re: #294
Starting a new issue as per the instructions in that issue
please try to NOT start discussions in here, start a new issue instead. ONLY use this thread to report extensions - thank you
@Thorin-Oakenpants Hi, I'm the Privacy Possum developer. Responding to some of your points:
- ETags - we can already do this with a rule for Header Editor - or users can disable both disk+memory cache. The first solution is the best. The second can be a tad extreme (nothing in memory will cause extra traffic etc). A third solution is clearing cache eg say every 15 minutes via an extension but is not a perfect solution (time factors leave holes for repeat visits).
- ETags - Currently I remove inbound 3rd party ETag headers. And allow 1st party etag headers. This is because first party etag tracking is uncommon, and real non-tracking use of etags is common in a first party context. I have a technique for determine if a given resource is using tracking vs real etags, but I'm currently limited by Chrome's API.
- "fingerprinting" - uM (and uBO) can handle 3rd parties if used in "medium" or hardened mode or whatever they call it. Yes, not everyone uses it that way. And some 3rd parties are unavoidable no doubt (for the site to work). And there are 1st party FP scripts. Been subscribed to FPjs2 for years. Mozilla's RFP pref defeats most of this (fonts, multiple window metrics, hardware, timing, etc etc). The key to FP'ng is that it is a worst case scenario (always do your tests allowing all JS etc), but in really you control most if it by limiting JS and 3rd parties.
- fingerprinting - The difference I actively detect fingerprinting. And when detected, I only spoof data to the guilty scripts. So a nice script on the page will be able access the real
navigator.userAgenta naughty script will get a random string. I think this is a fairly novel approach
I am building Privacy Possum as a platform for building heuristics for tracking detection and blocking. But the extension is very new and raw and so I haven't implemented many heuristics yet.
Thanks,
 cowlicks
cowlicks
All 12 comments
Hi @cowlicks Thanks for dropping by :)
Please don't take anything I say as an affront - it's all questions/discussion. And also note my ignorance re the extension, as I have not installed it or looked at it's settings (if there are any). I am, at this stage, just going off what your repo etc says it does (and I totally get that PP is new and a work in progress).
Just some background: this user.js doesn't have an actual manifest or design document, but basically it's the same as TBB (Tor Browser Bundle) - see this (which is all a bit tattered with edits over the years and some parts are out of date).
So essentially, we're concerned with as little persistent data storage as possible, separation of app and OS/other-apps, and of course security, tracking, privacy, anonymity, anti-FP'ing etc. Users can ramp up or relax some of those aspects as they wish.
First of all, personally, I think FP is slightly over-hyped. By that I mean you can stop most of it by limiting 3rd parties, and JS. That's the other mantra I push - default deny and then whitelist, whether that is cookies or JS or header referers etc. However, that is not practical for most users. And some FP'ing is server side (or even via CSS) - not to say that most of them can't be mitigated of course.
When it comes to FPing, we subscribe to the theory that lowering entropy is the way to go - you don't have to agree with that, but personally here's why I do
- entropy figures should be looked at in buckets that make sense. eg since it's impossible to fully hide your browser (Firefox, Chrome etc e.g. feature detection and 3 dozen other methods), then it pays to only look at numbers per browser.
- spoofing is HARD, really f^^kng hard - just looking at the UA string it's almost impossible to properly spoof all of it. Look at the Tor Uplift, and 5 or 6 years since Panopticlick came out and they still can't do it: they only just decided that spoofing the OS was futile, they do not bother to spoof the browser from Firefox. They do not bother to spoof the language (instead they expect you to use the built in language settings/UI and actually use
en-US) etc. Spoofing is really hard. Note on OS: they do spoof as win64 for windows, and after win/mac/android everything else is "linux" - even then you can determine linux flavors from scrollbar widths etc. Spoofing is really hard. - there are minuscule numbers of users who raise entropy (and tiny numbers who try to lower it as well), the vast majority of users do nothing
- users who lower entropy are already in a large set (eg 90% of FF users are very quickly onto the stable release - so maybe 8 to 9 % of users are on ESR). So not spoofing your UA (i.e 9 in 10 FF users, or about 10% of desktop users, or 5% of worldwide users, sucks FF has such a low share in mobile - ignore mobile as FF on android is a rounding error - focus on dekstop) .. or spoofing as per
privacy.resistFingerprintingas ESR ... among FF users you're going to look like about 9 million (or 90 million) other users on that ONE METRIC. This is lowering entropy, as you know. - users who raise entropy will probably/potentially stand out (because there are other ways to FP as well), and the numbers will never be achievable (60% of FF users only have 1 extension or none?). Most users have no knowledge, no tech skills, or don't care.
- the ONLY way to build an effective anti-FP'ing mechanism is with numbers, and you will only ever achieve that when it is driven and front facing within Firefox itself. One that will get uptake when it is ready and exposed. RFP (privacy.resistFingerprinting) will get a UI option. RFP lowers entropy. Betting against this strategy only makes you an outlier.
- Note: if RFP decided to randomize by raising entropy, that would have worked as well, since it would have the numbers of users doing it, and ALL RFP users would be the same. However, it wouldn't work, because there would be too much web site breakage (case in point, OS spoofing was abandoning due to this), the same would apply to not lying about the browser make. All they could really do is lie about the version (which is what they do now). So it makes no sense in that regard.
- TL;DR: I trust the experts, science, math, Tor Uplift and my 4 or 5 years of reading and research about this, that lowering entropy is the ONLY way to go.
I am not sure what other FP'ing you spoof, but on UA alone, randomizing it goes against everything we've said and stood for.
This is getting rather long, and there are other issues / questions. But I'll just post this for now
 Thorin-Oakenpants
on 25 Apr 2018
Thorin-Oakenpants
on 25 Apr 2018
One other quick mention:
And when detected, I only spoof data to the guilty scripts
This makes no sense to me. By randomizing the UA, you now need? to allow innocent script to work due to breakage? How can you truly tell if a script is guilty. This is approach allows false positives and holes. Again, I go back to the default deny - any solution should apply in all circumstances.
Currently I remove inbound 3rd party ETag headers
ETags for example: there is no real data that I know of for this in the wild, and even IF 3rd party ETags were more common than 1st party, HOW would you know if a first party ETag was nefarious (yes, I understand that you can read the value and if it's not a date its probably dodgy - from my limited knowledge on the header type). I actually personally find zero issues with speed etc by blocking all ETags. That's not to say that a smart approach can't improve it.
Thorin-Oakenpants
on 25 Apr 2018
@Thorin-Oakenpants indeed reducing entropy for fingerprinting is very important. I think that is the only approach to take for a privacy hardened system. However that is not the threat model I am working against. I do not care if a script is __truly__ guilty.
My goal is to attack the most profitable tracking vectors for tracking companies. I want to cost them as much money as possible.
So I'm not asking the question "Is it possible to circumvent this?" I am asking "Is it cost-effective for a tracking company to circumvent this?". If the answers to these questions are "yes, no", I'll happily include them. I don't think TBB would.
I think approaching the tracking problem from an economic angle like this will ultimately help shift the internet into a more privacy preserving direction (with the help of technical, and political approaches as well).
I will try to explain this better in the README.
cowlicks
on 25 Apr 2018
I do not care if a script is truly guilty.
On FP'ing:
It doesn't matter if you block an "innocent" script, it's the ones you let thru that are "guilty" that worries me. How can you quantify if a script is guilty or not?
I totally get that in the real world, there are legitimate uses for these things, and if you look at TBB they tend to disable APIs (for example), while the Tor Uplift integrated into Firefox has end users and uptake in mind - where possible, they have allowed a site permission, or fudged measurements instead (i.e way less breakage).
And I also get that there are economies of scale. Lower hanging fruit and all that. But IMO it is impossible to know (and maintain) what is and isn't "feasible". The threat model here is everyone is guilty, and then we mitigate that. Solutions like canvas spoofing in RFP do that - assume everyone is guilty - block all by default but prompt for "user-initiated" ones, and still allow a site permission to allow.
Maybe I'm not following this properly, but I have never seen FP'ng (or tracking eg referers, cookies, persistent storage, SSL session tickets, timing mitigations, etc) ever do anything but assume everyone is guilty.
Thorin-Oakenpants
on 26 Apr 2018
@cowlicks - FYI: ghacks article
Thorin-Oakenpants
on 7 May 2018
Good discussion (so far) at https://old.reddit.com/r/privacy/comments/8hui82/about_fingerprinting/ . I particularly like senperecemo's comment
Thorin-Oakenpants
on 9 May 2018
^^ from senperecemo's comment
Maybe they have a full beard and breasts
What's wrong with that. I happen to think this is appealing in dwarf women :smile:
Thorin-Oakenpants
on 9 May 2018
I didn't want to start a whole new issue for this, even though it's somewhat off-topic from this one, but in section 4.1 of the wiki, you say that Privacy Badger shouldn't be recommended since uBO does everything it does. Personally, I still use it even though I use NoScript, uBO, and uMatrix. This is for two reasons. First, unless they are perfectly configured (and possibly even then, since nothing is perfect), which is difficult to do, some stuff might slip through, and though it happens very infrequently, I do sometimes get PB catching stuff. Second, and probably more importantly, when a site is broken, sometimes I'll totally disable uBO and/or uM to see if they're the cause before spending time configuring them to get the site to work. Having PB running provides some protection while I do this, and I haven't had an issue yet where, even with this extra protection, it has been a contributing factor to a site's breakage.
Additionally, for users that might be less apt with uBO/uM, and might just whitelist a site in them to get it working (which I, myself, have done before when I didn't want to spend the time right then to mess with it), PB would, again, still be providing at least some protection. So I wouldn't write it off completely. And, of course, the same applies to PP, which I only just learned about through this issue and I will be keeping a close eye on and will probably switch to once it's matured a bit more.
 vertigo220
on 14 May 2018
vertigo220
on 14 May 2018
Regarding Privacy Badger, there's a wiki entry here, note how the test was done (PB was tested after having loaded sites three times), due to the permissive nature of PB (it blocks only after recursive pings to 3rd parties).
 Atavic
on 19 May 2018
Atavic
on 19 May 2018
First of all, @cowlicks Good work, keep up the good fight, best of luck. I have had a little play with PP, and my findings / thoughts below are based on what this repo attempts to do, and are just my thoughts. Sorry for the long post
:small_orange_diamond: fingerprinting
From the github readme
Instead when we see first party fingerprinting, we inject random data to spoil the fingerprint. Visit valve.github.io/fingerprintjs2 to see this. "get your fingerprint" multiple times, and see it change each time.
And from the comparison notes
Testing on fingerprintjs2's test page, PP spoofs 11 fields
See it change each time, spoofs 11 fields : this is in direct contrast to lowering entropy and conflicts with privacy.resistFingerprinting.
In testing (vanilla profile FF60) I found at least 12 items constantly randomly spoofed (excluding the deduced has lied results). Also DNT is sent as true (this overrides FF internal setting which we have as default only in PB mode) - why isn't this random as well? If the idea is to raise entropy, this should be random.
sample (of those 12 items), long strings I have truncated
user_agent = rdtfwx5blc
language = n39dr5v2awb
color_depth = 30
pixel_ratio = 1.434476809392379
hardware_concurrency = 6
resolution = 2623,1050
available_resolution = 2082,988
timezone_offset = 96
navigator_platform = 4hk2l7uyu69
regular_plugins = wz2ko1d5dn::k8v1123v19
webgl = jn9lh8iqxni
touch_support = 1,false,false
When PP's FP spoofs kick in (not entirely sure when or if it decides that), these certainly help make you unique (which is the point), but I wonder if the gibberish strings will cause breakage.
PP currently has 1400 users in FF. When FP is used (the key is to block unnecessary 3rd party and JS in the first place), i.e worst case scenario, you are very unique, as in how many people always spit out short garbage strings for UA + lang + platform and have such a random pixel ratio and plugins (which can be blank) is also gibberish. Not sure about the timezone offset, is that hours? I am not an expert, but If hours, then surely it should be -12 to +12? and if minutes, then non half or whole hours seems too precise. IMO, random spoofing should at least be plausible. With the above approach, you're actually making yourself very FP'able, IMO.
My main issue is really with when it decides to spoof (and the other blocks). I do not see the point in differentiating between 1st and 3rd party.
Reddit for example uses fingerprintjs2. Does PP detect and stop this? (becuase 1st party?, slow heuristics? IDK). Reddit can already track you across their own domain, but this deeper FP can link different sessions/IPs
Long story short, the FP part of PP clashes with RFP, and the random spoofing is too unique. The spoofing is not applied everywhere
:small_orange_diamond: cookies + referers + etags
As already mentioned, 3rd party cookies are already blocked in our user.js and is available in FF's preferences UI. Multiple cookie extensions exist to deal with all cookies, and on top of that FPI and containers (especially Temporary Containers) and one-off PB mode windows etc all help isolate cookies.
As for referers, at the end of the day, if you want any real control, you need a dedicated extension - we already have uMatrix with a default spoof if needed, otherwise Smart Referer is far more powerful. And for etags, I do not get why only 3rd party are covered here (as this does nothing for 1st party tracking), and we have a current etag solution (plus the Header Editor extension allows further scope in manipulation headers).
With regards to cookies + referers + etags, I don't think PP brings anything new here not already covered in this repo
:small_orange_diamond: usage
I only used the extension and played around for half an hour. PP is still being developed, but currently there are no global switches. I think there are only two settings here (not that the code can't change): they are "fingerprinting" and "tracking headers" (which is a combined referer + cookie + etag switch).
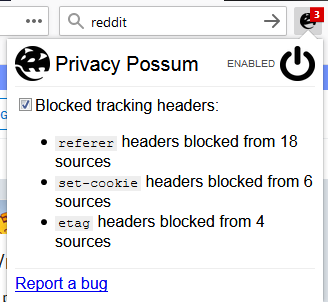
So currently, you can't globally disable any aspect of the extension, such as FP, and use the rest. And the rest is bundled into a single setting, so you couldn't for example, disable etag but keep referer.
:small_orange_diamond: conclusion
All the best, but in all honesty, in recommending a Firefox setup for privacy / security / anti-FP'ing / anti-Tracking .. this extension just does not fit. The anti-FPing alone is a deal breaker, and the rest offers nothing new (IMO).
Thorin-Oakenpants
on 23 May 2018
@Thorin-Oakenpants thank you for the thorough overview! I agree with your conclusion that Privacy Possum does not fit here. I'll answer a few of your questions just for clarity's sake (not to re-open this):
When PP's FP spoofs kick in (not entirely sure when or if it decides that),
When any given script touches more than %60 of the list of these fingerprinting propertise kick in.
but I wonder if the gibberish strings will cause breakage
The gibberish is only fed to the script marked as fingerprinting, to reduce potential of breakage. So if there are two scripts running in the same page fp.js is fingerprinting, normal.js is not, then PP will only feed bad data to fp.js. We do this by tracing all access to fingeprinting properties (linked above).
I do not see the point in differentiating between 1st and 3rd party.
Many sites package their fingerprinting code alongside code necessary for the website to function, but this usually only happens in a 1st party context. Reddit does this. Blocking the script that does reddit's fingerprinting also breaks reddit. So instead we allow it to load and feed it bad data. This is why we make the distinction.
Reddit for example uses fingerprintjs2. Does PP detect and stop this?
Yes
Thank you again for the review! I hope that eventually PP's heuristics will be modular enough that they can be extracted induvidually and made useful in other places.
cowlicks
on 24 May 2018
Thanks for the info :+1: and for being one of the good guys :kiss:
Thorin-Oakenpants
on 25 May 2018
Related issues
 crssi
·
3Comments
Thorin-Oakenpants
·
4Comments
Thorin-Oakenpants
·
3Comments
crssi
·
3Comments
Thorin-Oakenpants
·
4Comments
Thorin-Oakenpants
·
3Comments
 zdat
·
5Comments
Thorin-Oakenpants
·
7Comments
zdat
·
5Comments
Thorin-Oakenpants
·
7Comments