Tpot: increase n_estimators in config_dict default
I recently evaluated tpot and compared the results to sklearn RandomForest. I noticed the config_dict only has [100] trees in the default dict. I recommend this be increased to [100, 500] or something similar. Same with ExtraTreesClassifier. In my experience, n_estimators is a crucial parameter and it would be nice if the default config had a higher number of trees so new users can get optimal results out of the box. I beat the tpot optimized result (using defaults) on the first try just using n_estimators = 500.
 crawles
crawles
All 5 comments
Thank you for the suggestion. I agree that n_estimators is a crucial parameter. But, increasing n_estimator to 500 may largely increase computational time of pipeline evaluation (check #384 for more details). We need more evaluation before increasing n_estimators in default config_dict
 weixuanfu
on 25 Jul 2017
weixuanfu
on 25 Jul 2017
From our internal tests, we've found that the RandomForest has small improvements when adding beyond 100 trees. You can use a custom configuration dictionary, though, if you want TPOT to explore a larger number of trees.
 rhiever
on 2 Aug 2017
rhiever
on 2 Aug 2017
Thanks @rhiever. Understood about the custom configuration dictionary. I was surprised that RF with 500 trees beat TPOT result. Understand it's not automatically optimized out of the box. Thinking about it more, I used all default TPOT setup (population size and generations). I see in the docs you recommend AutoML is often designed to run for a long time, so impatience could have been it :)
I ran a little experiment on MNIST. There is an average and median increase after 100 trees. The average score improvement is marginal.
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
n_trees = [10,25,50,75,100,200,300,400,500,600,700,800,900,1000]
scores = []
for n in n_trees:
cl = RandomForestClassifier(n_estimators=n)
score = cross_val_score(cl, digits.data, digits.target, cv=10)
scores.append(score)
plt.figure(figsize=(12,8))
scores = np.array(scores)
scores_mean = scores.mean(axis=1)
scores_median = np.median(scores2, axis=1)
scores_min = scores.min(axis=1)
scores_max = scores.max(axis=1)
plt.plot(n_trees, scores_mean, label='mean score')
plt.fill_between(n_trees, scores_min, scores_max, alpha=0.5)
plt.plot(n_trees, scores_median, label='median score')
plt.vlines(100, 0.94, 0.96, label='100 estimators')
plt.xlabel('n_estimators')
plt.ylabel('accuracy')
plt.legend()
plt.xlim(0,500)
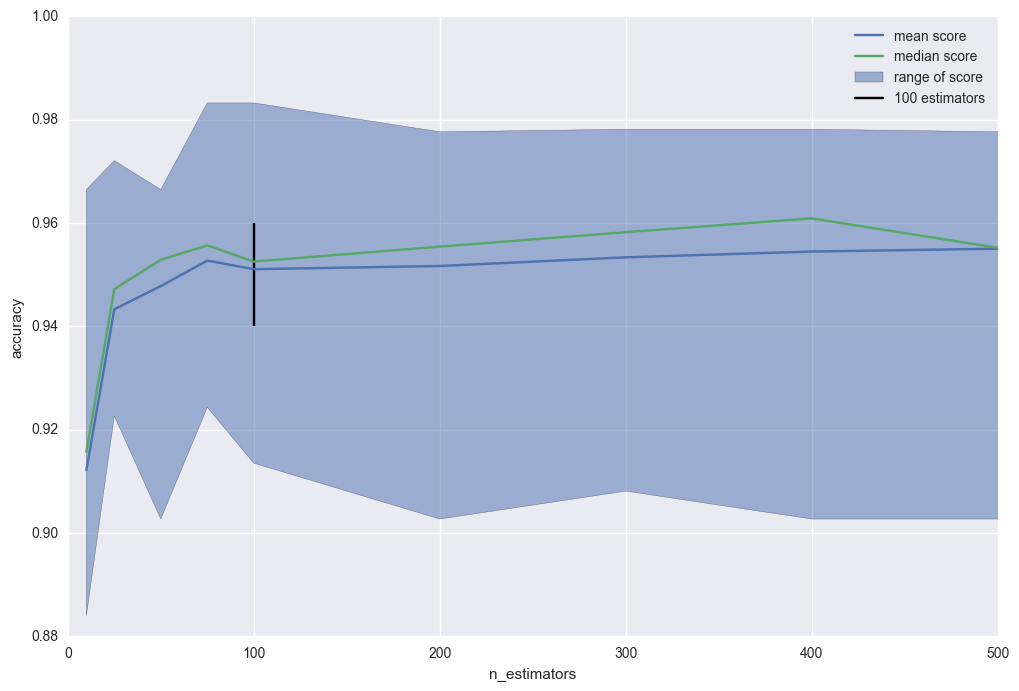
crawles
on 9 Aug 2017
That's more-or-less what we've seen across 100s of datasets. Glad you were able to replicate it.
rhiever
on 9 Aug 2017
Closing this issue. Please feel free to re-open or file a new issue if you have any further questions or comments.
rhiever
on 10 Oct 2017
Related issues
 TaherHabib
·
4Comments
TaherHabib
·
4Comments
 KhaledSharif
·
5Comments
KhaledSharif
·
5Comments
 CBrauer
·
5Comments
CBrauer
·
5Comments
 windowshopr
·
4Comments
windowshopr
·
4Comments
 lampsoft
·
3Comments
lampsoft
·
3Comments
Most helpful comment
Thanks @rhiever. Understood about the custom configuration dictionary. I was surprised that RF with 500 trees beat TPOT result. Understand it's not automatically optimized out of the box. Thinking about it more, I used all default TPOT setup (population size and generations). I see in the docs you recommend AutoML is often designed to run for a long time, so impatience could have been it :)
I ran a little experiment on MNIST. There is an average and median increase after 100 trees. The average score improvement is marginal.