Terraform: Partial/Progressive Configuration Changes
For a while now I've been wringing my hands over the issue of using computed resource properties in parts of the Terraform config that are needed during the refresh and apply phases, where the values are likely to not be known yet.
The two primary situations that I and others have run into are:
- Interpolating into provider configuration blocks, as I described in #2976. This is allowed by Terraform but fails in unintuitive ways when a chicken-and-egg problem arises.
- Interpolating into the
countmodifier on resource blocks, as described in #1497. Currently this permits only variables, but having it configurable from resource attributes would be desirable.
After a number of false-starts trying to find a way to make this work better in Terraform, I believe I've found a design that builds on concepts already present in Terraform, and that makes only small changes to the Terraform workflow. I arrived at this solution by "paving the cowpaths" after watching my coworkers and I work around the issue in various ways.
The crux of the proposal is to alter Terraform's workflow to support the idea of _partial application_, allowing Terraform to apply a complicated configuration over several passes and converging on the desired configuration. So from the user's perspective, it would look something like this:
$ terraform plan -out=tfplan
... (yada yada yada) ...
Terraform is not able to apply this configuration in a single step. The plan above
will partially apply the configuration, after which you should run "terraform plan"
again to plan the next set of changes to converge on the given configuration.
$ terraform apply tfplan
... (yada yada yada) ...
Terraform has only partially-applied the given configuration. To converge on
the final result, run "terraform plan" again to plan the next set of changes.
$ terraform plan -out=tfplan
... (yada yada yada) ...
$ terraform apply
... (yada yada yada) ...
Success! ....
For a particularly-complicated configuration there may be three or more apply/plan cycles, but eventually the configuration should converge.
terraform apply would also exit with a predictable exit status in the "partial success" case, so that Atlas can implement a smooth workflow where e.g. it could immediately plan the next step and repeat the sign-off/apply process as many times as necessary.
This workflow is intended to embrace the existing workaround of using the -target argument to force Terraform to apply only a subset of the config, but improve it by having Terraform itself detect the situation. Terraform can then calculate itself which resources to target to plan for the maximal subset of the graph that can be applied in a single action, rather than requiring the operator to figure this out.
By teaching Terraform to identify the problem and propose a solution itself, Terraform can guide new users through the application of trickier configurations, rather than requiring users to either have deep understanding of the configurations they are applying (so that they can target the appropriate resources to resolve the chicken-and-egg situation), or requiring infrastructures to be accompanied with elaborate documentation describing which resources to target in which order.
Implementation Details
The proposed implementation builds on the existing concept of "computed" values within interpolations, and introduces the new idea of a graph nodes being "deferred" during the plan phase.
Deferred Providers and Resources
A graph node is flagged as _deferred_ if any value it needs for refresh or plan is flagged as "computed" after interpolation. For example:
- A provider is _deferred_ if any of its configuration block arguments are computed.
- A resource is _deferred_ if its
countvalue is computed.
Most importantly though, a graph node is always deferred if _any_ of its dependencies are deferred. "Deferred-ness" propagates transitively so that, for example, any resource that belongs to a deferred provider is itself deferred.
After the graph walk for planning, the set of all deferred nodes is included in the plan. A _partial plan_ is therefore signaled by the deferred node set being non-empty.
Partial Application
When terraform apply is given a partial plan, it applies all of the diffs that are included in the plan and then prints a message to inform the user that it was partial before exiting with a non-successful status.
Aside from the different rendering in the UI, applying a partial plan proceeds and terminates just like an error occured on one of the resource operations: the state is updated to reflect what _was_ applied, and then Terraform exits with a nonzero status.
Progressive Runs
No additional state is required to keep track of partial application between runs. Since the state is already resource-oriented, a subsequent refresh will apply to the subset of resources that have already been created, and then plan will find that several "new" resources are present in the configuration, which can be planned as normal. The new resources created by the partial application will cause the set of deferred nodes to shrink -- possibly to empty -- on the follow-up run.
Building on this Idea
The write-up above considers the specific use-cases of computed provider configurations and computed "count". In addition to these, this new concept enables or interacts with some other ideas:
- #3310 proposed one design for supporting "iteration" -- or, more accurately, "fan out" -- to generate a set of resource instances based on data obtained elsewhere. This proposal enables a simpler model where
foreachcould iterate over arbitrary resource globs or collections within resource attributes, without introducing a new "generator" concept, by deferring the planning of the multiple resource instances until the collection has been computed. - #2976 proposed the idea of allowing certain resources to be refreshed immediately, before they've been created, to allow them to exist during the initial plan. Partial planning reduces the need for this, but supporting pre-refreshed resources would still be valuable to skip an iteration just to, for example, look up a Consul key to configure a provider.
- #2896 talks about rolling updates to sets of resources. This is not directly supported by the above, since it requires human intervention to describe the updates that are required, but the UX of running multiple
plan/applycycles to converge could be used for rolling updates too. - The cycles that result when mixing
create_before_destroywith not, as documented in #2944, could get a better UX by adding some more cases where nodes are "deferred" such that the "destroy" node for the deposed resource can be deferred to a separate run from the "create" that deposed it. - #1819 considers allowing the
providerattribute on resources to be interpolated. It's mainly concerned with interpolating from variables rather than resource attributes, but the partial plan idea allows interpolation to be supported more broadly without special exceptions like "only variables are allowed here", and so it may become easier to implement interpolation of provider. - #4084 requests "intermediate variables", where computed values can be given a symbolic name that can then be used in multiple places within the configuration. One way to support this would be to allow variable defaults to be interpolated and mark the variables themselves as "deferred" when their values are computed, though certainly other implementations are possible.
 apparentlymart
apparentlymart
All 49 comments
@phinze this proposal brings together several discussions we've had elsewhere and provides a new take on the "static vs. dynamic" problem that seems to be a common theme in Terraform supporting more complex use-cases.
I'd love to work on something in this vein early next year if you guys think this is a reasonable direction to take, but given the work involved I'd love to hear your thoughts before I get stuck in to implementation.
apparentlymart
on 3 Dec 2015
I could see this being very helpful, and a nice way to simplify situations where we are sometimes otherwise a bit stuck with one or another limitation.
 ketzacoatl
on 3 Dec 2015
ketzacoatl
on 3 Dec 2015
Thanks for this - as usual! - wonderfully clear write up, @apparentlymart. :grinning:
This solution does seem flexible and fairly straightforward conceptually. As I'm sure you'd agree, introducing the possibility of partial plans / applies would be a pretty central modification to Terraform's workflow, so it deserves careful scrutiny.
You have shown how partial progress could enable more complex configurations, but I'm worried about the cost to the general UX of the tool. The usage pattern would go from from two well-defined discrete steps to "just keep retrying until it goes through."
One of Terraform's most important qualities is in its ability to predict the actions it's going to take. This feature proposes to trade off Terraform's prediction guarantees to enable previously impossible configs, or in other words "enable Terraform to automate configurations it cannot predict (in one step)."
At this point, Partial Applies feels like a heavy hammer to wield before addressing some of the more specific pain points you mention like:
- Looking into getting read-only resources pushed earlier #2976
- Supporting variable interpolation in provider config #1819
However these are just my initial thoughts - I'll keep thinking and we can keep discussing!
 phinze
on 4 Dec 2015
phinze
on 4 Dec 2015
Thanks for the feedback. It's certainly what I was expecting, and echoes my own reservations about the design.
My rationale for proposing it in spite of those reservations was to observe that users are already effectively doing this workflow to work around what I perceive to be some flaws in Terraform's "ideal" model of being able to operate in a single step.
Here are two workarounds that my team is doing regularly, and that I've seen recommended to others running into similar problems:
- Use
-targetto force the creation of a particular resource before the others in order to break a chicken/egg problem around provider dependencies. This is a one-off resolution that we most often use to hack around a chicken/egg problem caused by an error during a Terraform run. - Creating multiple, entirely separate root configuration modules that need to be applied in a particular sequence to produce an infrastructure that Terraform would otherwise fail to implement in a single step.
terraform_remote_stateis used to string them together. In this case the workaround gets baked into the architecture because otherwise almost every run would require the above-targetworkaround.
Something like #2976 certainly reduces the cases where this is necessary, but not to zero. Consider for example the use-case of spinning up a Rundeck instance as an aws_instance, then using the rundeck provider to write jobs into it. On the first run, starting from nothing, this is fine: we can delay instantiating the rundeck provider until the aws_instance is complete. The problem arises any time the Rundeck instance is respun: now there is the risk that we get ourselves into the situation where the Rundeck server isn't running but Terraform still needs it to refresh the extant rundeck_project and rundeck_job resources in the state. This problem and various problems of this type have tripped me and my co-workers up frequently, each time forcing us to apply the workarounds I described above. Terraform could smooth this situation by noting that the rundeck provider depends on the EC2 instance that doesn't currently exist, and thus deferring the refresh/plan of those resources until the aws_instance has been recreated.
Thus I have concluded that "Terraform can plan everything" is a nice ideal, but it doesn't seem to stand up to reality. This proposal basically embraces the -target workaround and makes it a first-class workflow in order to get as close as possible to the ideal: while Terraform _can't_ plan everything in a single step, you _can_ rely on it to be explicit about what it will do every step of the way and guide the user towards convergence on the desired outcome.
I'd consider this a big improvement over the current situation, where quite honestly my coworkers lose confidence in Terraform every time I have to guide them through a manual workaround to a problem like I've described here, since it feels like hacking around the tool rather than working with it, and they (quite rightly) consider what would happen if they found themselves in such a situation in the middle of the night during an incident and were forced to create a workaround on the fly, working solo.
I think it'd be important to couple this architectual shift with the continued effort to have Terraform detect as many errors as possible at plan time, so that errors during terraform apply are rare and thus it is less likely that you would find yourself "stranded" in the middle of a multi-step application process. (#4170 starts to address this.)
I also think that it's important that Terraform describe the "I need multiple steps" situation very well after a plan, so that users can make an informed decision about whether to proceed with the multi-step process or whether to rework/simplify their configuration to not require it, if the "plan everything in one step" guarantee is important to them and they aren't willing to risk that step 2 might not be what they expected.
With all of that said, I'm just trying to directly address your initial feedback and hopefully aid your analysis; I totally agree that this is a significant change that requires scrutiny, and am happy to let this soak for a while.
apparentlymart
on 4 Dec 2015
This helps a lot, Martin, and it's very persuasive!
I agree that forcing users to -target their way out of a scenario is in no way acceptable and indeed erodes confidence in Terraform as a tool.
I have been silently wondering if Terraform should just encourage separation between "unplannable boundaries" into separate configs, but reading your description:
Creating multiple, entirely separate root configuration modules that need to be applied in a particular sequence to produce an infrastructure
It does seem perhaps too tedious and clunky to be a "recommended architecture".
I'll let this bounce around my brain over the weekend and follow up next week. :beers:
phinze
on 5 Dec 2015
This is a lot like something I've been bouncing around with @phinze for awhile. Good to see this to start being formalized a bit more. I actually called this something like "phased graphs" or something terrible, but partial apply makes more sense.
I think internally what we do is actually separate various graph nodes into "phases". Each phase on its own should be its own completely cycle free thing. It has various semantic checks such as: it can only depend on things from phase N or N-1, and it can't contain any cycles within it.
Detecting when a phase increase needs to happen uses the rules you outlined above: computed dependency from a provider, or a computed count.
Then for plan output we note the various phases that exist, and when you run it, we just increment the phase count, then you can plan the next phase, etc etc. Does this make sense?
 mitchellh
on 15 Dec 2015
mitchellh
on 15 Dec 2015
On second thought, we can probably make this a lot simpler: we detect when we have what I described above as "phase change" and just stop the plan/apply there, notifying the user that another run is required to continue forward. Once an apply is done then re-running it on the whole thing shouldn't affect things.
I can see the benefit of making this a more stateful operation but that is something we can do as an improvement later. The idea in the former paragraph can introduce partial applies while not having any huge UX change.
mitchellh
on 15 Dec 2015
I sort of use -target in an attempt to limit terraform to "phases". I recently noticed this would still try to rm / delete some resources if TF deemed necessary (even nodes outside the "target").
ketzacoatl
on 16 Dec 2015
@mitchellh Thanks for that feedback. It's great to hear how you're thinking about this.
Considering your first comment about planning multiple phases, I believe it's not possible for Terraform to plan the full set of apply steps in all cases. Consider the scenario where the provider configuration is computed: we then can't refresh/diff any resources belonging to that provider. I think the best we could do is note in the output that we're deferring certain resources, but I expected that would make the output rather noisy... seems like a good thing to learn via some prototyping.
I think your second comment describes what I had originally tried to propose: go as far as possible, let the user know it's not complete, and then let them re-plan to move to the next step. For me, marking a node as "deferred" was what you called "phase change", assuming I understand correctly. In my approach there are only two "phases" for a given plan: "planned" or "deferred". At each "apply" the state is updated, without having to retain anything new in the state file, just like we'd do if there was an error during the apply phase.
I'm hoping to spend some time prototyping this in the new year. I think it will be easier to talk about the details of this with a strawman implementation to tear apart.
apparentlymart
on 16 Dec 2015
@apparentlymart I don't think I was clear enough, but I think we're agreeing.
Only the current phase would be planned (contain a diff). The rest is a no-op, but may have to have some logic associated about it upstream, probably not downstream in the graph (in order to get the state to read things).
mitchellh
on 16 Dec 2015
From the peanut gallery:
I'm very relieved to find this thread, and just wanted to offer the perspective of a newbie user in love with this idea, but running into horrible chicken and egg roadblocks trying to spin up what should be a fairly simple AWS VPC.
At this point, after hours (actually days) of trying to manually pull out parts of configs and then put them back in to work around these chicken and egg scenarios that terraform is supposed to handling for me , terraform's state seems so confused to be moribund. Whereas before, I had a working environment, now I can't even figure out how to fix terraforms state to make it understand what's actually there - as it seems totally confused about that now, no doubt due to all my fiddling. I guess I just rip the entire thing out and start from scratch now? Will it even be ale to do that at this point?
If I were already a terraform expert - no doubt I'd recognize typical patterns, and know how to work around them as your remarkably named colleague, apparentlymart, can. But as a novice to your tech, I wouldn't even know where to begin. As he observed above, I am so addled by the experience, given how simple this environment is, that I would be terrified to even try to use this magic on anything remotely complex, and would never dream of suggesting some of my even less mart colleagues try.
The thought of making some minor change to my environment that, basically, completely borks it and leaves me not even knowing what the state is - is the stuff of nightmares, quite literally.
That does seem to be a problem. I am not as mart as apparentlymart, but it seems obvious that having a single pass in a system which must rely on future states for the data to support subsequent steps, is one of those magical ideas that looks great in theoretical language about phase state... but, basically, must fail in practice.
Again, I'm not remotely as mart as any of you, and that's why I'm trying to help you see that mere mortals have a hard time seeing how this reduces effort - quite to the contrary - I can manually make a VPC with a functioning vyetta node in a about fifteen minutes, and not be terrified that the smallest change will take my business offline.
Sorry for the long read and degree of frustration in tone - I have been at this, as I said, for days. And these tools are exciting! I'll be watching as it becomes something predictable and usable.
 erich-comsIO
on 16 Dec 2015
erich-comsIO
on 16 Dec 2015
Quick follow-up as an example - my most recent plan was hanging when applying trying to delete a network interface.. it would eventually time out and not report the details of the failure beyond that it timed out.
The problem ended up being that I had manually created an instance on that subnet, and so AWS was refusing to delete the subnet prior to deleting the dependent instance/interface.
1) I doubt the AWS API timed out rather than returning the same error it did in the console when I manually tried to delete the subnet.
2) I thought terraform was supposed to recognize manually induced dependencies against the plan and deal with them, no?
So - not a huge deal, obviously, and not a chicken and egg scenario - but an example of the sort of workflow detritus that gets really frustrating in repetition.
Again - I'm a huge fan, and don't expect a zero learning curve experience. Just offering the novice perspective. Thanks for the project and all your efforts!
erich-comsIO
on 16 Dec 2015
@erich-comsIO, there are a few assumption one should make, or allow Terraform to make (such as, let Terraform manage its space and interfere as little as possible), and you will run into these types of issues less often. It takes time, sharing, and sometimes bug squashing to improve that learning curve. I have run into similar issues and circular dependencies with template_file, subnets, security groups, etc. Part of this is also due to nuances with the provider, the AWS console smooths out the experience in many ways you do not realize until using Terraform.
Are you able to connect to #terraform-tool on freenode IRC? I would be happy to help you through some of these types of issues. The mailing list is also a great place for this discussion, this ticket will quickly spin out of control if we veer too far away from the central discussion.
ketzacoatl
on 16 Dec 2015
Thanks for the reply and offer of help. Very much appreciated. I’m about to jump into a meeting, but will start hanging out in the irc channel. I do get that I need to stay out of the way as much as possible and let it do its thing. But then I run into these circular dependency issues. I gather I need to start using —target to manage those things terraform seems unaware of or unable to track at AWS regarding these kinds of dependencies.
Departing this thread, and will ask my noob questions in new topics.
Thanks again!
On Dec 16, 2015, at 10:49 AM, ketzacoatl [email protected] wrote:
@erich-comsIO https://github.com/erich-comsIO, there are a few assumption one should make, or allow Terraform to make (such as, let Terraform manage its space and interfere as little as possible), and you will run into these types of issues less often. It takes time, sharing, and sometimes bug squashing to improve that learning curve. I have run into similar issues and circular dependencies with template_file, subnets, security groups, etc. Part of this is also due to nuances with the provider, the AWS console smooths out the experience in many ways you do not realize until using Terraform.
Are you able to connect to #terraform-tool on freenode IRC? I would be happy to help you through some of these types of issues. The mailing list is also a great place for this discussion, this ticket will quickly spin out of control if we veer too far away from the central discussion.
—
Reply to this email directly or view it on GitHub https://github.com/hashicorp/terraform/issues/4149#issuecomment-165151842.
erich-comsIO
on 16 Dec 2015
A follow up idea, building on this proposal: Terraform will usually happily propagate computed values through the graph as things are created, which means the initial diff often has a whole lot of raw interpolations that don't get resolved until apply time. This also means that certain validations can't be done until apply time, since the value to validate isn't yet known.
With partial apply support it becomes possible to offer a -conservative flag (suggestions for better names are welcome) that will make Terraform defer any resource that has at least one computed attribute, so the config would then be applied across more steps but with the benefit that at every step it is possible to completely inspect all of the values, both against human intuition and against Terraform's built-in validation rules. This would complement the new capability offered by #4348 in allowing Terraform to do more extensive plan-time validation than is possible today.
I often "fake" -conservertive using -target when I'm applying a particularly-complex configuration, or one where extended downtime due to manual error recovery would be bothersome.
I wouldn't tackle this immediately when implementing this feature, but I think this is a further use-case for having the infrastructure to allow partial plan/apply.
apparentlymart
on 17 Dec 2015
@apparentlymart Another good idea, but I'd make the same cautious viewpont as above: let's treat that as a separate idea once we do this one.
mitchellh
on 17 Dec 2015
This is definitely causing us issues.
A terraform refresh returns the issue mentioned, as the Rancher Server URL is generated via the private IP returned from a rancher-server (an aws_instance) module, this is then passed into a rancher-init module with calls the rancher provider.
Error refreshing state: 1 error(s) occurred:
* Get /v1: unsupported protocol scheme ""
Steps to reproduce:
- Create AWS Infrastructure/subnets/vpc e.t.c.
- Bring up rancher server via module
- Given rancher-server, init rancher server via rancher provider using the outputs from rancher-server module
If the aws_instance rancher-server is created first, and then we un-comment the second half of our plan everything is happy.
As a sidenote: On destroy, we also get cyclic dependencies due to the provider requiring the Instance Private IP for the URL generation, plus the rancher hosts, which require the rancher token and private IP of the server.
 matthewhartstonge
on 19 Feb 2017
matthewhartstonge
on 19 Feb 2017
Is there any update on this?
I've just started working with Terraform and I think that I've run straight into this issue... I want to define an AWS RDS instance and then provision with databases using the MySQL provider, but "terraform plan" fails because it doesn't understand that the remote MySQL instance for the databases does not exist yet.
 stuartellis
on 8 May 2017
stuartellis
on 8 May 2017
@apparentlymart, I'm wondering if at least some of the operational pressure could be taken off by a simpler(?) approach of exporting the count attribute of each resource, e.g.
resource "aws_internet_gateway" "foo" {
count = "${var.aws_account_name == "<redacted>" && !var.is_dr_region ? "1" : var.is_region_serving}"
[...]
}
resource "aws_eip" "foo_nat" {
count = "${aws_internet_gateway.foo.count > 0 ? [...] : [...]}"
[...]
}
Since count in this case can be calculated/known at plan time, and doesn't require creating resources to fill out data structures such that length(aws_internet_gateway.foo.*.id) > 0 (my original attempt) would work, I'd bet this could be implemented relatively quickly compared to refactoring the Terraform planner to have multiple phases.
I haven't scanned all of the various resources to see if any of them already export an attribute called count, or if it would need to be called something like terraform_count to avoid collisions.
Thoughts?
(Update: To be clear, this would only help with https://github.com/hashicorp/terraform/issues/1497 and related (I came here from https://github.com/hashicorp/terraform/issues/10857, FWIW), not https://github.com/hashicorp/terraform/issues/2976, but even simply fixing just the former seems like it would make lives easier.)
 handlerbot
on 29 Sep 2017
handlerbot
on 29 Sep 2017
Hi @handlerbot,
We do already export count like that, but I think due to some limitations in Terraform's internals it still ends up showing as computed today because of the standing rule that a list containing computed values is itself entirely computed, and thus its length is unknown. (I didn't actually test this, so I'm relying on my memory here; I may be mis-remembering the exact details for why this doesn't work as expected.)
You're right that in principle the count _should_ be known immediately, and hopefully this will work better as a natural consequence of the big configuration language revamp we're embarking on now. It will take a little time for us to have updated enough parts of Terraform for this benefit to percolate, but I don't _think_ we need to do anything additional to what was already planned in order for aws_internet_gateway.foo.count to evaluate the way you intended here; we'll see as we get a bit further down the line and have enough updates in place to try it out.
apparentlymart
on 2 Oct 2017
I think, 2017 is a great year, to reverberate on this and induce traction. I learned about my own opaque issue by writing "partial terraform apply" into google search. Despite all valid concerns, I read above, it seems to me the natural solution, my brain was intuitively seeking for. At least, that's what happened in my case.
 blaggacao
on 23 Oct 2017
blaggacao
on 23 Oct 2017
I just ran into this issue this weekend while trying to create a DigitalOcean droplet with a Docker image, then trying to take the droplet IP and pass it to the Docker provider to deploy containers. As stated above, the lack of this feature and the hackiness of using -target does indeed erode confidence in the tool for me, but I can't speak to the rest of the DevOps team. I hope this gets some traction soon!
 icornett
on 23 Oct 2017
icornett
on 23 Oct 2017
Hi,
I ran into this issue as well and is becoming a huge stop gap. Here is my use case,
module "kube_provision" {}
module "kube_install" {}
module "ops" {}
My kubernetes environment is not available until I finish applying kube_install. I want the kubernetes provider initiation wait until this happens and the use kubernetes provider in module.ops to deploy applications. I tried to use the hack (-target) but it weirdly refreshes the existing states and creates additional resources and is not a consistent behavior.
Great tool and would love to have this feature available soon.
 pycaster
on 15 Nov 2017
pycaster
on 15 Nov 2017
I would like to be able to do something similar, i.e. deploy Kubernetes on AWS, then deploy things to Kubernetes. I could imagine a scenario whereby I deploy something to Kubernetes which is further configured by Terraform, i.e. Grafana, or PostgreSQL, etc. so there's at least three potential separate runs which I might ideally want to be flattened into one.
 bodgit
on 15 Nov 2017
bodgit
on 15 Nov 2017
Not only different runs but my understanding is that some kubernetes resources even need to be manually refreshed / tainted for Terraform to rerun them on the new cluster.
 rochdev
on 15 Nov 2017
rochdev
on 15 Nov 2017
My team and I are also blocked from a potentially single step terraform apply due to this issue. The first apply results in this error:
aws_route.to_legacy: aws_route.to_legacy: value of 'count' cannot be computed
Our less than elegant workaround is to comment out this block before initial apply, and then reapply:
// needs to be commented out before initial apply
resource "aws_route" "to_legacy" {
route_table_id = "${module.network.private_subnet_route_table_ids[count.index]}"
count = "${length(module.network.private_subnet_route_table_ids)}"
destination_cidr_block = "${var.legacy_cidr}"
vpc_peering_connection_id = "${aws_vpc_peering_connection.peer_with_legacy.id}"
}
This is obviously not ideal. We are on Terraform v0.10.8, the latest at time of writing. Hope it gets resolved soon!
 sinzin91
on 15 Nov 2017
sinzin91
on 15 Nov 2017
I just ran into this with the following setup.
module "kea_db" {
source = "../../modules/aws_rds_mysql"
env_type = "${lower(var.env_type)}"
product = "${lower(var.product)}"
application = "${lower(var.application)}"
component = "${lower(var.component)}"
region = "${lower(var.region)}"
provider = "${lower(var.provider)}"
subnet_ids = "${data.consul_keys.subnets.var.core_private_subnet_ids}"
db_username = "${lower(var.db_username)}"
db_password = "${var.db_password}"
multi_az = "${var.multi_az}"
}
# MySQL provider
provider "mysql" {
endpoint = "${module.kea_db.db_endpoint}"
username = "${var.db_username}"
password = "${var.db_password}"
}
resource "mysql_database" "db" {
count = "${length(split(",", var.databases))}"
name = "${element(split(",", var.databases), count.index)}"
depends_on = [ "module.kea_db" ]
}
output "db_friendly_cname" {
value = "${module.kea_db.db_friendly_cname}"
}
output "db_host_address" {
value = "${module.kea_db.db_host_address}"
}
output "db_port" {
value = "${module.kea_db.db_port}"
}
output "db_name" {
value = "${module.kea_db.db_name}"
}
output "db_username" {
value = "${module.kea_db.db_username}"
}
module source
data "null_data_source" "hostname" {
inputs = {
name = "${var.env_type}-${var.application}-${var.component}"
}
}
data "null_data_source" "role" {
inputs = {
name = "${var.application}-${var.component}"
}
}
resource "aws_db_subnet_group" "db_subnet_group" {
name = "${var.env_type}-${var.application}-dbsg"
subnet_ids = ["${split(",",var.subnet_ids)}"]
tags {
Name = "${var.env_type}-${var.application}-dbsg"
}
}
resource "aws_db_parameter_group" "db_parameter_group" {
name = "${var.env_type}-${var.application}-dbpg"
family = "mysql5.6"
parameter {
name = "character_set_server"
value = "utf8"
}
parameter {
name = "character_set_client"
value = "utf8"
}
}
resource "aws_kms_key" "db_kms_key" {
description = "${var.env_type}-${var.application}-${var.component} Encryption Key"
deletion_window_in_days = 14
enable_key_rotation = true
}
resource "aws_kms_alias" "db_kms_alias" {
name = "alias/${var.env_type}-${var.application}"
target_key_id = "${aws_kms_key.db_kms_key.id}"
}
resource "aws_db_instance" "db_mysql" {
allocated_storage = 10
storage_type = "gp2"
engine = "mysql"
engine_version = "5.6"
instance_class = "db.t2.small"
name = "${var.env_type}_${replace(var.application, "-", "_")}_${var.component}"
identifier = "${var.env_type}-${var.application}-${var.component}"
username = "${var.db_username}"
password = "${var.db_password}"
db_subnet_group_name = "${aws_db_subnet_group.db_subnet_group.name}"
parameter_group_name = "${aws_db_parameter_group.db_parameter_group.name}"
storage_encrypted = true
kms_key_id = "${aws_kms_key.db_kms_key.arn}"
auto_minor_version_upgrade = false
final_snapshot_identifier = "${var.env_type}-${var.application}-${var.component}-final"
multi_az = "${var.multi_az}"
vpc_security_group_ids = ["${data.consul_keys.sg.var.allow_mysql}"]
tags {
Name = "${var.env_type}-${var.application}-${var.component}"
Environment = "${lower(var.env_type)}"
Product = "${lower(var.product)}"
Application = "${lower(var.application)}"
Component = "${lower(var.component)}"
Region = "${lower(var.region)}"
Provider = "${lower(var.provider)}"
}
}
data "aws_route53_zone" "private-domain" {
name = "aws.domain.com."
private_zone = true
}
resource "aws_route53_record" "db_cname" {
zone_id = "${data.aws_route53_zone.private-domain.id}"
type = "CNAME"
ttl = "60"
records = ["${aws_db_instance.db_mysql.address}"]
name = "${var.env_type}-${var.application}-${var.component}.${var.region}.${data.aws_route53_zone.private-domain.name}"
}
output "db_endpoint" {
value = "${aws_db_instance.db_mysql.endpoint}"
}
output "db_friendly_cname" {
value = "${aws_route53_record.db_cname.name}"
}
output "db_host_address" {
value = "${aws_db_instance.db_mysql.address}"
}
output "db_port" {
value = "${aws_db_instance.db_mysql.port}"
}
output "db_name" {
value = "${aws_db_instance.db_mysql.name}"
}
output "db_username" {
value = "${aws_db_instance.db_mysql.username}"
}
output
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
data.null_data_source.role: Refreshing state...
data.null_data_source.hostname: Refreshing state...
data.consul_keys.subnets: Refreshing state...
data.consul_keys.sg: Refreshing state...
data.aws_route53_zone.private-domain: Refreshing state...
------------------------------------------------------------------------
Releasing state lock. This may take a few moments...
Error running plan: 1 error(s) occurred:
* provider.mysql: dial tcp 127.0.0.1:3306: getsockopt: connection refused
 pryorda
on 28 Nov 2017
pryorda
on 28 Nov 2017
@apparentlymart in your previous comment you mention "the big configuration language revamp we're embarking on now.". Is this an official line of work that has started already? Do we have some visibility into it? It might be helpful for some to have in idea of the direction we'll follow for this work.
I personally I'm looking into reshaping a terraform project that accumulated complexity (due to module not having count, lack of support for advanced data structures or this issue which multi phase deployments); knowing where we're going would allow me to steer the refactoring in order to make the incoming transition easier (and I suppose other people would be in a similar position).
All the aforementioned issues have a common root problem which is that they are fundamental changes in the terraform language design, so I would applaud this initiative as it would fix some of the most common issues people face as they are growing their Terraform infra.
 ColinHebert
on 25 Dec 2017
ColinHebert
on 25 Dec 2017
Hi @ColinHebert! Sorry I didn't see your comment here earlier.
Unfortunately there isn't currently a central description of all of the config language changes because it spans over many separate GitHub issues covering different aspects, and we don't yet know to what extent it will be addressed in the first round vs. follow-up changes. It is unlikely that count for modules will come in the first pass because that requires a very big shift in Terraform's internal models, but we do plan to address it eventually. I'm not sure what specifically you mean when you say "advanced data structures" but the new language interpreter (which is currently living in a repo codenamed "HCL2" while we polish/finalize it) has a more robust type system which will, over time, be reflected in all of Terraform's features, including module variables and outputs.
If you have some specific concerns you'd like to discuss I'd be happy to go into more detail with you in separate github issues; this one has a lot of followers so I'd prefer not to get into a tangential discussion here to reduce notification noise for those people. It's likely that some of your concerns already have open issues, but I know there's a lot out there so if you happen to propose or ask about something that's already covered by another issue I'm happy to dig up any existing issues and consolidate.
apparentlymart
on 22 Feb 2018
We created a mock for a potential UI flow here as part of exploring future needs in the current configuration language project:
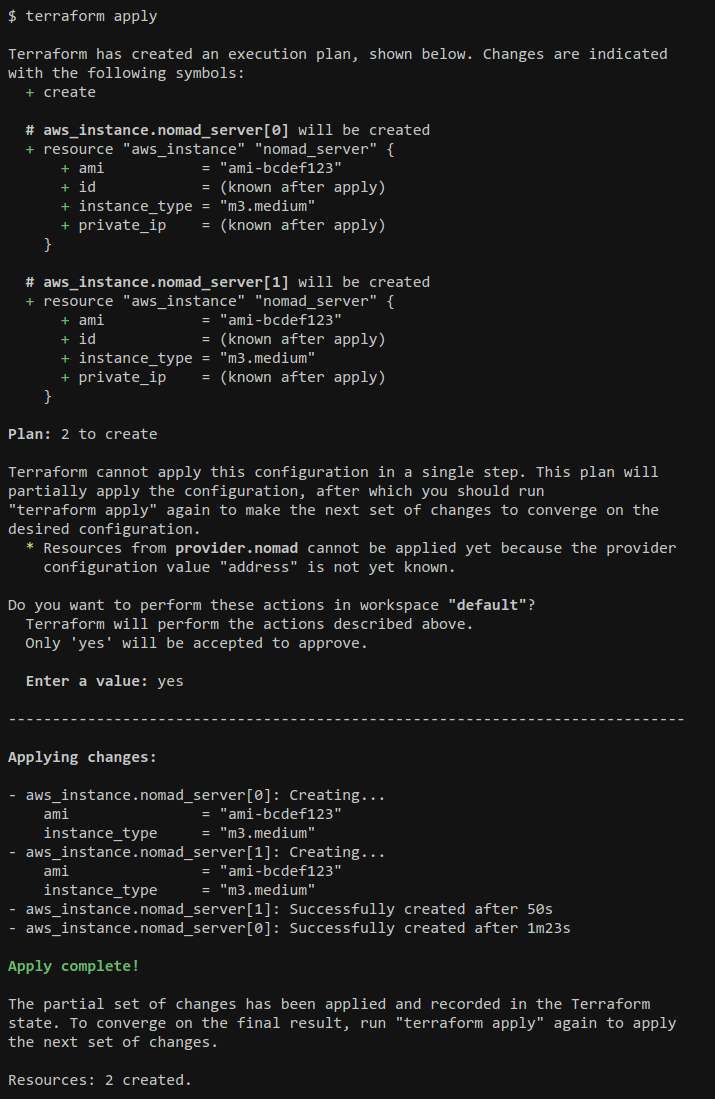
With the Terraform team at HashiCorp currently focused on configuration language improvements, no implementation work is going on for this yet, but we're keeping it in mind during the current project so that we can take opportunities to lay groundwork for it to be added in future.
apparentlymart
on 14 May 2018
I wanted to add my +1 to the issue.
The relevant TF / my case:
resource "aws_route53_record" "ipv6" {
count = "${length(aws_instance.my_instance.ipv6_addresses) > 1 ?length(aws_instance.my_instance.ipv6_addresses) : 0}"
}
For a variety of reasons, i can't afford to break my TF runs into multiple targets. Although, i am glad to have learned about this functionality.
My situation is relatively trivial, but it did get me wondering about two things:
How feasible is it to set a "OR" value for the count? It's either
unknownOR0. I understand that i would need totf applyagain in order to create the dependent resource (after theaws_instanceis created, state-file will have updated data which makes the count "knowable" and the previous value of 0 would be updated and the dependent resource (aws_route53_record) would be created as expected. many runs to finally converge is fine; different CLI arguments _per_ terraform run are not going to work.By using a computed value from the
aws_instancein the properties of theaws_route53_record, terraform already knows that any API calls w/r/t the r53 record can't be issued until some data about theaws_instanceis received from amazon. The same would be true for creating a security group and then assigning it to an instance; the ID of the SG must be known before the call to associate the two can be made. What is it about the use ofcountin this context that requires the value to be known ahead of time when so many other aspects of terraform already understand that a pending API call depends on data yet to be received from amazon?
Mean time, i've used one of the many workarounds i discovered:
resource "aws_route53_record" "ipv6" {
count = "${var.ipv6_create_r53_entry ? 1:0}"
}
 karl-tpio
on 30 Nov 2018
karl-tpio
on 30 Nov 2018
I'd like to emphasize the importance of "CI user experience" in regards to the proposed solution. We run terraform exclusively in non-interactive CI environments, and sporadically requiring commands to be ran twice does not sound very CI-friendly.
The message at the end of the partial apply says to rerun "terraform apply", but I assume that reusing the first plan's plan file for the second apply command would fail, so we would need to rerun the plan job to generate a new plan file, then run the apply on the new plan file. This adds significant complication to our CI pipeline setup.
At the very least some sort of detailed exit code that we can check for to rerun the entire pipeline again, but it could still lead to a confusing CI experience - seeing a job was successful but the resources were not created and having to dig into the job output to find that only a subset of resources were created and that a second pipeline is being ran. Users may not fully understand why a second pipeline is required and would not know to check for it.
I do appreciate that this limitation is being addressed!
 rifelpet
on 4 Dec 2018
rifelpet
on 4 Dec 2018
That is indeed an area where we will need to do further investigation to find the best compromise, @rifelpet.
The proposal as I wrote it now several years ago is assuming that a partial apply is, in effect, a funny sort of error case, and expecting that automation would deal with it in a similar way as for other errors. In many cases that is just marking the job as failed and requiring a human to come in and queue another run after reviewing the message, which is obviously not ideal but is the baseline we'd be starting from here.
Another assumption here is that this sort of thing would happen only during the initial bootstrapping of an environment where you're trying to go from nothing to all layers working at once. It is likely though that if we make this sort of multi-layer infrastructure easier to achieve then users will get more adventurous and start using this capability more widely, possibly making it more likely to encounter the need for a partial apply for an already-established environment.
When we get to doing the next detailed design for this we'll definitely be looking for ways we can improve on that baseline within the constraints provided by generic CI systems that may have fixed pipelines. Some CI systems allow for dynamic pipeline decisions, but that is not universal and would generally require a more complex configuration even if it _were_ possible.
apparentlymart
on 5 Dec 2018
Maybe this is overly simplistic, but maybe there could be a flag to terraform apply that (in the case of not passing a precomputed plan file) means "if the first apply is partial, try again"?
 glasser
on 10 Jan 2019
glasser
on 10 Jan 2019
I agree with @glasser there should be a CLI option to request terraform perform all the work, and error only on actual errors. Since (in theory) this multi-phase plan/apply could be endless, the option should accept a threshold, whereby (for example) the 20th "try again" is undesired and should be treated as a real error.
 cevich
on 25 Jan 2019
cevich
on 25 Jan 2019
I couldn't read the 4 years worth of notes, will we be able to have a calculated count field? any thoughts on possibly when? i saw notes saying 0.12-alpha but it doesn't look like that made it
 ooOOJavaOOoo
on 16 Oct 2019
ooOOJavaOOoo
on 16 Oct 2019
@ooOOJavaOOoo I used to have lots of issues with that on Terraform 0.11, but not a single one on Terraform 0.12.
 Sodki
on 19 Oct 2019
Sodki
on 19 Oct 2019
Feel silly asking- but its been over a year since that mock workflow was posted above, and that would certainly sand off the biggest current issue with terraform (in my mind at least) - where is this on the roadmap?
 pbecotte
on 20 Dec 2019
pbecotte
on 20 Dec 2019
@pbecotte this project has far more than 1k issues open. chances are very low this - and other things - will happen.
 gretel
on 20 Dec 2019
gretel
on 20 Dec 2019
An alternate approach would be to implement an orchestration feature around multiple terraform configs. Extract the computed elements into their own config, with their own state. Output the values needed by the next state. Use those outputs as variable inputs to the next state. A new terraform command/workflow could link these configs together in an orchestrated plan/apply/plan/apply cycle.
This is similar to the partial apply idea, but very intentional, declarative, and explicit about the inter-dependencies.
In some ways, this approach is a feature of terragrunt today.
 lorengordon
on 28 Mar 2020
lorengordon
on 28 Mar 2020
Any progress on this? We are hitting similar problems where, interestingly, on local or virtual machines the chaining works well with RKE and Kubernetes providers but on any CI the values from the RKE resource are not passed into Kubernetes, making CI kinda pointless there.
 muhlba91
on 10 Apr 2020
muhlba91
on 10 Apr 2020
Just went ahead and restructured all my projects. Split them into a bunch of seperated things. Wherever there is a provider that depends on the output of a previous step, I split it.
Have done both makefiles to run them all in order and individual ci projects for each of them chained together in a pipeline depending. It's not that bad, but it does go against the flow of how you assume things should be structured.
pbecotte
on 10 Apr 2020
How are we supposed to do multiple applies or targeted runs without undue iteration using e.g. Terraform Cloud/Enterprise, since they don't support these features?
Pushing a partial PR with commented out code, just to satisfy the simplicity of CI, then another PR to uncomment it, is ... unfortunate.
It also puts the burden of figuring out the dependencies on the author, which is not always clear.
 jspiro
on 26 Jun 2020
jspiro
on 26 Jun 2020
It is unbelievable that such a common use case still isn't fixed almost five years after it has been discovered. The fact that even a proposal has been written makes this much worse.
Just started using Terraform two week ago and this problem now almost stalls my progress completely. I generally like terraform and the way it solves things. This problem however is so annoying that I might consider switching to an alternative.
 FaustTobias
on 24 Nov 2020
FaustTobias
on 24 Nov 2020
@FaustTobias complaining about the lack of a solution to a problem and treatening to ditch the product in favor of others doesn't really add to the discussion or provide a way to a solution. Especially if all these products are free and open source, and the alternatives also don't really address the problem or add problems of their own.
 aequitas
on 25 Nov 2020
aequitas
on 25 Nov 2020
My solution currently is to queue multiple plans using the Terraform Cloud API. I specify the resource to update beforehand by setting the TF_CLI_ARGS_plan environment variable for the stack. Setting it to -target=resource_provider.resource_name for example, will only plan and apply the resource_provider.resource_name resource. This works but it - as many in the comments have pointed out - feels unintuitive in regards to usability.
After a short look into the source code, I think this problem occurs mostly when using the count and for_each meta-arguments, as those will create resources dynamically based on their input. If someone reading this wants to avoid this, try to not use those features.
@aequitas The proposal provided in this issue seems to provide a logical approach in my opinion, and all I initially wanted to know (though my wording definitely was not appropriate...) was whether or not this issue will still be addresses by some of the core developers of terraform. The project is open source, but there is still a corporation behind it with dedicated developers.
FaustTobias
on 25 Nov 2020
@Fabian-Schmidt fwiw, the issue with count/for_each is when terraform cannot determination the resource label in the plan phase. For count, this is the index. For for_each, this is each.key. With count, it will work if you can construct an expression to resolve the length of the list from variables or data sources (that do not themselves rely on resources). With for_each, it will work as long as your expression for each.key is similarly fully resolved at plan time. If you need more help with that, I'd recommend Hashicorp's Discuss forum, or the hangops or cloudposse slack channels.
When you can't construct your count/for_each expressions to work within that constraint, the current workarounds are to use -target (as you found), or to separate your config into two terraform states and pass the values from one to the other (using variables or remote terraform state).
lorengordon
on 25 Nov 2020
@FaustTobias complaining about the lack of a solution to a problem and treatening to ditch the product in favor of others doesn't really add to the discussion or provide a way to a solution. Especially if all these products are free and open source, and the alternatives also don't really address the problem or add problems of their own.
Let's not be so touchy. The world runs on open source, pulling out "free" when it's convenient to collapse a valid argument is hypocritical - and also not productive.
You're right - piling on about a porous deficiency that has lingered this long is certainly not providing a solution - and it wasn't likely an attempt at doing that; suggeting it's an attempt at letting the folks at Hashi know that this is causing insurmountable pain and requires a solution. I have been waiting for a module-level depends_on to resolve this, and lo! it doesn't.
 ret-aws
on 28 Nov 2020
ret-aws
on 28 Nov 2020
I had this issue when creating a service principal and it was driving me crazy even when I narrowed it down. I finally figured out this will stop the requirement of a target first. Here is the code that requires a target:
Key here is the movement of module.principal.service_principal_object_id
module resource-group {
source = "../terraform-azurerm-resource-groups"
resource-group-name = var.resource-group
spm-id = var.spm-id
owner = var.owner
application-name = var.application-name
cost-center = var.cost-center
lob = var.line-of-business
# These are optional object ids of groups that will be bound to each desired rg
rg-owners = distinct(concat(var.rg-owners, [module.principal.service_principal_object_id, data.azurerm_client_config.current.object_id]))
rg-contributors = distinct(var.rg-contributors)
rg-readers = distinct(var.rg-readers)
rg-vmadmin-login = distinct(var.rg-vmadmin-login)
rg-vmuser-login = distinct(var.rg-vmuser-login)
rg-vm-login = distinct(var.rg-vm-login)
}
The fix was to move it to it's own resource
module resource-group {
source = "../terraform-azurerm-resource-groups"
resource-group-name = var.resource-group
spm-id = var.spm-id
owner = var.owner
application-name = var.application-name
cost-center = var.cost-center
lob = var.line-of-business
# These are optional object ids of groups that will be bound to each desired role
rg-owners = distinct(concat(var.rg-owners, [data.azurerm_client_config.current.object_id]))
rg-contributors = distinct(var.rg-contributors)
rg-readers = distinct(var.rg-readers)
rg-vmadmin-login = distinct(var.rg-vmadmin-login)
rg-vmuser-login = distinct(var.rg-vmuser-login)
rg-vm-login = distinct(var.rg-vm-login)
}
resource azurerm_role_assignment contributor {
scope = data.azurerm_subscription.current.id
role_definition_name = "Contributor"
principal_id = module.principal.service_principal_object_id
}
 CrowderKroger
on 8 Dec 2020
CrowderKroger
on 8 Dec 2020
Related issues
 larstobi
·
3Comments
larstobi
·
3Comments
 jrnt30
·
3Comments
jrnt30
·
3Comments
 darron
·
3Comments
darron
·
3Comments
 rkulagowski
·
3Comments
rkulagowski
·
3Comments
 sprokopiak
·
3Comments
sprokopiak
·
3Comments
Most helpful comment
We created a mock for a potential UI flow here as part of exploring future needs in the current configuration language project:
With the Terraform team at HashiCorp currently focused on configuration language improvements, no implementation work is going on for this yet, but we're keeping it in mind during the current project so that we can take opportunities to lay groundwork for it to be added in future.