Terraform: Support count in resource fields
I would like to be able to define repeated fields the same way I can define repeated resources. For instance, this could be used to set beanstalk environment vars based on a list passed in by a variable.
resource "aws_elastic_beanstalk_environment" "myEnv" {
name = "test_environment"
application = "testing"
setting {
count = "${length(var.myvars)}"
namespace = "aws:elasticbeanstalk:application:environment"
name = "${var.myvars.*.name}"
value = "${var.myvars.*.value}"
}
setting {
namespace = "aws:autoscaling:asg"
name = "MinSize"
value = "1"
}
}
 oillio
oillio
All 78 comments
This would also be useful for aws_autoscaling_group tags and lots of other things.
 daveadams
on 7 Jun 2016
daveadams
on 7 Jun 2016
This would also be useful for declaring ebs_block_device mappings for an aws_launch_configuration.
 srhaber
on 16 Jun 2016
srhaber
on 16 Jun 2016
This is an interesting take on block expansion! On first glance, I like the symmetry w/ resource expansion, but I'm not sure on auto-indexing splat behavior you reference. I'll do some thinking on this and swing back around.
 phinze
on 27 Jun 2016
phinze
on 27 Jun 2016
We just need a way to reference items in a list based on the count index. The below would work fine as well, I just like how clean the splat syntax looks.
resource "aws_elastic_beanstalk_environment" "myEnv" {
name = "test_environment"
application = "testing"
setting {
count = "${length(var.myvars)}"
namespace = "aws:elasticbeanstalk:application:environment"
name = "${lookup(element(var.myvars,count.index),"name")}"
value = "${lookup(element(var.myvars,count.index),"value")}"
}
setting {
namespace = "aws:autoscaling:asg"
name = "MinSize"
value = "1"
}
}
Now that I look it up, I may have made up that splat syntax. I don't see a reference to it in the documentation.
oillio
on 6 Jul 2016
Just to add to this, it would also be useful for my use-case as well, multiple environment blocks/fields on aws_opsworks_application resources:
Instead of doing this:
resource "aws_opsworks_application" "custom_app" {
environment = {
key = "${element(split(",", var.environment_variable_keys), 0)}"
value = "${element(split(",", var.environment_variable_values), 0)}"
}
environment = {
key = "${element(split(",", var.environment_variable_keys), 1)}"
value = "${element(split(",", var.environment_variable_values), 1)}"
}
environment = {
key = "${element(split(",", var.environment_variable_keys), 2)}"
value = "${element(split(",", var.environment_variable_values), 2)}"
}
}
We could do this:
resource "aws_opsworks_application" "custom_app" {
environment = {
count = "3"
key = "${element(split(",", var.environment_variable_keys), count.index)}"
value = "${element(split(",", var.environment_variable_values), count.index)}"
}
}
 dlanner
on 8 Jul 2016
dlanner
on 8 Jul 2016
Would this be a valid syntax option?
resource "aws_elastic_beanstalk_environment" "myEnv" {
name = "test_environment"
application = "testing"
setting {
count = "${length(var.myvars)}"
namespace = "aws:elasticbeanstalk:application:environment"
name = "${var.myvars[count.index].name}"
value = "${var.myvars[count.index].value}"
}
setting {
namespace = "aws:autoscaling:asg"
name = "MinSize"
value = "1"
}
}
Also FYI, @dlanner: With the new list and map support in variables, you probably won't need to pass your configs into your module in CSV format anymore. In 0.7-rc2 you might be able to clean up your current setup to be something like key = "${var.environment_variable_keys[1]}
In the next release @phinze added support for lists of objects, so you could even pass the key/value as a single list key = "${lookup(var.environment_variable[1],"key"}"
You will currently still need to manually duplicate the environment entries though.
oillio
on 12 Jul 2016
I would also like to pass multiple settings to aws_elastic_beanstalk_environment in this way, is there a workable solution now that 0.7 has been released?
 jimsheldon
on 8 Aug 2016
jimsheldon
on 8 Aug 2016
I'm trying to do the same thing as @jimsheldon. Is there a way to do this in 0.7.3?
 tjboudreaux
on 11 Sep 2016
tjboudreaux
on 11 Sep 2016
Wanted to add another use case here: launch_specification in AWS spot fleets.
We have to define a launch_specification for each subnet/availability zone, which means that we end up with lots of repetition:
resource "aws_spot_fleet_request" "spot_fleet" {
...
// c4.large
launch_specification {
instance_type = "c4.large"
subnet_id = "${element(data.terraform_remote_state.vpc.private_subnet_ids, 0)}"
availability_zone = "${element(data.terraform_remote_state.vpc.azs, 0)}"
...
}
launch_specification {
instance_type = "c4.large"
subnet_id = "${element(data.terraform_remote_state.vpc.private_subnet_ids, 1)}"
availability_zone = "${element(data.terraform_remote_state.vpc.azs, 1)}"
...
}
launch_specification {
instance_type = "c4.large"
subnet_id = "${element(data.terraform_remote_state.vpc.private_subnet_ids, 2)}"
availability_zone = "${element(data.terraform_remote_state.vpc.azs, 2)}"
...
}
// c3.large
launch_specification {
instance_type = "c3.large"
subnet_id = "${element(data.terraform_remote_state.vpc.private_subnet_ids, 0)}"
availability_zone = "${element(data.terraform_remote_state.vpc.azs, 0)}"
...
}
launch_specification {
instance_type = "c3.large"
subnet_id = "${element(data.terraform_remote_state.vpc.private_subnet_ids, 1)}"
availability_zone = "${element(data.terraform_remote_state.vpc.azs, 1)}"
...
}
launch_specification {
instance_type = "c3.large"
subnet_id = "${element(data.terraform_remote_state.vpc.private_subnet_ids, 2)}"
availability_zone = "${element(data.terraform_remote_state.vpc.azs, 2)}"
...
}
Having count would make this so much easier to maintain.
 borgstrom
on 27 Sep 2016
borgstrom
on 27 Sep 2016
Maybe a new resource type could be created, aws_elastic_beanstalk_environment_setting for example, so the count would work as any other terraform resource, allowing us to write something like this:
resource "aws_elastic_beanstalk_environment" "myEnv" {
...
}
resource "aws_elastic_beanstalk_environment_setting" "environment_variables" {
environment_id = "${aws_elastic_beanstalk_environment.myEnv.id}"
count = "${length(var.myvars)}"
...
}
 cartolari
on 11 Oct 2016
cartolari
on 11 Oct 2016
This would be super helpful in my current task of creating a reusable elastic_beanstalk module. Either of the solutions so far would work for me, either a count on setting or a setting resource as long as that resource can be attached to either aws_elastic_beanstalk_environment or aws_elastic_beanstalk_configuration_template
 devinsba
on 18 Oct 2016
devinsba
on 18 Oct 2016
I would also like to see this implemented, because creating a reusable elastic_beanstalk module is currently almost impossible. Either proposal would work for our use case.
 ottopoellath
on 24 Oct 2016
ottopoellath
on 24 Oct 2016
Just hit the same issue as others trying to create a reusable elastic_beanstalk module. Would be happy with either syntax enhancement or new resource type.
 elbeanio
on 24 Oct 2016
elbeanio
on 24 Oct 2016
Just another vote for the fleet launch specification use case. I reverted to using ERB templates being rendered by a makefile because we have almost 50 specifications per fleet.
 justintime
on 4 Nov 2016
justintime
on 4 Nov 2016
Another vote now that conditionals are allowed in Terraform 0.8
```
- setting {
- count = "${var.spin_down_at_night == "true" ? 1 : 0}"
- namespace = "aws:autoscaling:scheduledaction"
- resource = "ScheduledPeriodicScaleup"
- name = "Recurrence"
- value = "0 10 * * *" #10am UTC = 4am CST
- }```
 myoung34
on 20 Dec 2016
myoung34
on 20 Dec 2016
Wanted to add another vote for the spot fleet launch_specification use case. We end up with 20+ specifications per fleet and have many different fleets so it quickly gets out of control. This looks like a nice elegant solution.
 avistramer
on 22 Dec 2016
avistramer
on 22 Dec 2016
I would love to see this feature working \o /
 mike-zenith
on 23 Dec 2016
mike-zenith
on 23 Dec 2016
Good idea @cartolari. I broke that request out as a separate issue: https://github.com/hashicorp/terraform/issues/11314
Since it doesn't look like count in fields is on the roadmap, maybe we can get that fix implemented.
oillio
on 20 Jan 2017
I'm looking forward to this to be implemented.
 bronislav
on 2 Feb 2017
bronislav
on 2 Feb 2017
A major use case for this is the ability to have a reusable elastic beanstalk module that can be used across application tiers (worker vs webserver) and platforms. Right now we have to duplicate lots of work by having a module for each type and combination.
 beanaroo
on 16 Feb 2017
beanaroo
on 16 Feb 2017
I just ran into this as well. It would be good if someone could share a workaround while we wait to see if this gets first-class support.
I note that the sub-blocks themselves are lists of maps, so if there was syntax to map (the function) a list into a map (the datastructure) I think that would solve this case.
For reference I wanted to add multiple access_policy blocks to azurerm_key_vault.
 glenjamin
on 23 Mar 2017
glenjamin
on 23 Mar 2017
Run into this issue trying to create different number of storage_data_disks in azurerm_virtual_machines.:
resource "azurerm_virtual_machine" "myvm" {
...
storage_data_disk {
count = ${var.disks_count}
name = "datadisk-${count.index}"
lun = ${count.index}
vhd_uri = /some/dir/datadisk-${count.index}.vhd"
create_option = "Empty"
...
}
}
 javierbertoli
on 19 Apr 2017
javierbertoli
on 19 Apr 2017
This would improve my code reusability very, very much!
 kamsz
on 24 Apr 2017
kamsz
on 24 Apr 2017
really waiting for this feature, any update?
Thanks!
 akmalabbasov
on 5 May 2017
akmalabbasov
on 5 May 2017
Hi all! Sorry for the quiet here.
This issue is still on our radar, but it'll still likely be some time before it's addressed. When it comes to changes to the configuration language, we worry that iteratively adding features to the language in isolation will create a result that is complicated and inconsistent, so instead we've been quietly collecting configuration use-cases that are currently unsupported or inconvenient (this one being an example of the former) with the goal of doing a holistic language revamp in the future.
Our goal would be to address as many of the use-cases as we can while still keeping the language as simple and understandable as possible, and while ensuring that all of the features "tessellate" well with each other and with existing Terraform core concepts.
Better support for reusable modules is definitely a key goal, but at this time we don't have a firm plan for when this work would begin. However, I do look forward to a future discussion with the community about the results of this design effort.
In the mean time, using external tools to generate Terraform configurations from templates is the best workaround for this language limitation.
Sorry again for the lack of movement here, and thanks for your patience as we work through these larger Terraform design changes.
 apparentlymart
on 5 May 2017
apparentlymart
on 5 May 2017
Could you suggest external tools for us to investigate? Terracotta is the only one I've found, and it only supports conditionals (which Terraform already partially supports), not loops/expansions.
 ThePletch
on 23 May 2017
ThePletch
on 23 May 2017
Could you suggest external tools for us to investigate? Terracotta is the only one I've found, and it only supports conditionals (which Terraform already partially supports), not loops/expansions.
I think the idea is you can do basically anything with a scripting language that can generate JSON.
Some examples are https://github.com/glenjamin/terrafiddle and https://github.com/thattommyhall/terrafied
glenjamin
on 23 May 2017
@borgstrom, according to the AWS docs it looks like you now should be able to use a comma separated string to list the subnets. I tried this in my TF config and it worked. Looks like the same for AZs as far as placement goes, though I didn't test that.
AWS SpotFleetLaunchSpecification
SubnetId (request), subnetId (response)
The ID of the subnet in which to launch the instances. To specify multiple subnets, separate them using commas; for example, "subnet-a61dafcf, subnet-65ea5f08".
AvailabilityZone (request), availabilityZone (response)
The Availability Zone.
[Spot fleet only] To specify multiple Availability Zones, separate them using commas; for example, "us-west-2a, us-west-2b".
 beastie29a
on 24 May 2017
beastie29a
on 24 May 2017
Another use case: The ability to optionally add lifecycle hooks based on whether a hook target is passed into an ASG module
 CannibalVox
on 8 Aug 2017
CannibalVox
on 8 Aug 2017
I just ran into this. I was trying to configure the environment based on platform (PHP or Node.js). Unfortunately, I got this error: invalid or unknown key: count.
# PHP platform option
setting {
count = "${var.platform == "php" ? 1 : 0}"
namespace = "aws:elasticbeanstalk:container:php:phpini"
name = "document_root"
value = "/"
}
# Node.js platform options
setting {
count = "${var.platform == "php" ? 0 : 1}"
namespace = "aws:elasticbeanstalk:container:nodejs"
name = "NodeCommand"
value = ""
}
setting {
count = "${var.platform == "php" ? 0 : 1}"
namespace = "aws:elasticbeanstalk:container:nodejs"
name = "GzipCompression"
value = "true"
}
setting {
count = "${var.platform == "php" ? 0 : 1}"
namespace = "aws:elasticbeanstalk:container:nodejs"
name = "ProxyServer"
value = "nginx"
 jpdoria
on 25 Aug 2017
jpdoria
on 25 Aug 2017
Hi all,
I just wanted to check in here again since it's been a while since my last note. In the mean time, we have a sketch for a possible way this could be represented in configuration which I'd like to share for feedback.
We are planning to introduce a new resource meta-attribute foreach that should provide a more convenient way to express the common pattern of creating one resource instance for each element in a list or map:
# DRAFT: Not yet implemented, and details may change before final release
resource "example" "example" {
# Set "foreach" to any list or map value to create one instance per entry.
foreach = "${var.list}"
# foreach.value gives the value of the list item corresponding to each instance
name = "${foreach.value}"
}
In initial sketches we'd tried generalizing this foreach feature to work within nested blocks, similar to what was originally requested here for count. However, this gets a bit tricky for a number of reasons. In particular, the use of the foreach. variable prefix means that multiple nested repetitions cannot be easily supported, and handling foreach as an attribute makes it hard to support generating block labels (the quoted values after the block type keyword) that vary per item. The latter is not currently used by any resource, but allowing that is another part of the planned enhancements.
That led us to the following idea, which is the current proposal:
# DRAFT: Not yet implemented, and details may change before final release
resource "aws_elastic_beanstalk_environment" "myEnv" {
name = "test_environment"
application = "testing"
dynamic "setting" {
foreach = "${var.myvars}" # presumed to be a map of strings
content {
namespace = "aws:elasticbeanstalk:application:environment"
name = "${dynamic.foreach.name}"
value = "${dynamic.foreach.value}"
}
}
The new dynamic block generates zero or more blocks of the type given in its label, which in the above example is "setting". The foreach attribute inside is then interpreted in the same way as for top-level foreach as described above, and the content child block is evaluated for each item to produce the contents of each dynamically-generated block.
This nested structure, while more verbose, allows for the generation of _labelled_ blocks as in the following example;
# DRAFT: Not yet implemented, and details may change before final release
example "foo" {
}
example "bar" {
}
The above could be generated as:
# DRAFT: Not yet implemented, and details may change before final release
dynamic "example" {
foreach = "${var.example_labels}"
labels = ["${dynamic.foreach.value}"]
content {
}
}
At this time the resource schema system does not support nested blocks with labels, but this is planned to better support use-cases where there is a multiple-instance nested resource where each instance has a unique name, with the name then serving as a key for diffing purposes.
The current sketch does not actually currently address the problem of nested dynamic blocks, like this:
# DRAFT: Not yet implemented, and details may change before final release
dynamic "example" {
foreach = "${var.example_items}"
content {
dynamic "example_child" {
foreach = "${var.example_item_children}"
content {
value = "${dynamic.foreach.value}"
parent_value = "${ ... }" # how do we get the item from the parent "dynamic" block?
}
}
}
}
We'll continue to iterate on the design here to try to solve for this more complex situation. In the mean time, I'm curious to hear feedback on the general idea here.
One concern we already have is that it may not be obvious to a new Terraform user that this block type has this special, generic behavior across all resources. We're thinking about different names for this block that might make this clearer, so this is one specific area where the design may drift as we continue to work on it.
apparentlymart
on 1 Sep 2017
@apparentlymart
Can we support the way as jinja, so we are free to play around with it?
{% extends "layout.html" %}
{% block body %}
<ul>
{% for user in users %}
<li><a href="{{ user.url }}">{{ user.username }}</a></li>
{% endfor %}
</ul>
{% endblock %}
 ozbillwang
on 23 Sep 2017
ozbillwang
on 23 Sep 2017
Good question, @ozbillwang!
Jinja2 is a text templating language rather than a structural/expression language, so unfortunately it's not at an appropriate level of abstraction for Terraform. In order to properly resolve the dependency graph, Terraform needs to be able to resolve some parts of the configuration _before_ expression evaluation is possible. Terraform relies on its ability to parse the configuration in multiple passes -- decoding the top-level structure first, and only later the bodies of blocks -- and so treating the configuration as a text-based template would be too free-form for Terraform's needs.
It's also important that whatever structure we specify for the native configuration syntax can _also_ be expressed in JSON, since we promise that generating configuration in JSON format allows equivalent functionality to the native syntax.
With all of that in mind, the above proposal is an attempt to address the problem within the existing block structure, so that we can retain the "partial parsing" capability we need and so that we can use the existing mapping from native syntax to JSON syntax.
For illustrative purposes, here's how one of my examples above might look as JSON:
// DRAFT: Not yet implemented, and details may change before final release
{
"resource": {
"aws_elastic_beanstalk_environment": {
"myEnv": {
"name": "test_environment",
"application": "testing",
"dynamic": {
"setting": {
"foreach": "${var.myvars}",
"content": {
"namespace": "aws:elasticbeanstalk:application:environment",
"name": "${dynamic.foreach.name}",
"value": "${dynamic.foreach.value}"
}
}
}
}
}
}
}
As usual, it's not so easy to read or write by hand, but fits within normal JSON syntax so it can easily be generated by software in situations where all or part of a configuration is derived from some other system, or generated using a transpiler like Jsonnet.
apparentlymart
on 26 Sep 2017
I have an use-case to overload Elastic Load Balancer with multiple ports for many instances of same service. Based on @apparentlymart idea, does the following going to work? Or can I achieve this with any existing feature?
resource "aws_elb" "ec2_elb" {
listener {
foreach = "${var.myvars}" # presumed to be a map of strings
content {
instance_port = "${listener.foreach.instance_port}"
instance_protocol = "${listener.foreach.instance_protocol}"
lb_port = "${listener.foreach.lb_port}"
lb_protocol = "${listener.foreach.lb_protocol}"
}
}
}
 palaniswamy
on 12 Oct 2017
palaniswamy
on 12 Oct 2017
I got pointed over here from #16276. Here's my $0.02.
I'd like to be able to create elastic beanstalk environments with conditional configuration, eg. add some settings to the environment only in dev envs.
Given this sort of thing:
resource "aws_elastic_beanstalk_environment" "foo" {
name = "foo"
application = "foo_app"
cname_prefix = "foo"
solution_stack_name = "64bit Amazon Linux 2017.03 v2.5.0 running PHP 7.1"
tier = "WebServer"
setting = [
{
namespace = "aws:autoscaling:asg"
name = "Availability Zones"
value = "Any"
},
{
namespace = "aws:autoscaling:asg"
name = "Cooldown"
value = "360"
},
{
namespace = "aws:autoscaling:asg"
name = "MaxSize"
value = "${var.asg_max_size}"
},
# plus many more...
]
}
I'd like to be able to do something like this, ie. define each beanstalk environment setting as a separate resource and conditionally create some of them:
resource "aws_elastic_beanstalk_environment" "foo" {
name = "foo"
application = "foo_app"
cname_prefix = "foo"
solution_stack_name = "64bit Amazon Linux 2017.03 v2.5.0 running PHP 7.1"
tier = "WebServer"
}
resource "aws_elastic_beanstalk_environment_setting" "aws_autoscaling_asg_availability_zones" {
environment = aws_elastic_beanstalk_environment.foo.name
namespace = "aws:autoscaling:asg"
name = "Availability Zones"
value = "Any"
}
resource "aws_elastic_beanstalk_environment_setting" "aws_autoscaling_asg_cooldown" {
environment = aws_elastic_beanstalk_environment.foo.name
namespace = "aws:autoscaling:asg"
name = "Cooldown"
value = "360"
}
resource "aws_elastic_beanstalk_environment_setting" "aws_autoscaling_asg_maxsize" {
count = "${var.is_dev_env}"
environment = aws_elastic_beanstalk_environment.foo.name
namespace = "aws:autoscaling:asg"
name = "MaxSize"
value = "${var.asg_max_size}"
}
# plus many more resources
Would this sort of thing be easy to add?
 robinbowes
on 25 Oct 2017
robinbowes
on 25 Oct 2017
I would like to know why this doesn't work.
variable "properties"{
type = "map"
default = {
MY_KEY_A = "VALUE_A"
MY_KEY_B = "VALUE_B"
MY_KEY_C = "VALUE_C"
}
}
resource "aws_elastic_beanstalk_environment" "tf_env_ebs" {
name = "etc..."
application = "etc..."
solution_stack_name = "Linux ..."
#other setting....
setting {
count = "${length(var.properties)}"
namespace = "aws:elasticbeanstalk:application:environment"
name = "${element(keys(var.properties), count.index)}"
value = "${element(values(var.properties), count.index)}"
}
}
Error:
.aws_elastic_beanstalk_environment.tf_env_ebs: setting.3: invalid or unknown key: count
 diogobernard
on 31 Oct 2017
diogobernard
on 31 Oct 2017
I like the dynamic foreach approach. Clean and concise.
@apparentlymart Is foreach going to support lists, maps and strings?
It wasn't entirely clear in your message.
In addition, is there alpha implementation of this behavior yet so we can test it out?
 dcherniv
on 8 Nov 2017
dcherniv
on 8 Nov 2017
@apparentlymart
Regarding your sketch, we can address the problem of nested dynamic blocks by adding another one optional meta-attribute foreach_accessor with default value foreach. This attribute renames the foreach variable. Your sketch example will become:
dynamic "example" {
foreach = "${var.example_items}"
foreach_accessor = "parent"
content {
dynamic "example_child" {
foreach = "${var.example_item_children}"
content {
value = "${dynamic.foreach.value}"
parent_value = "${dynamic.parent.value}"
}
}
}
}
The similar approach used in Ansible for loops.
 UvaK
on 19 Dec 2017
UvaK
on 19 Dec 2017
Hi all,
I've now implemented something like the above proposal as an HCL extension which we'll integrate as part of the broader work to switch over to the improved configuration language implementation.
The current state is _slightly_ different than what I posted earlier, but still broadly the same:
# DRAFT: Not yet integrated into Terraform, and details may change before final release
resource "aws_elastic_beanstalk_environment" "myEnv" {
name = "test_environment"
application = "testing"
dynamic "setting" {
for_each = var.environment_variables
content {
namespace = "aws:elasticbeanstalk:application:environment"
name = setting.foreach.key
value = setting.foreach.value
}
}
}
The two main changes are:
- The
foreachargument is now calledfor_each, which is more consistent with how we usually name things in Terraform. - The iteration variable for use inside the
contentblock is now named after the block type by default, so it'ssettingin the above example.
Nested dynamic blocks are possible by giving each a separate iterator variable name. The default of naming it after the block type means this happens automatically in most cases, but a new iterator argument allows the variable name to be customized in rare situations where the block names collide, similar to what @UvaK suggested:
# DRAFT: Not yet integrated into Terraform, and details may change before final release
dynamic "example" {
for_each = var.example_items
iterator = parent
content {
dynamic "example" {
for_each = parent.children
iterator = child
content {
value = child.value
parent_value = parent.value
}
}
}
}
We may find that there are some edge-cases here to take care of once this is fully integrated and we can more easily test it with real-world examples in Terraform itself, but the implementation so far seems like a good proof-of-concept of this approach.
(The above examples also reflect the new config parser's ability to real with variable references directly as attribute values, without wrapping them in ${ ... }. That wrapping syntax is now used only for string interpolation in the new parser.)
apparentlymart
on 22 Jan 2018
@apparentlymart
That's great.
So if variable environment_variables is ["dev", "staging", "prod"] how this part will look like? Or can you give any real samples for us to understand the change?
dynamic "setting" {
for_each = var.environment_variables
content {
namespace = "aws:elasticbeanstalk:application:environment"
name = setting.foreach.name
value = setting.foreach.value
}
}
This was based on the opening example in this issue, so I was assuing that var.environment_variables is a map of environment variables to set in the elastic beanstalk application's environment. So we could expand it out like this, to remove the variable from the mix to see what's really going on here:
# DRAFT: Not yet integrated into Terraform, and details may change before final release
dynamic "setting" {
for_each = {
HTTP_PROXY = "10.1.2.1:8080"
TMPDIR = "/var/myapp/tmp"
# .. etc
}
content {
namespace = "aws:elasticbeanstalk:application:environment"
name = setting.foreach.key
value = setting.foreach.value
}
}
The above would be interpreted as if the following had been written:
setting {
namespace = "aws:elasticbeanstalk:application:environment"
name = "HTTP_PROXY"
value = "10.1.2.1:8080"
}
setting {
namespace = "aws:elasticbeanstalk:application:environment"
name = "TMPDIR"
value = "/var/myapp/tmp"
}
# .. etc
The "iterator" variable (setting in this example, due to the block type name) is an object with key and value attributes giving the key and value of each element in the given collection. Since the collection is a map in this case the keys will be the actual map keys. If a list had been provided instead, the keys would be the numeric indices of the elements.
Of course, with a literal for_each value it feels quite contrived, since it would've been better to just write it out fully in the first place, but I hope that gives a better sense of how this mechanism is behaving and how it might be used in practice when assigning more dynamic expressions to for_each.
apparentlymart
on 22 Jan 2018
hi @apparentlymart
That foreach functionality looks great, but I'd love to use it for aws spot fleet launch specifications. All that changes between them is instance type, price and weight .
So could I use the dynamic foreach for all but those two properties? i.e.
resource "aws_spot_fleet_request" "ecs_container_instance_spot_fleet" {
iam_fleet_role = "${aws_iam_role.ecs_spot_fleet.arn}"
target_capacity = "${var.ecs_fleet_target_capacity}"
spot_price = "0.07"
terminate_instances_with_expiration = true
replace_unhealthy_instances = true
valid_until = "2018-07-05T00:00:00Z"
allocation_strategy = "diversified"
lifecycle {
create_before_destroy = true
}
dynamic "launch_configuration" {
for_each = {
m4.large = {
price = "0.111"
weight = "2"
}
m4.xlarge = {
price = "0.222"
weight = "2"
}
m4.2xlarge = {
price = "0.333"
weight = "3"
}
}
content {
ami = "${local.container_instance_ami}"
instance_type = setting.foreach.key
spot_price = setting.foreach.value["price"]
iam_instance_profile = "${aws_iam_instance_profile.ecs_container_instances.name}"
user_data = "${data.template_file.userdata_ecs_instance.rendered}"
vpc_security_group_ids = ["${aws_security_group.ecs_shared_instance_sg.id}"]
key_name = "${var.linux_key_pair}"
subnet_id = "${data.aws_subnet.private_subnet.0.id}"
ebs_optimized = true
root_block_device = ["${local.spot_root_block_device}"]
ebs_block_device = ["${local.ebs_block_devices}"]
weighted_capacity = setting.foreach.value["weight"]
tags = "${merge(local.tags, var.instance_tag_extras)}"
}
I thought a list of maps would work for launch_specifications but I get an error about required fields not being specified. That's a different issue though!
 JoshiiSinfield
on 16 Feb 2018
JoshiiSinfield
on 16 Feb 2018
Is there an ETA on the implementation of the suggested dynamic fix/change?
 GElkayam
on 15 Mar 2018
GElkayam
on 15 Mar 2018
@JoshiiSinfield,
Assigning lists of maps to the name of a nested block as if it were an attribute is something that partially works due to a coincidence in the implementation, but there are lots of situations where it doesn't properly work because Terraform was never intended to work that way. (Internally, it works because Terraform currently happens to use a similar data structure for both situations, but there are some differences that cause failures.)
The approach you showed here with using a mixture of iterator references and other references inside the content block is indeed what I'd suggest in that situation. The exact syntax might not be exactly as you showed here but the principle is good.
apparentlymart
on 15 Mar 2018
Yes, but when are you going to fix this properly? This ticket is 21 months old.
robinbowes
on 15 Mar 2018
+1
 pb0101
on 16 Mar 2018
pb0101
on 16 Mar 2018
There seems to be a way to fake this which I will try but FYI https://serverfault.com/questions/833810/terraform-use-nested-loops-with-count
 ghost
on 3 Apr 2018
ghost
on 3 Apr 2018
@khushil what you are talking about is totally different from this issue. (The question in your URL is not the case being discussed in this issue.)
 ckyoog
on 4 Apr 2018
ckyoog
on 4 Apr 2018
2 issues require count support:
https://github.com/terraform-providers/terraform-provider-azurerm/issues/1002
https://github.com/terraform-providers/terraform-provider-azurerm/issues/795
 metacpp
on 7 Apr 2018
metacpp
on 7 Apr 2018
Have the same thing in a module which creates Cloudfront distribution, ACM cert, R53 records etc and currently I need to maintain several different versions of the module for different use cases which is not optimal.
As an example I have one use case where we use Lambda@Edge which requires a certain block to be present on the cloudfront distribution resource, but in most other cases this should not be present. Would be good to be able to toggle that and other similar blocks/parameters.
Part of code with lambda association:
default_cache_behavior {
allowed_methods = "${var.allowed_methods}"
cached_methods = "${var.cached_methods}"
target_origin_id = "${module.distribution_label.id}"
compress = "${var.compress}"
forwarded_values {
headers = ["${var.forward_headers}"]
query_string = "${var.forward_query_string}"
query_string_cache_keys = "${var.query_string_cache_keys}"
cookies {
forward = "${var.forward_cookies}"
whitelisted_names = ["${var.forward_cookies_whitelisted_names}"]
}
}
viewer_protocol_policy = "${var.viewer_protocol_policy}"
lambda_function_association {
event_type = "${var.lambda_event_trigger_type}"
lambda_arn = "${var.lambda_arn}"
}
}
When will support for all of these things be added?
 anderssoder
on 10 Apr 2018
anderssoder
on 10 Apr 2018
Please make this happen, without this functionality, configuring multiple ECS tasks with multiple volumes is just a pain.
 azelezni
on 16 May 2018
azelezni
on 16 May 2018
Given the number of people interested in this feature, (or more generally disappointed by the low degree of reuse that HCL permits easily) maybe it's time to invest into a transpiler from a proper language (eg. Dhall).
FYI someone as started such a project: https://github.com/blast-hardcheese/terraform-dhall/tree/poc.
 jbgi
on 16 May 2018
jbgi
on 16 May 2018
@jbgi that is a plan my team has using Ruby (although I'll look into terraform-dhall project) .. however this shouldn't be necessary! As I'm sure you understand!
 bcarpio
on 16 May 2018
bcarpio
on 16 May 2018
@jbgi python +1. HCL is such an impediment 😢 . We could just do jinja2 -> terraform as a start. If only someone would create such a useful tool... they'd be nothing less than a hero of devops everywhere.
 saplla
on 16 May 2018
saplla
on 16 May 2018
😢 😢 😢
 agolomoodysaada
on 16 May 2018
agolomoodysaada
on 16 May 2018
Greetings, person who just discovered this ticket!! I'm pretty confident Hashicorp understands both the use cases and level of interest for this feature. There's a TON of people watching this issue and repo though so please consider if your reply adds something new before adding it.
 evralston
on 16 May 2018
evralston
on 16 May 2018
I also have this issue
 Tiny-wlx
on 17 May 2018
Tiny-wlx
on 17 May 2018
I'd like to create a google_compute_instance with a configurable number of disks (for the purpose of making logical volume groups), however I am unable to because each disk requires its own attached_disk entry; would this feature, if implemented, allow me to do this?
 lubars
on 5 Jun 2018
lubars
on 5 Jun 2018
I would like to add dynamically extra disks to a vm in VMware when needed, this would be very usefull! :)
 michaelhajjar
on 6 Jun 2018
michaelhajjar
on 6 Jun 2018
This would be very valuable for dynamically adding multiple origins to a CloudFront distribution. As it is, I either need to create multiple distributions or manually maintain a list of origins where everyother resource in my code is driven by environment-specific variables.
 creativeux
on 6 Jun 2018
creativeux
on 6 Jun 2018
as @michaelhajjar mentioned, this would be very useful for being able to create a single vmware creation module that can create a vsphere_virtual_machine with an optional number of disks
 MrFishFinger
on 20 Jun 2018
MrFishFinger
on 20 Jun 2018
Is there an update or a milestone associated with this change? I am another vsphere user looking real hard at dynamic disk subresource usecase :beers: @MrFishFinger
 mauilion
on 21 Jun 2018
mauilion
on 21 Jun 2018
Is this somewhat related? https://github.com/terraform-providers/terraform-provider-null/issues/18
 gaui
on 26 Jun 2018
gaui
on 26 Jun 2018
Same here, would be very nice to have this in regards to volumes on ECS.
 KWyckmans
on 12 Jul 2018
KWyckmans
on 12 Jul 2018
I believe this is going to be supported in Terraform 0.12.
 mwarkentin
on 12 Jul 2018
mwarkentin
on 12 Jul 2018
Yeah, seems like following improvement:
Dynamic blocks. Child blocks such as rule in aws_security_group can now be dynamically generated based on lists/maps and support iteration.
 rkul
on 12 Jul 2018
rkul
on 12 Jul 2018
Indeed, that's what that bullet point in the preview article is talking about. There's a more detailed article on this subject coming very soon, so I'd been holding off for that to link to it. I'll link to that here once it's posted.
apparentlymart
on 12 Jul 2018
Here we go: For and For Each. This article covers a set of related new constructs for working with collections, including the dynamic block.
For those who'd like more detail on this feature _in particular_, you might like to read the updated docs from the development branch. These docs will be subject to some more edit passes before final, but the general idea is there.
apparentlymart
on 12 Jul 2018
That looks great - can't wait until it's released.
robinbowes
on 12 Jul 2018
This is the fourth post of the series highlighting new features in Terraform 0.12.:
HashiCorp Terraform 0.12 Preview: Generalized Splat Operator
 mattes
on 25 Jul 2018
mattes
on 25 Jul 2018
@mattes When will 0.12 be released?
saplla
on 25 Jul 2018
@saplla the only info I can find is this:
Terraform 0.12 will not be released until later this summer
bcarpio
on 25 Jul 2018
I tried the following with Terraform v0.12.0-alpha1:
provider "aws" {
region = "us-west-2"
}
variable "environment_vars" {
type = map(string)
default = {
FOO = "bar"
BAZ = "boop"
}
}
resource "aws_elastic_beanstalk_environment" "example" {
name = "test_environment"
application = "testing"
# Static Setting
setting {
namespace = "aws:autoscaling:asg"
name = "MinSize"
value = "1"
}
dynamic "setting" {
for_each = var.environment_vars
content {
namespace = "aws:elasticbeanstalk:application:environment"
name = setting.key
value = setting.value
}
}
}
I don't have sufficient other Elastic Beanstalk infrastructure in my AWS account to apply this, but I was able to see it generating the expected result in terraform plan.
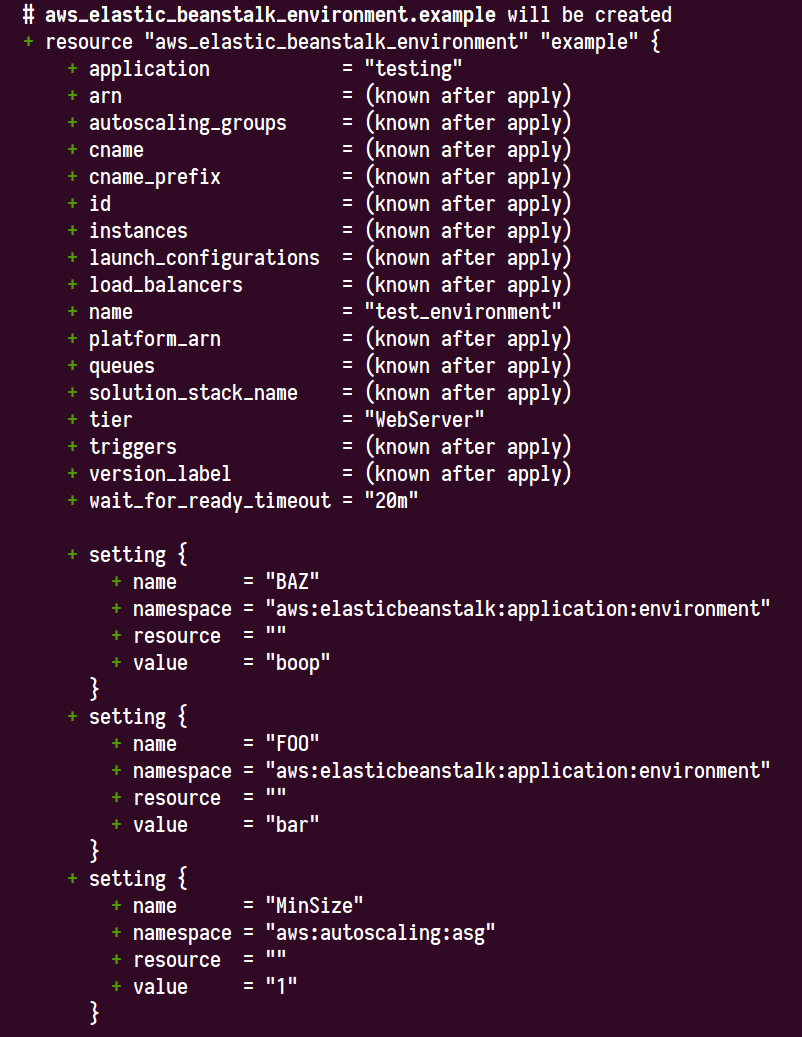
So with all of that said, it seems that the new dynamic block feature serves the use-case presented in this issue, albeit not in exactly the same way as suggested, and so I'm going to close this out. You can try this feature out experimentally in v0.12.0-alpha1, and it'll be also included in the eventual v0.12.0 final release. Thanks everyone for your patience on this one! I know it's been a long time coming. :tada:
apparentlymart
on 26 Oct 2018
@apparentlymart will this new dynamic setting also support 0 resource blocks? So for example if I left variable empty, it won't create this blocks at all?
 petrokashlikov
on 11 Apr 2019
petrokashlikov
on 11 Apr 2019
@petrokashlikov yes I believe that should be the case.
mwarkentin
on 12 Apr 2019
I couldn't get this to work. We build out two environments one with AAD integration and one without, so I was trying to dynamically create the azure_active_directory dependent on whether or not the params have been provided.
This is the terraform defn
role_based_access_control {
enabled = "true"
dynamic "azure_active_directory" {
for_each = "${var.aad_tenant_id != "" ? list("aad_reqd") : list("")}"
content {
client_app_id = "${var.aks_client_app_id}"
server_app_id = "${var.aks_server_app_id}"
server_app_secret = "${var.aks_server_app_secret}"
tenant_id = "${var.aad_tenant_id}"
}
}
}
On terraform plan I get this:
+ role_based_access_control {
+ enabled = true
+ azure_active_directory {
+ client_app_id = (known after apply)
+ server_app_id = (known after apply)
+ server_app_secret = (sensitive value)
+ tenant_id = (known after apply)
}
}
But on terraform apply I get the error
The value of parameter aadProfile.clientId is invalid
So, I assume the block has been created
 Johnch9
on 24 May 2019
Johnch9
on 24 May 2019
My bad
I hadn't defined an empty list correctly
for_each = "${var.aad_tenant_id != "" ? list("aad_reqd") : []}"
Now works now :)
Johnch9
on 24 May 2019
I'm going to lock this issue because it has been closed for _30 days_ ⏳. This helps our maintainers find and focus on the active issues.
If you have found a problem that seems similar to this, please open a new issue and complete the issue template so we can capture all the details necessary to investigate further.
![hashibot[bot] picture](https://avatars2.githubusercontent.com/in/8332?v=4&s=40) hashibot[bot]
on 25 Jul 2019
hashibot[bot]
on 25 Jul 2019
Related issues
 zeninfinity
·
3Comments
zeninfinity
·
3Comments
 rjinski
·
3Comments
rjinski
·
3Comments
 sprokopiak
·
3Comments
sprokopiak
·
3Comments
 carl-youngblood
·
3Comments
carl-youngblood
·
3Comments
 shanmugakarna
·
3Comments
shanmugakarna
·
3Comments
Most helpful comment
Hi all,
I just wanted to check in here again since it's been a while since my last note. In the mean time, we have a sketch for a possible way this could be represented in configuration which I'd like to share for feedback.
We are planning to introduce a new resource meta-attribute
foreachthat should provide a more convenient way to express the common pattern of creating one resource instance for each element in a list or map:In initial sketches we'd tried generalizing this
foreachfeature to work within nested blocks, similar to what was originally requested here for count. However, this gets a bit tricky for a number of reasons. In particular, the use of theforeach.variable prefix means that multiple nested repetitions cannot be easily supported, and handlingforeachas an attribute makes it hard to support generating block labels (the quoted values after the block type keyword) that vary per item. The latter is not currently used by any resource, but allowing that is another part of the planned enhancements.That led us to the following idea, which is the current proposal:
The new
dynamicblock generates zero or more blocks of the type given in its label, which in the above example is"setting". Theforeachattribute inside is then interpreted in the same way as for top-levelforeachas described above, and thecontentchild block is evaluated for each item to produce the contents of each dynamically-generated block.This nested structure, while more verbose, allows for the generation of _labelled_ blocks as in the following example;
The above could be generated as:
At this time the resource schema system does not support nested blocks with labels, but this is planned to better support use-cases where there is a multiple-instance nested resource where each instance has a unique name, with the name then serving as a key for diffing purposes.
The current sketch does not actually currently address the problem of nested dynamic blocks, like this:
We'll continue to iterate on the design here to try to solve for this more complex situation. In the mean time, I'm curious to hear feedback on the general idea here.
One concern we already have is that it may not be obvious to a new Terraform user that this block type has this special, generic behavior across all resources. We're thinking about different names for this block that might make this clearer, so this is one specific area where the design may drift as we continue to work on it.