Transformers: RuntimeError: CUDA error: device-side assert triggered
❓ Questions & Help
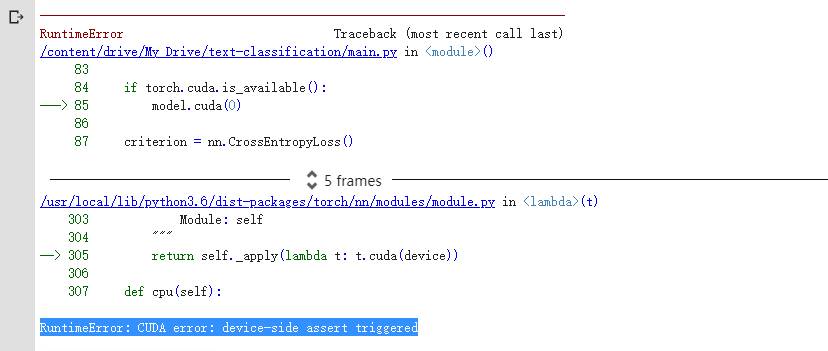 . "RuntimeError: CUDA error: device-side assert triggered" occurs. My model is as follows:
. "RuntimeError: CUDA error: device-side assert triggered" occurs. My model is as follows:
class TextClassify(nn.Module):
def __init__(self, bert, kernel_size, word_dim, out_dim, num_class, dropout=0.5):
super(TextClassify, self).__init__()
self.bert = bert
self.cnn = nn.Sequential(nn.Conv1d(word_dim, out_dim, kernel_size=kernel_size, padding=1), nn.ReLU(inplace=True))
self.drop = nn.Dropout(dropout, inplace=True)
self.fc = nn.Linear(out_dim, num_class)
def forward(self, word_input):
batch_size = word_input.size(0)
represent = self.xlnet(word_input)[0]
represent = self.drop(represent)
represent = represent.transpose(1, 2)
contexts = self.cnn(represent)
feature = F.max_pool1d(contexts, contexts.size(2)).contiguous().view(batch_size, -1)
feature = self.drop(feature)
feature = self.fc(feature)
return feature
How can I solve it?
 cswangjiawei
cswangjiawei
All 9 comments
Are you in a multi-GPU setup ?
 LysandreJik
on 12 Nov 2019
LysandreJik
on 12 Nov 2019
I did not use multi-GPU setup, I used to model.cuda(), it ocuurs "RuntimeError: CUDA error: device-side assert triggered", so I changed to model.cuda(0), but the error still occurs.
cswangjiawei
on 13 Nov 2019
Do you mind showing how you initialize BERT and the code surrounding the error?
LysandreJik
on 13 Nov 2019
My project structure is as follows:

And dataset.py is as follows:
# -*- coding: utf-8 -*-
"""
@time: 2019/8/6 19:47
@author: wangjiawei
"""
from torch.utils.data import Dataset
import torch
import csv
class MyDataset(Dataset):
def __init__(self, data_path, tokenizer):
super(MyDataset, self).__init__()
self.tokenizer = tokenizer
texts, labels = [], []
with open(data_path, 'r', encoding='utf-8') as csv_file:
reader = csv.reader(csv_file, quotechar='"')
for idx, line in enumerate(reader):
text = ""
for tx in line[1:]:
text += tx
text += " "
text = self.tokenizer.tokenize(text)
if len(text) > 512:
text = text[:512]
text = self.tokenizer.encode(text, add_special_tokens=True)
text_id = torch.tensor(text)
texts.append(text_id)
label = int(line[0]) - 1
labels.append(label)
self.texts = texts
self.labels = labels
self.num_class = len(set(self.labels))
def __len__(self):
return len(self.labels)
def __getitem__(self, item):
label = self.labels[item]
text = self.texts[item]
return {'text': text, 'label': torch.tensor(label).long()}
main.py is as follows:
# -*- coding: utf-8 -*-
"""
@time: 2019/7/17 20:37
@author: wangjiawei
"""
import os
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
from utils import get_default_folder, my_collate_fn
from dataset import MyDataset
from model import TextClassify
from torch.utils.tensorboard import SummaryWriter
import argparse
import shutil
import numpy as np
import random
import time
from train import train_model, evaluate
from transformers import BertModel, BertTokenizer
seed_num = 123
random.seed(seed_num)
torch.manual_seed(seed_num)
np.random.seed(seed_num)
if __name__ == "__main__":
parser = argparse.ArgumentParser("self attention for Text Categorization")
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--num_epoches", type=int, default=20)
parser.add_argument("--lr", type=float, default=0.001)
parser.add_argument("--kernel_size", type=int, default=3)
parser.add_argument("--word_dim", type=int, default=768)
parser.add_argument("--out_dim", type=int, default=300)
parser.add_argument("--dropout", default=0.5)
parser.add_argument("--es_patience", type=int, default=3)
parser.add_argument("--dataset", type=str,
choices=["agnews", "dbpedia", "yelp_review", "yelp_review_polarity", "amazon_review",
"amazon_polarity", "sogou_news", "yahoo_answers"], default="yelp_review")
parser.add_argument("--log_path", type=str, default="tensorboard/classify")
args = parser.parse_args()
input, output = get_default_folder(args.dataset)
train_path = input + os.sep + "train.csv"
if not os.path.exists(output):
os.makedirs(output)
# with open(input + os.sep + args.vocab_file, 'rb') as f1:
# vocab = pickle.load(f1)
# emb_begin = time.time()
# pretrain_word_embedding = build_pretrain_embedding(args.embedding_path, vocab, args.word_dim)
# emb_end = time.time()
# emb_min = (emb_end - emb_begin) % 3600 // 60
# print('build pretrain embed cost {}m'.format(emb_min))
model_class, tokenizer_class, pretrained_weights = BertModel, BertTokenizer, 'bert-base-uncased'
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert = model_class.from_pretrained(pretrained_weights)
train_dev_dataset = MyDataset(input + os.sep + "train.csv", tokenizer)
len_train_dev_dataset = len(train_dev_dataset)
dev_size = int(len_train_dev_dataset * 0.1)
train_size = len_train_dev_dataset - dev_size
train_dataset, dev_dataset = random_split(train_dev_dataset, [train_size, dev_size])
test_dataset = MyDataset(input + os.sep + "test.csv", tokenizer)
train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, collate_fn=my_collate_fn)
dev_dataloader = DataLoader(dev_dataset, batch_size=args.batch_size, shuffle=False, collate_fn=my_collate_fn)
test_dataloader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, collate_fn=my_collate_fn)
model = TextClassify(bert, args.kernel_size, args.word_dim, args.out_dim, test_dataset.num_class, args.dropout)
log_path = "{}_{}".format(args.log_path, args.dataset)
if os.path.isdir(log_path):
shutil.rmtree(log_path)
os.makedirs(log_path)
writer = SummaryWriter(log_path)
if torch.cuda.is_available():
model.cuda(0)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
best_acc = -1
early_stop = 0
model.train()
batch_num = -1
train_begin = time.time()
for epoch in range(args.num_epoches):
epoch_begin = time.time()
print('train {}/{} epoch'.format(epoch + 1, args.num_epoches))
batch_num = train_model(model, optimizer, criterion, batch_num, train_dataloader, writer)
dev_acc = evaluate(model, dev_dataloader)
writer.add_scalar('dev/Accuracy', dev_acc, epoch)
print('dev_acc:', dev_acc)
if dev_acc > best_acc:
early_stop = 0
best_acc = dev_acc
print('new best_acc on dev set:', best_acc)
torch.save(model.state_dict(), "{}{}".format(output, 'best.pt'))
else:
early_stop += 1
epoch_end = time.time()
cost_time = epoch_end - epoch_begin
print('train {}th epoch cost {}m {}s'.format(epoch + 1, int(cost_time / 60), int(cost_time % 60)))
print()
# Early stopping
if early_stop > args.es_patience:
print(
"Stop training at epoch {}. The best dev_acc achieved is {}".format(epoch - args.es_patience, best_acc))
break
train_end = time.time()
train_cost = train_end - train_begin
hour = int(train_cost / 3600)
min = int((train_cost % 3600) / 60)
second = int(train_cost % 3600 % 60)
print()
print()
print('train end', '-' * 50)
print('train total cost {}h {}m {}s'.format(hour, min, second))
print('-' * 50)
model_name = "{}{}".format(output, 'best.pt')
model.load_state_dict(torch.load(model_name))
test_acc = evaluate(model, test_dataloader)
print('test acc on test set:', test_acc)
model.py is as follows:
# -*- coding: utf-8 -*-
"""
@time: 2019/8/6 19:04
@author: wangjiawei
"""
import torch.nn as nn
import torch
import torch.nn.functional as F
class TextClassify(nn.Module):
def __init__(self, bert, kernel_size, word_dim, out_dim, num_class, dropout=0.5):
super(TextClassify, self).__init__()
self.bert = bert
self.cnn = nn.Sequential(nn.Conv1d(word_dim, out_dim, kernel_size=kernel_size, padding=1), nn.ReLU(inplace=True))
self.drop = nn.Dropout(dropout, inplace=True)
self.fc = nn.Linear(out_dim, num_class)
def forward(self, word_input):
batch_size = word_input.size(0)
represent = self.bert(word_input)[0]
represent = self.drop(represent)
represent = represent.transpose(1, 2)
contexts = self.cnn(represent)
feature = F.max_pool1d(contexts, contexts.size(2)).contiguous().view(batch_size, -1)
feature = self.drop(feature)
feature = self.fc(feature)
return feature
train.py is as follows:
# -*- coding: utf-8 -*-
"""
@time: 2019/8/6 20:14
@author: wangjiawei
"""
import torch
def train_model(model, optimizer, criterion, batch_num, dataloader, writer):
model.train()
for batch in dataloader:
model.zero_grad()
batch_num += 1
text = batch['text']
label = batch['label']
if torch.cuda.is_available():
text = text.cuda(0)
label = label.cuda(0)
feature = model(text)
loss = criterion(feature, label)
writer.add_scalar('Train/Loss', loss, batch_num)
loss.backward()
optimizer.step()
return batch_num
def evaluate(model, dataloader):
model.eval()
correct_num = 0
total_num = 0
for batch in dataloader:
text = batch['text']
label = batch['label']
if torch.cuda.is_available():
text = text.cuda(0)
label = label.cuda(0)
with torch.no_grad():
predictions = model(text)
_, preds = torch.max(predictions, 1)
correct_num += torch.sum((preds == label)).item()
total_num += len(label)
acc = (correct_num / total_num) * 100
return acc
utils.py is as follows:
# -*- coding: utf-8 -*-
"""
@time: 2019/8/6 19:54
@author: wangjiawei
"""
import csv
import nltk
import numpy as np
from torch.nn.utils.rnn import pad_sequence
import torch
def load_pretrain_emb(embedding_path, embedd_dim):
embedd_dict = dict()
with open(embedding_path, 'r', encoding="utf8") as file:
for line in file:
line = line.strip()
if len(line) == 0:
continue
tokens = line.split()
if not embedd_dim + 1 == len(tokens):
continue
embedd = np.empty([1, embedd_dim])
embedd[:] = tokens[1:]
first_col = tokens[0]
embedd_dict[first_col] = embedd
return embedd_dict
def build_pretrain_embedding(embedding_path, vocab, embedd_dim=300):
embedd_dict = dict()
if embedding_path is not None:
embedd_dict = load_pretrain_emb(embedding_path, embedd_dim)
alphabet_size = vocab.size()
scale = 0.1
pretrain_emb = np.empty([vocab.size(), embedd_dim])
perfect_match = 0
case_match = 0
not_match = 0
for word, index in vocab.items():
if word in embedd_dict:
pretrain_emb[index, :] = embedd_dict[word]
perfect_match += 1
elif word.lower() in embedd_dict:
pretrain_emb[index, :] = embedd_dict[word.lower()]
case_match += 1
else:
pretrain_emb[index, :] = np.random.uniform(-scale, scale, [1, embedd_dim])
not_match += 1
pretrain_emb[0, :] = np.zeros((1, embedd_dim))
pretrained_size = len(embedd_dict)
print('pretrained_size:', pretrained_size)
print("Embedding:\n pretrain word:%s, prefect match:%s, case_match:%s, oov:%s, oov%%:%s" % (
pretrained_size, perfect_match, case_match, not_match, (not_match + 0.) / alphabet_size))
return pretrain_emb
def get_default_folder(dataset):
if dataset == "agnews":
input = "data/ag_news_csv"
output = "output/ag_news/"
elif dataset == "dbpedia":
input = "data/dbpedia_csv"
output = "output/dbpedia/"
elif dataset == "yelp_review":
input = "data/yelp_review_full_csv"
output = "output/yelp_review_full/"
elif dataset == "yelp_review_polarity":
input = "data/yelp_review_polarity_csv"
output = "output/yelp_review_polarity/"
elif dataset == "amazon_review":
input = "data/amazon_review_full_csv"
output = "output/amazon_review_full/"
elif dataset == "amazon_polarity":
input = "data/amazon_review_polarity_csv"
output = "output/amazon_review_polarity/"
elif dataset == "sogou_news":
input = "data/sogou_news_csv"
output = "output/sogou_news/"
elif dataset == "yahoo_answers":
input = "data/yahoo_answers_csv"
output = "output/yahoo_answers/"
return input, output
def my_collate(batch_tensor, key):
if key == 'text':
batch_tensor = pad_sequence(batch_tensor, batch_first=True, padding_value=0)
else:
batch_tensor = torch.stack(batch_tensor)
return batch_tensor
def my_collate_fn(batch):
return {key: my_collate([d[key] for d in batch], key) for key in batch[0]}
class Vocabulary(object):
def __init__(self, filename):
self._id_to_word = []
self._word_to_id = {}
self._pad = -1
self._unk = -1
self.index = 0
self._id_to_word.append('<PAD>')
self._word_to_id['<PAD>'] = self.index
self._pad = self.index
self.index += 1
self._id_to_word.append('<UNK>')
self._word_to_id['<UNK>'] = self.index
self._unk = self.index
self.index += 1
word_num = dict()
with open(filename, 'r', encoding='utf-8') as f1:
reader = csv.reader(f1, quotechar='"')
for line in reader:
text = ""
for tx in line[1:]:
text += tx
text += " "
text = nltk.word_tokenize(text)
for word in text:
if word not in word_num:
word_num[word] = 0
word_num[word] += 1
for word, num in word_num.items():
if num >= 3:
self._id_to_word.append(word)
self._word_to_id[word] = self.index
self.index += 1
def unk(self):
return self._unk
def pad(self):
return self._pad
def size(self):
return len(self._id_to_word)
def word_to_id(self, word):
if word in self._word_to_id:
return self._word_to_id[word]
elif word.lower() in self._word_to_id:
return self._word_to_id[word.lower()]
return self.unk()
def id_to_word(self, cur_id):
return self._id_to_word[cur_id]
def items(self):
return self._word_to_id.items()
when I use Google Cloud, it works. Before I used Google Colab. It is strange.
cswangjiawei
on 17 Nov 2019
It's probably because your token embeddings size (vocab size) doesn't match with pre-trained model. Do model.resize_token_embeddings(len(tokenizer)) before training. Please check #1848 and #1849
 iedmrc
on 17 Nov 2019
iedmrc
on 17 Nov 2019
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 16 Jan 2020
stale[bot]
on 16 Jan 2020
I also faced the same issue while encoding 20_newspaper dataset, After further investigation, I found there are some sentences which are not in the English language, for example :
'subject romanbmp pa of from pwisemansalmonusdedu cliff replyto pwisemansalmonusdedu cliff distribution usa organization university of south dakota lines maxaxaxaxaxaxaxaxaxaxaxaxaxaxax maxaxaxax39f8z51 wwizbhjbhjbhjbhjgiz mgizgizbhjgizm 1tei0lv9f9f9fra 5z46q0475vo4 mu34u34u m34w 084oo aug 0y5180 mc p8v5555555555965hwgv 7uqgy gp452gvbdigiz maxaxaxaxaxaxaxaxaxaxaxaxaxaxax maxaxax34t2php2app12a34u34tm11 6um6 mum8 zbjf0kvlvc9vde5e9e5g9vg9v38vc o3o n5 mardi 24y2 g92li6e0q8axaxaxaxaxaxaxax maxaxaxaxaxaxaxas9ne1whjn 1tei4pmf9l3u3 mr hjpm75u4u34u34u nfyn 46uo m5ug 0y4518hr8y3m15556tdy65c8u 47y m7 hsxgjeuaxaxaxaxaxaxaxaxaxaxaxax maxaxaxaxaxaxaxax34t2pchp2a2a2a234u m34u3 zexf3w21fp4 wm3t f9d uzi0mf8axaxaxaxaxaxrxkrldajj mkjznbbwp0nvmkvmkvnrkmkvmhi axaxaxaxax maxaxaxaxaxaxaxks8vc9vfiue949h g9v38v6un5 mg83q3x w5 3t pi0wsr4c362l zkn2axaxaxaxaxaxaxaxaxaxax maxaxaxaxaxaxaxaxaxaxaxaxaxaxax maxax39f9fpli6e1t1'
This was causing the model to produce this error If you are facing this issue follow these steps:
- Catch Exception and store the sentences in the new list to see if the sentence is having weird characters
- Reduce the batch size, If your batch size is too high (if you are using batch encoding)
- Check if your sentence length is too long for the model to encode, trim the sentence length ( try 200 first then 128 )
 monk1337
on 29 Jul 2020
monk1337
on 29 Jul 2020
I am continuously getting the runtime error: CUDA error: device-side assert triggered, I am new to transformer library.
I am creating the longformer classifier in the below format:
model = LongformerForSequenceClassification.from_pretrained('allenai/longformer-base-4096', gradient_checkpointing = True, num_labels = 5)
and tokenizer as :
tokenizer = LongformerTokenizer.from_pretrained('allenai/longformer-base-4096')
encoded_data_train = tokenizer.batch_encode_plus(
df[df.data_type=='train'].content.values,
add_special_tokens = True,
return_attention_mask=True,
padding = True,
max_length = 3800,
return_tensors='pt'
)
Can anyone please help? I am using latest version of transformer library and using google colab GPU for building my classifier.
 pul95
on 17 Nov 2020
pul95
on 17 Nov 2020
Related issues
 delip
·
3Comments
delip
·
3Comments
 chuanmingliu
·
3Comments
chuanmingliu
·
3Comments
 guanlongtianzi
·
3Comments
guanlongtianzi
·
3Comments
 ereday
·
3Comments
ereday
·
3Comments
 quocnle
·
3Comments
quocnle
·
3Comments
Most helpful comment
It's probably because your token embeddings size (vocab size) doesn't match with pre-trained model. Do
model.resize_token_embeddings(len(tokenizer))before training. Please check #1848 and #1849