Turing.jl: Abstract out inference procedures
At the last JuliaCon we (@yebai, @willtebbutt) talked briefly about abstracting out inference procedures so that we can have a common interface for different libraries. DynamicHMC by @tpapp is a good example of this package.
I and a few others work on Omega.jl, Mostly we've been working on getting the foundations right, which are a little different to Turing and most other PPLs. But they're mostly stable now and I intended to start working on implementing a variety of inference procedures in Omega, but thought I would consult Turing people first to see if you wanted to avoid redoing work.
If we wanted to do this, there are a bunch of technical issues to resolve. DynamicHMC is easily abstracted out because it requires only a function which computes the gradient of the negative log density. I imagine it might be more difficult to do the same for other inference procedures which require more intricate access to and information about the model.
It may be too difficult or not worth while to separate out inference procedures, which is also fine.
 zenna
zenna
All 8 comments
Hi @zenna!
Similar thoughts have been discussed in the Turing team before. In particular, currently we have Inference and Core submodules of the Turing module, where Inference hosts the inference algorithm implementations and Core has all the book-keeping and model definition stuff. The problem is that Inference currently accesses very internal fields of structs and some low level functions defined in Core which makes it hard to de-couple them. However, this de-coupling is an important step towards a meaningful abstraction that is usable by others. One step we talked about for the near future is to try to make the Core functions used in Inference more "macroscopic" in the sense that they map to semantic functionality required by the inference algorithms. This makes it then possible to identify these high level functions required by the various inference algorithms. Then it should be possible for you to define these functions for your model type and the Turing sampler to "reuse" just the inference algorithm implementation from Turing without the Turing Core/model/backend. Each inference algorithm can have its documented set of functions that you need to define for your model type to use the algorithm's implementation in Turing. Perhaps, this can also be useful for the GP work of @willtebbutt .
So roughly speaking, Turing can serve 2 purposes:
- A package for inference algorithm implementations, e.g. HMC and particle samplers, which can be used for your custom backend/model type,
- A package that manages the model definition and book-keeping, i.e. our own backend, and hooks it into our inference algorithm implementations in the same way that any external backend would.
This kind of design can also make it easier to:
- Experiment with various backend implementations without messing with the inference code,
- Optimize the inference and backend codes separately,
- Introduce any new specialized backend that makes certain assumptions about the model, e.g. fixed length parameters, immutability, etc. thus unlocking further optimizations which are not possible in the general case, and
- Wrap or implement any new inference algorithm in Turing which only requires the set of high level functions already defined for the Turing backend, no need to tamper with
Coreinternals.
This is all very much still in the brainstorming phase, so there may be a lot practical challenges to be overcome, but I think this is a direction worth pursuing. Once all the abstractions have been figured out and made inside of Turing, we can also consider separating out the Inference module into a separate lighter package for those who want to use only the inference bit of Turing.
 mohamed82008
on 16 May 2019
mohamed82008
on 16 May 2019
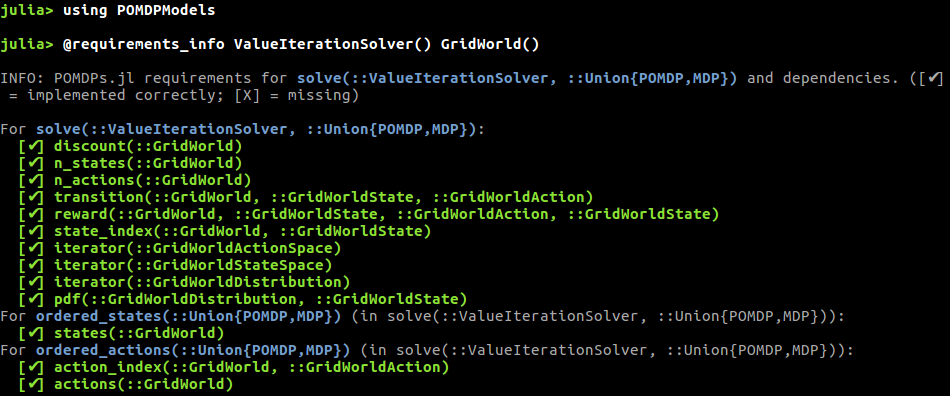
This makes me think a little about POMDPs.jl. I haven't looked at the code but in their case there are several kinds of solvers, which can be quite different (discrete, continuous, sampling based, explicit table, etc) and different kinds of model. They have a "requirements" system. In their words:
Due to the large variety of problems that can be expressed as MDPs and POMDPs and the wide variety of solution techniques available, there is considerable variation in which of the POMDPs.jl interface functions must be implemented to use each solver. No solver requires all of the functions in the interface, so it is wise to determine which functions are needed before jumping into implementation.
Solvers can communicate these requirements through the @requirements_info and @show_requirements macros. @requirements_info should give an overview of the requirements for a solver, which is supplied as the first argument, the macro can usually be more informative if a problem is specified as the second arg. For example, if you are implementing a new problem NewMDP and want to use the DiscreteValueIteration solver, you might run the following
I think these requirements basically boil down to the functions that an inference procedure requires and what a model should produce
zenna
on 16 May 2019
Very cool approach! There is also a similar approach in MathOptInterface. You can write your own optimization solver and then support certain classes of problems by defining some methods for your solver. Most solvers support only a specific class of problems each. These methods are then used to send a JuMP model to your solver and then query the results.
mohamed82008
on 16 May 2019
It's also worth noting here that we're working on building a common MCMC interface (see #746) which will hopefully provide a set of common standards that'll make hot-swapping inference a bit easier. We've also got some nifty stuff happening to put up some firewalls in Turing's internals, like (#750 and #634).
A goal we might shoot for to make integrating Turing's back end with the rest of Julia's probabilistic ecosystem easier is a cohesive set of technical documents specifying our "dream specs".
 cpfiffer
on 16 May 2019
cpfiffer
on 16 May 2019
It would be interesting to see some concrete examples where the abstraction would be a benefit.
I think that, in contrast to multivariate optimization, inference algorithms are much more tightly coupled to particular ways of formulating problems for each algorithm. Eg HMC is probably the most efficient general non-approximate algorithm, but it is very easy to run into medium-size problems which need a reparameterization or some other trick to avoid catastrophic mixing or ineffective sampling.
Thus my approach to MCMC in Julia has been writing components that each handle a part of the problem, are able to cooperate nicely but at the same time I can replace or skip one or more of them (eg code the gradients manually, skip or tweak adaptation, etc).
 tpapp
on 16 May 2019
tpapp
on 16 May 2019
Can a common bayesian IR through ModelingToolkit.jl help here
 datnamer
on 17 May 2019
datnamer
on 17 May 2019
@marcoct
zenna
on 17 May 2019
@cscherrer
datnamer
on 17 May 2019
Related issues
 trappmartin
·
6Comments
trappmartin
·
6Comments
 skanskan
·
5Comments
skanskan
·
5Comments
 ClaudMor
·
4Comments
ClaudMor
·
4Comments
 willtebbutt
·
4Comments
willtebbutt
·
4Comments
 yebai
·
6Comments
yebai
·
6Comments