Three.js: Proposal: Making flattened math classes that operate directly on views the default
Description of the problem
Clara.io has been struggling with the non-memory efficient Three.JS math classes for four years now. Basically Three.JS math classes use object members to represent their data, e.g.:
THREE.Vector3 = function( x, y, z ) {
this.x = x;
this.y = y;
this.z = z;
}
This pattern above leads to a lot of inefficiencies. It is an object and it is an editable object. It has a large overhead per object in terms of allocation time and extra memory usage because it is an editable object. There are also costs to copy from a BufferGeometry array to a Vector3 and vice versa. Also there are costs to flatten these arrays when using them as uniforms.
As we are looking to speed up Clara.io, I think we need to move away from object-based math classes and instead make the hard switch to math classes that are based around internal arrays. This would be the primary representation of the Three.JS math types, although we could still emulate the object-based design we have by building on top of these. Thus I want to see this design being the primary design for all of Three.JS math:
Vector3.set( array, x, y, z ) {
array[0]=x;
array[1]=y;
array[2]=z;
}
Vector3.add( target, lhs, rhs ) {
target[0]=lhs[0]+rhs[0];
target[1]=lhs[1]+rhs[1]
target[2]=lhs[2]+rhs[2]
}
I think the above pattern is the only way that Clara.io can achieve the speed it needs.
Important point: I was talking to one of the JavaScript spec designers and he said that we should use large arraybuffer allocations and then try to use views for each individual math element in a large array (e.g. var usernameView = new Float32Array(buffer, 4, 16) ). He said that views were incredibly cheap as now you do not even pay an array allocation cost per element.
I think we could keep around the Vector3 object (as opposed to the new functional interface), but it could be built by creating a BufferArray (or alternatively initialized by a passed in view) and remembering it, and then using all of the pure array buffer functions I am advocating as the primary interface. It could have accessors for x, y, and z that map onto the BufferArray. This would give us backwards compatibility.
But going forward it would likely be best to nearly always use the versions of the math classes that can operate directly on a preallocated array. This design would be ultra fast -- no allocations for the most part, and ultra cheap and easy conversions to uniforms and BufferGeometry.attribute
I think this is necessary for Clara.io to move to the next level and I think Three.JS wants to get there as well. We, ThreeJS, have been moving to this solution slowly but we've never made the full break to transform the primary math-objects. I think it is time to do this.
/ping @WestLangley
Three.js version
- [x] Dev
- [ ] r75
[ ] ...
Browser
[x] All of them
- [ ] Chrome
- [ ] Firefox
[ ] Internet Explorer
OS
[x] All of them
- [ ] Windows
- [ ] Linux
- [ ] Android
- [ ] IOS
Hardware Requirements (graphics card, VR Device, ...)
 bhouston
bhouston
All 37 comments
How about doing something along the lines of this?
THREE.Vector3 = function () {
this.array = THREE.Memory.getFloat32( 3 );
};
THREE.Vector3.prototype = {
get x () {
return this.array[ 0 ];
},
set x ( value ) {
this.array[ 0 ] = value;
},
...
};
THREE.Memory = {
currentArray: 0,
currentOffset: 0,
arrays: [
new Float32Array( 8000 ) // 8Mb blocks?
],
getFloat32: function ( length ) {
var array = new Float32Array( this.arrays[ this.curentArray ], this.currentOffset, length );
this.currentOffset += length;
if ( this.currentOffset > 8000 ) {
this.currentArray++; // Also create new memory block
this.currentOffset = 0;
}
return array;
}
};
Of course, this means that we'll have to do memory management/garbage collection ourselves...
 mrdoob
on 18 Apr 2016
mrdoob
on 18 Apr 2016
Coincidentally just expressed a similar thought that might work very nicely with this suggestion https://github.com/mrdoob/three.js/pull/8165#issuecomment-211360219 , would also need an offset if we wanted to avoid the garbage from using TypedArray.subarray a lot.
 tschw
on 18 Apr 2016
tschw
on 18 Apr 2016
I like the idea of a memory manager, but how do you make it not leak?
I was thinking that the default would be something like this:
// use auto-GC'ed memory, this will not leak :)
THREE.Vector3 = function( buffer, x, y, z ) {
this.array = buffer || new Float32Array( 3 );
if( x !== undefined ) {
this.x = x;
this.y = y;
this.z = z;
}
};
// use memory manager
THREE.Vector3.fromMemory( x, y, z ) {
return new THREE.Vector3( memory.getFloat32( 3 ), x, y, z );
}
// use BufferGeometry attribute
THREE.Vector3.fromArray( array, offset, , x, y, z ) {
return new THREE.Vector3( new Float32Array( array, offset, 3 ), x, y, z );
}
//And then you could easily do:
var myVector1 = THREE.Vector3();
var myVector2 = THREE.Vector3.fromMemory();
// this is my primary use case
var myVector3 = THREE.Vector3.fromArray( geometry.attribute.vertices, 10 );
The reason is I want to usually create THREE.Vector3() from large flat arrays, like the attributes in the BufferGeometry.
The other reason is that I want to do fast copies of arrays of Vector3 data, which if it is just a flat continuous array, is near instant. The memory manager would not allow for contiunous arrays of data, so I need to have the option to not use it.
Also if we make the Vector3s and other math elements from SharedArrayBuffers, we can do multi-threaded coding very easily: pass the same buffer to a bunch of works with unique offsets per thread and that each can work on a different part of the SharedArrayBuffer in generating their results. For Clara.io, and ThreeJS, this is the holy grail of performance. :)
The above constructors would allow for that -- I just do not like the if tests in the constructor to differentiate between the different use cases.
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/SharedArrayBuffer
bhouston
on 18 Apr 2016
THREE.Vector = function( x, y, z, optionalAllocator ) {
var allocator = optionalAllocator || THREE.Allocator.TrivialAllocator;
// the TrivialAllocator would simply create arrays and forget them, so they won't leak
allocator.allocate( this, 3 ); // sets this.buffer, this.offset
// [ ... set x y z if present ]
};
just as a thought...
tschw
on 18 Apr 2016
THREE.Vector = function( x, y, z, optionalAllocator ) {
How do you create an vector without setting x, y, z ? I guess this:
var myVector3 = new THREE.Vector( undefined, undefined, undefined, buffer );
Function calls are also slow. I really want to separate allocation from initialization:
THREE.Vector3 = function( buffer ) {
this.buffer = buffer || THREE.Allocator.TrivialAllocator.float32( 3 );
}
var myVector = new THREE.Vector3( buffer ).set( x, y, z );
Separating out allocation from initialization would be clear and maximally efficient.
bhouston
on 18 Apr 2016
@bhouston
How do you create an vector without setting x, y, z ?
Could have static Vector.allocate( allocator ) for that.
Function calls are also slow. I really want to separate allocation from initialization
var myVector = new THREE.Vector3( buffer ).set( x, y, z );
In the longer term I think that'd be even better. Totally love that API.
It's a rather drastic change, however, and maybe we should take a transitional step so existing code keeps working, making it warn all over the place, allowing easy porting.
@tschw
allocator.allocate( this, 3 ); // sets this.buffer, this.offset
or might want to go
this.buffer = allocator.allocate( size );
this.offset = allocator.previousOffset;
// larger property first, guessing this may yield better memory alignment
allocator.allocate( this, 3 ); // sets this.buffer, this.offset
Allocator needs to know the type so it can create the proper view type, Float32, Int, etc.
bhouston
on 18 Apr 2016
@bhouston
Allocator needs to know the type so it can create the proper view type, Float32, Int, etc.
Arguably might want to be a property of the allocator. Was just assuming Float32Array for now...
tschw
on 18 Apr 2016
It's a rather drastic change, however, and maybe we should take a transitional step so existing code keeps working, making it warn all over the place, allowing easy porting.
I agree. I think I can whip up a less than optimal in terms of speed solution that is nearly perfectly backwards compatible. And then a few versions from now we can remove the backwards compatible warnings and get maximum speed.
bhouston
on 18 Apr 2016
I'll start on somethign today then. I am also look at @toji's great library as well: https://github.com/toji/gl-matrix I will be building at the base a functional interface like gl-matrix and adding object-oriented stuff on top because we are Clara.io are interested in the raw speed that comes with a functional interface -- the allocation of Vector3 objects is costly in-and-of itself even if we do use Float32Buffers internally.
bhouston
on 18 Apr 2016
@bhouston
I agree. I think I can whip up a less than optimal in terms of speed solution that is nearly perfectly backwards compatible. And then a few versions from now we can remove the backwards compatible warnings and get maximum speed.
Yes please!
var myVector = new THREE.Vector3( buffer );
That would also allow to map whatever is in the buffer (e.g. the a vertex position within a buffered geometry).
Important point: I was talking to one of the JavaScript spec designers and he said that we should use large arraybuffer allocations and then try to use views for each individual math element in a large array (e.g. var usernameView = new Float32Array(buffer, 4, 16) ). He said that views were incredibly cheap as now you do not even pay an array allocation cost per element.
Using views would still mean many small objects need to be allocated - more than now, actually... This might be OK, but is something to consider. Views are immutable and cannot be remapped.
I am also look at @toji's great library as well: https://github.com/toji/gl-matrix
Oh yes, recently found that one. Haven't yet gotten around to actually look into it. So it's a procedural thing? Nice!
I once been toying with the (admittedly crazy) idea of writing a class that holds a buffer and implements the vector math stuff with an assembly-like API where every operand is just an offset:
var ctx = new MathAsm( new Float32Array( 6 ) );
var a = ctx.alloc( 3 ),
b = ctx.alloc( 3 );
ctx.assign( a, 1, 2, 3 );
ctx.assign( b, 3, 2, 1 );
var s = ctx.dot( a, b ); // = 10
Views are immutable and cannot be remapped.
I was told that views are incredibly cheap, in comparison to the strategy used in gl-matrix where it actually creates new ArrayBuffers per element. I do not see a reason to need remapping, as you can just create a new view from the underlying ArrayBuffer.
var ctx = new MathAsm( new Float32Array( 6 ) );
var a = ctx.alloc( 3 ),
b = ctx.alloc( 3 );
ctx.assign( a, 1, 2, 3 );
ctx.assign( b, 3, 2, 1 );
var s = ctx.dot( a, b ); // = 10
Very similar except I'd use types to give name spaces to the various functions, like add, slerp, cross, etc:
var result = Vector3.dot( a.array, b.array );
// or
var result = new THREE.Vector3(); // default allocator
Vector3.cross( result.array, a.array, b.array );
// this will also work as it did before:
a.cross( b, result );
I think that you stuff could easily map onto the functional Math classes if we switch to that as our core implementation. :)
NOTE: I updated the example code above after the fact because I forgot to use buffer directly in the functional interface.
bhouston
on 18 Apr 2016
// use auto-GC'ed memory, this will not leak :) THREE.Vector3 = function( buffer, x, y, z ) { this.array = buffer || new Float32Array( 3 ); if( x !== undefined ) { this.x = x; this.y = y; this.z = z; } };
We tried this many years ago. new Float32Array() slowed down vector initialisation to the point that we decided to revert. Maybe this has been improved since then.
mrdoob
on 18 Apr 2016
We tried this many years ago. new Float32Array() slowed down vector initialisation to the point that we decided to revert. Maybe this has been improved since then.
I guess my thoughts are that they can use any approach, memory manager (which in a simple version may leak), Float32Array that is auto-GCs but is slower than the memory manager, or they can manage allocations themselves with pre-allocated large buffers.
I think that nearly all cases one should manage the allocations themselves because then you can just set one array and then place it in BufferGeometry.attributes.vertices or attributes.normals. Because to set those directly without any copies you need to have a contiguous buffer so it can upload it to the GPU.
It should be a simple matter to change the default allocator between THREE.Memory to Float32Array buffer to see what gets the best performance -- my hope is that THREE math objects that are not tied to large flat contiguous arrays are rare and it may not matter than much, especially if people use the idea of closures to reuse intermediate values like we do in many parts of the math library. I'll ensure that this is very easy to switch between because I can not predict which is faster.
bhouston
on 18 Apr 2016
It should be a simple matter to change the default allocator between THREE.Memory to Float32Array buffer to see what gets the best performance
I suspect 90% of three.js users don't know what a Float32Array really is...
Have you considered re-defining Vector3 at load time for Clara?
mrdoob
on 18 Apr 2016
I suspect 90% of three.js users don't know what a Float32Array really is...
Have you considered re-defining Vector3 at load time for Clara?
I can ensure it ThreeJS uses THREE.Memory by default and that you can configure it on a per project basis. :) I'll make a PR in the next while that converts Vector3 across and we can see how it performs and how the code looks.
Quick survey:
- PlayCanvas, OnShape, Trubulenze use Float32Array-based math classes. I think all three are using code derived from gl-matrix.
- Babylon.js uses an approach that is nearly identical to Three.JS's current approach.
- Sketchfab uses Vec3 object with a non-ArrayBuffer array in it.
I know from talking with the guys at OnShape.com, they have significantly less scalability issues (memory/speed) than Clara.io precisely because of this difference.
bhouston
on 18 Apr 2016
I think there might be a way to automate it, because 99% of the users will either not care about bound memory or able to call vector.dispose() or both:
THREE.ArrayAllocator = function( typedArrayCtor, arraySize, nArraysPerBuffer ) {
var blockSize = arraySize * ( nArraysPerBuffer || 128 ),
currentBuffer = new typedArrayCtor( blockSize ),
freeOffset = 0,
freeArrayViews = [];
this.allocate = function() {
if ( freeArrayViews.length !== 0 ) return freeArrayViews.pop();
var start = freeOffset;
freeOffset += arraySize;
if ( start === blockSize ) {
currentBuffer = new typedArrayCtor( blockSize );
start = 0;
freeOffset = arraySize;
}
return currentBuffer.subarray( start, freeOffset );
};
this.free = function( array ) { freeArrayViews.push( array ); }
};
Then for e.g. THREE.Vector3:
Vector3.Allocator = new THREE.ArrayAllocator( Float32Array, 3, 1024 );
Vector3.prototype.dispose = function() { Vector3.Allocator.free( this ); }
Note that when this thing is used in a streaming scenario, where many vectors are used and forgotten, it will at most bogart the memory of one buffer.
Could add an additional method that enforces a new buffer to be used to make this use case leak-free without having to .dispose() all the vectors individually.
tschw
on 18 Apr 2016
@tschw I like that. I'll let you and @mrdoob handle the allocator. :) I'll start with this or the one @mrdoob posted earlier - which ever is easiest to get working. You guys can then refine it. My primary concern is simplicity of the interface, speed and backwards compatibility. :)
bhouston
on 18 Apr 2016
Extending on this thought:
Could add an additional method that enforces a new buffer to be used to make this use case leak-free without having to .dispose() all the vectors individually.
Could even throw out the free list logic, free and dispose altogether:
THREE.ArrayAllocator = function( typedArrayCtor, arraySize, nArraysPerBuffer ) {
var blockSize = arraySize * ( nArraysPerBuffer || 128 ),
currentBuffer = new typedArrayCtor( blockSize ),
freeOffset = 0;
this.allocate = function() {
var start = freeOffset;
freeOffset += arraySize;
if ( start === blockSize ) {
currentBuffer = new typedArrayCtor( blockSize );
start = 0;
freeOffset = arraySize;
}
return currentBuffer.subarray( start, freeOffset );
};
this.segmentBoundary = function() {
currentBuffer = new typedArrayCtor( blockSize );
freeOffset = 0;
};
};
That'd be even simpler. So when you wanted to go streaming you'd do:
this.somethingMorePermanent = new THREE.Vector3();
THREE.Vector3.Allocator.segmentBoundary();
// [ ... mess with lots of temporary vectors ]
THREE.Vector3.Allocator.segmentBoundary();
A more sophisticated API could look like
this.somethingMorePermanent = new THREE.Vector3();
var state = THREE.Vector3.Allocator.resetState(); // sets a new buffer
// [ ... mess with lots of temporary vectors ]
THREE.Vector3.Allocator.resetState( state ); // back to the buffer for permanent stuff
to avoid partly unused buffers.
tschw
on 18 Apr 2016
I'm also adding a version if you don't mind.
THREE.Vector3Array = function(buffer,offset) {
this.array = new Float32Array(buffer,offset,3);
}
THREE.vector3Array.prototype = new THREE.Vector()
and we edit vector3 as following:
THREE.Vector3 = function() {
this.array = {"0":0,"1":0,"2":0};
}
THREE.Vector3.prototype = {
get x() { return this.array[0]},
set x(v) { this.array[0] = v},
get y() { return this.array[1]},
set y(y) { this.array[1] = y},
get z() { return this.array[2]},
set z(z) { this.array[2] = z},
// after this all methods that are defined in Vector3 now updates to use array[0] for x,array[1] for y and array[2] for z.
...
}
This way we could reduce the size of memory usage, I think.
 gero3
on 18 Apr 2016
gero3
on 18 Apr 2016
@gero3 I think that by introducing functions for accessing each variable we will need to heavily rely on the compiler to do the right optimization. I am concerned about that. I also understand that JavaScript by default uses Double (foat64) but it can optimize down to using Float32 if you stick close to the array buffer level in your accesses and sets of the data. I am concerned that if we do not stick close to the Float32Array we may introduce a lot of de-optimizations in the name of convenience, and likely inconsistently across browsers too.
bhouston
on 18 Apr 2016
@bhouston
I like that. I'll let you and @mrdoob handle the allocator. :)
My second vesion is essentially a @mrdoob allocator...
I'll start with this or the one @mrdoob posted earlier - which ever is easiest to get working.
That should be fine. I think I like the idea of having it global. However, in case there's anything less than 32-bit must consider alignment, else may get miserable performance reading 32-bit values at addresses which are not a multiple of 4 (bytes, that is) after using smaller arrays. Higher alignment will probably be better, especially thinking SIMD.
Just remove the arrays stuff so it doesn't bogart the buffers. Something like:
THREE.MemoryBlockSize = 32768; // 32K as a wild guess
THREE.Memory = {
currentBuffer: new ArrayBuffer( THREE.MemoryBlockSize ),
currentOffset: 0,
getFloat32: function ( length ) {
var buffer = this.currentBuffer,
start = this.currentOffset,
bytes = length * Float32Array.BYTES_PER_ELEMENT,
newOffset = start + bytes;
if ( newOffset > buffer.byteLength ) {
// insufficient free memory in buffer
buffer = new ArrayBuffer( THREE.MemoryBlockSize );
start = 0;
newOffset = bytes;
this.currentBuffer = buffer;
}
this.currentOffset = newOffset;
return new Float32Array( buffer, start, length );
}
};
Just lurking, since @bhouston invoked my name. :)
I've been tempted to try using a similar allocator with glMatrix in the past, but I've always been a bit concerned about leaving releasing the objects in the hands of the library's users. What have you found to be an effective way to manage object lifetimes?
 toji
on 18 Apr 2016
toji
on 18 Apr 2016
@toji, I do not think we have a proven effective approach yet, just ideas. :) But I think we can prove them out pretty quickly. I think gl-matrix and ThreeJS share the same license terms, so sharing is probably easy. :)
bhouston
on 18 Apr 2016
@toji wrote:
What have you found to be an effective way to manage object lifetimes?
@bhouston wrote:
I do not think we have a proven effective approach yet, just ideas.
These threads grow long real quickly... Posts on that matter: https://github.com/mrdoob/three.js/issues/8661#issuecomment-211337586, https://github.com/mrdoob/three.js/issues/8661#issuecomment-211419176, https://github.com/mrdoob/three.js/issues/8661#issuecomment-211419176
tschw
on 18 Apr 2016
Oops! Just need to read back further it seems. Thanks for the reference!
For the record, one pattern I've experimented with in the past is tying temporary allocations to the call stack, like so:
function allocateVec3(callback) {
var vector = somePoolAllocator.getVec3();
callback(vector);
somePoolAllocator.dispose(vector);
}
You could probably do something more efficent by having it provide n vectors instead of one. This pattern can be nice in some cases as it guarantees object lifetime, but it's hard to use generally and I worry that it makes it easy to accidentally create _more_ garbage if the closure is handled badly.
toji
on 18 Apr 2016
Very quick prototype of the design I was thinking of. Mostly bug free, but no allocator yet (and yes Float32Array seems slow to allocate):
https://github.com/mrdoob/three.js/pull/8667
Feel free to modify yourself. :) I'll put in an allocate this afternoon.
bhouston
on 18 Apr 2016
The prototype PR has been updated with the @tschw's last allocator. It addressed the performance problem nicely.
bhouston
on 18 Apr 2016
@toji
Similar to
function allocateVec3(callback) {
var vector = somePoolAllocator.getVec3();
callback(vector);
somePoolAllocator.dispose(vector);
}
might go
Allocator.prototype.temporaryScope = function ( that, func ) {
var allocatorState = this.forceNewBlockAndReturnPreviousState();
func.call( that );
this.restoreState( allocatorState );
}
and allow any number of allocations performed via that allocator within the callback. I'm not so sure about that encapsulation, though.
tschw
on 18 Apr 2016
I've completed what is both a fast, and minimal change that achieves my goals of being able to use the "attach" workflow. It turns out the best solution was to use @mrdoob's & @tschw's allocator along with @gero3's core idea for integrating the arrays in a minimally disruptive fashion. Turns out one has to only allocate large Float32Arrays and use an offset per vector to access them for speed -- allocation of views or buffers per vector was just too slow.
The completed PR is here: #8672
bhouston
on 19 Apr 2016
@bhouston
I am dissappointed with this whole approach, it is not faster in any place.
well, tbh it sounded as if you were to rewrite native GC code in JS
 makc
on 23 Apr 2016
makc
on 23 Apr 2016
well, tbh it sounded as if you were to rewrite native GC code in JS
haha similar thoughts too, although that approach is similar to what emscripten does, which seems to be work reasonably well (having to allocate memory upfront) and would probably map nicely towards asm.js/webasm.
then again, I would imagine classes like Vector3 to be optimized by the javascript engines...
 zz85
on 11 Jun 2016
zz85
on 11 Jun 2016
randomly found this thread.
Just FYI, AFAICT Float32Array is slow. I'm only guessing it's because there is a required conversion to/from 64bit doubles. If you do this
const a = new Float32Array([123, 456, 0]);
and then do this
a[2] = a[0] * a[1];
The JavaScript engine is required to do this
a[2] = float((double)a[0] * (double)a[1]);
And those conversions to and from float to double add to the time
Here's a test
https://jsperf.com/float32-vs-float64-vs-nativearray
And here's my results
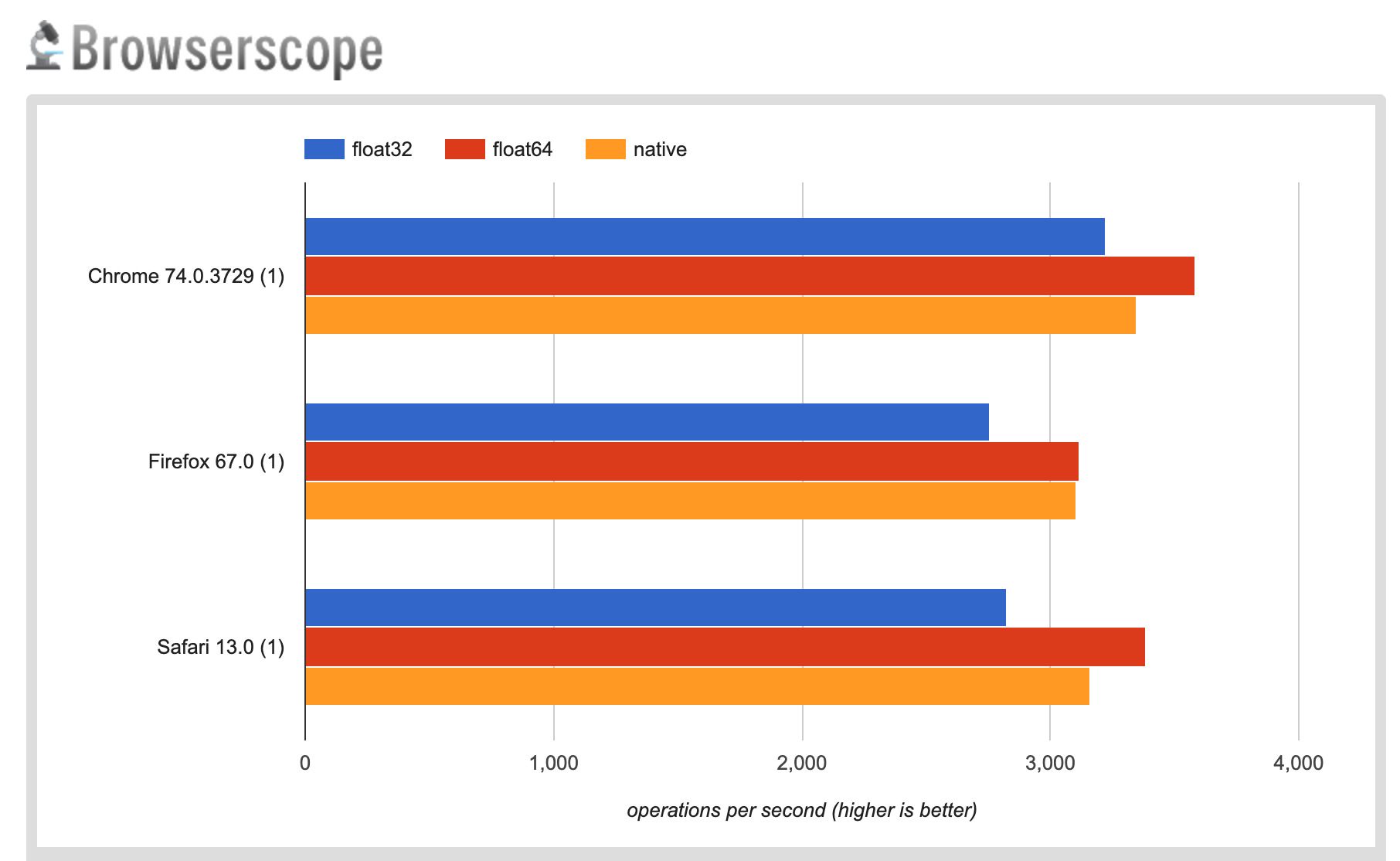
A long time ago I forked some matrix library tests
http://greggman.github.io/webgl-matrix-benchmarks/matrix_benchmark.html
THREE.js math is up to 10x slower than others though the benchmarks might suck
Note that each browser gets different results. On my machine TDLMath (which uses native arrays) is fastest in Chrome. glMatrix when configured to use native arrays is fastest in Firefox and when configured to use Float64Arrays is fastest in SafariTP.
Unfortunately I've noticed some worrying results in that in trying to figure out why particular results are the way they are
Here's just a few numbers from Chrome. The numbers are in millions of operations per second so higher is better.
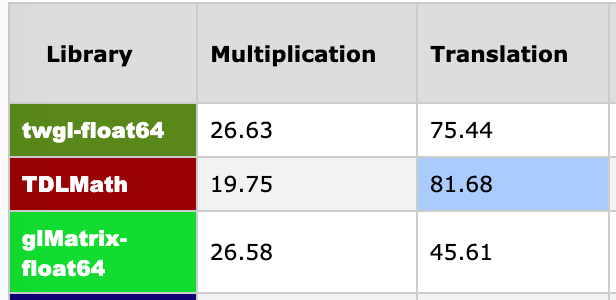
Here's Firefox

In the Chrome one you see the numbers are about the same for glMatrix-float64 and twgl-float64 for multiplication which is what I expect. In Firefox they are vastly different. I've gone in and pasted the code from one library into the other and still seen the same issue. Vastly different results, in both browsers. In other words it's possible something about the environment the function is declared in matters. I've even tried pulling out references to the functions so for example instead of mat4.multiply(dst, a, b) before the test loop do const mul = mat4.multiply and in the loop just use mul(dst, a, b) and still even though the code is 100% the same I see crazy different results. The only difference being where/how the function is exposed. It could also mean the benchmark sucks.
In any case, for this issue in particular the short of it is, assuming vector and matrix math speed is actually a bottleneck then three.js has a slow math library.
 greggman
on 13 Jun 2019
greggman
on 13 Jun 2019
My preference would be to coerce things read from a Float32Array to be floats during the mathematical operations rather than double. I think it was intended to be possible via ASM.js but I am unsure if it actually works in practice: https://github.com/zbjornson/human-asmjs#1-types
That would be preferred. The reason is Float32 everything would be faster than Float64 everything because both the mathematical operations are faster but also it will have more cache hits because it takes half the memory.
All major game engines are Float32 everywhere I believe.
bhouston
on 13 Jun 2019
But yeah, you are right that twgl-float64 seems to be the fastest. I like it actually - it is array based and functional:
https://github.com/greggman/twgl.js/blob/master/src/v3.js
I would advocate adopting it but it is also a pain to change all of Three.JS.
bhouston
on 13 Jun 2019
Yes, all major game engines are float32 everywhere but I don't think it's possible for Float32Array to work as you want it to in JavaScript. Yes, asm.js did that but I believe it requires that every operation be separted out. In other words this code can not stay float32
const f = new Float32Array([1,2,3,4,5]);
f[0] = f[1] / f[2] * f[3] / f[4];
because by the rules of JavaScript that would come up with a different answer with double vs float and the spec says math uses doubles.
asm.js got around that by adding fround but it has to be used such that the results would stay they same even if they are using doubles. In other words it's not enough to do this
f[0] = fround(f[1] / f[2] * f[3] / f[4]);
it has to be this
f[0] = fround(fround(f[1] / f[2]) * f[3]) / f[4];
If you go look at the number of frounds needed to get a matrix multiple to stay in float32 it's a bunch but worse there is no guarantee the JavaScript engine will actually optimize the code. In fact since it's executing outside of an asm.js context it's almost for sure not going to optimize the code (keep it float32 the entire way). Asm.js doesn't use Math.fround it uses some fake fround so make sure that someone can't do Math.fround = customImpl
It is surprising to me that native arrays would faster than Float64Array but I assume that's just the JS engines haven't fully optimized that yet.
As for switching, you could add getters and setters for x, y, z etc to an array based vector3 class
class Vector3 {
constructor(x, y, z) {
this.v = [x, y, z];
}
get x() { return this.v[0]; } set x(v) { this.v[0] = v; }
get y() { return this.v[1]; } set y(v) { this.v[1] = v; }
get z() { return this.v[2]; } set z(v) { this.v[2] = v; }
}
It would be interesting to see how much slower it gets.
greggman
on 17 Jun 2019
Related issues
 Horray
·
3Comments
Horray
·
3Comments
 alexprut
·
3Comments
alexprut
·
3Comments
 fuzihaofzh
·
3Comments
fuzihaofzh
·
3Comments
 jack-jun
·
3Comments
jack-jun
·
3Comments
 ghost
·
3Comments
ghost
·
3Comments