Ublock: HTML filtering can break encoding
Describe the issue
HTML filters convert text to Unicode, but Firefox still chooses language-based encoding.
One or more specific URLs where the issue occurs
https://vk.com/rbc
https://new.pikabu.ru/best
Screenshot in which the issue can be seen
Steps for anyone to reproduce the issue
- Visit vk.com/rbc. You can see correct Russian text on the page. Check your encoding: it should be
Cyrillic (Windows).
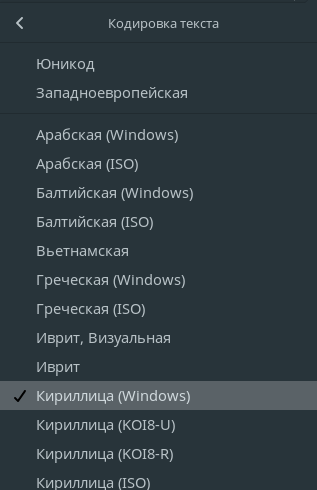
- Hide something using HTML filtering. For example,
vk.com##^.current_text. - Refresh the page. Now you can see broken text. Check encoding: it is still
Cyrillic (Windows). - Select Unicode. Now the text is correct.
Your settings
- OS/version: Debian GNU/Linux
- Browser/version: Mozilla Firefox 57.0.3
- uBlock Origin version: 1.14.23b10
 hant0508
hant0508
All 5 comments
Thanks for the report, it's going to involve some investigation/thoughts.
uBO uses TextEncoder to convert back the modified DOM into a buffer array expected by the browser's StreamFilter. TextEncoder however does not allow to encode into anything else than utf-8. I made uBO add a <meta charset="utf-8"> at the top of the DOM to be sure the browser decode properly the data, however this does not seem to work in your repro case.
So I will need to investigate about what can be done, if anything.
Ultimately, I figure if all fail and nothing can be done when using TextEncoder, I might have to consider custom encoders, possibly using WebAssembly, if I want HTML filtering to be available to more than just utf-8-encoded pages.
 gorhill
on 2 Jan 2018
gorhill
on 2 Jan 2018
I made uBO add a
Just checking. You meant <meta charset="utf-8">. = missing in your reply.
 harshanvn
on 2 Jan 2018
harshanvn
on 2 Jan 2018
Ok initial findings suggest I will have to create encoders. For when a document is encoded in a charset for which there is no encoder, response data modification will have to be forfeited.
gorhill
on 2 Jan 2018
I think I will go on a usage basis. According to this page, probably worth to provide encoding for the top most likely:
charset | usage Jan 2018
---- | ----
UTF-8 | 90.5% (nothing to fix)
ISO-8859-1 | 4.3% (fixed)
Windows-1251 (case here) | 1.5% (fixed)
Shift JIS (#3399) | 0.8%
Windows-1252 | 0.7% (fixed)
GB2312 | 0.6%
... |
Windows-1250 (#3397) | 0.1% (fixed)
Total fixed | 97.1%
gorhill
on 2 Jan 2018
The Shift_JIS and GB2312 mapping will have to be loaded dynamically, on a per-need basis, these are huge character sets.
gorhill
on 6 Jan 2018
Related issues
 KonoromiHimaries
·
3Comments
KonoromiHimaries
·
3Comments
 splattadat
·
4Comments
gorhill
·
3Comments
gorhill
·
4Comments
splattadat
·
4Comments
gorhill
·
3Comments
gorhill
·
4Comments
 FuglyLookingGuy
·
3Comments
FuglyLookingGuy
·
3Comments
Most helpful comment
I think I will go on a usage basis. According to this page, probably worth to provide encoding for the top most likely:
charset | usage Jan 2018
---- | ----
UTF-8 | 90.5% (nothing to fix)
ISO-8859-1 | 4.3% (fixed)
Windows-1251 (case here) | 1.5% (fixed)
Shift JIS (#3399) | 0.8%
Windows-1252 | 0.7% (fixed)
GB2312 | 0.6%
... |
Windows-1250 (#3397) | 0.1% (fixed)
Total fixed | 97.1%