu and Docker, can you please tell me which packages you have imported from Vapor into your project? Also, can you run an empty Vapor template project with the same set up and tell me if you still see the issue?
Thanks for helping out!
fouadhatem
on 28 Oct 2020
@siemensikkema I detected an interesting new pattern relating to this issue:
If an Xcode project crashes at runtime for any reason during its very first run, the issue disappears for as long as that Xcode project is open, even if it is being changed and rebuilt. However, if you quit Xcode and relaunch it again with the same project and attempt to run it, the failure to terminate pattern will return.
Example: I create an Xcode project from template with the usual packages(Vapor, Fluent, Fluent Postgres Driver) and I create a couple of models and their associated migrations. If I deliberately mess up a migration (reference a non-existent parent model from a child model, for instance) then the error will only be triggered at runtime when Vapor attempts to run the migration and the server will not start.
Fixing the references in the migration, resetting the db and attempting to run it again will cause the project to terminate correctly each and every time thereafter during the same Xcode session. However, if I quit Xcode and attempt to run the project again, the same old pattern of unsuccessful server shutdown returns.
fouadhatem
on 11 Nov 2020
@fouadhatem Yep, even more definitely sounds specifically related to LLDB - Can you try editing the scheme and unchecking the "Debug executable" box in the Info tab of the Run action, and see if the issue remains? Preferably using Xcode 12.2b4, in particular. (In fact, it'd be useful to know whether the issue is present in that Xcode version at all.)
gwynne
on 11 Nov 2020
Oh wow you DO levitate! @gwynne I think we have a winner! Works every time with Debug Executable box unchecked.
This is on Xcode 12.1 and I'm downloading 12.2b4 to further test out this theory. I'm also going to try out different configurations for the settings below to see which other combinations cause the same issue to arise and which make it go away.
My schema settings (under Run > Info) for the project are now:
- Build Configuration: Debug
- Executable: Run
- Debug Executable: Unchecked
- Debug process as: Me
- LLDB Init File:
$(SRCROOT)/LLDBInitFile - Launch: Automatically
How did you figure this out and what is causing it?
fouadhatem
on 11 Nov 2020
@fouadhatem When combined with the SIGCONT issue I referenced earlier in this discussion (https://github.com/vapor/vapor/issues/2502#issuecomment-717525115), the issue going away after the first failed termination but returning when Xcode was relaunched was a dead giveaway - relaunching Xcode also relaunches the macOS-specific lldb-rpc-server, and given that termination is implemented by delivery of a signal (SIGINT or SIGKILL, depending on termination method), the existing LLDB signal handling issue was an obvious culprit.
Of course, this has nothing whatsoever to do with any issues experienced on Linux, but it looks like the event loop fixes actually solved that, and the LLDB issue was an unfortunately well-timed coincidence.
gwynne
on 11 Nov 2020
@gwynne very interesting! Why did you ask me about Xcode 12.2b4 though? Is that LLDB issue resolved there? There was a reference in this thread earlier about the issue not popping up in Xcode 12.2b3.
And might I ask, what exactly was the issue with LLDB that makes this happen? Is it related to why this issue appears on less resourceful Macs like this lowly MacBook Air and not on more powerful ones like the MacBook Pro?
fouadhatem
on 11 Nov 2020
@fouadhatem Yeah, the mention of it vanishing in b3 made me wonder if it'd appear at all in b4.
The issue with LLDB is one of mishandled signal delivery, caused by - as far as I can tell - a bug in the RPC-based interface with Xcode (all of which is internal to Apple's developer tools, there's no public RPC mode for LLDB as far as I'm aware). It resulted in LLDB treating certain signals (such as SIGCONT) as breakpoints, rather than using the "pass to target process" behavior those signals previously had. My best guess is that since Xcode was issuing a termination command, the UI wouldn't stop at a breakpoint for it, but LLDB would still fail to pass the appropriate signal along, so the termination wouldn't happen. On next launch, the signal handling behavior would be reset to the correct defaults (since the mixup seemed to be due to Xcode's internal one-time initialization after launching the RPC server process), and everything would work - until the RPC server got relaunched and Xcode ran its own initialization again.
I would guess that the "only when running with constrained resources" behavior was already absent once the event loop issues were fixed and the bug vanished completely on Linux - but of course, the LLDB bug remained, and it would take some careful re-examination to realize that the issue was suddenly affecting _all_ systems.
gwynne
on 11 Nov 2020
@gwynne thanks for that!
I just tried different combinations of settings and the issue only completely goes away when the Debug Executable box is unchecked. This indeed was a very unfortunately well-timed coincidence! How about that?
fouadhatem
on 11 Nov 2020
@mikecsh can you implement the solution from above and let us know if that resolved it for you on the Mac on your non-beta Xcode version?
Also, are you still experiencing the issue on Docker with Ubuntu 18?
fouadhatem
on 11 Nov 2020
@gwynne Assuming that everyone else who participated in this issue are now satisfied with the resolutions mentioned here for all platforms, do you think it needs to be extended anywhere else after this issue is closed to make sure that the findings here are easy to locate in the future?
Something along the lines of:
Adding some kind of tip or note somewhere in here that talks about turning off that
Debug Executableoption in case someone else is facing a similar issue when using Xcode versions lower than 12.2, followed by a small warning regarding what info/functionality could be lost when that option is turned off.Filing a bug report with Apple and/or LLVM about this bug.
Speaking of which, is it really an LLDB bug or is it more of an Xcode thing? The reason I ask is that I never had issues building/running/terminating a Vapor project from the macOS terminal, which I assume also uses the same LLVM/LLDB infrastructure. Or am I missing something else, as usual?
EDIT: Just tried it out on Xcode 12.2. The issue still persists and it looks like your solution is the only one that fixes it.
fouadhatem
on 12 Nov 2020
Related issues
 hjuraev
·
3Comments
hjuraev
·
3Comments
 kgn
·
3Comments
kgn
·
3Comments
 OlegKorchickiy
·
3Comments
OlegKorchickiy
·
3Comments
 nsleader
·
4Comments
nsleader
·
4Comments
 xiaoyifan
·
3Comments
xiaoyifan
·
3Comments
Most helpful comment
@mikecsh yeah the issue seems to have been tracked down, at least partially. Both the Vapor and NIO teams need to sort it out.
It seems trivial at first, but this situation is actually like attempting to pull a seemingly harmless nail out of the wall in your living room, only to end up having your neighbor's bedroom on the other side of the wall flooded with water and drowning his hamster.