Transformers: Summarization Fine Tuning
❓ Questions & Help
Details
I tried using T5 and Bart but the abstraction summarization on scientific texts does not seem to give the results I want since I think they are both trained on news corpora. I have scraped all of the free PMC articles and I am thinking about fine-tuning a seq2seq model between the articles and their abstracts to make an abstractive summarizer for scientific texts. This Medium article (https://medium.com/huggingface/encoder-decoders-in-transformers-a-hybrid-pre-trained-architecture-for-seq2seq-af4d7bf14bb8) provides a bit of an introduction to how to approach this but does not quite go into detail so I am wondering how to approach this.
I'm not really asking for help being stuck but I just don't really know how to approach this problem.
A link to original question on Stack Overflow:
https://stackoverflow.com/questions/61826443/train-custom-seq2seq-transformers-model
 kevinlu1248
kevinlu1248
All 79 comments
First thing you can try is fine-tune T5/BART for summarization on your corpus and see how it performs.
 patil-suraj
on 18 May 2020
patil-suraj
on 18 May 2020
@patil-suraj where can I find a guide to this? I'm a bit confused by the documentation.
kevinlu1248
on 18 May 2020
Here's the official example which fine-tunes BART on CNN/DM, you can just replace the cnn/dm dataset with your own summerization dataset.
patil-suraj
on 18 May 2020
@patil-suraj Thanks for the example. I'm wondering if there is any simpler way to get started since I'm planning on training it in a Kaggle notebook due to GPU constraints, because otherwise I may need to copy paste entire folder into a Kaggle notebook.
kevinlu1248
on 18 May 2020
@kevinlu1248
This colab shows how to fine-tune T5 with lightening. This is just the self-contained version of official example. You should be able to use the same Trainer, just replace the model with BART and use you own dataset.
patil-suraj
on 21 May 2020
@patil-suraj Thanks, I'll look into it.
kevinlu1248
on 21 May 2020
Here's the official example which fine-tunes BART on CNN/DM, you can just replace the cnn/dm dataset with your own summerization dataset.
Hi @patil-suraj, I am following that example and have my data in that format, and I can see the process using GPU/CPU, but I can't get tensorboard working. Do you have any hints? I am happy to contribute to documentation once I get it working.
 sam-qordoba
on 23 May 2020
sam-qordoba
on 23 May 2020
@sam-qordoba lightning handles logging itself and by default the tensorboard logs are saved in lightning_logs directory. So you should be able see the logs by passing lightning_logs as the logdir to tensorboard command.
patil-suraj
on 23 May 2020
Thanks @patil-suraj
sam-qordoba
on 23 May 2020
Hey @patil-suraj, I had OOM issues on Colab, so moved to a VM with 56GB RAM, and the behaviour is the same as on Colab: memory usage grows, until it uses up everything available (I even added 32GB of swap, so, it's a really impressive amount of memory usage), until I get locked out of the machine... and the only time it writes to lightning_logs is right when it starts.
jupyter@pytorch-20200529-155153:~/lightning_logs$ tree
.
└── version_0
├── events.out.tfevents.1590794134.pytorch-20200529-155753.8733.0
└── hparams.yaml
1 directory, 2 files
nvidia-smi looks like this:
jupyter@pytorch-20200529-155753:~$ nvidia-smi
Sat May 30 00:07:12 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 77C P0 35W / 70W | 2579MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 8733 C /opt/conda/bin/python 2569MiB |
+-----------------------------------------------------------------------------+
The cell trainer.fit(model) outputs the model definition, but no progress bar on anything,
| Name | Type | Params
-----------------------------------------------------------------------------------------------------------------
0 | model | T5ForConditionalGeneration | 222 M
1 | model.shared | Embedding | 24 M
2 | model.encoder | T5Stack | 109 M
...
514 | model.decoder.block.11.layer.2.dropout | Dropout | 0
515 | model.decoder.final_layer_norm | T5LayerNorm | 768
516 | model.decoder.dropout | Dropout | 0
517 | model.lm_head | Linear | 24 M
Selected optimization level O1: Insert automatic casts around Pytorch functions and Tensor methods.
Defaults for this optimization level are:
enabled : True
opt_level : O1
cast_model_type : None
patch_torch_functions : True
keep_batchnorm_fp32 : None
master_weights : None
loss_scale : dynamic
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O1
cast_model_type : None
patch_torch_functions : True
keep_batchnorm_fp32 : None
master_weights : None
loss_scale : dynamic
Sorry to keep bothering you, but do you have any hints? It's hard to know what's going on because it doesn't seem to log
sam-qordoba
on 30 May 2020
It shouldn't take that much memory, did you try reducing the batch size ?
Also seems that you are using fp16 here. I haven't tried it with fp16 yet.
tagging @sshleifer
patil-suraj
on 1 Jun 2020
Ok, I tried fp16 as a "maybe this will use less memory" experiment, I will try without. I tried batch size of 4, could go lower I guess. Should I just double the learning rate each time I halve the batch size, or are other changes needed?
sam-qordoba
on 1 Jun 2020
Could somebody who has fine-tuned BART give me an estimate of how long it takes / how many epochs until convergence? Also any tricks to speed it up (weight freezing etc)?
1 epoch takes c. 150 hrs for my dataset so wondering how many I need...
 alexgaskell10
on 5 Jun 2020
alexgaskell10
on 5 Jun 2020
Sounds like you have a huge dataset?
It's tough to know exactly how many you will need, but for xsum and cnn most of the model's I've need have required 4-6 to converged.
The [original authors] https://github.com/pytorch/fairseq/blob/master/examples/bart/README.summarization.md#4-fine-tuning-on-cnn-dm-summarization-task say 15-20K Steps.
I have had to go down to batch size=1 or 2 on some occasions.
You can use --gradient_accumulation_steps to keep the "effective" batch size (how many examples your model processes per backward pass) consistent.
@sam-qordoba is your Dataset/DataLoader putting all the examples in memory before training? That could be an issue on a large dataset.
 sshleifer
on 5 Jun 2020
sshleifer
on 5 Jun 2020
You can also freeze the BartForConditionalGeneration.model.encoder using the function below to reduce memory cost.
def freeze_part(model: nn.Module):
for par in model.parameters():
par.requires_grad = False
You can also use val_check_interval in lightning to check validation statistics more frequently, but unfortunately your checkpoints will still be saved at the end of every epoch.
sshleifer
on 5 Jun 2020
@sshleifer thanks for coming back with this- all very helpful.
Yes- essentially I am just trying out using BART to for longer docs (arXiv/PubMed) as a baseline to compare more sophisticated methods against. This means training set has 300k samples and only 1 sample fits on the GPU at once (12Gb- using 1,024 input length).
Lots for me to play around with and see what works well. Thanks for your help.
alexgaskell10
on 5 Jun 2020
Yes- essentially I am just trying out using BART to for longer docs (arXiv/PubMed) as a baseline to compare more sophisticated methods against
@alexgaskell10 If you are interested in using BART for long documents then keep an eye here.
https://github.com/patil-suraj/longbart
I'm trying to convert BART to it's long version using longformer's sliding-window attention.
I've been able to replace BART encoder's SelfAttention with LongformerSelfAttention with 4096 max length. Now I'm working on adding gradient checkpointing to allow it to train on smaller GPU's. Hope to finish it soon.
gradient checkpointing and fp16 with '02' opt level should allow to use larger batch size
patil-suraj
on 5 Jun 2020
@patil-suraj thanks for this- adapting BART for LongformerSelfAttention was actually something I was going to start looking into over the next couple of weeks. Thanks for sharing- I'll be sure to give it a go soon.
alexgaskell10
on 5 Jun 2020
Hey @patil-suraj, any updates on your latest progress on LongBART? Thinking about diving into a similar block of work: expanding BART via Longformer
 virattt
on 12 Jun 2020
virattt
on 12 Jun 2020
Hi @virattt , I've been able to replace bart encoder's self attention with sliding window attention. Also added gradient checkpoiting in the encoder.
Gradient checkpoiting in decoder is not working so going to remove it for now. Will update the repo this weekend and will put some instructions in the readme.
patil-suraj
on 12 Jun 2020
Sounds great, thanks @patil-suraj
virattt
on 12 Jun 2020
Would love to hear LongBart experimental results whenever they are available!
sshleifer
on 12 Jun 2020
@sshleifer I have been playing around with LongBart recently and have some preliminary experimental results. This is using @patil-suraj 's longbart repo fine-tuned on the PubMed dataset using the hf summarization finetune.py script.
The best result so far is ROUGE-1 = 36.8 (for comparison, fine-tuning vanilla BART on PubMed and truncating articles at 1024 tokens I got 42.3 ROUGE-1). I have only run a few configs so far and will be running many more so I expect this to improve. Next steps:
- Have been only using a 12Gb GPU so far so have frozen the embeddings and encoder otherwise too large. I have a much larger cluster I can move to so will start running trials on this soon which will give more freedom to try different configs
- I am only fine-tuning at the moment. Might explore doing some pre-training although this may be too expensive.
Let me know if there is anything you would like to see and I'll try to schedule it in.
alexgaskell10
on 1 Jul 2020
Hi @alexgaskell10 , did you use the code as it is ? I think we'll need to train the embeddings for few epochs then we can freeze it.
However without freezing the embeddings I ran into OOM halfway through the epoch even with bart-base with '02' fp16 on 16GB V100.
@sshleifer do you have any ideas why this might be happening ? It went well till 60% of first epoch then OOM. Batch size was 1 and max_seq_len 4096 ?
@alexgaskell10 can you share more details, how many epochs, batch size, fp16 or not ?
patil-suraj
on 1 Jul 2020
Yes, I used the code as is (minor changes to integrate with hf finetune.py script). I agree that the embeddings and encoder should not be frozen from the beginning but I couldn't fit it on my 12Gb GPU. Once I get setup on the cluster I'll try this.
More details on all my runs so far can be found in my wandb project. To answer your question, max a couple epochs so far, batch size between 4 and 16 depending on what fits, not fp16 so far (haven't set up yet but will do soon).
alexgaskell10
on 1 Jul 2020
Thanks @alexgaskell10 , I think you'll be able to use bart-base with fp16 and max 2048 seq len without frezzing embdddings on 12GB GPU
patil-suraj
on 1 Jul 2020
@patil-suraj:
- 4096 is a very large max_seq_len, but I know that doesn't answer your question. I would guess that the answer is that you got a really big batch. The batches are not all the same size. We trim them to save padding computation. If you are on one GPU you can use
--sortish_samplerwhich ensures that the first batch is the largest, so you get OOM at the beginning of the epoch at least. You also get hopefully a further reduction in padding computation. - I would be interested to know how much
--sortish_samplerreduces the training cost of 1 epoch with other parameters fixed.
@alexgaskell10 :
Thanks for sharing your wandb, it makes understanding what you're doing way easier.
- From pegasus Table 2, it seems like SOTA for PubMed is around
45.49/19.90/27.69. (Rouge 1, Rouge 2, Rouge L) So there is still some headroom! (Note we will add pegasus in the library sometime in July). - From looking at your wandb logs, your models are still getting better when training stops. When you move to a beefier setup you might consider training for longer.
- I think there is general consensus that Rouge2 and Rouge-L are better metrics than Rouge-1.
Some questions I would love to know the answer to (for any dataset):
- which
--model_name_or_pathis the best starting point for finetuning: bart-base vs. bart-large vs. bart-large-xsum vs distilbart-xsum-12-6, for example. - How does
LongBartcompare in performance toBartForConditionalGeneration? - Does increasing
--adam_epsimprove performance? Jeremy Howard at fastai recommended this once, and the default 1e-8 seems to be a fairly low setting. - What is the impact of
--freeze-encoderand--freeze_embedson time per epoch, max batch size, and performance.
sshleifer
on 1 Jul 2020
@sshleifer thanks for coming back to me. Several of your questions I can answer immediately, the others I will try to take a look at. If you're interested, I have a separate wandb project containing a bunch of fine-tuning runs for BartForConditionalGeneration on PubMed to act as a baseline for Longformer. All of these runs have frozen embs and enc because of size constraints- only batch size 1 or 2 fit on GPU and that didn't perform well. If I get a bigger setup I'll try with these unfrozen and a larger batch size.
Addressing your questions:
- I have been using facebook/bart-large-cnn so far- will investigate if I get time
- This can be seen in the two wandb repos I've shared here and above. So far my best
BartForConditionalGenerationis 0.426/0.177/0.263 and my bestLongformeris 0.367/0.120/0.222 so BART is much better so far. However, both of these have frozen embs and enc (and presumably PEGASUS was fine-tuned without these frozen) so there are more experiments to run - Haven't looked at this. Will give it a go
- Freezing both has a big impact (haven't looked at freezing each separately).
- Time per epoch I think order of 3-4x quicker (8hrs vs 24+hrs per epoch using 12Gb GPU)
- Batch size >8x improvement (2 vs 16)
- Performance seemed much better when frozen. Probably due to small batch size training was unstable when using a small batch size. The img below shows a comparison between frozen (grey, bsz=16) and unfrozen (blue, bsz=2).
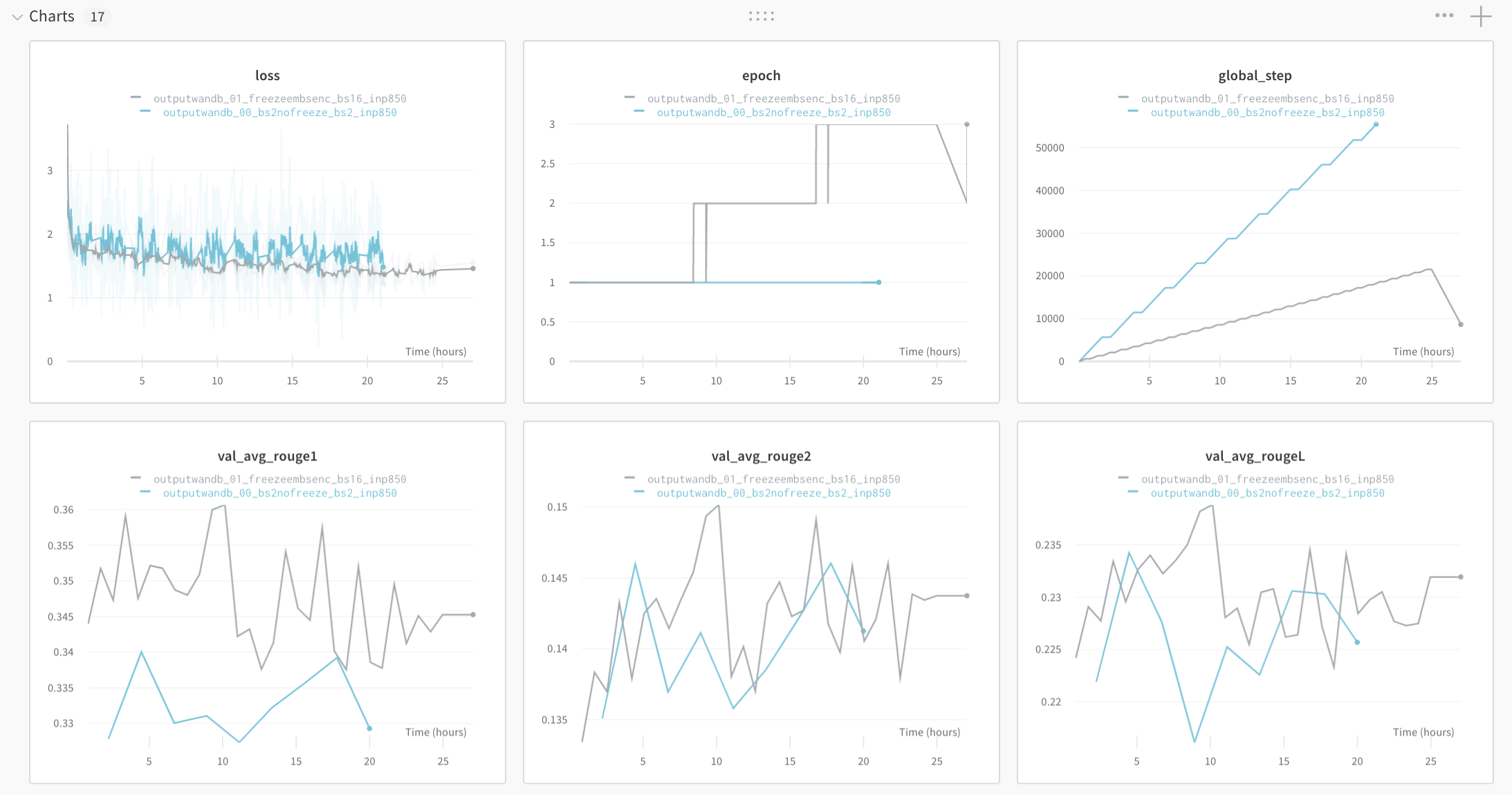
alexgaskell10
on 1 Jul 2020
BartForConditionalGeneration is 0.426/0.177/0.263 and my best Longformer is 0.367/0.120/0.222
There's a bug related to masking that could be the reason for the performance drop. I started working on LongformerEncoderDecoder and have a fix here.
 ibeltagy
on 6 Jul 2020
ibeltagy
on 6 Jul 2020
Thanks for flagging, I will take a look.
In any case, I have much better LongBart results now (0.433, 0.189, 0.273). I found that fine-tuning LongBart without freezing the embs or enc worked much better, whereas Bart performed better when embs and enc were frozen. This probably makes sense given that LongBart is using weight transfer so needs more comprehensive training to be effective. Hopefully the bug fix will improve these results even more.
alexgaskell10
on 6 Jul 2020
Is this still with seqlen=1024? what is the maximum seqlen your dataset requires?
ibeltagy
on 6 Jul 2020
The above results are using seqlen=1024 and window size=512 (only using a 12Gb GPU currently so nothing larger fits; I'm trying to get a beefier setup sorted). This is PubMed dataset so max seqlen is well above this, probably in the region of 6k tokens.
I did experiment with using longer inputs with enc and embs weights frozen and it didn't improve performance. My hypothesis is that using longer inputs for PubMed doesn't actually help as the abstract is often extractive from the introduction so using longer inputs doesn't help- I'll test this once I get the bigger setup. Pegasus is SOTA and I believe it only uses the introduction...
alexgaskell10
on 6 Jul 2020
window size=512
Just an FYI, this is one-sided window size. The actual window size is 1024.
only using a 12Gb GPU currently so nothing larger fits
I added gradient checkpointing which will help. With 12Gb I think you can run the large model with seqlen=4096.
This is PubMed dataset so max seqlen is well above this, probably in the region of 6k tokens.
With fp16, gradient checkpointing and 48Gb gpu, I was able to run the large model on seqlen=12k. I have the pretrained model and gradient checkointing instructions in the readme. This is still early WIP though.
ibeltagy
on 6 Jul 2020
Just an FYI, this is one-sided window size. The actual window size is 1024.
Ah ok, thanks for flagging.
I added gradient checkpointing which will help. With 12Gb I think you can run the large model with seqlen=4096.
Will take a look, thanks!
alexgaskell10
on 6 Jul 2020
Hi @ibeltagy , Thank you for the LongformerEncoderDecoder .
I added gradient checkpointing which will help.
is it only in encoder or in both encoder and decoder ? I've been able to add gradient checkpointing in encoder, but I still got OOM with bart-base, fp-16 with '02', attention window 1024 and max seq len 4096.
I was able to run the large model on seqlen=12k
What is the output length for this ?
patil-suraj
on 7 Jul 2020
both encoder and decoder. The commit is here.
What is the output length for this?
It is pretty small. Maybe I should try it again with a longer output.
ibeltagy
on 7 Jul 2020
With fp16, gradient checkpointing and 48Gb gpu, I was able to run the large model on seqlen=12k. I have the pretrained model and gradient checkointing instructions in the readme. This is still early WIP though.
@ibeltagy How did you create this pre-trained model? Did you use the create_long_model function from notebook in the readme with the BartLarge model? Or did you use patil-suraj's modified conversion function?
Did you change the position embedding matrix for the decoder in addition to the encoder?
 HHousen
on 12 Jul 2020
HHousen
on 12 Jul 2020
With both longbart and the LongformerEncoderDecoder I get the below error on the line query = query.view(bsz, tgt_len, embed_dim):
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
Anyone have any ideas as to why query is not contiguous?
HHousen
on 12 Jul 2020
@HHousen, the conversion code is here, and yes, it extends the position embeddings of both, the encoder and the decoder.
Anyone have any ideas as to why query is not contiguous?
Not sure, do you have an example to reproduce this error? and can you share the full stack trace? Also, can you try input_ids.contiguous()?
ibeltagy
on 13 Jul 2020
@ibeltagy Thanks. Yep, calling input_ids.contiguous() fixed that problem.
HHousen
on 13 Jul 2020
The issue reappears when using a batch size greater than 1.
Stack Trace:
Traceback (most recent call last):
File "main.py", line 342, in <module>
main(args)
File "main.py", line 96, in main
trainer.fit(model)
File "/usr/local/lib/python3.6/dist-packages/pytorch_lightning/trainer/trainer.py", line 1003, in fit
results = self.single_gpu_train(model)
File "/usr/local/lib/python3.6/dist-packages/pytorch_lightning/trainer/distrib_parts.py", line 186, in single_gpu_train
results = self.run_pretrain_routine(model)
File "/usr/local/lib/python3.6/dist-packages/pytorch_lightning/trainer/trainer.py", line 1196, in run_pretrain_routine
False)
File "/usr/local/lib/python3.6/dist-packages/pytorch_lightning/trainer/evaluation_loop.py", line 293, in _evaluate
output = self.evaluation_forward(model, batch, batch_idx, dataloader_idx, test_mode)
File "/usr/local/lib/python3.6/dist-packages/pytorch_lightning/trainer/evaluation_loop.py", line 470, in evaluation_forward
output = model.validation_step(*args)
File "/content/abstractive.py", line 703, in validation_step
cross_entropy_loss = self._step(batch)
File "/content/abstractive.py", line 686, in _step
outputs = self.forward(source, target, source_mask, target_mask, labels=labels)
File "/content/abstractive.py", line 233, in forward
labels=None, # `labels` is None here so that huggingface/transformers does not calculate loss
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bart.py", line 1041, in forward
output_hidden_states=output_hidden_states,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bart.py", line 901, in forward
output_hidden_states=output_hidden_states,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bart.py", line 333, in forward
x, attention_mask,
File "/usr/local/lib/python3.6/dist-packages/torch/utils/checkpoint.py", line 155, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "/usr/local/lib/python3.6/dist-packages/torch/utils/checkpoint.py", line 74, in forward
outputs = run_function(*args)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bart.py", line 328, in custom_forward
val, _ = module(*inputs, output_attentions=False)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/modeling_bart.py", line 229, in forward
query=x, key=x, key_padding_mask=encoder_padding_mask, output_attentions=output_attentions
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/longformer/longformer_encoder_decoder.py", line 63, in forward
query = query.view(bsz, tgt_len, embed_dim)
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
I called .contiguous() on all of the inputs to the model as a test. I call forward() like so but the problem persists:
outputs = self.model.forward(
input_ids=source.contiguous(),
attention_mask=source_mask.contiguous(),
decoder_input_ids=target.contiguous(),
decoder_attention_mask=target_mask.contiguous(),
use_cache=False,
labels=None
)
The problem is not gradient checkpointing since I have tried with it enabled and disabled yet the error persists.
HHousen
on 14 Jul 2020
With both
longbartand theLongformerEncoderDecoderI get the below error on the linequery = query.view(bsz, tgt_len, embed_dim):RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.Anyone have any ideas as to why
queryis not contiguous?
Hi @HHousen , what was your transformers version ? I've used LongBART successfully with v2.11.0, didn't try it with latest version. I think @alexgaskell10 might be able to help as he's used it extensively.
Anyway, I think you should now use LongformerEncoderDecoder now instead of LongBART
patil-suraj
on 14 Jul 2020
Hi @HHousen, I also had this issue with LongBart (but not LongformerEncoderDecoder). I solved it by replacing the line above with query = query.contiguous().view(bsz, tgt_len, embed_dim) and this fixed it for all batch sizes.
@patil-suraj @ibeltagy I was doing some side-by-side of the LongformerEncoderDecoder and LongBart last week. It seems as though LED is about 30% slower than LongBart- shown by the graph below (the purple line is LongBart, green is LongformerEncoderDecoder on the same machine and y-axis is model steps). I did some quick digging and the two models gave the same outputs for my test cases but I didn't manage to bottom out why the new one is slower than the old before I ran out of time. Just thought I should flag this.
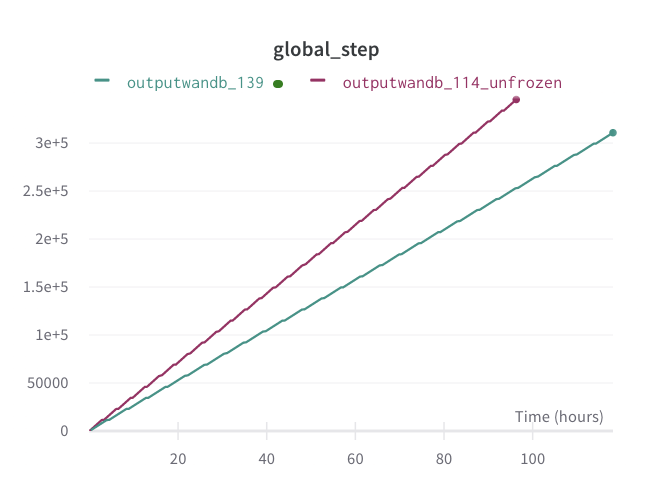
alexgaskell10
on 14 Jul 2020
@HHousen, thanks for reporting.
@alexgaskell10, which version of transformers are you using? there has been a code refactor in v3.0.1, so can you try v.2.11.0 to see if you still get the same speed?
ibeltagy
on 14 Jul 2020
@ibeltagy yes I saw there was refactor, I presume that is the cause. The LED code (green line) is using v.3.0.1 and LongBart code (purple line) uses v.2.11.0. I'm not sure it will be straightforward to run the LED code on v.3.0.1, I tried originally with v.2.11.0 but couldn't get it to work so moved to v.3.0.1.
alexgaskell10
on 14 Jul 2020
@patrickvonplaten, is this something you can help with? I know you have tools to benchmark different models, would it be possible to benchmark longformer v2.11.0 and v3.0.1?
ibeltagy
on 14 Jul 2020
Could it be because of gradient checkpoiting, LongBART uses it only encoder and LED( I like this short form 😄) uses it in both encoder and decoder.
patil-suraj
on 14 Jul 2020
Gradient checkpointing was off for both runs above so can't have been that.
alexgaskell10
on 14 Jul 2020
Hi @HHousen , what was your transformers version ? I've used
LongBARTsuccessfully withv2.11.0, didn't try it with latest version. I think @alexgaskell10 might be able to help as he's used it extensively.
Hi @HHousen, I also had this issue with
LongBart(but notLongformerEncoderDecoder). I solved it by replacing the line above withquery = query.contiguous().view(bsz, tgt_len, embed_dim)and this fixed it for all batch sizes.
@patil-suraj @alexgaskell10, I have tested LongformerEncoderDecoder with huggingface/transformers versions 2.11.0, 3.0.1 (ibeltagy/transformers version for BART gradient checkpointing), and 3.0.2 and got the same error message that query is not contiguous, despite calling .contiguous() on all inputs.
HHousen
on 14 Jul 2020
@HHousen did you try using .reshape() as the error message suggests? I believe this also worked for me.
alexgaskell10
on 14 Jul 2020
@alexgaskell10 Yes. Changing to .reshape() solves the problem. But you were able to use LongformerEncoderDecoder without making that change, right?
HHousen
on 14 Jul 2020
Yes thats right. I spent quite a while going through the code and made several changes so maybe I changed something else upstream which helped it to work. Can't remember exactly what though!
alexgaskell10
on 14 Jul 2020
@patrickvonplaten, is this something you can help with? I know you have tools to benchmark different models, would it be possible to benchmark longformer v2.11.0 and v3.0.1?
Hmm, yeah it would be great to benchmark the models between v2.11.0 and v3.0.1. The easiest would probably be to just switch between master and the 2.11 branch: https://github.com/huggingface/transformers/tree/v2.11.0.
Then just running the benchmark script:
python examples/benchmarking/run_benchmark.py --models longformer-base-4096
should be good enough to compare the performance
 patrickvonplaten
on 14 Jul 2020
patrickvonplaten
on 14 Jul 2020
I ran the benchmark scripts for each version: python examples/benchmarking/run_benchmark.py --models allenai/longformer-base-4096 --training.
Latest master branch:
2020-07-14 18:21:34.487221: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
Downloading: 100% 725/725 [00:00<00:00, 583kB/s]
1 / 1
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 1.031
allenai/longformer-base-4096 8 32 1.015
allenai/longformer-base-4096 8 128 1.037
allenai/longformer-base-4096 8 512 1.028
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 2117
allenai/longformer-base-4096 8 32 2117
allenai/longformer-base-4096 8 128 2117
allenai/longformer-base-4096 8 512 2117
--------------------------------------------------------------------------------
==================== TRAIN - SPEED - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 2.0
allenai/longformer-base-4096 8 32 1.999
allenai/longformer-base-4096 8 128 2.103
allenai/longformer-base-4096 8 512 2.366
--------------------------------------------------------------------------------
==================== TRAIN - MEMORY - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 10001
allenai/longformer-base-4096 8 32 10155
allenai/longformer-base-4096 8 128 10207
allenai/longformer-base-4096 8 512 12559
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 3.0.2
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.5.1+cu101
- python_version: 3.6.9
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-07-14
- time: 18:30:48.341403
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 13021
- use_gpu: True
- num_gpus: 1
- gpu: Tesla T4
- gpu_ram_mb: 15079
- gpu_power_watts: 70.0
- gpu_performance_state: 0
- use_tpu: False
Version 2.11.0 (git checkout tags/v2.11.0):
2020-07-14 18:31:04.379166: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
1 / 1
======= INFERENCE - SPEED - RESULT =======
======= MODEL CHECKPOINT: allenai/longformer-base-4096 =======
allenai/longformer-base-4096/8/8: 0.356s
allenai/longformer-base-4096/8/32: 0.359s
allenai/longformer-base-4096/8/128: 0.364s
allenai/longformer-base-4096/8/512: 0.367s
======= INFERENCE - MEMORY - RESULT =======
======= MODEL CHECKPOINT: allenai/longformer-base-4096 =======
allenai/longformer-base-4096/8/8: 8178 MB
allenai/longformer-base-4096/8/32: 8170 MB
allenai/longformer-base-4096/8/128: 8162 MB
allenai/longformer-base-4096/8/512: 8162 MB
======= TRAIN - SPEED - RESULT =======
======= MODEL CHECKPOINT: allenai/longformer-base-4096 =======
allenai/longformer-base-4096/8/8: 0.357s
allenai/longformer-base-4096/8/32: 0.359s
allenai/longformer-base-4096/8/128: 0.363s
allenai/longformer-base-4096/8/512: 0.366s
======= TRAIN - MEMORY - RESULT =======
======= MODEL CHECKPOINT: allenai/longformer-base-4096 =======
allenai/longformer-base-4096/8/8: 9320 MB
allenai/longformer-base-4096/8/32: 9416 MB
allenai/longformer-base-4096/8/128: 9514 MB
allenai/longformer-base-4096/8/512: 11866 MB
======== ENVIRONMENT - INFORMATION ========
- transformers_version: 2.11.0
- framework: PyTorch
- framework_version: 1.5.1+cu101
- python_version: 3.6.9
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-07-14
- time: 18:34:31.155709
- cpu_ram_mb: 13021
- use_gpu: True
- num_gpus: 1
- gpu: Tesla T4
- gpu_ram_mb: 15079
- gpu_power_watts: 70.0
- gpu_performance_state: 0
I also tested the differences before and after d697b6ca751e7727e92d4fa1de35e5e62fd541fa ([Longformer] Major Refactor (#5219)).
Training time changes:
Before --> After
1.323 --> 1.995
1.353 --> 2.016
1.416 --> 2.094
1.686 --> 2.378
Before d697b6ca751e7727e92d4fa1de35e5e62fd541fa (at commit e0d58ddb65eff1a52572dff75944d8b28ea706d3):
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 0.332
allenai/longformer-base-4096 8 32 0.342
allenai/longformer-base-4096 8 128 0.35
allenai/longformer-base-4096 8 512 0.357
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 2117
allenai/longformer-base-4096 8 32 2117
allenai/longformer-base-4096 8 128 2117
allenai/longformer-base-4096 8 512 2117
--------------------------------------------------------------------------------
==================== TRAIN - SPEED - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 1.323
allenai/longformer-base-4096 8 32 1.353
allenai/longformer-base-4096 8 128 1.416
allenai/longformer-base-4096 8 512 1.686
--------------------------------------------------------------------------------
==================== TRAIN - MEMORY - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 9617
allenai/longformer-base-4096 8 32 9771
allenai/longformer-base-4096 8 128 9823
allenai/longformer-base-4096 8 512 12175
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
- transformers_version: 3.0.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.5.1+cu101
- python_version: 3.6.9
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-07-14
- time: 18:59:34.297304
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 13021
- use_gpu: True
- num_gpus: 1
- gpu: Tesla T4
- gpu_ram_mb: 15079
- gpu_power_watts: 70.0
- gpu_performance_state: 0
- use_tpu: False
After d697b6ca751e7727e92d4fa1de35e5e62fd541fa (at commit d697b6ca751e7727e92d4fa1de35e5e62fd541fa):
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 1.028
allenai/longformer-base-4096 8 32 1.01
allenai/longformer-base-4096 8 128 1.013
allenai/longformer-base-4096 8 512 1.061
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 2117
allenai/longformer-base-4096 8 32 2117
allenai/longformer-base-4096 8 128 2117
allenai/longformer-base-4096 8 512 2117
--------------------------------------------------------------------------------
==================== TRAIN - SPEED - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 1.995
allenai/longformer-base-4096 8 32 2.016
allenai/longformer-base-4096 8 128 2.094
allenai/longformer-base-4096 8 512 2.378
--------------------------------------------------------------------------------
==================== TRAIN - MEMORY - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 9617
allenai/longformer-base-4096 8 32 9771
allenai/longformer-base-4096 8 128 9823
allenai/longformer-base-4096 8 512 12175
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
The current process just got forked. Disabling parallelism to avoid deadlocks...
To disable this warning, please explicitly set TOKENIZERS_PARALLELISM=(true | false)
- transformers_version: 3.0.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.5.1+cu101
- python_version: 3.6.9
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-07-14
- time: 19:10:37.139177
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 13021
- use_gpu: True
- num_gpus: 1
- gpu: Tesla T4
- gpu_ram_mb: 15079
- gpu_power_watts: 70.0
- gpu_performance_state: 0
- use_tpu: False
@patrickvonplaten @alexgaskell10 @ibeltagy The training time increased from tags/v2.11.0 (0.361s) to right before d697b6c (at commit e0d58dd) (1.445s) by 1.084s.
The training time increased from right before d697b6c (at commit e0d58dd) (1.445s) to directly after d697b6c (at commit d697b6c) (2.121s) by 0.676s.
I ran the benchmarks twice and got similar results both times.
HHousen
on 14 Jul 2020
nice finding. Thanks, @HHousen.
@patrickvonplaten, we can check the refactoring more carefully to find the reason for the second slowdown. Any thoughts on what could be the reason for the first one? It is a span of 270 commits!!
ibeltagy
on 14 Jul 2020
Thanks a lot for running the benchmark @HHousen !
Very interesting indeed! I will take a look tomorrow.
The benchmarking tools were changed quite significantly from 2.11 to 3.0.1 => so I will run both Longformer versions (2.11 and master) with the same benchmarking tools tomorrow to make sure that the performance degradation is really due to changes in Longformer.
patrickvonplaten
on 15 Jul 2020
@patrickvonplaten You're correct about the first training time increase. I tracked down the time change to commit fa0be6d76187e0639851f6d762b9ffae7fbd9202. At 18a0150bfa1b47065ce8a8ac22fc1791ed0ac2b3 (right before fa0be6d76187e0639851f6d762b9ffae7fbd9202) the training time is about 0.35s. But at fa0be6d76187e0639851f6d762b9ffae7fbd9202 it's about 1.4s. So the first time increase can be safely ignored because it was caused by a change in the benchmark scripts.
The second time increase, caused by d697b6ca751e7727e92d4fa1de35e5e62fd541fa seems to be the main issue.
HHousen
on 15 Jul 2020
@HHousen @ibeltagy,
I just ran the same benchmarking scripts on different versions and I can confirm that there is quite a drastic slow-down at master.
Here is the branch: https://github.com/huggingface/transformers/tree/benchmark_for_2_11 in case it's useful for you.
My results for master:
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 0.644
allenai/longformer-base-4096 8 32 0.64
allenai/longformer-base-4096 8 128 0.64
allenai/longformer-base-4096 8 512 0.637
--------------------------------------------------------------------------------
Saving results to csv.
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 2023
allenai/longformer-base-4096 8 32 2023
allenai/longformer-base-4096 8 128 2023
allenai/longformer-base-4096 8 512 2023
--------------------------------------------------------------------------------
Saving results to csv.
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 3.0.2
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.5.0
- python_version: 3.7.7
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-07-15
- time: 18:30:00.426834
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32089
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 0
- use_tpu: False
results for 2.11.0:
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 0.144
allenai/longformer-base-4096 8 32 0.144
allenai/longformer-base-4096 8 128 0.144
allenai/longformer-base-4096 8 512 0.145
--------------------------------------------------------------------------------
Saving results to csv.
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
allenai/longformer-base-4096 8 8 2023
allenai/longformer-base-4096 8 32 2023
allenai/longformer-base-4096 8 128 2023
allenai/longformer-base-4096 8 512 2023
--------------------------------------------------------------------------------
Saving results to csv.
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.5.0
- python_version: 3.7.7
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-07-15
- time: 18:39:00.315564
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32089
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 0
- use_tpu: False
It was probably caused by me, when I did the major longformer refactoring... => will investigate more tomorrow!
Thanks a lot for pointing this out @HHousen - this is super useful.
I guess we should have tests that automatically check if the PR causes a significant slow down. (also @sshleifer , @thomwolf, @mfuntowicz )
patrickvonplaten
on 15 Jul 2020
Ok fixed it. @ibeltagy @HHousen - it would be great if you can try again on your end with the current version of master to make sure the inference speed is back to normal.
patrickvonplaten
on 16 Jul 2020
@patrickvonplaten I ran the benchmark on master and the speeds do look to be normal again.
The training speeds are 1.328s, 1.378s, 1.457s, and 1.776s for sequences of length 8, 32, 128, 512 respectively, which is similar to the speeds before the major refactor at d697b6c.
Inference speeds are 0.326s, 0.343s, 0.348s, and 0.367s, which are appear to be back to normal.
HHousen
on 16 Jul 2020
@ibeltagy Should you merge ibeltagy/transformers@longformer_encoder_decoder into huggingface/transformers@master yet to add gradient checkpointing to BART? Or are you waiting for the final LongformerEncoderDecoder implementation to be completed?
HHousen
on 16 Jul 2020
@HHousen, I had to disable certain features of the model here to implement gradient checkpointing, so merging it will require more work.
@LysandreJik started working on gradient checkpointing in this PR https://github.com/huggingface/transformers/pull/5415 and he might have better ideas.
ibeltagy
on 16 Jul 2020
@kevinlu1248
This colab shows how to fine-tune T5 with lightening. This is just the self-contained version of official example. You should be able to use the sameTrainer, just replace the model with BART and use you own dataset.
I modified this example to adapt to the BART. And only use Positive </s> as target , but after training for a epoch, the model output all 0, tensor([[2, 0, 0, 2]]), decoded as '' .
What could be reason for the model failed on such simple task?
Using training_rate = 2*10^-5
 WangHexie
on 2 Aug 2020
WangHexie
on 2 Aug 2020
@WangHexie , not sure. One suggestion, with BART you won't need to manually add at the end as the BART tokenizer automatically add the eos token at the end of the text
patil-suraj
on 2 Aug 2020
@patil-suraj Thanks to your prompt. These models' behaviour is quite different, the problem is solved by shifting decoder input to the right manually.
WangHexie
on 2 Aug 2020
@alexgaskell10, @HHousen, the query.reshape()solution is wrong. The code runs but it is not doing the right thing. It should be query.transpose(0, 1). I just pushed a fix. This bug will affect all your results if you are using a batch size > 1
ibeltagy
on 6 Aug 2020
@ibeltagy @HHousen Thanks for the update, it still is not working well for me with bsz > 1. I think you also need to change attn_output = attn_output.contiguous().view(tgt_len, bsz, embed_dim) to attn_output = attn_output.transpose(0,1) in longformer/longformer_encoder_decoder.py, line 75.
alexgaskell10
on 7 Aug 2020
@alexgaskell10, you are right. Just pushed a fix for that one as well.
ibeltagy
on 7 Aug 2020
@ibeltagy it still isn't working correctly for me (even at bsz=1). On some runs and at random points training the training becomes corrupted as per the image below. Taking a look into this now but not really sure where to start as it only happens sometimes and at random points during training so I haven't got much to work with. Any ideas?
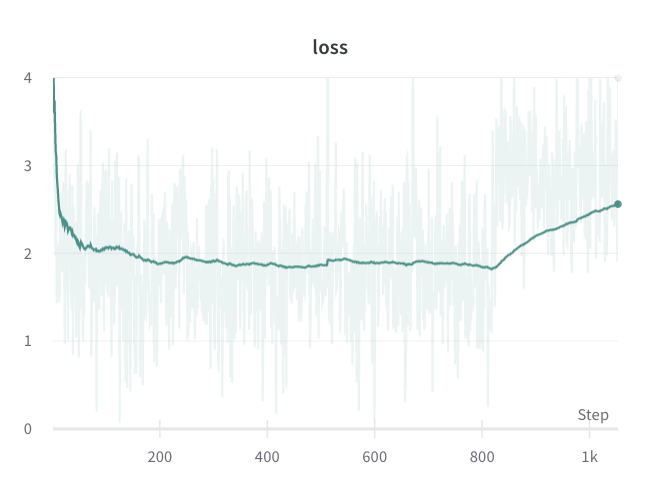
alexgaskell10
on 12 Aug 2020
what is the effective batch size? bsz x gradient accumulation x number of gpus? make sure it is not very small, try at least 8 if not 32.
how does the learning
curverate curve look like? can you draw it next to the loss curve? are you using warmup and decay? try lowering the learning rate?
ibeltagy
on 12 Aug 2020
Thanks for the suggestions- a couple of good thoughts. I have only been using small bsz so far (< 4) so I think that is somewhere to start alongside playing with the LR. Thanks!
- I am not using warmup and decay. I don't think warmup is the issue as it rarely begins soon into training. Will try with decay though
- What are you referring to as the learning curve in this instance? The validation loss?
alexgaskell10
on 12 Aug 2020
oh, sorry, I meant plotting learning rate curve vs. steps.
ibeltagy
on 12 Aug 2020
Gradient checkpointing in the decoder is not working so going to remove it for now. Will update the repo this weekend and will put some instructions in the readme.
Hello @patil-suraj
Do you have any advance in this work? I checked the repository but the README is still empty.
Can you help me please @alexgaskell10?
Thank you so much.
 JessicaLopezEspejel
on 18 Aug 2020
JessicaLopezEspejel
on 18 Aug 2020
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
Just adding that I get the same error for AlbertForMaskedLM with albert-large-v2, batch size of 8, using version 3.1.0 (pytorch), and training with Trainer
It doesn't appear immediately, but a little way into the warm-up phase of the training.
 morganmcg1
on 24 Sep 2020
morganmcg1
on 24 Sep 2020
I had the same problem with FunnelTransformer. But it seems resolved after I set WANDB_WATCH=false or disable --fp16. You can try if it works for you.
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.Just adding that I get the same error for
AlbertForMaskedLMwith albert-large-v2, batch size of 8, using version 3.1.0 (pytorch), and training with TrainerIt doesn't appear immediately, but a little way into the warm-up phase of the training.
 memray
on 30 Sep 2020
memray
on 30 Sep 2020
@patil-suraj what is the best way to save the fine tune model in order to reuse it again with T5ForConditionalGeneration.from_pretrained()?
 Amirosimani
on 12 Oct 2020
Amirosimani
on 12 Oct 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 12 Dec 2020
stale[bot]
on 12 Dec 2020
Related issues
 zhezhaoa
·
3Comments
zhezhaoa
·
3Comments
 lcswillems
·
3Comments
lcswillems
·
3Comments
 guanlongtianzi
·
3Comments
guanlongtianzi
·
3Comments
 ereday
·
3Comments
ereday
·
3Comments
 lemonhu
·
3Comments
lemonhu
·
3Comments
Most helpful comment
Hi @virattt , I've been able to replace bart encoder's self attention with sliding window attention. Also added gradient checkpoiting in the encoder.
Gradient checkpoiting in decoder is not working so going to remove it for now. Will update the repo this weekend and will put some instructions in the readme.