Transformers: gpt-2 generation examples
❓ Questions & Help
Hi! Thanks for everything, I want to try generation with the gpt-2 model, following:
python ./examples/run_generation.py \
--model_type=gpt2 \
--length=20 \
--model_name_or_path=gpt2 \
But it does not seem to work very well, for example (Prompt -> Generation):
i go to -> the Kailua Islands? Eh? Ahh. Although they did say the
i like reading -> -_-/- 40:25:13 7d 9h 25m We battle trainer. Before we
i like running -> from someone which can easily overwhelm your battery in those moments and through the rest of your day
I mean, the generation don't really look good to me, is that anything I should mind during trying this?
Thanks!
Additional info:
12/02/2019 15:41:46 - INFO - __main__ - Namespace(device=device(type='cuda'), length=20, model_name_or_path='gpt2', model_type='gpt2', n_gpu=1, no_cuda=False, num_samples=1, padding_text='', prompt='', repetition_penalty=1.0, seed=42, stop_token=None, temperature=1.0, top_k=0, top_p=0.9, xlm_lang='')
 cloudygoose
cloudygoose
All 6 comments
You can tune the value for temperature and seed. Temperature is a hyper-parameter used to control the randomness of predictions by scaling the logits before applying softmax.
- when temperature is a small value (e.g. 0,2), the GPT-2 model is more confident but also more conservative
- when temperature is a large value (e.g. 1), the GPT-2 model produces more diversity and also more mistakes
If I were you, I'll change the temperature value down to 0,2 or 0,3 and see what happens (i.e. the result is what you want).
N.B: if you want (and you can), it is more preferably to use CPUs over GPUs for inference.
Questions & Help
Hi! Thanks for everything, I want to try generation with the gpt-2 model, following:
python ./examples/run_generation.py \ --model_type=gpt2 \ --length=20 \ --model_name_or_path=gpt2 \But it does not seem to work very well, for example (Prompt -> Generation):
i go to -> the Kailua Islands? Eh? Ahh. Although they did say the
i like reading -> -_-/- 40:25:13 7d 9h 25m We battle trainer. Before we
i like running -> from someone which can easily overwhelm your battery in those moments and through the rest of your dayI mean, the generation don't really look good to me, is that anything I should mind during trying this?
Thanks!Additional info:
12/02/2019 15:41:46 - INFO - __main__ - Namespace(device=device(type='cuda'), length=20, model_name_or_path='gpt2', model_type='gpt2', n_gpu=1, no_cuda=False, num_samples=1, padding_text='', prompt='', repetition_penalty=1.0, seed=42, stop_token=None, temperature=1.0, top_k=0, top_p=0.9, xlm_lang='')
 TheEdoardo93
on 3 Dec 2019
TheEdoardo93
on 3 Dec 2019
@TheEdoardo93
Thanks for the reply, I tried temperature 0.2 or topk 20, the generation does makes more sense to me.
But one thing that's still mysterious to me is that it loves to generate a lot of line breaks, do you have any intuition why that's happening?
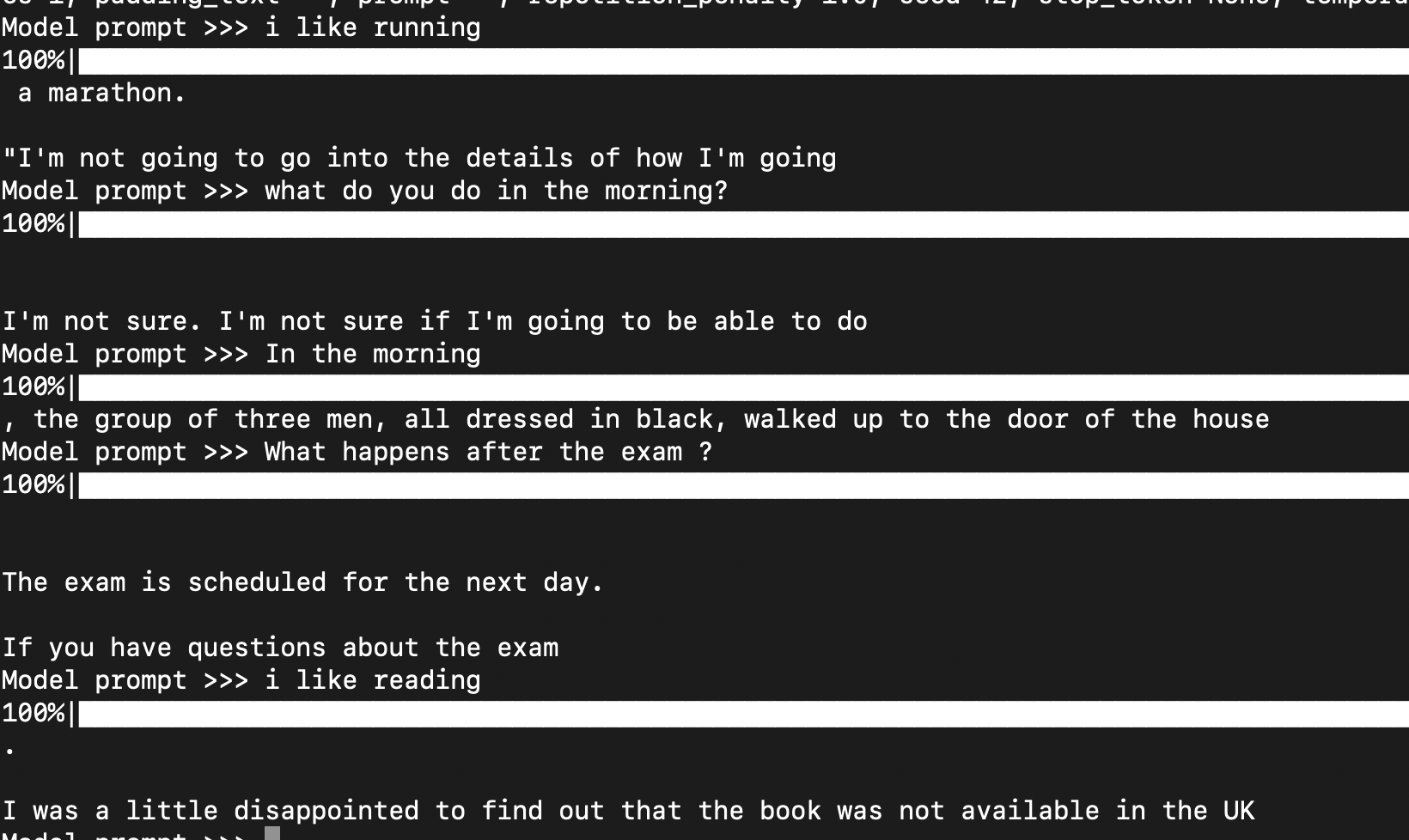
Also, could you also explain why it is more preferably to use CPUs over GPUs for inference?
Thanks!
cloudygoose
on 3 Dec 2019
Typically, if you have small-medium models (in terms of hyper-parameters), it's common to use CPUs for inference; GPUs are well suited for training large models. In general, it's up to you the choice to use CPU or GPU in inference mode. It depends on different factors: for example if you have a requirements of larger batches in the fastest way, you have to use GPU, but if you don't have such requirements of speed and batches, you can use CPU.
Source: my opinion on this topic :D
@TheEdoardo93
Thanks for the reply, I tried temperature 0.2 or topk 20, the generation does makes more sense to me.
But one thing that's still mysterious to me is that it loves to generate a lot of line breaks, do you have any intuition why that's happening?
Also, could you also explain why it is more preferably to use CPUs over GPUs for inference?
Thanks!
TheEdoardo93
on 3 Dec 2019
I'm still wondering about the line breaks and whether there's any thing I can do about that. Thanks~
cloudygoose
on 3 Dec 2019
I believe the line breaks are due to your context. You're simulating dialog, which is often represented as a sentence followed by line breaks, followed by another entity's response.
If you give the model inputs that are similar to traditionally long texts (e.g. Wikipedia articles), you're bound to have generations not split by line returns.
 LysandreJik
on 4 Dec 2019
LysandreJik
on 4 Dec 2019
I'm still wondering about the line breaks and whether there's any thing I can do about that. Thanks~
You can actually use bad_words_id parameter with a line break, which will prevent generate function from giving you results, which contain "\n". (though you'd probably have to add every id from your vocab, which has line breaks in it, since I do think there tends to be more than one "breaking" sequence out there...)
 anonymous2ch
on 28 Aug 2020
anonymous2ch
on 28 Aug 2020
Related issues
 rsanjaykamath
·
3Comments
rsanjaykamath
·
3Comments
 yspaik
·
3Comments
yspaik
·
3Comments
 0x01h
·
3Comments
0x01h
·
3Comments
 HansBambel
·
3Comments
HansBambel
·
3Comments
 alphanlp
·
3Comments
alphanlp
·
3Comments
Most helpful comment
I believe the line breaks are due to your context. You're simulating dialog, which is often represented as a sentence followed by line breaks, followed by another entity's response.
If you give the model inputs that are similar to traditionally long texts (e.g. Wikipedia articles), you're bound to have generations not split by line returns.