Test-infra: boskos resource exhaustion: us-central1-f
What happened:
W0128 12:03:22.701] ERROR: (gcloud.compute.instances.create) Could not fetch resource:
W0128 12:03:22.702] - The zone 'projects/k8s-jkns-gci-gce-1-3/zones/us-central1-f' does not have enough resources available to fulfill the request. '(resource type:pd-standard)'.
W0128 12:03:22.702] Failed to create master instance due to non-retryable error
W0128 12:03:22.702] Some commands failed.
What you expected to happen:
boskos should be able to get a project
Anything else we need to know?:
This is impacting multiple jobs
 spiffxp
spiffxp
All 24 comments
ref: https://github.com/kubernetes/test-infra/pull/10999 hoping this frees up some capacity?
spiffxp
on 28 Jan 2019
https://github.com/kubernetes/kubernetes/issues/73396 - release-master-blocking/node-kubelet-master is failing due to this
spiffxp
on 28 Jan 2019
/sig testing
/area boskos
/area jobs
spiffxp
on 28 Jan 2019
/assign @amwat
as testinfra oncall
/cc @mariantalla
spiffxp
on 28 Jan 2019
ref: https://github.com/kubernetes/test-infra/pull/9161 this has happened before
spiffxp
on 28 Jan 2019
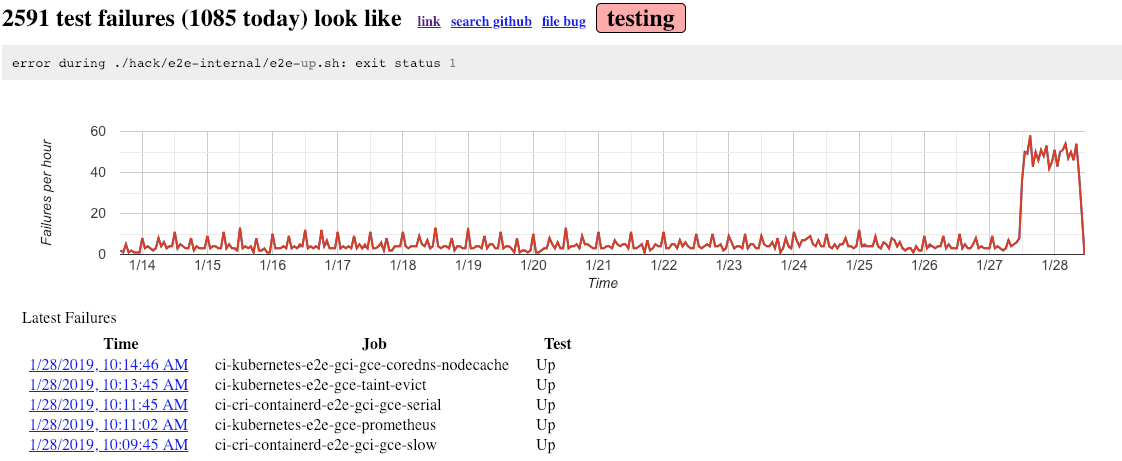
https://storage.googleapis.com/k8s-gubernator/triage/index.html#ea6679417165f10786e6
I'm going to guess this is hitting a lot of our jobs
spiffxp
on 28 Jan 2019
This has nothing to do with boskos though :-) us-central1-f was out of quota
Wonder if we can find a way to list zonal quota and load-balancing clusters to other zones...
 krzyzacy
on 28 Jan 2019
krzyzacy
on 28 Jan 2019
I'm trying to use this as continued evidence that it'd be nice to have boskos pool across zones if there's an issue fo rthat
spiffxp
on 28 Jan 2019
Each project technically has same quota for all available zones so we don't need to make zonal pools. We need to somehow be able to detect stock outs though..
krzyzacy
on 28 Jan 2019
Given that we're hitting stockouts should we shift everything elsewhere, or sit tight and wait? If the latter we should let kubernetes-dev@ know.
I'd rather move to unblock, but I don't know if that means we'll bump into quota issues elsehwere
spiffxp
on 28 Jan 2019
We should not have all resources in one zone. This is going to result in these types of outages. Instead can we:
- Use regional clusters (aka --zone=us-central1)
- Start getting quota in multiple regions
 fejta
on 28 Jan 2019
fejta
on 28 Jan 2019
I agree with that stance in the long term. Is there an issue for this?
Short term, I feel like we should prioritize unblocking:
- anything that runs in sig-release-master-blocking
- anything that runs as a blocking presubmit to kubernetes/kubernetes
spiffxp
on 28 Jan 2019
regional clusters are fine for GKE, but this is GCE nodes isn't it?
Yes, we should move zones. I'm okay with moving to a completely different single zone short term, but longer term we should figure out how to be in multiple zones.
 cblecker
on 28 Jan 2019
spiffxp
on 28 Jan 2019
cblecker
on 28 Jan 2019
spiffxp
on 28 Jan 2019
longer term we should figure out how to be in multiple zones.
For kops-aws test, we rotate across a list of known zones (https://github.com/kubernetes/test-infra/blob/master/scenarios/kubernetes_e2e.py#L39-L86) but that didn't work out too well either since if a zone goes down, we'll be getting random flakes...
krzyzacy
on 28 Jan 2019
It would be great if there was a google api for "is the cloud full" 🤔
cblecker
on 28 Jan 2019
i think a great fix in the longterm for the pre-submits is not have the CP dependency on blocking jobs.
/hides
 neolit123
on 28 Jan 2019
neolit123
on 28 Jan 2019
Another temporary fix is switch to pd-ssd.
It would be great if there was a google api for "is the cloud full" 🤔
I haven't found any news or error report about this issue with capacity in us-central1-f.
 agadelshin
on 28 Jan 2019
agadelshin
on 28 Jan 2019
@pondohva
I haven't found any news or error report about this issue with capacity in us-central1-f.
neither have I, but https://storage.googleapis.com/k8s-gubernator/triage/index.html#ea6679417165f10786e6 is telling me this is not a blip, and every occurrence I've spot checked has had this same problem
@amwat discussed with @fejta @BenTheElder @krzyzacy and myself offline, we're going to try doing the "stupid" thing first, let's just switch everything out of us-central1-f
spiffxp
on 28 Jan 2019
/priority critical-urgent
oh right, because everything is blocked
spiffxp
on 28 Jan 2019
Checking back in to see if #11002 has helped out. It merged around 3:30pm PT so only jobs scheduled after then will benefit.
Presubmits will show us sooner than the slower jobs:
- https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-e2e-gce&width=5 is looking happier
- https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-node-e2e&width=5 is a clear yes
Looking at release-master-blocking:
- https://testgrid.k8s.io/sig-release-master-blocking#gce-cos-master-default maybe?
- https://testgrid.k8s.io/sig-release-master-blocking#node-kubelet-master looks good
- most of the others we'll need to wait
Looking at kubernetes/kubernetes:
- https://github.com/kubernetes/kubernetes/pull/73341 we finally merged something
All good initial signs. I'll be happier when https://go.k8s.io/triage stops showing a pronounced shelf of Up failures
Given all this I'm going to downgrade in priority, but leave this open for continued monitoring
/priority important-soon
/remove-priority critical-urgent
spiffxp
on 29 Jan 2019
/kind failing-test
In my haste to ~fail~ (EDIT: file!, I meant file!), this really show have been a failing-test issue, since it was about jobs/tests continually failing
spiffxp
on 29 Jan 2019
closing this as the issue has been mitigated by https://github.com/kubernetes/test-infra/pull/11002, we might need a better overall solution though
/close
krzyzacy
on 14 Feb 2019
@krzyzacy: Closing this issue.
In response to this:
closing this as the issue has been mitigated by https://github.com/kubernetes/test-infra/pull/11002, we might need a better overall solution though
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 14 Feb 2019
k8s-ci-robot
on 14 Feb 2019
Related issues
 lavalamp
·
3Comments
lavalamp
·
3Comments
 BenTheElder
·
4Comments
BenTheElder
·
4Comments
 Aisuko
·
3Comments
fejta
·
4Comments
cblecker
·
4Comments
Aisuko
·
3Comments
fejta
·
4Comments
cblecker
·
4Comments
Most helpful comment
It would be great if there was a google api for "is the cloud full" 🤔