Toml: Clarification: same bare and quotted keys sematically equivalent?
The question is simple: Do a and "a" refer to the same semantic key?
For example, is that forbidden?
a = 4
"a" = 5
My interpretation of the specification is that a and "a" are the same semantic key. It is what makes the most sense for me. However the implementation I use in Ocaml, To.ml, make them semantically separate. They have either KeyBare of string or KeyDotted of string (That's a sum type for those that do not know Ocaml) and so bare key and dotted keys can never overlap. Did I misunderstood or should I raise an issue on their side.
Furthermore, once this is clarified here, I strongly suggest you make it explicit in the standard because even if I read it one way on my first read, I have to admit I cannot prove that the other interpretation is wrong with the current specification text.
 CuiCui66
CuiCui66
All 33 comments
I agree it is not explicitly mentioned in the spec that they are the same. To the best of my knowledge, name, "name" and 'name' are equivalent, and while a parser may distinguish them while parsing, they should ultimately translate to the same key: the same name quoted or not should lead to an error.
Maybe there's a test case that covers this? If not, it would be good to add one.
Someone with more knowledge of the spec should probably give his or her insight here as well ;).
 abelbraaksma
on 5 May 2020
abelbraaksma
on 5 May 2020
All keys in TOML resolve to strings. To this end, treat bare keys like basic literal strings without the surrounding single quotes.
So it follows that k, "k", and 'k' are all the same key. Likewise, k is the same key as "\u006b".
 eksortso
on 6 May 2020
eksortso
on 6 May 2020
It might be useful to explicitly mention that keys are strings. Currently that is more or less implied.
Also, the example
# DO NOT DO THIS
name = "Tom"
name = "Pradyun"
could be changed to:
# DO NOT DO THIS
name = "Tom"
"name" = "Pradyun"
 ChristianSi
on 6 May 2020
ChristianSi
on 6 May 2020
That's reasonable. I'll make a PR.
eksortso
on 7 May 2020
What @eksortso said is correct.
I really don't think we need to make changes to the spec for this, since I think the only reason this issue came up is that an implementation is not handling them as expected/implied throughout the specification. (TOML maps to a JSON table, 3 -> "3" etc).
I'd much rather push correctness in implementations on this front through the compliance tests, rather than complicate our "keys" section more.
 pradyunsg
on 7 May 2020
pradyunsg
on 7 May 2020
@pradyunsg I disagree and would argue that at least a short explanation would improve the spec. Right now the string-nature of keys is merely implied, but never stated clearly and unambiguously.
Also, not every TOML document can be mapped losslessly to a JSON document, nor vice versa. (JSON lack's TOML's date/time types, TOML lack's JSON's null.)
ChristianSi
on 8 May 2020
I think the string nature of keys is clearly stated.
Bare keys may only contain ASCII letters, ASCII digits, underscores, and dashes (A-Za-z0-9_-). Note that bare keys are allowed to be composed of only ASCII digits, e.g. 1234, but are always interpreted as strings.
Quoted keys follow the exact same rules as either basic strings or literal strings and allow you to use a much broader set of key names. Best practice is to use bare keys except when absolutely necessary.
I am well aware that TOML is not entirely equivalent to JSON. That's an intentional choice. :)
My point was, there are examples that already clarify this detail (like the pi example, the dotted keys example etc). They show the equivalent in "JSON land" where dotted and bare keys are both represented as strings.
This specific issue of "string" being the same as string, on the LHS of a key-value pair, is not worth calling out explicitly IMO. I'd much rather have a test case in the compliance suite to make sure parsers reject a = 1\n"a" = 2.
pradyunsg
on 8 May 2020
@pradyunsg O-kay, consider me convinced!
ChristianSi
on 8 May 2020
I think the string nature of keys is clearly stated.
As a spec writer myself (xslt), I've come to learn that specs need to be very explicit. That keys are strings is implied, which is not good (the quote you give is specific about non-quoted integers only, and specifically says "bare keys", suggesting there's a difference in interpretation between the two kinds, which isn't true).
I'd argue to simplify the definition, instead of complicating it. For instance, all becomes clear by making the first line something like:
A key is a string and may be either bare, quoted, or dotted. The quotes are not part of the key name.
Or, because we need to be language agnostic (interpretations may store a key using a different format):
A key is interpreted as a string and may be either bare, quoted, or dotted. The quotes are not part of the key name.
(or "treated" instead of "interpreted"). Either definition removes any ambiguity about how the rest of the text on keys needs to be understood.
abelbraaksma
on 9 May 2020
After v1.0.0 is released and the website is up, it may be necessary to change the README from a user-centric document to a full-on strict specification. Either that, or introduce a new document as the official spec and repurpose the README as a companion document for new users. The spec would include the ABNF as an appendix, and it would codify behaviors captured in the compliance tests that the README or website don't explicitly mention.
eksortso
on 9 May 2020
Why not do it as @abelbraaksma has suggested?
ChristianSi
on 11 May 2020
@ChristianSi In principle I fully agree with @abelbraaksma's proposed changes. I do think there must be a clean break between README the configuration manifesto and README the detailed specification. Unless we draw a line it'll never get done.
That line, though, is in the future of the TOML spec, not now. I seriously don't want v1.0.0 held up any longer. The practicality of the spec on hand, which has already gained some accolades, already beats the purity of having our very own ECMA-404.
eksortso
on 11 May 2020
Unless we draw a line it'll never get done.
@eksortso I'd suggest marking bugs as editorial, minor or major/critical in this stage, where only critical bugs would delay publishing version 1.0. Bugs like these are in the minor or editorial range, as it merely asks for clarification.
A very literal reading of the spec might reveal more bugs like these. But the spec as it is has proven to be pretty stable and quite well and unambiguously understood by many implementers. Certainly, small differences in interpretation exist, but there's nothing wrong with publishing a spec as "official" for v1.0, editing it in place a few times wrt to editorial bugs (the ones that don't change any features of the spec), as long as you document that carefully (let's say by saying something like "this document was edited in place to fix some links, and improve some wording, for details on the changes, see... ").
That way you can move on without worrying too much on getting it perfect the first time around, and/or with an empty list of bugs. As there's no such thing as a bug free spec (and you're pretty close to perfect already!).
abelbraaksma
on 13 May 2020
What's a status of this? Should I prepare a small PR clarifying things as per abelbraaksma's suggestion? Or do we just leave this as is for v1.0?
(Personally, I'm in favor of clarification. A question that has been asked in the past will surely come up again in the future.)
ChristianSi
on 2 Jun 2020
@ChristianSi, in light of time spent on this so far, it is probably quicker to just bite the bullet and put it in. Since it is a clarification and not a language change, it doesn't influence any implementation (though that argument can also be used to postpone this). For me, it's ultimately a flip of a coin at this stage (but I'd also argue to not postpone v1.0 because of editorial changes these).
abelbraaksma
on 2 Jun 2020
I'm not super convinced that this is needed still. Anyway, I'm happy to accept a single sentence change for this.
I'll add another bullet to my TODO item for "TOML spec: nuance clarifications", to think about this if/when I get to that item. :)
pradyunsg
on 2 Jun 2020
"A key is simply a string in a table that defines a name for a given value." Would this work?
eksortso
on 2 Jun 2020
@eksortso, the whole point was to make it explicit that bare, single and double quoted strings are treated equally. The phrase "simply a string" doesn't remove that ambiguity. Have a look at my proposals that make that clear: https://github.com/toml-lang/toml/issues/733#issuecomment-626171546
abelbraaksma
on 3 Jun 2020
If those proposals are not sufficient/satisfactory/clear enough, another approach is perhaps to change this:
Whitespace is ignored around key names and values
Into this:
Whitespace is ignored around key names and values; delimiting quotes are not part of either the key name or value.
(though I think my earlier proposal was better)
abelbraaksma
on 3 Jun 2020
@abelbraaksma I do not see how this will work well as a single sentence in the current README, but your text is certainly a lot better than mine.
Taking your suggestion into account here. Consider, in a new PR, making this the first paragraph of the Keys section:
A key is treated as a string and may be either bare, quoted, or dotted.
Also, let's place this in the paragraph where dotted keys are explained. I explicitly called out the surrounding quotes.
The quotes surrounding a quoted key are not part of the key name.
Nothing will be said about the distinction between basic and literal strings, and nothing will be said about multi-line strings in this context. Hope that works; it's been a rough day. What do you think?
eksortso
on 3 Jun 2020
LGTM. I think that certainly removes the ambiguity, I'd go for it!
Rough day here too, European bed time now :p.
abelbraaksma
on 3 Jun 2020
Thanks, @abelbraaksma.
So invalid tests still need to be composed, and @pradyunsg already mentioned a good one, a = 1\n"a" = 2. I'll include a = 1\n"\u0061" = 2 as another one, because that basic-string quoted key is equivalent to a. We'll offer those for compliance testing, which I'm still setting up but looking forward to running!
eksortso
on 3 Jun 2020
So invalid tests still need to be composed
@eksortso Similarly, perhaps a few tests like this (I assume, but didn't check, that some may already be present):
(granted, not 100% sure I interpreted all rules correctly, as the syntax checker doesn't make all failed lines red)
# whitespace stripped, fail duplicate keys
a = 2
a = 3
# only surrounding whitespace is stripped, fail: illegal key name or syntax error
a b = 3
# whitespace is allowed when quoted, fail duplicate key
"a b" = 3
'a b' = 3
# whitespace is allowed when quoted, but not collapsed, success
"a b" = 3
'a b' = 3
# whitespace relevant, but fail: duplicate key
"a " = 2
'a ' = 3
# whitespace relevant, and not collapsed, success
"a " = 2
"a " = 3
# whitespace can be escaped, success, different keys (whitespace is not normalized)
"a\n" = 2
"a\r" = 3
"a\t" = 3
"a\f" = 3
# whitespace relevant (success test, values are NOTE equal)
a = " to do "
b = "to do"
# values must be quoted, syntax error
a = to do
b = todo
# different quotes, fail duplicate keys
a = 2
'a' = 2
# different quotes, fail duplicate keys
'a' = 2
"a" = 2
# different quotes, fail duplicate keys
'a' = 2
"""a""" = 2
# different quotes, fail duplicate keys
'''a''' = 2
"""a""" = 2
# success test, capital not equal to small
a = 2
A = 3
# inner quotes are not stripped from value, a & b are equal, value surrounded by quotes
a = "\"quoted\""
b = """"quoted""""
# quote correction is not applied, fail syntax error
"a = "test"
'a = 'test'
"a = 'test"
'a = "test'
# quotes cannot appear in keys this way, fail syntax error
a'b = 3
a"b = 3
# escaped quotes and single quotes can appear this way, fail duplicate keys
"a'b" = 2
"a\u0027b" = 4
# literal strings, escapes are not escaped, success, since keys are valid and not equal
'a"b' = 2
'a\"b' = 4
# escapes must be compared after unescaping, fail duplicate key
a = 1
"\u0061" = 2
# escaping requires quotes, syntax error
\u0061 = 2
# empty keys are allowed, but can only appear once, fail duplicate key
"" = 2
'' = 3
# bare keys can be numerals, but are interpreted as strings, fail duplicate key
1234 = 5
"1234" = 5
# bare keys can be numerals, but are interpreted as strings, fail duplicate key
1234 = 5
'1234' = 5
# bare keys can be numerals, but are interpreted as strings, valid, different keys
1234 = 5
01234 = 5
# bare keys can be numerals, but are interpreted as strings, valid, different keys
12e3 = 4
12000 = 5
# bare keys can be numerals, but are interpreted as strings, valid, different keys, one dotted
1.2e3 = 4
1200 = 5
# bare keys can be numerals, but are interpreted as strings, success, cause one is dotted
1.2e3 = 4
"1.2e3" = 5
# bare keys can be numerals, but are interpreted as strings, fail duplicate keys
12e3 = 4
"12e3" = 5
# bare keys can be numerals, but are interpreted as strings, fail duplicate dotted keys
1.2e3 = 4
1."2e3" = 5
# bare keys can be numerals, but are interpreted as strings, fail duplicate dotted keys
1.2e3 = 4
"1".2e3 = 5
Hmm, I just checked the current text, and we say keys follow the exact same rules for "basic strings". Looking up strings show that _basic strings_ can be delimited with triplets like """ and singles like ". So I _think_ the above is allowed where I wrote """a""" = 2, but since it is all red, I am not so sure anymore. Same is true for literal strings.
Btw, one other small nitpick:
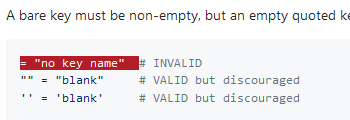
this snippet kind-of suggests that duplicate names are allowed. I know that it is just trying to say that empty keys are allowed when quoted, so I'm not sure of a better way of writing this. Therefore, I added it to the test as a fail case for duplicate keys.
abelbraaksma
on 3 Jun 2020
@abelbraaksma: The spec defines "four ways to express strings: basic, multi-line basic, literal, and multi-line literal", but only two of them are allowed as quoted keys: "basic strings or literal strings".
Hence, keys surrounded by triple quotes should indeed be rejected by a compliant parser. It's a good idea to add some negative test cases to make sure that's indeed the case.
ChristianSi
on 3 Jun 2020
@ChristianSi, it's a pity we call "multi line strings" basic. Hence my confusion. Same is true for literal. This leads to sentences like "x can take the form of a basic string" to be ambiguous.
I assume the EBNF covers this, so there's no need for extra clarification for implementers (the duplicate key rule was different as it cannot be expressed there).
Adding tests to rule this out would be good. There are a few in my list anyway.
abelbraaksma
on 3 Jun 2020
~@abelbraaksma Your whitespace normalization test case above will generate false-negatives on some platforms for \n and \r, per the spec:~
~TOML parsers should feel free to normalize newlines to whatever makes sense for their platform.~
Arguably TOML's definition of newline should be expanded to include _any_ vertical whitespace character (as is the case in some other languages), though I guess that's a topic for another discussion.
The rest LGTM (excepting the ML strings as keys, as covered later in the conversation).
 marzer
on 8 Jun 2020
marzer
on 8 Jun 2020
@marzer, but that quote from the spec deals with whitespace, that is, actual whitespace and not escapes, so that a parser can safely normalize any input file before parsing.
Here it's an escaped character, that's not the same. Surely a literal \n in a context where escaping is allowed, must translate to LF and \r to CR? It would be very surprising if that's not the case. Likewise, someone having \u000D really ought to be different than \u000A. These aren't whitespace in the sense of that spec quote, but escapes that translate to an exact Unicode character.
(if I'm wrong, then that's quite a surprising rule of toml that I hadn't expected)
abelbraaksma
on 8 Jun 2020
@abelbraaksma Oh! Of course. Duh. I read the phrase "whitespace is not normalized", remembered the line in the spec, and immediately short-circuited. Carry on, heh.
marzer
on 8 Jun 2020
Reading the spec again, I think it's quite explicit in making sure that newlines, unless escaped, can be treated however is needed for that platform. The ML strings are even given their possible counterparts as single quoted strings, showing the potential difference:
# On a Unix system, the above multi-line string will most likely be the same as:
str2 = "Roses are red\nViolets are blue"
# On a Windows system, it will most likely be equivalent to:
str3 = "Roses are red\r\nViolets are blue"
Posted at (almost) same time ;p
abelbraaksma
on 8 Jun 2020
753 should cover this.
pradyunsg
on 24 Jun 2020
Thanks @pradyunsg, for that, and for the separation of toml.md from the README. That's the clean break we were looking for.
eksortso
on 24 Jun 2020
Related issues
 uvtc
·
3Comments
uvtc
·
3Comments
 jacobconley
·
4Comments
jacobconley
·
4Comments
 paiden
·
3Comments
ChristianSi
·
3Comments
paiden
·
3Comments
ChristianSi
·
3Comments
 Silentdoer
·
4Comments
Silentdoer
·
4Comments
Most helpful comment
@eksortso I'd suggest marking bugs as editorial, minor or major/critical in this stage, where only critical bugs would delay publishing version 1.0. Bugs like these are in the minor or editorial range, as it merely asks for clarification.
A very literal reading of the spec might reveal more bugs like these. But the spec as it is has proven to be pretty stable and quite well and unambiguously understood by many implementers. Certainly, small differences in interpretation exist, but there's nothing wrong with publishing a spec as "official" for v1.0, editing it in place a few times wrt to editorial bugs (the ones that don't change any features of the spec), as long as you document that carefully (let's say by saying something like "this document was edited in place to fix some links, and improve some wording, for details on the changes, see... ").
That way you can move on without worrying too much on getting it perfect the first time around, and/or with an empty list of bugs. As there's no such thing as a bug free spec (and you're pretty close to perfect already!).