Transformers: What is the "could not find answer" warning in squad.py
Hello,
I am trying to run run_squad.py for BERT (italian-cased) with an italian version of squad.
During the creation of features from dataset, I got some answer skipped like in the following:
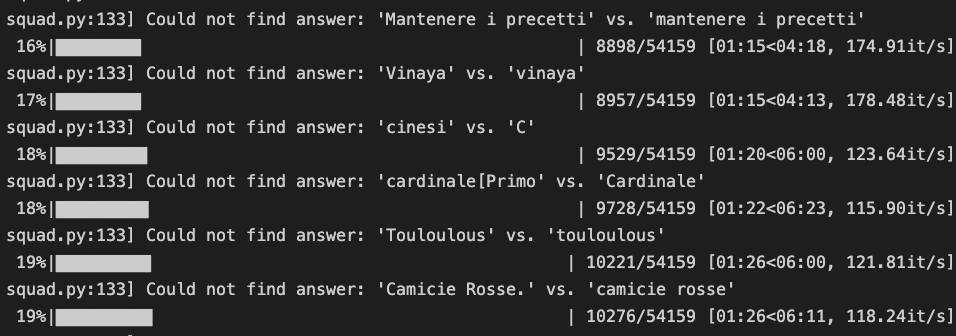
Can you tell why is this happening and if this influences the overall accuracy of the training?
 antocapp
antocapp
All 5 comments
This means that the script that converts the examples to features can't find the answers it should be finding. Rather than trying to predict those, it ignores them.
This means that these examples won't be used for training, reducing the total number of examples that will be used. If it is a small portion of the total number of examples, it shouldn't impact the resulting accuracy much. If it is a significant portion of the examples then it would be a good idea to look into it to see if there's a quick fix.
 LysandreJik
on 6 Jan 2020
LysandreJik
on 6 Jan 2020
Hi @LysandreJik, thanks for the clarification. I noticed that for some of my data it happens that the the "text" field in "answers" field may differ from the one present in the "context" just because of some upper/lower letters mismatch. Do you think this could be avoided by using an uncased model?
antocapp
on 7 Jan 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 7 Mar 2020
stale[bot]
on 7 Mar 2020
@antocapp I had your same logs with a cased model. Now I'm using an uncased model, putting the flag --do_lower_case in run_squad.py I expected not to have those warnings, instead they appeared anyway.
I took a look in the doc and I saw that in run_squad.py, examples are passed to the function squad_convert_examples_to_features in this line.
features, dataset = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=not evaluate,
return_dataset="pt",
threads=args.threads,
)
The tokenizer is created passing the argument --do_lower_case so it should tokenize putting the lower case to every token. Anyway the warning you see comes within squad_convert_example_to_features declaration.
def squad_convert_example_to_features(
example, max_seq_length, doc_stride, max_query_length, padding_strategy, is_training
):
features = []
if is_training and not example.is_impossible:
# Get start and end position
start_position = example.start_position
end_position = example.end_position
# If the answer cannot be found in the text, then skip this example.
actual_text = " ".join(example.doc_tokens[start_position : (end_position + 1)])
cleaned_answer_text = " ".join(whitespace_tokenize(example.answer_text))
if actual_text.find(cleaned_answer_text) == -1:
logger.warning("Could not find answer: '%s' vs. '%s'", actual_text, cleaned_answer_text)
return []
tok_to_orig_index = []
orig_to_tok_index = []
all_doc_tokens = []
for (i, token) in enumerate(example.doc_tokens):
orig_to_tok_index.append(len(all_doc_tokens))
sub_tokens = tokenizer.tokenize(token)
for sub_token in sub_tokens:
tok_to_orig_index.append(i)
all_doc_tokens.append(sub_token)
# code continues...
As you can see actual_text and cleaned_answer_text use example.doc_tokens and example.answer_text which already contain upper_case! cleaned_answer_text is searched within actual_text considering upper-case letters different from lower_case letters, so an example like _'Mantenere i precetti' vs 'mantenere i precetti'_ (like you told in the issue) would be discarded. Indeed the tokenizer hasn't tokenized yet in those lines so, even if the features could be created with lower_case, that check makes that example to be discardes, even if it could be considered!
So what I made, is putting a lower() on every field of example before passing it to that function, changin run_squad.py in this way:
# other code...
else:
processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
if evaluate:
examples = processor.get_dev_examples(args.data_dir, filename=args.predict_file)
else:
examples = processor.get_train_examples(args.data_dir, filename=args.train_file)
if args.do_lower_case:
logger.info("Putting lower case to examples...")
for example in examples:
example.doc_tokens = [token.lower() for token in example.doc_tokens]
example.question_text = example.question_text.lower()
example.context_text = example.context_text.lower()
if example.answer_text is not None: # for dev set
example.answer_text = example.answer_text.lower()
features, dataset = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=not evaluate,
return_dataset="pt",
threads=args.threads,
)
I don't know if this can improve the results, but it avoids some discarded examples for sure 😊
@LysandreJik, is this a bug 🐛 ? Or maybe was there another trivial method to fix this?
 paulthemagno
on 28 Aug 2020
paulthemagno
on 28 Aug 2020
Hi @paulthemagno, lowering every example was the same thing I did to solve the warning, although I lowered the dataset instead of editing the run_squad.py; but it is indeed the same thing.
I uploaded just toady a model on the HF model hub (https://huggingface.co/antoniocappiello/bert-base-italian-uncased-squad-it).
This was trained based on dbmdz/bert-base-italian-uncased; I tried also a training with Musixmatch Umberto but the F1 and EM were slightly lower (like 1 point percentage lower).
But maybe running several experiments with different hyperparameters could lead to better results.
antocapp
on 28 Aug 2020
Related issues
 ereday
·
3Comments
ereday
·
3Comments
 adigoryl
·
3Comments
adigoryl
·
3Comments
 lemonhu
·
3Comments
lemonhu
·
3Comments
 delip
·
3Comments
delip
·
3Comments
 yspaik
·
3Comments
yspaik
·
3Comments
Most helpful comment
@antocapp I had your same logs with a cased model. Now I'm using an uncased model, putting the flag
--do_lower_casein run_squad.py I expected not to have those warnings, instead they appeared anyway.I took a look in the doc and I saw that in run_squad.py, examples are passed to the function
squad_convert_examples_to_featuresin this line.The tokenizer is created passing the argument
--do_lower_caseso it should tokenize putting the lower case to every token. Anyway the warning you see comes within squad_convert_example_to_features declaration.As you can see
actual_textandcleaned_answer_textuseexample.doc_tokensandexample.answer_textwhich already contain upper_case!cleaned_answer_textis searched withinactual_textconsidering upper-case letters different from lower_case letters, so an example like _'Mantenere i precetti' vs 'mantenere i precetti'_ (like you told in the issue) would be discarded. Indeed thetokenizerhasn't tokenized yet in those lines so, even if the features could be created with lower_case, that check makes that example to be discardes, even if it could be considered!So what I made, is putting a
lower()on every field of example before passing it to that function, changin run_squad.py in this way:I don't know if this can improve the results, but it avoids some discarded examples for sure 😊
@LysandreJik, is this a bug 🐛 ? Or maybe was there another trivial method to fix this?