Ever since we rolled out the latest version of prow, we've encountered some... problems. Prow feels slow, takes a good bit to respond to random events, etc.
Let's talk about it!
Things I've heard of:
- pods were randomly unable to talk to each other at times
- ... because the push_gateway component was eating ~400% CPU
- now it still seems to be slow, it seems to be all components
- we are suspicious of the generated client
- we are looking at bumping our nodes up to give us headroom while we diagnose what has changed and is going wrong
/assign @BenTheElder
since you're on call
/assign @fejta @cjwagner
since I believe you're looking at this as well
We want to get prow.k8s.io to HEAD instead of continually rolling it back to a pre-February version, so let's figure out what it takes.
 spiffxp
spiffxp
All 27 comments
/priority critical-urgent
/milestone v1.14
spiffxp
on 21 Feb 2019
/assign @Katharine
also looking at reverting deck, apparently
spiffxp
on 21 Feb 2019
/area prow
because why not
spiffxp
on 21 Feb 2019
We rolled back to January -
Merged: https://github.com/kubernetes/test-infra/pull/11429
Deployed: https://gubernator.k8s.io/build/kubernetes-jenkins/logs/post-test-infra-deploy-prow/1019/?log#log
 fejta
on 21 Feb 2019
fejta
on 21 Feb 2019
relevant slack threads:
spiffxp
on 21 Feb 2019
http://velodrome.k8s.io/dashboard/db/monitoring?panelId=9&fullscreen&orgId=1&from=now-2d&to=now - shows tide processing times went wild
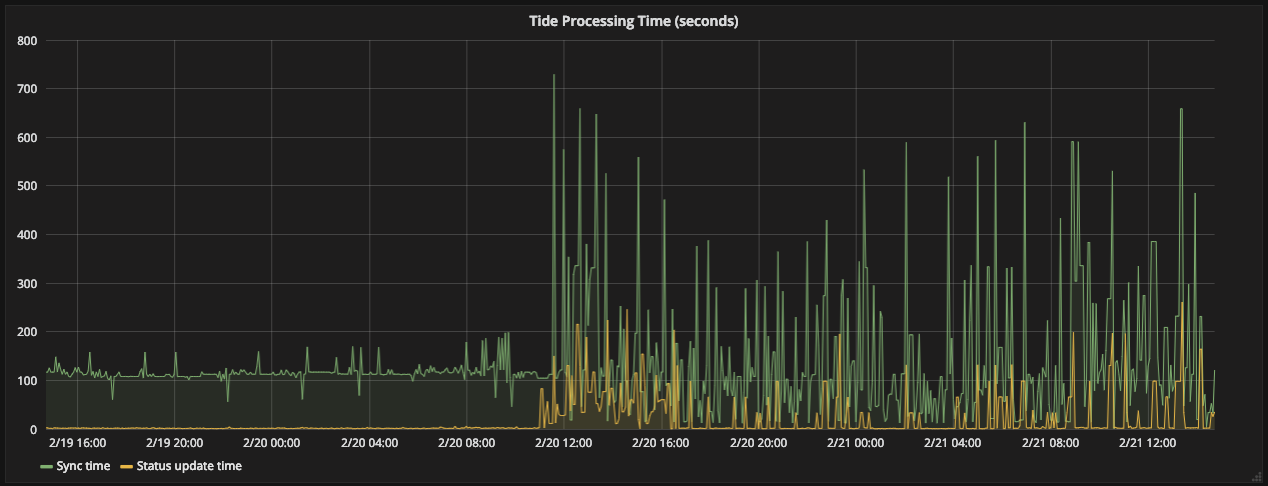
spiffxp
on 21 Feb 2019
prow workloads are on nodes with 2x the number of cores now (4->8)
 BenTheElder
on 21 Feb 2019
BenTheElder
on 21 Feb 2019
resource usage appears to be nominal again, presubmit triggering for helm/charts is fixed.
BenTheElder
on 22 Feb 2019
tide processing time in velodrome looks like it went back in line with historical trend
 tpepper
on 22 Feb 2019
tpepper
on 22 Feb 2019
We're now running deck at HEAD of master without issue after:
- reverting the client refactor in deck
- doubling the cpu available to the cluster
- upgrading the version of GKE
Next will revert the client refactor in plank, followed by tide and then hook
fejta
on 22 Feb 2019
Next will revert the client refactor in plank, followed by tide and then hook
Why?
 stevekuznetsov
on 22 Feb 2019
stevekuznetsov
on 22 Feb 2019
There is a known LOGICAL bug in hook for triggering. We do not currently have any known issues with plank. The tide issues for all we can tell are not related to the clients. It is not a good use of time to do that.
stevekuznetsov
on 22 Feb 2019
Primary goal for the day is:
a) Get all prow components at a Feb 22nd commit instead of Jan 25th
b) Get all prow component at the same commit
c) revert as much as necessary to accomplish the above (and as little as possible)
Once we've found a good Feb 22nd deployment, then start reintroducing things we had to revert.
Normally we keep all prow components at the same commit, and update them concurrently. Today let's move deployments off Jan 25 to Feb 22nd one a time
fejta
on 22 Feb 2019
I gave kubernetes-dev@ a heads up, when we reach an all-clear state we should let them know
spiffxp
on 22 Feb 2019
cc
 neolit123
on 22 Feb 2019
neolit123
on 22 Feb 2019
Yesterday the known problematic pieces were:
- Hook
- Tide
- Deck
- Our cluster
Current state is that cluster, deck and now possibly tide appear to be healthy at head (update at 11a, expecting yellow status update time line to settle down after ~90m). We also changed the cluster significantly from yesterday (larger node pool, new kubernetes version)
fejta
on 22 Feb 2019
tide still looks good:
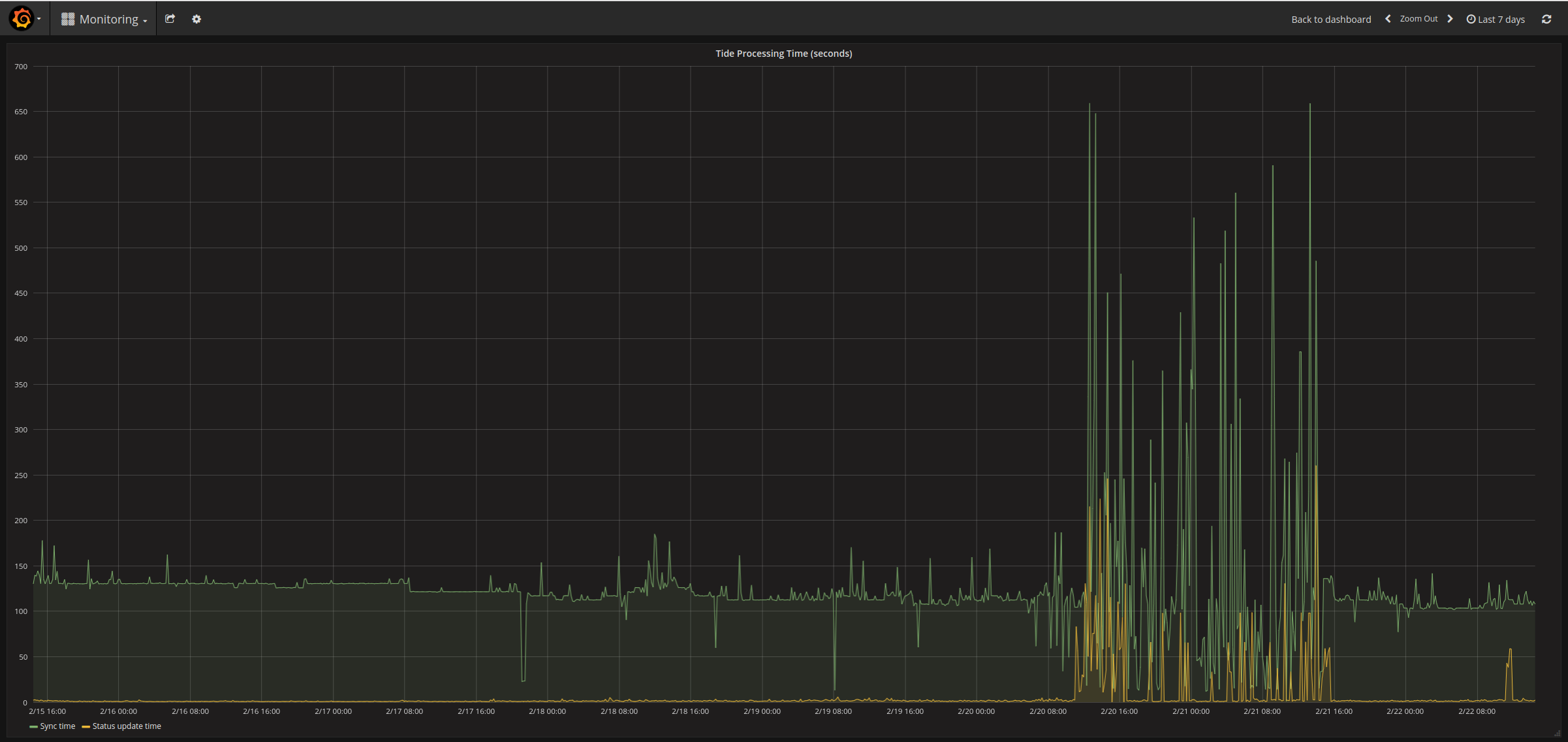
BenTheElder
on 22 Feb 2019
Update: We are now monitoring the effect of deploying this: https://github.com/kubernetes/test-infra/pull/11461
Once we've determined things are stable (lets give it 20 mins or so and keep an eye on CPU) we'll try to update hook to HEAD.
 cjwagner
on 22 Feb 2019
cjwagner
on 22 Feb 2019
11461 Seems to have deployed fine with the exception of a couple transient errors that don't appear to be related.
We're holding off on updating hook for the moment to address https://github.com/kubernetes/test-infra/pull/11460#issuecomment-466586230 and will instead update horologium to HEAD and monitor that.
cjwagner
on 23 Feb 2019
horologium, crier, and sinker are all up to date now and seem to be healthy.
Only hook remains to be updated.
cjwagner
on 23 Feb 2019
hook has been updated now and also seems to be healthy. ref: https://github.com/kubernetes/test-infra/pull/11464
Lets close this issue on Monday if things are still looking good. I'd like to validate everything under peak load to ensure we're in a healthy state.
cjwagner
on 23 Feb 2019
for future reference, this is a typical snapshot across the cluster:
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-prow-ghproxy-2cc2c707-n3p7 257m 3% 4466Mi 16%
gke-prow-n1-standard-8-24b71378-2kw2 84m 1% 2646Mi 9%
gke-prow-n1-standard-8-24b71378-g7bf 185m 2% 3987Mi 15%
gke-prow-n1-standard-8-24b71378-hbt0 205m 2% 3773Mi 14%
gke-prow-n1-standard-8-24b71378-l0s8 79m 0% 2123Mi 7%
gke-prow-n1-standard-8-24b71378-pt2v 275m 3% 4912Mi 18%
gke-prow-n1-standard-8-24b71378-q8s1 347m 4% 1948Mi 7%
gke-prow-n1-standard-8-24b71378-xkpt 219m 2% 4113Mi 15%
gke-prow-n1-standard-8-24b71378-z0c3 141m 1% 6647Mi 25%
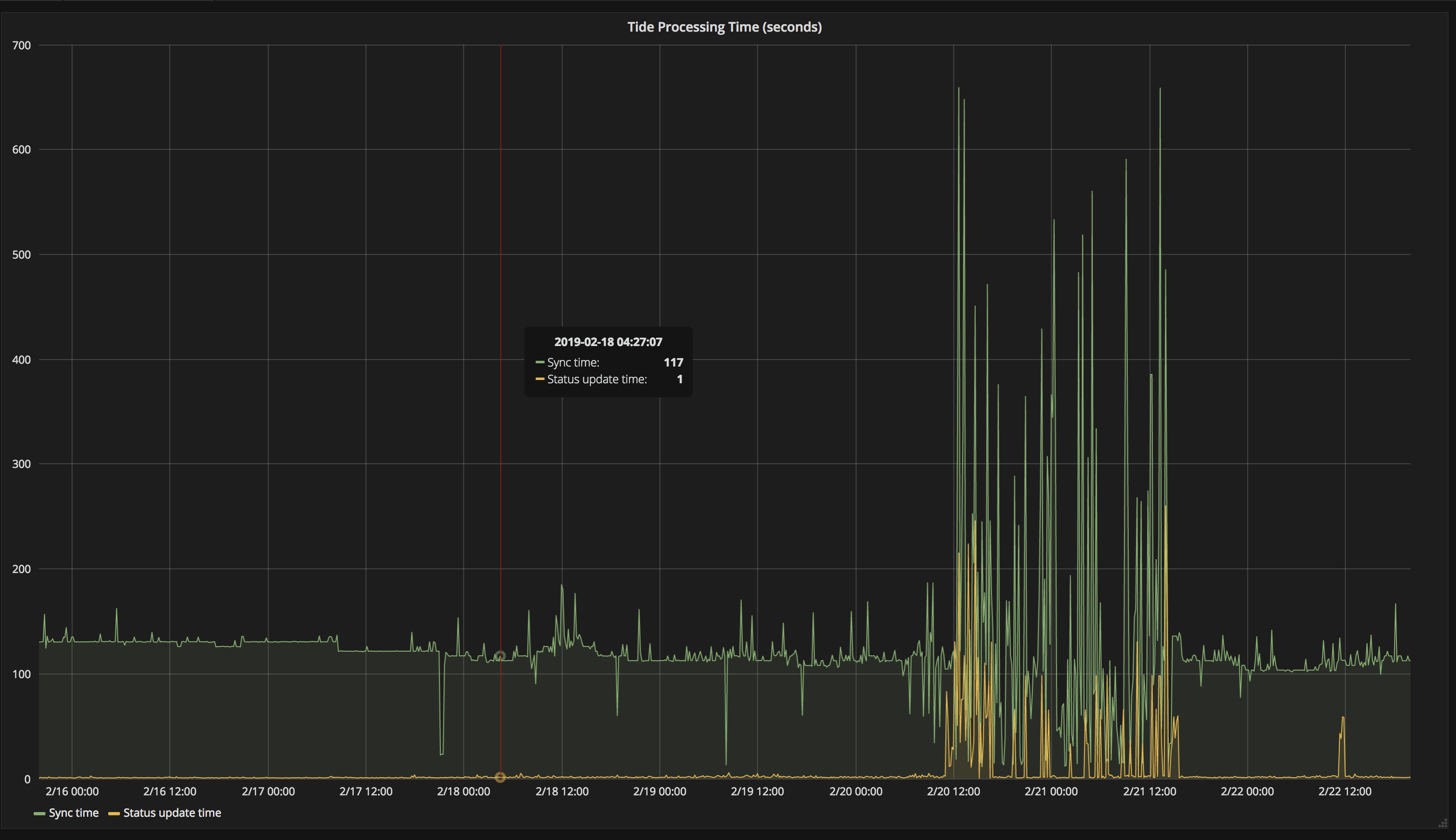
logs look pretty fine.
we can't prove that helm/charts is fine after the hook update but we also have no proof that it's not 😛
BenTheElder
on 23 Feb 2019
@cjwagner spotted a triggered presubmit in helm/charts 🎉
BenTheElder
on 23 Feb 2019
If we're happy with where prow is at @BenTheElder can you send a followup to the k-dev@ thread?
spiffxp
on 25 Feb 2019
We should have all components at the same commit (and update them all concurrently) before we declare success
fejta
on 25 Feb 2019
doing the bump part first
https://github.com/kubernetes/test-infra/pull/11477
On Mon, Feb 25, 2019 at 12:33 PM Erick Fejta notifications@github.com
wrote:
We should have all components at the same commit (and update them all
concurrently) before we declare success—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/kubernetes/test-infra/issues/11430#issuecomment-467172102,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AA4Bq7P6F9_PDfuwl6U_7Y2FBFYLXLgiks5vREiYgaJpZM4bIeVl
.
BenTheElder
on 25 Feb 2019
All components are at the same commit and we've updated them all concurrently without problem: https://github.com/kubernetes/test-infra/pull/11419
Lets consider this issue resolved.
cjwagner
on 28 Feb 2019
Related issues
 fen4o
·
4Comments
cjwagner
·
3Comments
fen4o
·
4Comments
cjwagner
·
3Comments
 xiangpengzhao
·
3Comments
xiangpengzhao
·
3Comments
 sjenning
·
4Comments
sjenning
·
4Comments
 zacharysarah
·
3Comments
zacharysarah
·
3Comments
Most helpful comment
hookhas been updated now and also seems to be healthy. ref: https://github.com/kubernetes/test-infra/pull/11464Lets close this issue on Monday if things are still looking good. I'd like to validate everything under peak load to ensure we're in a healthy state.