Test-infra: go.k8s.io/triage cluster data is much larger than usual
What happened:
I visited go.k8s.io/triage and it said it was downloading 100's of MB of data
What you expected to happen:
I'm used to seeing it claim to download ~20-40MB of data (e.g. https://storage.googleapis.com/k8s-gubernator/triage/index.html?date=2020-08-23)
Please provide links to example occurrences, if any:
- https://storage.googleapis.com/k8s-gubernator/triage/index.html?date=2020-08-23 - downloaded 20.71 MB data (known good example)
- https://storage.googleapis.com/k8s-gubernator/triage/index.html?date=2020-08-25 - downloaded 501.23 MB data
- https://storage.googleapis.com/k8s-gubernator/triage/index.html?date=2020-08-30 - downloaded 249.99 MB data
Anything else we need to know?:
We had a brief outage from 2020-08-23 - 2020-08-25 for unrelated reasons (ref: https://github.com/kubernetes/test-infra/issues/17625#issuecomment-681108961), so we're not quite sure what happened within that window.
Suspect this is pathological data / clustering and not the go rewrite, but don't know for sure.
$ gsutil ls -lh gs://k8s-gubernator/triage/history | tail -n20
5.22 MiB 2020-08-10T23:31:25Z gs://k8s-gubernator/triage/history/20200810.json
4.94 MiB 2020-08-11T23:33:57Z gs://k8s-gubernator/triage/history/20200811.json
4.91 MiB 2020-08-12T23:42:54Z gs://k8s-gubernator/triage/history/20200812.json
4.89 MiB 2020-08-14T00:00:06Z gs://k8s-gubernator/triage/history/20200813.json
4.44 MiB 2020-08-14T19:59:20Z gs://k8s-gubernator/triage/history/20200814.json
4.39 MiB 2020-08-17T23:51:08Z gs://k8s-gubernator/triage/history/20200817.json
4.36 MiB 2020-08-18T23:39:30Z gs://k8s-gubernator/triage/history/20200818.json
4.23 MiB 2020-08-19T23:41:14Z gs://k8s-gubernator/triage/history/20200819.json
4.2 MiB 2020-08-20T23:57:37Z gs://k8s-gubernator/triage/history/20200820.json
4.15 MiB 2020-08-21T23:56:54Z gs://k8s-gubernator/triage/history/20200821.json
4.04 MiB 2020-08-22T23:57:30Z gs://k8s-gubernator/triage/history/20200822.json
3.85 MiB 2020-08-23T18:39:04Z gs://k8s-gubernator/triage/history/20200823.json
32.41 MiB 2020-08-25T22:43:55Z gs://k8s-gubernator/triage/history/20200825.json
35.09 MiB 2020-08-26T19:53:01Z gs://k8s-gubernator/triage/history/20200826.json
14.75 MiB 2020-08-27T22:51:06Z gs://k8s-gubernator/triage/history/20200827.json
27.63 MiB 2020-08-28T23:06:57Z gs://k8s-gubernator/triage/history/20200828.json
25.94 MiB 2020-08-29T22:50:59Z gs://k8s-gubernator/triage/history/20200829.json
18.95 MiB 2020-08-30T23:20:06Z gs://k8s-gubernator/triage/history/20200830.json
13.17 MiB 2020-08-31T23:36:15Z gs://k8s-gubernator/triage/history/20200831.json
/area triage
 spiffxp
spiffxp
All 10 comments
slack thread where we noticed this: https://kubernetes.slack.com/archives/C09QZ4DQB/p1598551413082100?thread_ts=1598472722.065900&cid=C09QZ4DQB
spiffxp
on 1 Sep 2020
but… how will we triage the issue…
/me wanders away, lost
 liggitt
on 2 Sep 2020
liggitt
on 2 Sep 2020
/priority critical-urgent
Well, now it's frozen at Loading... parsing 0MB. after climbing to somewhere above 520 MB
spiffxp
on 2 Sep 2020
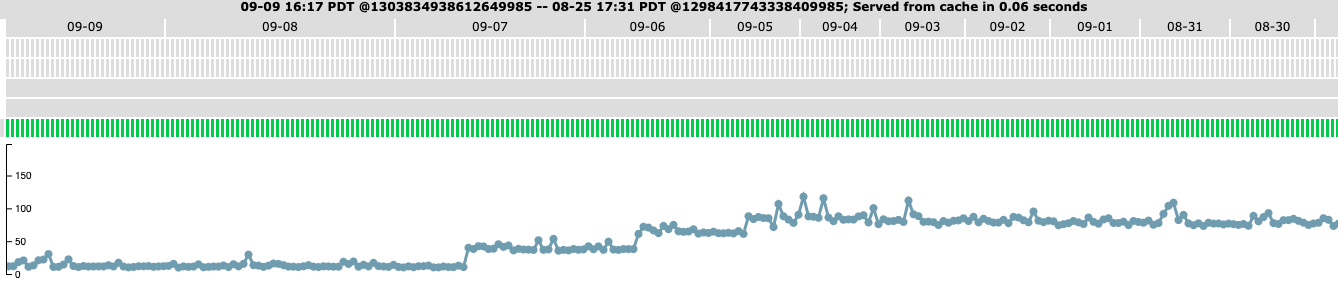
So, as of now, jobs are taking ~11 minutes and producing ~50MB of data, which is normal.
Something happened at midnight between 9/07 and 9/08, with runtimes dropping from ~40 minutes to the current ~11 and output size dropping from ~250MB to the current ~50. A similar drop happened between 9/06 and 9/07, and between 9/05 and 9/06.
Since Triage runs over data from the past 2 weeks starting from midnight, I would guess this was some issue with the input data. I'd note that global clustering time did not scale up proportionally with local clustering time, meaning that it may be more susceptible to bad inputs, whatever they may be.
 michaelkolber
on 9 Sep 2020
michaelkolber
on 9 Sep 2020
/remove-priority critical-urgent
/priority important-soon
We should figure out what the culprit is and filter for it, but I'll drop priority since the tool is more usable now
spiffxp
on 10 Sep 2020
The drops for posterity
spiffxp
on 10 Sep 2020
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 9 Dec 2020
fejta-bot
on 9 Dec 2020
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 8 Jan 2021
/close
It hasn't climbed to similar levels since august, going to defer investigating.
spiffxp
on 8 Jan 2021
@spiffxp: Closing this issue.
In response to this:
/close
It hasn't climbed to similar levels since august, going to defer investigating.
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 8 Jan 2021
k8s-ci-robot
on 8 Jan 2021
Related issues
 zacharysarah
·
3Comments
zacharysarah
·
3Comments
 BenTheElder
·
3Comments
BenTheElder
·
4Comments
BenTheElder
·
3Comments
BenTheElder
·
4Comments
 xiangpengzhao
·
3Comments
xiangpengzhao
·
3Comments
 fen4o
·
4Comments
fen4o
·
4Comments