Transformers: RuntimeError: index out of range: Tried to access index 512 out of table with 511 rows.
❓ Questions & Help
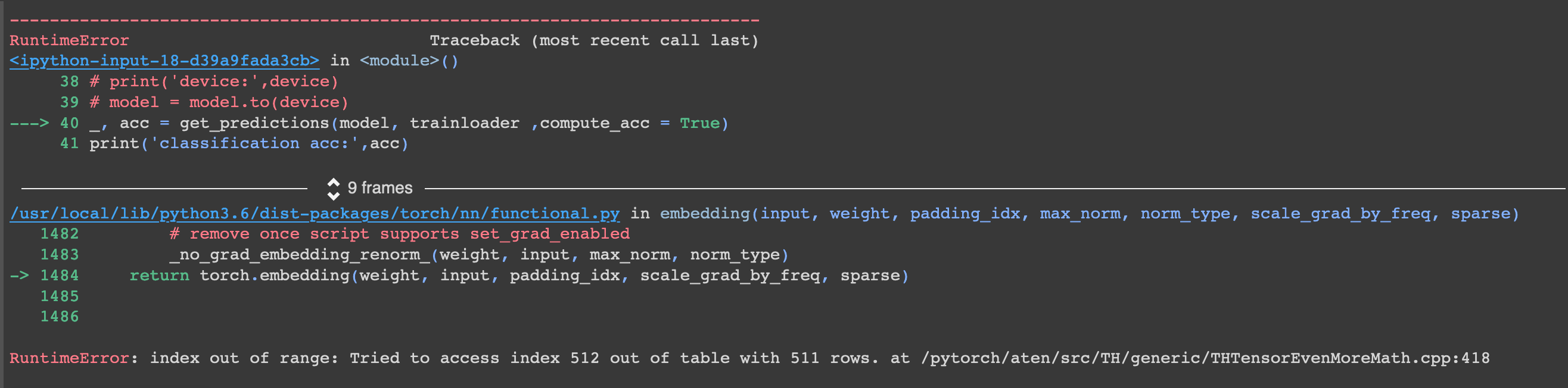
I am receiving the error RuntimeError: index out of range: Tried to access index 512 out of table with 511 rows.
What can I do to increase this source sentence length constraint?
 supremepoison
supremepoison
All 8 comments
Different models have different sequence lengths. Some models don't, like XLNet and TransformerXL.
 LysandreJik
on 9 Jan 2020
LysandreJik
on 9 Jan 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 9 Mar 2020
stale[bot]
on 9 Mar 2020
I have the same error.
I found out that it is because the BERT model only handles up to 512 characters, so if your texts are longer, I cannot make embeddings. There are different ways to handle this, and one is e.g. to make a sliding window of the embeddings, and then take the average embedding for words in overlapping windows.
 esbeneickhardt
on 9 Mar 2020
esbeneickhardt
on 9 Mar 2020
Quick reminder: Limit of 512 is not word limit, it is token length limit as BERT models do not use words as tokens. You always have more tokens than number of words.
You can divide the text into half and then pool afterwards even though this is not exactly the same as having the whole thing and then pooling.
 ogencoglu
on 3 Apr 2020
ogencoglu
on 3 Apr 2020
Related to this: Using tokenizer.encode_plus(doc) gives a sensible warning:
Token indices sequence length is longer than the specified maximum sequence length for this model (548 > 512). Running this sequence through the model will result in indexing errors
But tokenizer.batch_encode_plus doesn't seem to output this warning. Are other people noticing this?
 bpben
on 23 Apr 2020
bpben
on 23 Apr 2020
Hi All,
I am running a Roberta Model for predicting the sentence classification task. I am using Fastai implementation of it. I get a similar error as mentioned above. Please help me resolve this.

 shravankoninti
on 6 May 2020
shravankoninti
on 6 May 2020
Check if you texts are longer than 512 characters, and if so the error is
expected.
Solutions:
- Only use the first 512 characters of each text.
- Divide you texts into chunks of 512 characters and make embeddings on
each chunk
On Wed, 6 May 2020, 19:07 Shravan Koninti, notifications@github.com wrote:
Hi All,
I am running a Roberta Model for predicting the sentence classification
task. I am using Fastai implementation of it. I get a similar error as
mentioned above. Please help me resolve this.[image: fast_er_1]
https://user-images.githubusercontent.com/6191291/81206700-1d01d500-8fea-11ea-8964-86298ad231cd.JPG—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/huggingface/transformers/issues/2446#issuecomment-624772966,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ADCAJ7S77GPU3D7XZ57Z2X3RQGKNPANCNFSM4KEDJF3Q
.
esbeneickhardt
on 8 May 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
stale[bot]
on 8 Jul 2020
Related issues
 lcswillems
·
3Comments
lcswillems
·
3Comments
 delip
·
3Comments
delip
·
3Comments
 HanGuo97
·
3Comments
HanGuo97
·
3Comments
 alphanlp
·
3Comments
alphanlp
·
3Comments
 guanlongtianzi
·
3Comments
guanlongtianzi
·
3Comments
Most helpful comment
I have the same error.
I found out that it is because the BERT model only handles up to 512 characters, so if your texts are longer, I cannot make embeddings. There are different ways to handle this, and one is e.g. to make a sliding window of the embeddings, and then take the average embedding for words in overlapping windows.