Tpot: Issue with cuML: "Current best internal CV score: -inf"
(EDIT: see comment below for quicker repro steps)
I'm trying to make use of a GPU-accelerated environment to train a TPOT Regression pipeline.
After two generations, when tpot computes the first CV score, the result goes straight to negative infinity:
Generation 1 - Current best internal CV score: -inf
After that, it outputs this rather unintelligible error:
RuntimeError: There was an error in the TPOT optimization process. This could be because the data was not formatted properly, or because data for a regression problem was provided to the TPOTClassifier object. Please make sure you passed the data to TPOT correctly. If you enabled PyTorch estimators, please check the data requirements in the online documentation: https://epistasislab.github.io/tpot/using/
Environment
I spun a fresh g4dn.xlarge machine on AWS. Ubuntu 18.04, Python 3.7. This is what nvidia-smi is outputting:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 73C P0 67W / 70W | 1522MiB / 15109MiB | 93% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 9058 C ...vs/rapids-0.17/bin/python 1519MiB |
+-----------------------------------------------------------------------------+
I installed cuML with this command:
conda create -n rapids-0.17 -c rapidsai -c nvidia -c conda-forge -c defaults rapids-blazing=0.17 python=3.7 cudatoolkit=11.0
That generated a conda environment. I then installed tpot and related dependencies, in this way:
conda activate rapids-0.17
conda install -c conda-forge tpot dask dask-ml scikit-mdr skrebate
Pytorch has not been installed in this conda environment.
Process to reproduce the issue
The following Hello World will reproduce the bug. I tried to change the number of samples and features, and the size of the CV, with no avail.
from tpot import TPOTRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
NSAMPLES = 15000
NFEATURES = 150
SEED = 12
# For cuML with TPOT, you must use CPU data (such as NumPy arrays)
X, y = make_regression(
n_samples=NSAMPLES,
n_features=NFEATURES,
n_informative=NFEATURES,
random_state=SEED,
noise=200,
)
X = X.astype("float32")
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=12)
# TPOT setup
GENERATIONS = 5
POP_SIZE = 100
CV = 5
tpot = TPOTRegressor(
generations=GENERATIONS,
population_size=POP_SIZE,
random_state=SEED,
config_dict="TPOT cuML",
n_jobs=1, # cuML requires n_jobs=1
cv=CV,
verbosity=2,
)
tpot.fit(X_train, y_train)
preds = tpot.predict(X_test)
print(r2_score(y_test, preds))
print(tpot.export())
Full error print out
Below, a full copy of the error:
Optimization Progress: 33%
200/600 [11:11<12:39, 1.90s/pipeline]
Generation 1 - Current best internal CV score: -inf
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
~/anaconda3/envs/rapids-0.17/lib/python3.7/site-packages/tpot/base.py in fit(self, features, target, sample_weight, groups)
741 per_generation_function=self._check_periodic_pipeline,
--> 742 log_file=self.log_file_
743 )
~/anaconda3/envs/rapids-0.17/lib/python3.7/site-packages/tpot/gp_deap.py in eaMuPlusLambda(population, toolbox, mu, lambda_, cxpb, mutpb, ngen, pbar, stats, halloffame, verbose, per_generation_function, log_file)
280 if per_generation_function is not None:
--> 281 per_generation_function(gen)
282
~/anaconda3/envs/rapids-0.17/lib/python3.7/site-packages/tpot/base.py in _check_periodic_pipeline(self, gen)
1051 """
-> 1052 self._update_top_pipeline()
1053 if self.periodic_checkpoint_folder is not None:
~/anaconda3/envs/rapids-0.17/lib/python3.7/site-packages/tpot/base.py in _update_top_pipeline(self)
837 break
--> 838 raise RuntimeError('There was an error in the TPOT optimization '
839 'process. This could be because the data was '
RuntimeError: There was an error in the TPOT optimization process. This could be because the data was not formatted properly, or because data for a regression problem was provided to the TPOTClassifier object. Please make sure you passed the data to TPOT correctly. If you enabled PyTorch estimators, please check the data requirements in the online documentation: https://epistasislab.github.io/tpot/using/
During handling of the above exception, another exception occurred:
RuntimeError Traceback (most recent call last)
<ipython-input-8-e01323d79c09> in <module>
37 )
38
---> 39 tpot.fit(X_train, y_train)
40
41 preds = tpot.predict(X_test)
~/anaconda3/envs/rapids-0.17/lib/python3.7/site-packages/tpot/base.py in fit(self, features, target, sample_weight, groups)
771 # raise the exception if it's our last attempt
772 if attempt == (attempts - 1):
--> 773 raise e
774 return self
775
~/anaconda3/envs/rapids-0.17/lib/python3.7/site-packages/tpot/base.py in fit(self, features, target, sample_weight, groups)
762 self._pbar.close()
763
--> 764 self._update_top_pipeline()
765 self._summary_of_best_pipeline(features, target)
766 # Delete the temporary cache before exiting
~/anaconda3/envs/rapids-0.17/lib/python3.7/site-packages/tpot/base.py in _update_top_pipeline(self)
836 error_score="raise")
837 break
--> 838 raise RuntimeError('There was an error in the TPOT optimization '
839 'process. This could be because the data was '
840 'not formatted properly, or because data for '
RuntimeError: There was an error in the TPOT optimization process. This could be because the data was not formatted properly, or because data for a regression problem was provided to the TPOTClassifier object. Please make sure you passed the data to TPOT correctly. If you enabled PyTorch estimators, please check the data requirements in the online documentation: https://epistasislab.github.io/tpot/using/
Additional info
By using the default config file, everything run smoothly. Using dask also doesn't give any relevant problem (but it's 2 to 3 times slower, as expected).
 giansegato
giansegato
All 7 comments
Quick update.
I got a fresh vanilla Ubuntu 18.04 server install, and I only installed the recommended package as suggested here in the documentation.
Repro steps
All the relevant commands from fresh system install (virgin Nvidia AMI) to the error:
1 sudo apt-get update
2 sudo apt-get upgrade
3 sudo apt-get install python3.8
4 wget https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.sh
5 bash Anaconda3-2020.11-Linux-x86_64.sh
6 source ~/.bashrc
7 wget https://raw.githubusercontent.com/EpistasisLab/tpot/master/tpot-cuml.yml
8 conda env create -f tpot-cuml.yml -n tpot-cuml
9 conda activate tpot-cuml
10 wget https://raw.githubusercontent.com/EpistasisLab/tpot/master/tutorials/cuML_Regression_Example.ipynb
11 pip install jupyter
12 jupyter notebook
Moving forward, in a Jupyter environment, running the cuML_Regression_Example.ipynb file outputs the same error as before.
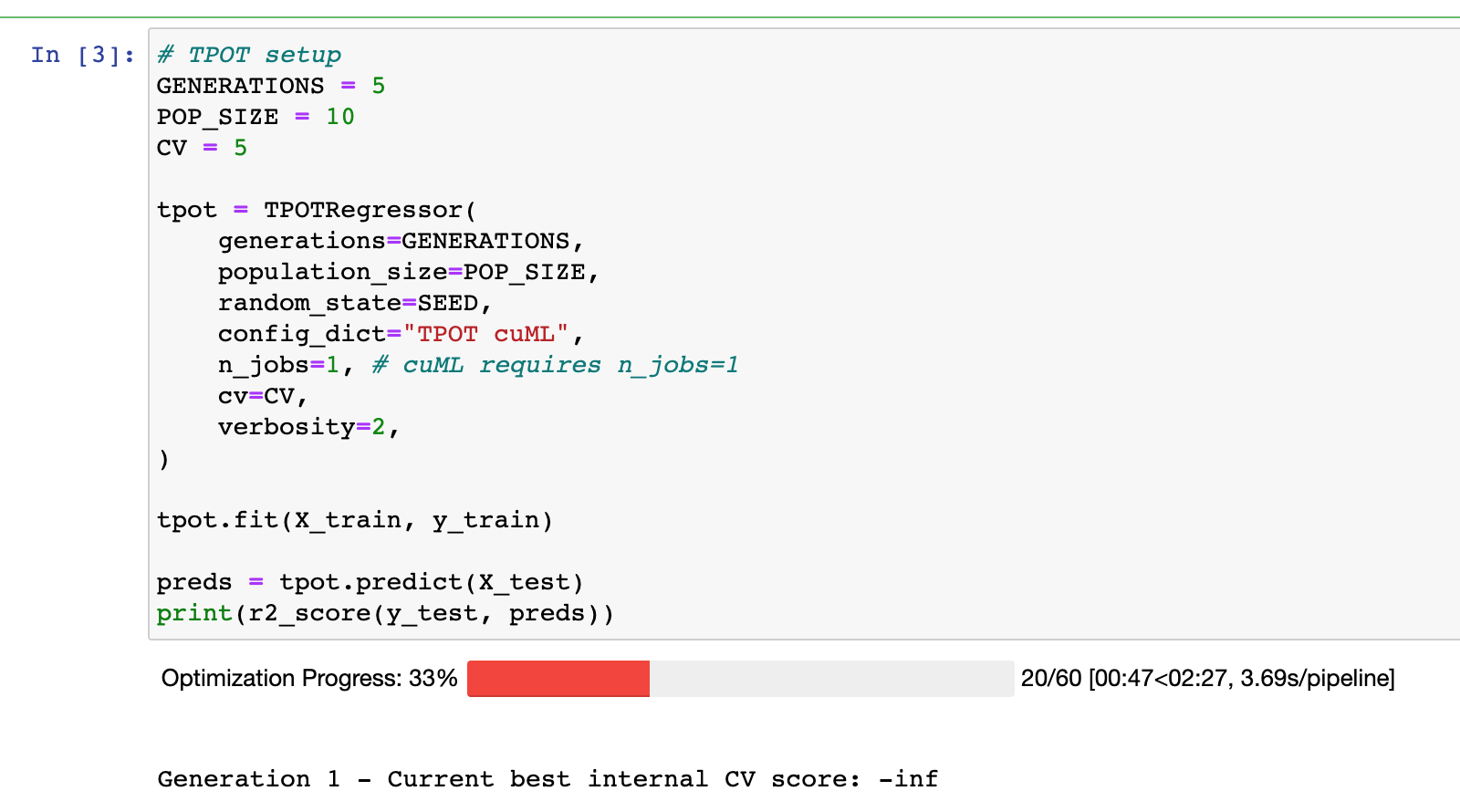
_(I decreased the number of population individuals and epochs to get the screenshot faster, but changing them doesn't make the result differ.)_
giansegato
on 31 Dec 2020
Thank you for reporting this issue. I will be back to work for checking it next Wednesday. But I will try to debug it if I get a chance meanwhile. Could you please let me know the versions of TPOT and its dependencies in your environment? Also please share that jupyter notebook with all stderr messages via a GitHub link. Thank you.
 weixuanfu
on 31 Dec 2020
weixuanfu
on 31 Dec 2020
Thanks @weixuanfu!
Here you can find the full Jupyter notebook with the error output (for some weird reasons "Optimization Progress" progress bar is presented at 0%; it actually stopped at 20/60, as you can see from my previous screenshot). I forked the notebook from the original examples folder available here.
I'm currently running tpot=0.11.6.post3, installed via conda in the following way: conda env create -f tpot-cuml.yml -n tpot-cuml, using this conda enviornment file. Python version is Python 3.7.9.
This is my current tpot dependency tree:
tpot 0.11.6.post3 pyhd3deb0d_0
------------------------------
file name : tpot-0.11.6.post3-pyhd3deb0d_0.tar.bz2
name : tpot
version : 0.11.6.post3
build : pyhd3deb0d_0
build number: 0
size : 82 KB
license : LGPL-3.0-or-later
subdir : noarch
url : https://conda.anaconda.org/conda-forge/noarch/tpot-0.11.6.post3-pyhd3deb0d_0.tar.bz2
md5 : 78120def91befbeeb56147675f2ef0df
timestamp : 2020-12-14 22:46:09 UTC
dependencies:
- deap >=1.2
- joblib >=0.13.2
- numpy >=1.16.3
- pandas >=0.24.2
- py-xgboost >=0.90
- python >=3.5
- scikit-learn >=0.22.0
- scipy >=1.3.1
- stopit >=1.1.1
- tqdm >=4.36.1
- update_checker >=0.16
I made available a full list of the packages installed in the conda environment in here. In particular, tpot is making use of cuml=0.16.0=cuda10.2_py37_gbbe737348_0. I noticed that the latest cuml version is 0.17, but from previous tests 0.17 doesn't fix the problem.
I noticed that the cuml build is referring cuda 10.2, while on my system I've cuda 11.0 installed. I'm not sure whether this can be relevant to debugging the problem, but I wanted to highlight the discrepancy.
Enjoy your NYE, and have a happy 2021!
giansegato
on 31 Dec 2020
I can reproduce this locally. It also reproduces with the scikit-learn TPOT, too. With an environment with scikit-learn 0.23.2 (the one that comes by default with the commands below), the snippet below works fine. In the same environment but with conda remove scikit-learn --force; conda install -c conda-forge scikit-learn=0.24, I get the same negative infinity RuntimeError (the cuML environment linked above uses scikit-learn 0.24)
Perhaps this is due to general scikit-learn 0.24 compatibility?
conda create -n tpot-test python=3.7
conda activate tpot-test
conda install -c conda-forge tpot dask dask-ml ipython
from tpot import TPOTRegressor
from sklearn.datasets import make_regression
NSAMPLES = 1000
NFEATURES = 10
SEED = 12
X, y = make_regression(
n_samples=NSAMPLES,
n_features=NFEATURES,
n_informative=NFEATURES,
random_state=SEED,
noise=200,
)
tpot = TPOTRegressor(
generations=2,
population_size=2,
random_state=SEED,
n_jobs=1,
cv=2,
verbosity=2,
)
tpot.fit(X, y)
 beckernick
on 31 Dec 2020
beckernick
on 31 Dec 2020
@beckernick thanks for suggesting downgrading scikit-learn to 0.23.2, it worked perfectly now.
 rishabhindoria
on 31 Dec 2020
rishabhindoria
on 31 Dec 2020
I confirm that conda remove scikit-learn --force; conda install -c conda-forge scikit-learn=0.23.2 does indeed fix the issue!
giansegato
on 1 Jan 2021
Thank both of you for debuting this issue.
This issue should be fixed in recent release (v0.11.7) of TPOT. Please update TPOT and feel free to reopen this issue if it still exists.
weixuanfu
on 6 Jan 2021
Related issues
 TomAugspurger
·
4Comments
TomAugspurger
·
4Comments
 rhiever
·
4Comments
rhiever
·
4Comments
 qtisan
·
3Comments
qtisan
·
3Comments
 fferroni
·
4Comments
fferroni
·
4Comments
 chjq201410695
·
4Comments
chjq201410695
·
4Comments
Most helpful comment
I can reproduce this locally. It also reproduces with the scikit-learn TPOT, too. With an environment with scikit-learn 0.23.2 (the one that comes by default with the commands below), the snippet below works fine. In the same environment but with
conda remove scikit-learn --force; conda install -c conda-forge scikit-learn=0.24, I get the same negative infinity RuntimeError (the cuML environment linked above uses scikit-learn 0.24)Perhaps this is due to general scikit-learn 0.24 compatibility?