Transformers: Out of Memory (OOM) when repeatedly running large models
❓ Any advice for freeing up GPU memory after training a large model (e.g., roberta-large)?
System Info
Platform Linux-4.4.0-1096-aws-x86_64-with-debian-stretch-sid
Python 3.6.6 |Anaconda, Inc.| (default, Jun 28 2018, 17:14:51)
[GCC 7.2.0]
PyTorch 1.3.0
AWS EC2 p3.2xlarge (single GPU)
My current objective is to run roberta-large multiple training jobs sequentially from the same python script (i.e., for a simple HPO search). Even after deleting all of the objects and clearing the cuda cache after the first training job ends I am still stuck with 41% GPU memory usage (as compared to 15% before starting the training process).
I am attaching a reproducible example to get the error:
Here is the relevant code
show_gpu('Initial GPU memory usage:')
for i in range(2):
model, optimizer, scheduler = get_training_obj(params)
show_gpu(f'{i}: GPU memory usage after loading training objects:')
for epoch in range(1):
epoch_start = time.time()
model.train()
for batch in dp.train_dataloader:
xb,mb,_,yb = tuple(t.to(params['device']) for t in batch)
outputs = model(input_ids = xb, attention_mask = mb, labels = yb)
loss = outputs[0]
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
show_gpu(f'{i}: GPU memory usage after training model:')
del model, optimizer, scheduler, loss, outputs
torch.cuda.empty_cache()
torch.cuda.synchronize()
show_gpu(f'{i}: GPU memory usage after clearing cache:')
Here is the output and full traceback
Initial GPU memory usage: 0.0% (0 out of 16130)
0: GPU memory usage after loading training objects: 14.7% (2377 out of 16130)
0: GPU memory usage after training model: 70.8% (11415 out of 16130)
0: GPU memory usage after clearing cache: 41.8% (6741 out of 16130)
1: GPU memory usage after loading training objects: 50.2% (8093 out of 16130)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-7-20a3bdec1bf4> in <module>()
8 for batch in dp.train_dataloader:
9 xb,mb,_,yb = tuple(t.to(params['device']) for t in batch)
---> 10 outputs = model(input_ids = xb, attention_mask = mb, labels = yb)
11 loss = outputs[0]
12 loss.backward()
~/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.6/site-packages/transformers/modeling_roberta.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, labels)
326 token_type_ids=token_type_ids,
327 position_ids=position_ids,
--> 328 head_mask=head_mask)
329 sequence_output = outputs[0]
330 logits = self.classifier(sequence_output)
~/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.6/site-packages/transformers/modeling_roberta.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask)
179 token_type_ids=token_type_ids,
180 position_ids=position_ids,
--> 181 head_mask=head_mask)
182
183
~/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask)
625 encoder_outputs = self.encoder(embedding_output,
626 extended_attention_mask,
--> 627 head_mask=head_mask)
628 sequence_output = encoder_outputs[0]
629 pooled_output = self.pooler(sequence_output)
~/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py in forward(self, hidden_states, attention_mask, head_mask)
346 all_hidden_states = all_hidden_states + (hidden_states,)
347
--> 348 layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])
349 hidden_states = layer_outputs[0]
350
~/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py in forward(self, hidden_states, attention_mask, head_mask)
326 attention_outputs = self.attention(hidden_states, attention_mask, head_mask)
327 attention_output = attention_outputs[0]
--> 328 intermediate_output = self.intermediate(attention_output)
329 layer_output = self.output(intermediate_output, attention_output)
330 outputs = (layer_output,) + attention_outputs[1:] # add attentions if we output them
~/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
539 result = self._slow_forward(*input, **kwargs)
540 else:
--> 541 result = self.forward(*input, **kwargs)
542 for hook in self._forward_hooks.values():
543 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py in forward(self, hidden_states)
298 def forward(self, hidden_states):
299 hidden_states = self.dense(hidden_states)
--> 300 hidden_states = self.intermediate_act_fn(hidden_states)
301 return hidden_states
302
~/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py in gelu(x)
126 Also see https://arxiv.org/abs/1606.08415
127 """
--> 128 return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
129
130 def gelu_new(x):
RuntimeError: CUDA out of memory. Tried to allocate 26.00 MiB (GPU 0; 15.75 GiB total capacity; 14.24 GiB already allocated; 8.88 MiB free; 476.01 MiB cached)
Appendix / complete code to reproduce
import platform; print("Platform", platform.platform())
import sys; print("Python", sys.version)
import torch; print("PyTorch", torch.__version__)
from __future__ import absolute_import, division, print_function
import glob
import logging
import os
import time
import json
import random
import numpy as np
import pandas as pd
from random import sample, seed
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler,TensorDataset
from torch.utils.data.distributed import DistributedSampler
from transformers import RobertaConfig, RobertaForSequenceClassification, RobertaTokenizer
from transformers import DistilBertConfig, DistilBertForSequenceClassification, DistilBertTokenizer
from transformers import BertConfig, BertForSequenceClassification, BertTokenizer
from transformers import AdamW, WarmupLinearSchedule
from transformers import glue_compute_metrics as compute_metrics
from transformers import glue_output_modes as output_modes
from transformers import glue_processors as processors
from transformers import glue_convert_examples_to_features as convert_examples_to_features
import subprocess
params = {
'num_epochs': 2,
'warmup_ratio': 0.06,
'weight_decay': 0.1,
'adam_epsilon': 1e-6,
'model_name': 'roberta-large',
'max_grad_norm': 1.0,
'lr': 2e-5,
'bs': 32,
'device': 'cuda',
'task': 'cola',
'data_dir': '/home/ubuntu/glue_data/CoLA',
'max_seq_length': 50,
'metric_name': 'mcc',
'patience': 3,
'seed': 935,
'n': -1,
}
class DataProcessor():
'''Preprocess the data, store data loaders and tokenizer'''
_TOKEN_TYPES = {
'roberta': RobertaTokenizer,
'distilbert': DistilBertTokenizer,
'bert': BertTokenizer,
}
def __init__(self, params):
model_type = params['model_name'].split('-')[0]
assert model_type in self._TOKEN_TYPES.keys()
self.tok = self._TOKEN_TYPES[model_type]
self.params = params
self.processor = processors[self.params['task']]()
self.output_mode = output_modes[self.params['task']]
self.label_list = self.processor.get_labels()
@staticmethod
def _convert_to_tensors(features):
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
return TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
def _load_examples(self, tokenizer, evaluate):
if evaluate:
examples = self.processor.get_dev_examples(self.params['data_dir'])
else:
examples = self.processor.get_train_examples(self.params['data_dir'])
if self.params['n'] >= 0:
examples = sample(examples, self.params['n'])
features = convert_examples_to_features(examples,
tokenizer,
label_list=self.label_list,
max_length=self.params['max_seq_length'],
output_mode=self.output_mode,
pad_on_left=False,
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=0)
return self._convert_to_tensors(features)
def _define_tokenizer(self):
return self.tok.from_pretrained(self.params['model_name'], do_lower_case=True)
def load_data(self):
tokenizer = self._define_tokenizer()
self.train_data = self._load_examples(tokenizer, False)
self.valid_data = self._load_examples(tokenizer, True)
self.train_n = len(self.train_data)
self.valid_n = len(self.valid_data)
self.params['total_steps'] = self.params['num_epochs'] * self.train_n
return self.params
def create_loaders(self):
self.train_dataloader = DataLoader(self.train_data, shuffle=True, batch_size=self.params['bs'])
self.valid_dataloader = DataLoader(self.valid_data, shuffle=False, batch_size=2*self.params['bs'])
dp = DataProcessor(params)
params = dp.load_data()
dp.create_loaders()
def show_gpu(msg):
"""
ref: https://discuss.pytorch.org/t/access-gpu-memory-usage-in-pytorch/3192/4
"""
def query(field):
return(subprocess.check_output(
['nvidia-smi', f'--query-gpu={field}',
'--format=csv,nounits,noheader'],
encoding='utf-8'))
def to_int(result):
return int(result.strip().split('\n')[0])
used = to_int(query('memory.used'))
total = to_int(query('memory.total'))
pct = used/total
print('\n' + msg, f'{100*pct:2.1f}% ({used} out of {total})')
# ### Running the Training Loop
def get_training_obj(params):
config = RobertaConfig.from_pretrained(params['model_name'], num_labels=2)
model = RobertaForSequenceClassification.from_pretrained(params['model_name'], config=config).to(params['device'])
no_decay = ['bias', 'LayerNorm.weight']
gpd_params = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
'weight_decay': params['weight_decay']},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
'weight_decay': 0.0}
]
optimizer = AdamW(gpd_params, lr=params['lr'], eps=params['adam_epsilon'])
warmup_steps = int(params['warmup_ratio'] * params['total_steps'])
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=warmup_steps, t_total=params['total_steps'])
return model, optimizer, scheduler
show_gpu('Initial GPU memory usage:')
for i in range(2):
model, optimizer, scheduler = get_training_obj(params)
show_gpu(f'{i}: GPU memory usage after loading training objects:')
for epoch in range(1):
epoch_start = time.time()
model.train()
for batch in dp.train_dataloader:
xb,mb,_,yb = tuple(t.to(params['device']) for t in batch)
outputs = model(input_ids = xb, attention_mask = mb, labels = yb)
loss = outputs[0]
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
show_gpu(f'{i}: GPU memory usage after training model:')
del model, optimizer, scheduler, loss, outputs
torch.cuda.empty_cache()
torch.cuda.synchronize()
show_gpu(f'{i}: GPU memory usage after clearing cache:')
 josiahdavis
josiahdavis
All 29 comments
This behavior is expected. pytorch.cuda.empty_cache() will free the memory that can be freed, think of it as a garbage collector.
I assume the ˋmodelˋ variable contains the pretrained model. Since the variable doesn’t get out of scope, the reference to the object in the memory of the GPU still exists and the latter is thus not freed by empty_cache().
Try executing ˋdel modelˋ before ˋempty_cache()` to explicitly delete the variable and remove all reference to objects in the GPU’s memory.
 rlouf
on 6 Nov 2019
rlouf
on 6 Nov 2019
Thank you for taking the time to review and comment! That makes sense, however, doesn't my code (lines 3rd and 4th from end below) execute del model before calling torch.cuda.empty_cache()?
show_gpu('Initial GPU memory usage:')
for i in range(2):
model, optimizer, scheduler = get_training_obj(params)
show_gpu(f'{i}: GPU memory usage after loading training objects:')
for epoch in range(1):
epoch_start = time.time()
model.train()
for batch in dp.train_dataloader:
xb,mb,_,yb = tuple(t.to(params['device']) for t in batch)
outputs = model(input_ids = xb, attention_mask = mb, labels = yb)
loss = outputs[0]
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
show_gpu(f'{i}: GPU memory usage after training model:')
del model, optimizer, scheduler, loss, outputs ## <<<<---- HERE
torch.cuda.empty_cache() ## <<<<---- AND HERE
torch.cuda.synchronize()
show_gpu(f'{i}: GPU memory usage after clearing cache:')
(You are correct that the variable model contains the pre-trained model.)
josiahdavis
on 6 Nov 2019
I updated the code to print out GPU usage after loading the batch to GPU and after completing the forward pass for the first 5 batches of each run. It seems the big memory jumps occur during the first and second forward pass and the second loading of the batch to the GPU. Aside from these events, it seems the memory usage is relatively constant across a given training run.
Initial GPU memory usage: 0.0% (0 out of 16130)
0: GPU memory usage after loading training objects: 14.7% (2377 out of 16130)
0: GPU memory usage after loading batch 0: 14.7% (2377 out of 16130)
0: GPU memory usage after forward pass 0: 43.6% (7029 out of 16130)
0: GPU memory usage after loading batch 1: 49.1% (7927 out of 16130)
0: GPU memory usage after forward pass 1: 70.0% (11289 out of 16130)
0: GPU memory usage after loading batch 2: 70.6% (11393 out of 16130)
0: GPU memory usage after forward pass 2: 70.6% (11393 out of 16130)
0: GPU memory usage after loading batch 3: 70.6% (11393 out of 16130)
0: GPU memory usage after forward pass 3: 70.6% (11393 out of 16130)
0: GPU memory usage after loading batch 4: 70.6% (11393 out of 16130)
0: GPU memory usage after forward pass 4: 70.6% (11393 out of 16130)
0: GPU memory usage after training model: 70.8% (11415 out of 16130)
0: GPU memory usage after clearing cache: 41.8% (6741 out of 16130)
1: GPU memory usage after loading training objects: 50.2% (8093 out of 16130)
1: GPU memory usage after loading batch 0: 50.2% (8093 out of 16130)
1: GPU memory usage after forward pass 0: 78.6% (12673 out of 16130)
1: GPU memory usage after loading batch 1: 84.3% (13593 out of 16130)
Traceback (most recent call last):
File "14_OOM_submission.py", line 102, in <module>
outputs = model(input_ids = xb, attention_mask = mb, labels = yb)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/transformers/modeling_roberta.py", line 328, in forward
head_mask=head_mask)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/transformers/modeling_roberta.py", line 181, in forward
head_mask=head_mask)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py", line 627, in forward
head_mask=head_mask)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py", line 348, in forward
layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py", line 328, in forward
intermediate_output = self.intermediate(attention_output)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py", line 300, in forward
hidden_states = self.intermediate_act_fn(hidden_states)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/transformers/modeling_bert.py", line 128, in gelu
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
RuntimeError: CUDA out of memory. Tried to allocate 26.00 MiB (GPU 0; 15.75 GiB total capacity; 14.24 GiB already allocated; 8.88 MiB free; 476.01 MiB cached)
Yes I'm sorry, I misread the code the first time. Did you try clearing the last batch as well?
rlouf
on 6 Nov 2019
I did, same result :(
josiahdavis
on 6 Nov 2019
So if you delete xb, mb, yb you still get the same memory usage after clearing the cache?
rlouf
on 6 Nov 2019
Yes. Just for kicks I also tried deleting xb, mb, yb after every forward pass (i.e., within the batch loop) and also clearing the cache and and confirmed that there is no difference here either.
josiahdavis
on 6 Nov 2019
Ok, I may have an idea. You can have a look at the tensors that are still tracked by python's garbage collector using something along the lines of:
import gc
for tracked_object in gc.get_objects():
if torch.is_tensor(tracked_object):
print("{} {} {}".format(
type(tracked_object).__name__,
"GPU" if tracked_object.is_cuda else "" ,
" pinned" if tracked_object.is_pinned() else "",
))
Thanks! I'm digging into it now... there is a lot that is showing up. Here is the output right after getting the OOM error.
josiahdavis
on 6 Nov 2019
Oops, quick update I just made, the " pinned" if... statement part should be a method not an attribute. Updating it produces a different output, showing that none of the objects are pinned.
import gc
for tracked_object in gc.get_objects():
if torch.is_tensor(tracked_object):
print("{} {} {}".format(
type(tracked_object).__name__,
"GPU" if tracked_object.is_cuda else "" ,
" pinned" if tracked_object.is_pinned() else "",
))
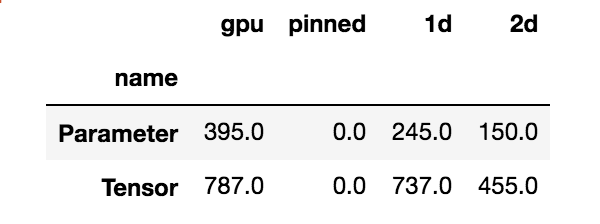
This is the core of my confusion. Why are their so many objects in memory after I have deleted everything I can think of in my script. I did a quick summary of the output of the code you just provided after running a single training job and deleting the aforementioned objects (del model, optimizer, scheduler, outputs, loss, xb, mb, yb, batch) and emptying the cache (torch.cuda.empty_cache()):
import pandas as pd
import gc
result = []
for tracked_object in gc.get_objects():
if torch.is_tensor(tracked_object):
shape = tracked_object.shape
result.append({
'name': type(tracked_object).__name__,
'1d': len(shape)==1,
'2d': len(shape)==2,
'nrows': shape[0],
'ncols': shape[1] if (len(shape) > 1) else None,
'gpu': tracked_object.is_cuda,
'pinned': tracked_object.is_pinned()
})
d = pd.DataFrame(result)
d.groupby('name')['gpu', 'pinned', '1d', '2d'].sum()
josiahdavis
on 6 Nov 2019
Do you know which objects they correspond to?
rlouf
on 6 Nov 2019
I think they correspond to the parameters and gradients of the roberta-large model. (So strange that they are still there after I deleted the model at the end of the training job.)
Here is a single layer of the model:
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=1024, out_features=1024, bias=True)
(key): Linear(in_features=1024, out_features=1024, bias=True)
(value): Linear(in_features=1024, out_features=1024, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=1024, out_features=1024, bias=True)
(LayerNorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=1024, out_features=4096, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=4096, out_features=1024, bias=True)
(LayerNorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
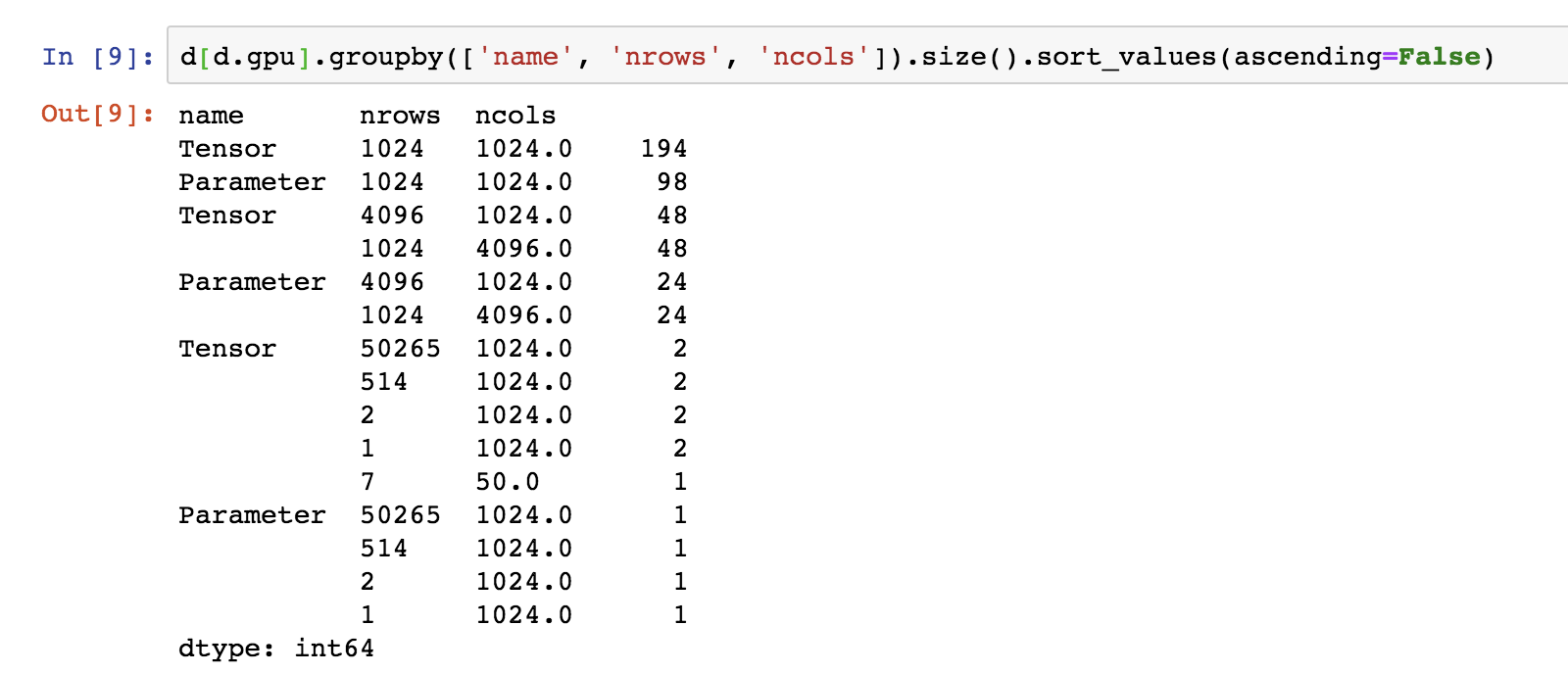
Here is the summary of what's being stored in GPU:
josiahdavis
on 6 Nov 2019
I think this person is on to something: https://discuss.pytorch.org/t/releasing-gpu-memory-after-deleting-model/48167
josiahdavis
on 6 Nov 2019
Mmm I stared for a really long time at your code, and it seems to be that the memory of the _ element of the tuple is never freed (token type ids?). I believe that in Python its throwaway meaning is a convention, and the memory is effectively allocated. That’s the only think I can see that has not been freed with your previous attempts.
rlouf
on 6 Nov 2019
Thank you so much for looking into it!
The token type ids was a good idea, though it does not appear to impact anything.
However, I made some progress. What I discovered:
I am unable to remove the model parameters from GPU when I load the WarmupLinearSchedule from transformers: e.g.,
from transformers import WarmupLinearSchedule
...
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=warmup_steps, t_total=params['total_steps'])
However, when I use a standard scheduler (e.g., StepLR) I have no issue with deleting the model from the GPU:
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
Here is the code for WarmupLinearSchedule for reference that your team wrote. Seems pretty reasonable to me, not sure why it would be causing an issue when a standard learning rate scheduler is not (e.g., both LambdaLR and StepLR inherit from _LRScheduler):
class WarmupLinearSchedule(LambdaLR):
""" Linear warmup and then linear decay.
Linearly increases learning rate from 0 to 1 over `warmup_steps` training steps.
Linearly decreases learning rate from 1. to 0. over remaining `t_total - warmup_steps` steps.
"""
def __init__(self, optimizer, warmup_steps, t_total, last_epoch=-1):
self.warmup_steps = warmup_steps
self.t_total = t_total
super(WarmupLinearSchedule, self).__init__(optimizer, self.lr_lambda, last_epoch=last_epoch)
def lr_lambda(self, step):
if step < self.warmup_steps:
return float(step) / float(max(1, self.warmup_steps))
return max(0.0, float(self.t_total - step) / float(max(1.0, self.t_total - self.warmup_steps)))
@LysandreJik any idea why that might be?
rlouf
on 7 Nov 2019
@LysandreJik thanks for taking a look! To summarise my issue in a minimal example I am attaching screenshots + complete code for a minimal reproducible example that gets at the crux of the issue (w/downloading any data).

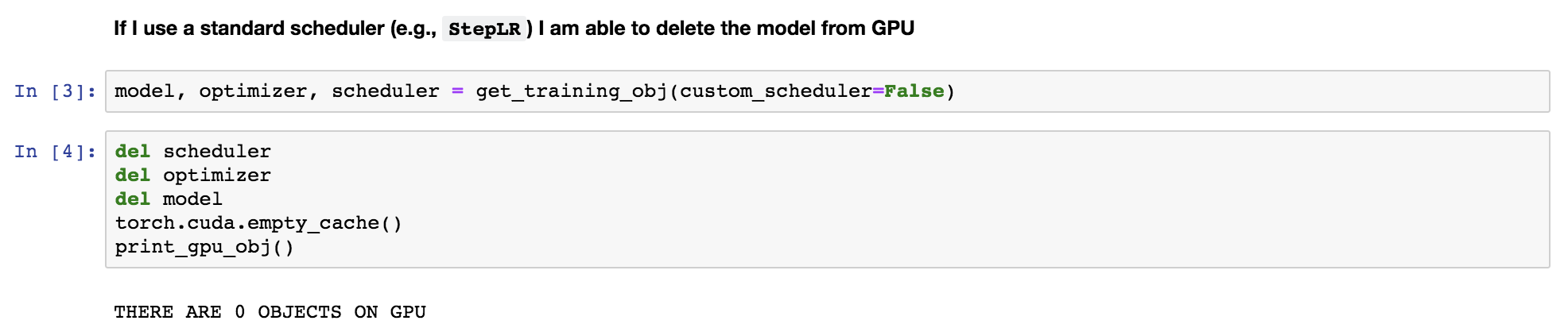

Here is the complete code to reproduce these screenshots code.txt.
josiahdavis
on 8 Nov 2019
Hi, there indeed seems to be an issue with the schedulers. Probably related to #1134
 LysandreJik
on 8 Nov 2019
LysandreJik
on 8 Nov 2019
I don’t see any circular references in your code but a gc.collect() after del cannot hurt—garbage collection is clearly not what takes the longest here. Let me know if this solves the problem.
rlouf
on 8 Nov 2019

So I instantiated WarmupLinearSchedule with AdamW and this is what objgraph gives me: there is a circular reference that seems to come with our implementation. gc.collect() should work as a temporary workaround, if that (I hope) is the issue.
Edit: Would you mind adding the following right after gc.collect() and giving us the result?
for item in gc.garbage:
print(item)
Thank you so much! This order of operations does the trick for me, removing the parameters and gradients from the GPU.
- delete objects
gc.collect()torch.cuda.empty_cache()
Strangely, running your code snippet (for item in gc.garbage: print(item)) after deleting the objects (but not calling gc.collect() or empty_cache()) doesn't print out anything.
josiahdavis
on 9 Nov 2019
Regarding the aforementioned 1. I ran a couple of quick tests. The only objects I need to delete in order to delete the model parameters and gradients is the optimizer and scheduler. (I do not need to delete the outputs, loss, batch data.) As you can see from the screengrab below the only objects on GPU are xb, mb, yb, ([32,50]) tt ([32]), loss ([]), output ([32,2]) and the parameters and gradients are not there.

josiahdavis
on 9 Nov 2019
- delete objects
gc.collect()torch.cuda.empty_cache()Strangely, running your code snippet (
for item in gc.garbage: print(item)) after deleting the objects (but not callinggc.collect()orempty_cache()) doesn't print out anything.
Sorry, maybe I wasn’t completely clear: you need to run it right after garbage collection.
Does that completely solve your Out Of Memory issue? Thank you for raising the issue and helping us find the solution :)
This is apparently bothering other users, but I am not 100% sure we can easily do something about it; Would you mind trying to initialize the scheduler with the following function and tell me if you still have a memory error? (without using gc.collect())
def warmup_linear_schedule(optimizer, warmup_steps, t_total, last_epoch=-1):
def lr_lambda(step):
if step < warmup_steps:
return float(step) / float(max(1, warmup_steps))
return max(0.0, float(t_total - step) / float(max(1.0, t_total - warmup_steps)))
return LambdaLR(optimizer, lr_lambda, last_epoch=-1)
There might be a reference mixup when we subclass LambdaLR; using a closure may avoid this.
rlouf
on 9 Nov 2019
Yes, it does solve my issue! I am currently running some training jobs on my GPU (thanks to your help!). I will try out the closure approach once I finish up with those and get back with you on this thread.
josiahdavis
on 9 Nov 2019
Thanks guys for the great discussion.
(leaving a comment so i can access this thread whenever need, sorry for a useless comment)
 AdityaSoni19031997
on 12 Nov 2019
AdityaSoni19031997
on 12 Nov 2019
(Apologies for the delayed response.)
I just tested it out and it worked as expected. No need to call gc.collect() now when removing parameters and gradients from GPU. Thank you so much @rlouf, I commend you for your attentiveness to resolving the issue and updating your examples.
josiahdavis
on 18 Nov 2019
Related issues
 alphanlp
·
3Comments
alphanlp
·
3Comments
 lemonhu
·
3Comments
lemonhu
·
3Comments
 delip
·
3Comments
delip
·
3Comments
 yspaik
·
3Comments
yspaik
·
3Comments
 adigoryl
·
3Comments
adigoryl
·
3Comments
Most helpful comment
Yes, it does solve my issue! I am currently running some training jobs on my GPU (thanks to your help!). I will try out the closure approach once I finish up with those and get back with you on this thread.