Follow-up to the discussion in #772
Notes
click to expand
browser.sessionhistory.max_total_viewers to 0 prior to testing, to prevent the fastback/backforward cache from messing with the resultscache-control: immutable, that don't ever trigger conditional requests (even when fetched from disk)
My observations
click to expand
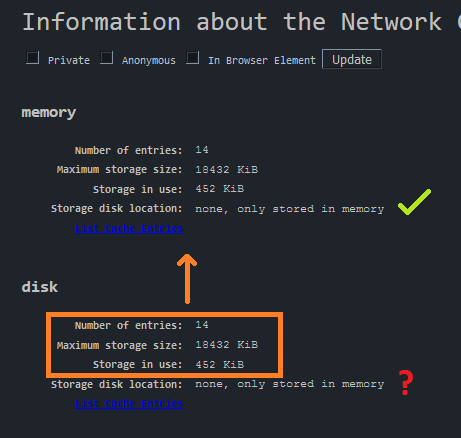
My conclusions (you draw your own)
When it comes to tracking, disabling disk cache but not memory cache (disk=disabled + memory=enabled) represents a risk only for the duration of the session, but even then it is not as straightforward to exploit as many seem to think. With FPI on, I see no risks whatsoever. Fingerprinting-wise, there are significant differences between all four possible combinations of click to expand
disk.enabled and memory.enabled, with the exception of disk=enabled + memory=enabled vs disk=enabled + memory=disabled (those seem to be identical).
Some reading:
click to expand
Tools used:
click to expand
edited for clarity
 claustromaniac
claustromaniac
All 29 comments
Close the session once in a while and you're done!
 Atavic
on 30 Aug 2019
Atavic
on 30 Aug 2019
I haven't forgotten about this, or the section header cleanup plan. Thanks for all the testing, and summarizing. About the only thing that I didn't know was the "conditional requests are triggered". You know more about this I do - I just hit F5 when I refresh and expect a new set of downloads. But I don't see how that means that what I said earlier, or the section header, is "not correct" (if that's the right word to use). Anyway, lets just truck on here...
I've read this four times today, slowly and carefully. Focusing on just the four possible combos:
- A: Default FF: D ✅ M ✅
- same as 99% of FF users probably: we have
Das a setup-perf and if users flip that they're at default and no worse off
- same as 99% of FF users probably: we have
- B: Default user.js: D ❌ M ✅
- I honestly can say that the only reason this was added (at least initially) was because of disk avoidance (a la TB's threat model), and because I use portable FF and it comes with that setting as well, and I never noticed a speed diff TBH
- This also means only one pref to flip to get to default, and one flip to get to paranoid: which seems like a good balance
- C: Paranoid: D ❌ M ❌
- Never used this TBH
- The point remains that in this state, ETAGs don't happen: "nothing is ever cached (as expected)"
- Which is why I am confused why the benefits of disabling both in the section header seems to be an issue
- D: The Other One: D ✅ M ❌
- makes no sense as a combo, so lets ignore that.
Here is the old proposed section header change
ETAG [1] and other [2][3] cache tracking/fingerprinting techniques can be averted by
disabling *BOTH* disk (1001) and memory (1003) cache. But there are better solutions.
ETAGs can be neutralized by modifying response headers [4]. A hardened configuration
with Temporary Containers isolates every tab [5]. Alternatively, you can *LIMIT* exposure
by clearing cache on close (2803), or on a regular basis manually or with an extension.
I still don't get the problem with the first sentence, which I think you said we should just drop. I'm probably OK with that.
ETAG [1] and other [2][3] cache tracking/fingerprinting techniques exist. ETAGS can be
neutralized....
and/or maybe add in something about FPI?
and/or just move the both disk + memory thing to the end: e.g "as a last resort...": because it's technically true
@claustromaniac here kitty kitty
 Thorin-Oakenpants
on 9 Sep 2019
Thorin-Oakenpants
on 9 Sep 2019
Which is why I am confused why the benefits of disabling both in the section header seems to be an issue
The statement itself is true, but that emphasis in both (disabling *BOTH* disk (1001) and memory) implies that disabling only disk cache is not enough to beat ETAG [1] and other [2][3] cache tracking/fingerprinting techniques, while this is not entirely true.
A more accurate statement would be:
ETAG [1] and other [2][3] cache tracking/fingerprinting techniques can be averted by
disabling both disk (1001) and memory (1003) cache, or by disabling disk cache only
and *never* reloading pages, or by disabling disk cache only *and* leaving FPI enabled
*and* not leaving Firefox running 24/7. But there are better solutions...
... but that's obviously too long and probably confusing.
claustromaniac
on 9 Sep 2019
OK ... I get it ... I'll work it out and get back to you. Here's some ideas:
- When cache tracking/fingerprinting techniques are applicable....
- Generally speaking...
Thorin-Oakenpants
on 9 Sep 2019
I'd leave the fingerprinting part out, too. Adversaries can figure out your current combination of D and M if they want (with little margin of error).
Let's see... Just to throw ideas, how about something like this:
First-party isolation alone defeats all tracking techniques that work by exploiting the
cache, but such techniques can still de-anonimize you. The latter can be prevented
by disabling the cache altogether, but there are alternatives. ETags can be neutralized
by modifying response headers [4]. The Temporary Containers extension isolates cached
content in disposable containers. Clearing the cache on close (2803), or on a regular
basis manually or with an extension also limits exposure.
(I left the references out, but you'd want to add those back in, I guess)
claustromaniac
on 10 Sep 2019
First-party isolation alone
On second thought... I guess that could be misinterpreted... Well, your English should be better than mine. I'm sure you'll come up with something better.
claustromaniac
on 10 Sep 2019
If you go that route, you can add a line to 1003 to justify its existence in the user.js, saying something like:
Disabling memory cache is generally not helpful unless you don't use FPI and/or don't close Firefox often
EDIT x10^999: OK I'm done editing. Jeez.
claustromaniac
on 10 Sep 2019
First-party isolation alone defeats all tracking techniques that work by exploiting the cache
umm, no it doesn't: an in-session return visit to a 1st party could still exploit that: example: I google Taylor Swift, switch VPNs, then google TOOL's latest album ... now google knows I'm into TayTay and TOOL : Joke Reference
Anyway, I'll just have to work out how to carefully word this all
Thorin-Oakenpants
on 10 Sep 2019
umm, no it doesn't: an in-session return visit to a 1st party could still exploit that: example: I google Taylor Swift, switch VPNs, then google TOOL's latest album ... now google knows I'm into TayTay and TOOL :
That's not _tracking_ though. In that case they would be using the cache to de-anonimize you (oh, you're the same guy that visited with this other IP a while back!).
Tracking is if you then go to another site with a Google Analytics script - they know you're the same guy, and now they also know you're into porn involving llamas.
claustromaniac
on 11 Sep 2019
How to exploit the cache for tracking:
Make the victim request a script that
- gets stuck in the browser's cache indefinitely
- sets a variable to a unique value (the identifier), and then
- reports the site the victim is browsing along with that identifier to its source (you).
Or easier: exploit both the ETag and Origin headers together. The ETag is the identifier, and the Origin is what you (evil bastard) want to know: which site the victim is browsing.
I believe that is what tracking is. FPI defeats those tracking techniques.
claustromaniac
on 11 Sep 2019
That's not tracking though. In that case they would be using the cache to de-anonimize
I disagree. Anonymity is when you cannot be identified. In this example, I can search google and they have no idea who I am. The cache can still track me across multiple visits (e.g. etags) - it can't necessarily ID the real me (de-anonymize). Tracking is the linking of the same user's activities: that doesn't mean only across different websites. Cookies are a classic example: they are used to tie together all your activities on a site: e.g you get a unique login id.
Anonymity: your real id is not exposed
Privacy: only the end parties can read the contents
Security: the end-points know they are who they say they are (anonymous or not)
Tracking: the linking or connection of the same id (real or not). FPing by it's very definition is a tracking mechanism: it is trying to give you a unique ID
Thorin-Oakenpants
on 11 Sep 2019
Cookies are a classic example
Cookies are ye old infamous tracking vectors precisely because without FPI they can ID you across websites (as third-party cookies). If a 1st party sticks a cookie in your browser, that does not automatically mean it's trying to track you. Back when the internet wasn't as dynamic as it is today (with Ajax and all that crap), they were meant to be used for authentication. Authentication != tracking.
Anonymity is not a boolean either. There are degrees of anonymity. If you never ever type in your real name anywhere, congratulations! you're making it hard for them to figure it out, but that does not mean they can't eventually guess it. That's half of the goal of tracking: figuring out who you are. The other half is about knowing what you do, what you like, what you don't like, etc. That's what adversaries all over the Internet want to know. That's where the money is. And those actors must respond to authorities to save their own asses. That's why it's so important to be careful when using Tor Browser, because if you're not (e.g. if you install some shitty extension that makes you look significantly different than other TB users), you're losing anonymity. You waltz around with your mask on feeling all safe and all of a sudden you're busted. You ask yourself, now, how the hell did that happen, I never used my real name!. It has happened to many a criminal. True story.
I recall reading some good articles on the subject some years ago that didn't cover just the online aspects but also the offline ones. I know you like to read so I'll be sure to share them with you if I happen to find them.
In my opinion, what makes it hard to tell these terms apart is that they are linked in how and why they are used. This is how I understand these terms (I know not everyone agrees):
- De-anonimizing techniques are necessary for tracking (they are means), because you need to tag users somehow to track them around, but de-anonimizing is also part of the goal of tracking (in this case, to discover your real identity).
- Privacy is our right to keep our shit to ourselves, and we do it for many reasons - the most fundamental one is security (you can't have security if you don't have any privacy).
- Violating your privacy is what adversaries do in the process of tracking you and ID'ing you, because they have to follow you around until they know who you are (and beyond).
- Security is at the same time the means and the end goal to Privacy. What you (Pants) refer to as security, I refer to as authentication, just one of many security tools.
- Fingerprinting is one of many ways to de-anonimize you. They can fingerprint you across websites and track you, or not, that's up to your adversaries.
It's fine if you don't agree though. Not trying to force my concepts on anyone.
claustromaniac
on 11 Sep 2019
It's fine if you don't agree though. Not trying to force my concepts on anyone.
OK, you have your view. And it's all good. It's just a discussion. 🍻
Cookies are ye old infamous tracking vectors precisely because ... they can ID you across websites (as third-party cookies) ... If a 1st party sticks a cookie in your browser, that does not automatically mean it's trying to track you
Cookies are ye old infamous tracking vectors precisely because ... they can ID you across a website (as first party) ... If a third party sticks a cookie in your browser, that does not automatically mean it's trying to track you.
See what I did there? Not sure why you're fixated on parties. Tracking is not limited to 3rd party. Tracking is the linking of a user's activities: and that includes 1st party: e.g. google searches. Why do you think TC hard mode exists? And this includes logins e.g. gmail. An account is simply you giving them an ID so you can use and they can provide the service: an ID means tracking (in order for the service to work).
Like most things, these can be used for "good" and "evil". Not all tracking or cookies or FPing is evil, but they can all be used for that. I shouldn't have to qualify that all that time.
That's why it's so important to be careful when using Tor Browser, because if you're not (e.g. if you install some shitty extension that makes you look significantly different than other TB users), you're losing anonymity ... You waltz around with your mask on feeling all safe and all of a sudden you're busted
First of all, I agree that messing with TB is stooooopid.
But you're not losing anonymity (at least not directly)... instead you're increasing tracking vectors. Those vectors could help lead to de-anonymization, but that would be due to OpSec, not your FP. As long as they can't link back to the real you (OpSec): you are still anonymous. Your anonymous "shadow profile" however would keep growing and all it takes is one OpSec mistake and then you're "busted" as you so put it.
I could quite easily bounce around in TB with a modified UA which includes "COME GET ME YOU NSA BASTARDS" and my actions / OpSec in TB would (99% sure) never betray the real me. i.e I wouldn't log in anywhere, or post anything etc... just surf websites and research stuff. Sure: I'd have a unique FP, but I'm not de-anonymized. However, this is stupid: because if something were to go wrong (exploit, honeypot, the NSA spending trillions to get me because they took offence), I wouldn't be de-anonymized for a few things: my whole history could be up for grabs (tracking).
You said anonymity is not a boolean : I disagree: either you are or you aren't. There's no such thing as half anonymous. If no-one can link back to the real you: you're anonymous. As soon as one person can, you're not. It's pretty much black and white in my book. It's like cryptography: you can't build in a backdoor only for the "good" guys.
Security
Its a very broad term. I was using it in the simplistic sense of the networking of the two parties (sender/receiver): e.g certs. But also end-to-end encryption which ties into privacy.
Anyway: I enjoy writing these things
Thorin-Oakenpants
on 11 Sep 2019
As I keep doing unrelated stuff, my mind's background processes just came up with a fun analogy. Just for kicks, here you have it:
Let's say there are two serial killers.
The first one is methodical and is a rare case of a serial killer: he kills mostly at random, when he sees a good opportunity to do it, and doesn't leave a signature behind. He doesn't ultimately want to get caught. He just, quite simply, wants to. Kill. People.
He is extremely cautious, so he never lets anyone see him (or her?), and makes sure not to leave any evidence behind (not even his victims' bodies).
The second killer likes attention. He likes to introduce himself (with a pseudonym) to his about-to-be victims in perfect British accent, wears a Guy Fawkes mask, and mostly kills politicians. All witnesses (he likes witnesses) describe him as a him (inferred from his voice and body build).
Now, would you say they're both equally anonymous? If not, who would you say is the least anonymous of the two?
If the first gets caught, they won't necessarily have any way to link all of his killings. They may not even think he is a serial killer, depending on the circumstances. If the second gets caught, well, they know exactly what he did, so he wasn't as anonymous as he thought he was. Even if they don't get caught, the authorities will be pretty sure the second one is male and likely British, and that immediately eliminates most of the world's population as potential suspects.
claustromaniac
on 11 Sep 2019
^^ Thats all about OpSec and I agree with it (as in my post just before yours). Not the state of your anonymity. There's no such thing as partly anonymous.
Thorin-Oakenpants
on 11 Sep 2019
Well, at this point we're discussing semantics. I'd say the difference is I judge anonymity more by its actual effect than by its intended effect. For me, an author publishing under a pseudonym was not anonymous to begin with if someone can eventually manage to link the two personas. That's what I think of as partial anonymity. OpSec wouldn't necessarily take part in that. If the author himself wants to disclose his alter ego's true identity later on, he may not be directly able to prove that he wrote those books, but he may be able to prove that the two are one and the same, or the other way around.
claustromaniac
on 11 Sep 2019
It's like cryptography: you can't build in a backdoor only for the "good" guys.
But you can totally give the "good" guys near unlimited computing power for cracking it. By that logic, absolutely no one is anonymous.
claustromaniac
on 11 Sep 2019
Your killers analogy mixes several things IMO
Killer 1: he is anonymous and private (not witnesses, no bodies, nothing!)
Killer 2: he is anonymous but not private and has terrible OpSec, which facilitates tracking/linkage = shadow profile
Both are anonymous until caught. But their chances of being de-anonymized are not the same, because killer 2 has drawn attention to himself (not private) which means any mistake he makes will get picked up on (OpSec). His activities are easily linked (lack of forward secrecy for a bad analogy here). Killer 1 might only get caught for one crime, but killer 2 if caught for a crime with all his characteristics, would be up for all of them.
I judge anonymity more by its actual effect than by its intended effect
So, in other words, the chances of being de-anonymized, or how good your setup/strategy is. When talking theory, I think you have to talk in terms of absolutes: because nothing is ever certain. e.g. something is only "secure" until that cipher is broken, or shown to be compromised: there's always risk. This is why scientists have hypotheses. Its only as good until proven wrong once. So here, you're anonymous but for all we know, it's already compromised: or the NSA has some unknown exploits, not to mention OpSec failures, and I can think of a couple more scenarios which aren't really OpSec or exploits (they really are quite nasty). There's no guarantee of anonymity (or security, or privacy). And I think that is what you're calling it.
That's not how my mind/theory works. I'm the opposite of you. I'm talking in absolutes or states. In my Venn diagram of privacy, anonymity, security: you can have any or all or none, or any combination of them. Then I have forces or variables acting on those. Being variable, they of course alter the chances of success, or viability of achieving that state.
If the author himself wants to disclose his alter ego's true identity later on
Funny you say that, because I've thought about this (but I am not an expert). With digital publications for example, you could provide an encrypted message. Each subsequent publication you provide the key to the previous one, and of course add a new encrypted message with a new key. And so on. But I guess this has flaws: a single point of failure? IDK.
🍻
Good idea. I enjoy these chats :)
Thorin-Oakenpants
on 11 Sep 2019
Good idea. I enjoy these chats :)
:beers:
That's not how my mind/theory works. I'm the opposite of you. I'm talking in absolutes or states. In my Venn diagram of privacy, anonymity, security: you can have any or all or none, or any combination of them. Then I have forces or variables acting on those. Being variable, they of course alter the chances of success, or viability of achieving that state.
I'd just say I'm just more of a practical guy, that's why I purposely avoid absolutism. In our observable reality, everything tends toward relativity, so I have long ago figured out that's what works best for me. You can be anonymous to someone and not anonymous to somebody else. You can be anonymous with shitty OpSec, but if no one cares, you're effectively as anonymous as you need to be (because no one cares anyway). The fact that I see levels of anonymity where you don't probably means I see anonymity as a product of the other things combined (variables included), not as an entirely separate thing. I'm talking about anonymity in practice, not in theory, because that's the one that matters to me.
So yeah. We're talking semantics here. I'm glad we apparently agree on the underlying concepts though, even if we don't use the terms the same way.
claustromaniac
on 11 Sep 2019
OK, the more I read my original draft, the more I'm convinced it's just fine. Clearly a cache tracking/fingerprinting technique can only be averted when it's applicable: that's an assumption we shouldn't have to state.
The BOTH was so people didn't miss the part that both were required: it doesn't "imply that disabling only disk cache is not enough to beat 1,2,3" - it actually says that! Because there are instances where disk cache being disabled are not enough (even if the risk is small).
And this is the bit that irks. So we simply add something like "Using just memory cache still has edge cases.." but that's a bit silly in my opinion: because those edge cases are already listed (TC etc, I'll add in FPI), except for the bit about reloading a page: which is what the cache was designed for: OMG. How dumbed down do we need to make this?
I'm going to drink another beer coffee and then commit something
Thorin-Oakenpants
on 15 Sep 2019
@claustromaniac - IDK, hows that ^^ PR looking?
I know what you're saying about conditional requests: and that it's not often (anecdotal? depends on the user) something gets re-requested (and the same holds for disk cache): e.g you need to reload/refresh?. But I honestly just can't work that in, given that this is how cache works. We're simply talking about mitigating shit when it happens: not explaining every single use case
please advise: ps: can't add you as a reviewer cuz you changed/hid your status or something
PPS: it adds 10 more lines to the user.js. Not super happy about that: can we shrink it?
Thorin-Oakenpants
on 15 Sep 2019
Because there are instances where disk cache being disabled are not enough (even if the risk is small).
Disabling both disk and memory cache is not a perfect solution either (not even if you decide to ignore the performance aspects), because it causes the browser to request everything over and over again, and prevents it from making conditional requests. I'd argue very few people do that, which can make those who do it more easily identifiable than those who leave the cache enabled but wipe it as necessary instead. This is part of what I was talking about when I said that all possible combinations of disk.enabled and memory.enabled have significant differences fingerprinting-wise and, in that sense, no single combination is better than the rest IMHO.
OMG. How dumbed down do we need to make this?
Personally, the main reason I shared my findings here was to correct what I said before, because I (claustromaniac) don't want to misinform anyone if I can avoid it. If I can help in the process, that's great, but what you do and how you do things in your project is up to you.
We're simply talking about mitigating shit when it happens: not explaining every single use case
I would either be detailed or I'd make it something short, like:
We consider these defaults good, taking into account many factors, but there are other good strategies for dealing with the cache.
[More info here, links, links, more links, or whatever]
Anything half way can be ambiguous and/or misleading, and will probably be confusing to some.
ps: can't add you as a reviewer cuz you changed/hid your status or something
I left the organization (remember? precisely to stop taking part in that kind of stuff).
claustromaniac
on 15 Sep 2019
Disabling both disk and memory cache is not a perfect solution either
Agreed. But (like the IPv6 argument), it is better to ensure you can't be uniquely tagged (e.g. Wiki says Hulu and KISSmetrics were doing this back in 2011: granted: we can counter ETags separately) than to be in a smaller bucket of users. Regardless, we don't do that (disable both).
PB mode doesn't use the disk cache. 25% of FF users use PB mode (not start in PB mode necessarily) - that's from memory from some Mozilla article/comment: it's probably higher. I think the bucket is bigger than you think.
I don't think cache settings FPing is a huge risk, or even a thing (yet). It's not stable: pb mode vs normal windows, hard reloads, users clearing on close, extension sanitizing, internal FF sanitizing, third party cleaning apps.
Thorin-Oakenpants
on 16 Sep 2019
PB mode doesn't use the disk cache... I think the bucket is bigger than you think.
But it does use the memory cache, which means the result is akin to disabling disk but NOT memory cache. In other words: I'm pretty sure the bucket is way smaller than you think (because disk=disabled + memory=disabled does not match PB's behavior).
claustromaniac
on 16 Sep 2019
I'm just pointing out that our default matches it. Well actually, I didn't say that exactly: I just said that PB mode is, with disk cache off, common. Of course thats D=off M=on. I should have been clearer.
Thorin-Oakenpants
on 16 Sep 2019
Cats and singers 😄
Just to double check... do I need ETag Stoppa when, RFP = true, D = false, M = true and TC = Automatic mode?
Thank you and cheers
 crssi
on 16 Sep 2019
crssi
on 16 Sep 2019
I'm just pointing out that our default matches it... I should have been clearer.
Indeed. You said "I think the bucket is bigger than you think", while the only time that I alluded to the bucket's size was when I was pointing out that disabling both disk and memory cache is not a perfect solution. I had no way to tell you were trying to make a separate remark.
do I need ETag Stoppa when, RFP = true, D = false, M = true and TC = Automatic mode?
Personally, with TC in automatic mode I don't use ETag Stoppa, regardless of the other settings.
claustromaniac
on 16 Sep 2019
@claustromaniac ... something interesting for you: https://bugzilla.mozilla.org/show_bug.cgi?id=1545909 .. they bumped it to P1
Thorin-Oakenpants
on 23 Oct 2019
Not interested. Thanks for the heads up though. I expect them to fuck up once or twice in the process of fixing it.
claustromaniac
on 23 Oct 2019
Related issues
 earthlng
·
4Comments
crssi
·
4Comments
earthlng
·
4Comments
crssi
·
4Comments
 TerkiKerel
·
4Comments
Thorin-Oakenpants
·
4Comments
Thorin-Oakenpants
·
5Comments
TerkiKerel
·
4Comments
Thorin-Oakenpants
·
4Comments
Thorin-Oakenpants
·
5Comments