Tokio: Memory leak and performance issue in RwLock/Semaphore/BatchSemaphore
Version 0.2.20
tokio v0.2.20
|-- tokio-macros v0.2.5
Platform Windows 10 x64
WindowsBuildLabEx : 17763.1.amd64fre.rs5_release.180914-1434
WindowsCurrentVersion : 6.3
WindowsEditionId : EnterpriseN
WindowsInstallationType : Client
WindowsProductName : Windows 10 Enterprise N
WindowsVersion : 1809
Rust
rustc 1.43.0 (4fb7144ed 2020-04-20)
CPU/RAM
Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz
- Base speed: 2.90 GHz
- Sockets: 1
- Cores: 8
- Logical processors: 16
- L1 cache: 512 KB
- L2 cache: 2.0 MB
- L3 cache: 20.0 MB
RAM
- 64.0 GB DDR3 @ 1600 MHz, ECC
Description
While performing some synthetic tests I've discovered that application use enormous amount of memory (220mb+) while performing simple read/write locking.
Memory is not getting freed after all synthetic routines complete.
While some time of lurking for the culprit I've stripped down test code to the following form:
use std::sync::Arc;
#[tokio::main]
async fn main() {
// Create RwLock to synchronize r/w access to shared resource (simple u32)
let lock_ptr:Arc<tokio::sync::RwLock<u32>> = Arc::new(tokio::sync::RwLock::new(0));
/* We are spawning async tasks in few bursts:
1. 1000000 x 2 (reads + writes)
2. 100000 x 2 (reads + writes)
3. 10000 x 2 (reads + writes)
4. 1000 x 2 (reads + writes)
5. 100 x 2 (reads + writes)
*/
let mut burst_size = 1000000;
println!("About to burst {} requests.", burst_size);
let stdin = std::io::stdin();
let mut input = String::new();
// just make a pause to prepare application monitoring tool
stdin.read_line(&mut input).unwrap();
for i in 1..6 {
println!("Burst #{}, size {}", i, burst_size);
for _ in 0..burst_size {
// Spawn readers
let read_lock_ptr = lock_ptr.clone();
tokio::spawn(async move {
let read_value = read_lock_ptr.read().await;
*read_value
});
// Spawn writers
let write_lock_ptr = lock_ptr.clone();
tokio::spawn(async move {
let mut write_value = write_lock_ptr.write().await;
*write_value += 1;
*write_value
});
}
/* Wait a bit for tasks to complete.
Use monitoring tool to detect that everything is settled down:
CPU usage is 0, no I/O, no more context switches, etc.
You can use Barriers to wait for each task to complete
but I don't want to pollute this test with more entities.
*/
println!("Sending burst #{} completed. Wait a bit for tasks to complete.", i);
stdin.read_line(&mut input).unwrap();
// Decrease bust size
burst_size = burst_size / 10;
}
// Once we've completed bombarding worker threads - check memory usage
println!("Check memory usage.");
stdin.read_line(&mut input).unwrap();
}
Results
I ran this test in few configurations
- Spawning readers AND writers: memory consumption approx 220 mb, memory is not getting freed, remains constant after 1st burst, doesn't increase/decrease on subsequent bursts (see Fig. 1 and Fig. 2);
- Spawning writers ONLY: memory consumption approx 112 mb, memory is not getting freed, remains constant after 1st burst, doesn't increase/decrease on subsequent bursts;
- Spawning readers ONLY: memory increase is not significant (approx +200kb), MAY or MAY NOT be decreased on subsequent bursts;
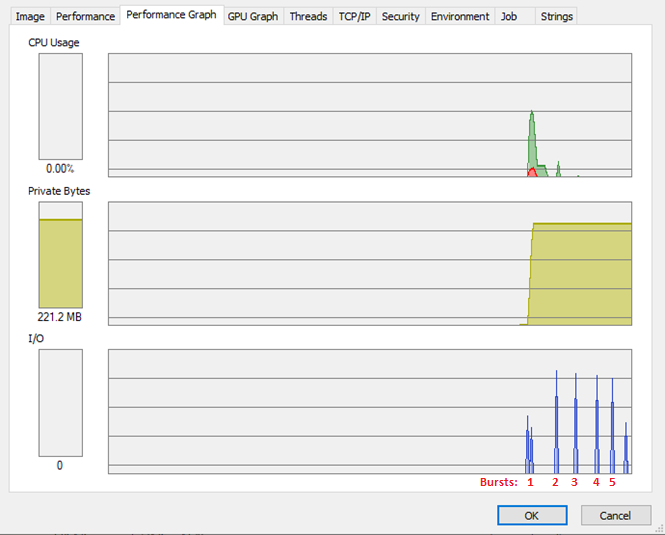
Fig. 1
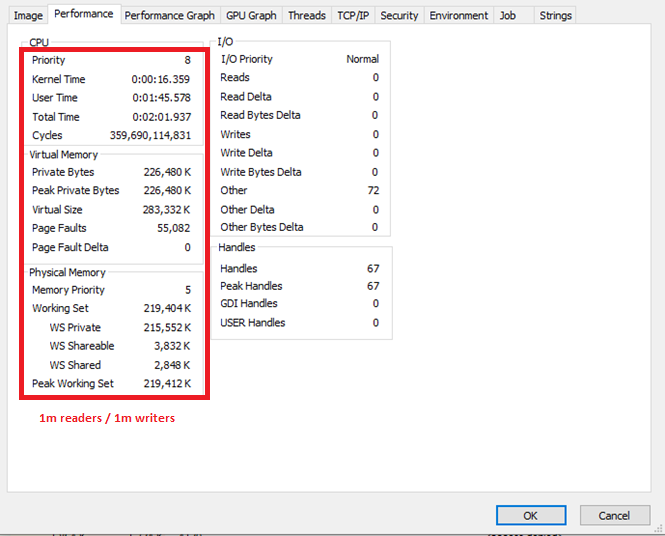
Fig. 2
Using async_std::sync::RwLock (v 1.5.0)
I've ran the same test but have used async_std::sync::RwLock implementation.
I didn't detect any suspicious memory consumption for any of tested configurations: r/ only, w/ only, r/w
Memory was always on the same level. (Fig. 3)
Also CPU consumption was 3.6 time less than with tokio::sync::RwLock:
tokio::sync::RwLock: approx 360bn cyclesasync_std::sync::RwLock: approx 100bn cycles (Fig. 4)
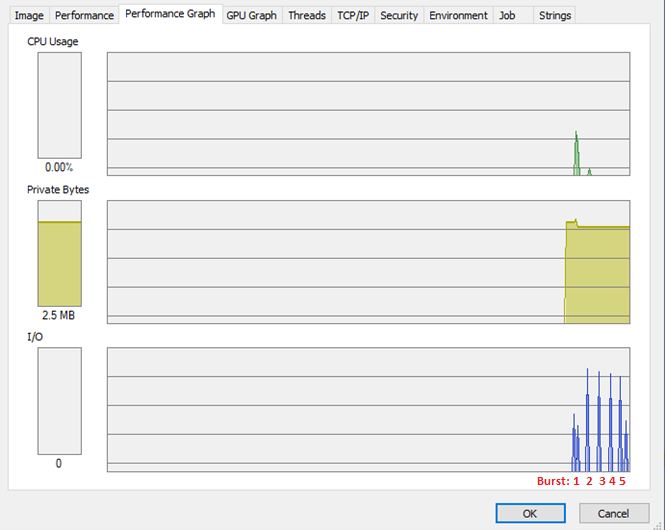
Fig. 3
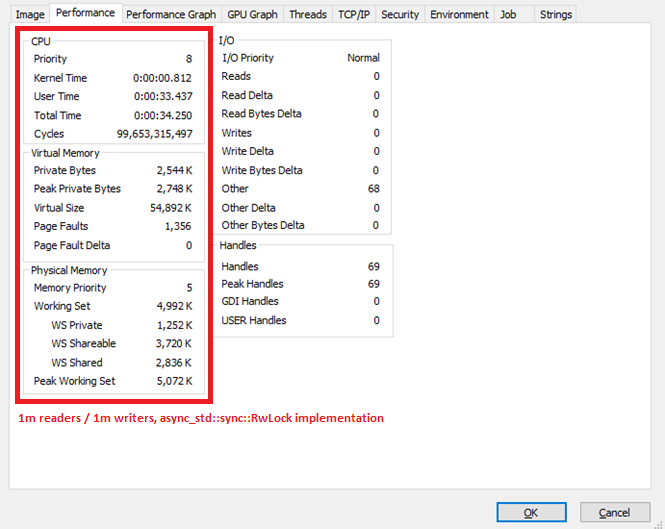
Fig. 4
Offtopic
I'm new to Rust and I've just started to evaluate different async libraries.
Purpose: development of distributed/shared cache.
Any suggestions/hints appreciated :)
 eugene-nikolsky
eugene-nikolsky
All 9 comments
After sometime of digging I've come to conclusion that problem itself is hidden somewhere in BatchSemaphore which is being used under the hood of RwLock (RwLock > Semaphore > BatchSemaphore).
But I would like to make sure that this case is not something that is expected and I'm not "fighting with windmills" right now.
The idea was simple: to see how theoretically tokio can handle such amount of requests to shared resource.
If I'm doing something completely stupid - don't hesitate to say it :) I've came from C++/Java/ObjC/JavaScript worlds, but I'm completely new to Rust
eugene-nikolsky
on 3 May 2020
Thanks for the report, this seems surprising — using the batch semaphore _shouldn't_ result in any additional allocations beyond the Arc itself, so there could be a bug in the implementation. I'll take a closer look tomorrow.
 hawkw
on 3 May 2020
hawkw
on 3 May 2020
This is most likely not a memory leak, instead the difference in behavior is due to Tokio’s mutex being fair. This means the lock is assigned on FIFO basis. Tasks that request the lock first get to run first.
By running this synthetic benchmark, you are creating a large queue of tasks. This requires memory. You are seeing memory remain associated with the process due to how allocators behave.
On the other hand, a non-fair lock would result in fewer total tasks allocated but larger latency variance.
To confirm there is no memory leak, first run the process with a tool like valgrind. Second, use an allocator like jemalloc and configure it to release back to the operating system aggressively.
JEMALLOC_SYS_WITH_MALLOC_CONF="background_thread:true,narenas:1,tcache:false,dirty_decay_ms:0,muzzy_decay_ms:0,abort_conf:true"
cargo run
 carllerche
on 3 May 2020
carllerche
on 3 May 2020
As a general point of feedback, you almost certainly do not need an async RwLock. The only reason to use one is to hold the lock across await points and in most cases doing this is not ideal.
See the mini redis example: http://github.com/tokio-rs/mini-redis
I have yet to personally hit a case that is best served with an async RwLock.
carllerche
on 3 May 2020
Hay @carllerche, thanks for the hints about valgrind and jemalloc. I'll revert with my results here.
I'll do some additional tests to check latency variation on for same simple tasks.
But what about overall performance? I mean 360 billion CPU cycles vs 100 billion. Also please take a look at user/kernel times provided in screenshots. Is that expected?
eugene-nikolsky
on 3 May 2020
The addition CPU is most likely due to fair vs not fair. In a non-fair scenario, a task is able to immediately acquire the lock if it happens to be free. In a fair scenario, the task will be forced to queue and wake up if the lock queue is not empty.
Because your test has such a tiny critical section with no async logic, the spawning / schedulers going to serialize access resulting in the lock being available to immediately claim in the non-fair mode.
Again, if you have such a small critical section and no async work with the lock held, you will be best served with parking_lot::RwLock. Using an async mutex is inappropriate for this case.
The tokio RwLock is geared towards cases where the lock is held across async yield points. In this case it becomes far less likely that the lock happens to be available and fairness is a desired trait.
carllerche
on 3 May 2020
Is it not an issue that a call to rw_lock.write() might block on readers, or is the critical section so small that it shouldn't matter?
 asonix
on 3 May 2020
asonix
on 3 May 2020
If the critical section is small the cost is rescheduling tasks will be much higher than the small amount of pausing. Keep in mind that all implementations of async RwLock contains some amount of thread locking anyway.
carllerche
on 3 May 2020
It appears like this question has been resolved, so I am closing. Feel free to reopen if I misunderstood anything.
 Darksonn
on 16 May 2020
Darksonn
on 16 May 2020
Related issues
 sdroege
·
4Comments
sdroege
·
4Comments
 abonander
·
5Comments
abonander
·
5Comments
 zhuxiujia
·
3Comments
zhuxiujia
·
3Comments
 izolyomi
·
5Comments
izolyomi
·
5Comments
 polomsky
·
4Comments
polomsky
·
4Comments
Most helpful comment
If the critical section is small the cost is rescheduling tasks will be much higher than the small amount of pausing. Keep in mind that all implementations of async RwLock contains some amount of thread locking anyway.