Tpot: Custom Scorer that is function of features (not just predicted and true y-values)
I was intrigued by tpot's potential to quickly find a good machine learning pipeline, but unfortunately the objective function I seek to optimize during fitting is not just a function of the predicted and true y-values, but rather those and the x-values/features used. In other words, I seek to implement a cost/loss/scorer function like below:
def accuracy(y_true, y_pred, x_used): # note that each x_used must correspond to each y_pred
return something_that_depends_on_all_three_arguments
But currently the only supported cost function has the signature
def accuracy(y_true, y_pred):
return something_that_does_not_depend_on_x_used
I think generalizing the cost function in this way greatly expands the realm of what problems tpot is able to optimize. In my case, each y_pred determines which of three actions should occur, but the consequences of each action depends on a couple numbers in each x_used, and it is the sum of these consequences for all the predictions that I wish to optimize.
I would be happy to _attempt_ to alter the code to implement this functionality if anyone can point me where to start.
Feel free to clear up any conceptual misunderstandings I might be illuminating by asking this question.
 joseortiz3
joseortiz3
All 12 comments
Interesting idea. I think you need define this customized scoring function. You can start from tpot.metrics (metrics.py in tpot source codes, also see the codes below). Even though make_score function from scikit-learn only use score_func(y_true, y_pred, **kwargs), you may hack into the **kwargs part to add x_used (maybe defined it as a global variable for using it in the new scoring function). Also you can check these scoring function in scikit-learn to build the customized one.
Please also check the TPOT document for using this customized version of TPOT.
In [12]: import tpot.metrics
In [13]: tpot.metrics.SCORERS
Out[13]:
{'accuracy': make_scorer(accuracy_score),
'adjusted_rand_score': make_scorer(adjusted_rand_score),
'average_precision': make_scorer(average_precision_score, needs_threshold=True),
'balanced_accuracy': make_scorer(balanced_accuracy),
...
 weixuanfu
on 3 Nov 2016
weixuanfu
on 3 Nov 2016
@weixuanfu2016, were you able to hack up a demo of this as we discussed yesterday?
@joseortiz3, there seems to be a way to hack something like this into TPOT/sklearn, but it's pretty non-standard. You need to hack your scoring function into tpot.metrics.SCORERS, then make your instance of TPOT use that scoring function (set tpot_instance. scoring_name to the name of your scoring function in the tpot.metrics.SCORERS dictionary).
 rhiever
on 3 Nov 2016
rhiever
on 3 Nov 2016
Here is a demo. Hope it could be helpful
# for editing tpot/metrics.py
from sklearn.metrics import make_scorer, SCORERS
import numpy as np
def custom_scorer(y_true, y_pred, X_used = None):
"""
Parameters
----------
y_true: numpy.ndarray {n_samples}
True class labels
y_pred: numpy.ndarray {n_samples}
Predicted class labels by the estimator
X_used: numpy.ndarray {n_samples, n_features_used}
A numpy matrix containing the training and used features for the
`individual`'s evaluation
Returns
-------
fitness: float
Returns a float value indicating the `individual`'s accuracy
"""
def custom_conseq_func(y_pred, X_used):
"""
define the consequence of action
return y_pred_consequences
just a example:
"""
if X_used:
for i in X_used.shape[0]:
if list(X_used[i,]).count(1) > 10:
y_pred[i] = 0
return y_pred
y_pred_consequences = custom_func(y_ture, X_used)
all_classes = list(set(np.append(y_true, y_pred_consequences)))
all_class_accuracies = []
for this_class in all_classes:
this_class_sensitivity = \
float(sum((y_pred_consequences == this_class) & (y_true == this_class))) /\
float(sum((y_true == this_class)))
this_class_specificity = \
float(sum((y_pred_consequences != this_class) & (y_true != this_class))) /\
float(sum((y_true != this_class)))
this_class_accuracy = (this_class_sensitivity + this_class_specificity) / 2.
all_class_accuracies.append(this_class_accuracy)
return np.mean(all_class_accuracies)
# register custom_scorer
# need also define the self.used_features to
# then you can use the custom_scorer with scoring='custom_scorer' in scripts of TPOT
# X_used = used_features is a kwarg passing to custom_scorer function
# Note: !!used_features need to be a global variable if you don't want to change too much in base.py
SCORERS['custom_scorer'] = make_scorer(custom_scorer, X_used = used_features)
@rhiever Thanks for that. So you don't think I'll have to hack new classes and functions into sklearn.metrics.scorer? I just want to clear this up, since from what I've seen, it looks like I need to hack sklearn more than tpot to get this to work.
It seems to me the way we add a scorer to TPOT's SCORERS dictionary is to do the following in tpot.metrics (or sklearn.metrics.scorer):
SCORERS['custom_scorer_name'] = make_scorer(custom_scorer)
(where custom_scorer is now def custom_scorer(y_true, y_pred, x_used))
but make_scorer is defined in sklearn.metrics.scorer, and is a function that currently only has the insufficient arguments:
def make_scorer(score_func, greater_is_better=True, needs_proba=False, needs_threshold=False, **kwargs):
It seems to me I would have to add another optional argument needs_xvals=False to make_scorer, that would make my scorer's class brand-new class: _XvalScorer (which would be adding another class to the three currently defined under sklearn.metrics.scorer: ThresholdScorer, ProbaScorer, and PredictScorer.) My new class would be able to call its self._score_func with the self._score_func(y_true, y_pred, x_used) signature.
Sounds like that's all I need to do? If so, I think I will try doing it soon.
@weixuanfu2016 I see what you did there: You used the kwargs argument of make_scorer to pass X_used to the scoring function through the scoring class. Didn't realize X_used would then become the self._kwargs member variable of sklearn.metrics.scorer._BaseScorer class, which would then make it available to self._score_func which is currently called by:
self._score_func(y_true, y_pred, **self._kwargs)
That's pretty neat (maybe it's considered best-practices in python?). That's nice, considering I don't have to hack anything.
The following might be a misconception:
_The major problem with this is some array X_used will be permanently referenced by my _BaseScorer subclass. So I'm more inclined to hack sklearn (maybe it will be a supported feature someday)._
joseortiz3
on 3 Nov 2016
@weixuanfu2016's solution is probably the "best" solution in sklearn terms. You can then pass arbitrary X matrices to the function resulting from make_scorer(custom_scorer, X_used = used_features), as X_used is a parameter of the scoring function and not a fixed value.
rhiever
on 4 Nov 2016
Well, I did it, but it didn't do what I was naively hoping it would by adding a new subclass to sklearn.metrics.scorer. The custom scoring function works, but the models do not use it for optimization, so there is little point in using it.
I was [very naively] hoping that my custom scoring function would be used as the loss function for all the models included in TPOT. Yes, it's absurd, but I thought it.
Now I'm trying to see if TPOT might work with sample_weights. This sounds like the closest thing to solving my problem. I will make another issues thread, since this is unrelated to the current one. Feel free to close this, we found the answer to my original question.
joseortiz3
on 12 Nov 2016
Can you please clarify: Where did you inject the scoring function? If you inject your scoring function into the SCORING dictionary and set TPOT's scoring_function to a string containing your scoring function, as we do here, TPOT should use that scoring function for the optimization process.
rhiever
on 15 Nov 2016
I put the custom scoring function into the SCORERS dictionary using my hacked make_scorer, and it worked fine. Unfortunately, the individual models (xgboost,etc..) will still only use the loss functions they are designed to support (such as least squares). I now know that many models work well only with certain loss functions, that passing my arbitrary scoring function as the loss function would probably (?) not work. It's still helpful to have the xvals scoring functionality however, and I will probably continue to use it. I can basically accomplish what I wanted to do by getting TPOT to use sample_weights.
#uses my custom subclass XValScorer due to my added argument needs_xvals
SCORERS['x_score'] = make_scorer(my_custom_func,needs_xvals = True)
#works fine
model = tpot.TPOTRegressor(generations = 6, population_size = 10, scoring='x_score', verbosity =3)
We exposed sample_weights in the latest version on the development branch. Hope that's useful in the next release!
rhiever
on 19 Dec 2016
I am unable to create a custom scorer and feed it into tpot
I try the following:
my_scorer = make_scorer(fbeta_score, beta=beta, pos_label=1, average='binary')
tpot = TPOTClassifier(verbosity=2,
scoring=my_scorer,
random_state=23,
periodic_checkpoint_folder="tpot_out.txt",
n_jobs=-1,
generations=15, # INCREASE to 100
population_size=40,
cv=5)
tpot.fit(X_train, y_train)
I get an error:
Need to fit ...
 Vaderv
on 24 Apr 2019
Vaderv
on 24 Apr 2019
@NaderNazemi Could you please provide the fbeta_score function for letting us to reproduce this issue?
weixuanfu
on 25 Apr 2019
When I create my own score function and feed it into TPOT, I can't create a model when I set n_jobs = -1. My new score function is :

When I execute the following:
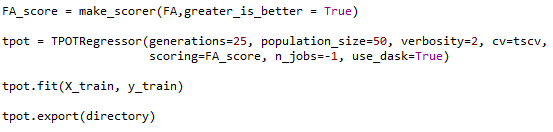
I obtain the next error:

I would appreciate any help!
Thank you,
Mario
 mariomm17
on 3 Dec 2019
mariomm17
on 3 Dec 2019
Related issues
 KhaledSharif
·
5Comments
KhaledSharif
·
5Comments
 heaven00
·
4Comments
heaven00
·
4Comments
 pan-alex
·
3Comments
pan-alex
·
3Comments
 beijingtl
·
4Comments
beijingtl
·
4Comments
 fferroni
·
4Comments
fferroni
·
4Comments
Most helpful comment
Here is a demo. Hope it could be helpful