Terraform-provider-kubernetes: Intermittent failure with "kubernetes_namespace" resource - Get http://localhost/api/v1/namespaces/my-ns: dial tcp 127.0.0.1:80: connect: connection refused
Community Note
- Please vote on this issue by adding a 👍 reaction to the original issue to help the community and maintainers prioritize this request
- Please do not leave "+1" or other comments that do not add relevant new information or questions, they generate extra noise for issue followers and do not help prioritize the request
- If you are interested in working on this issue or have submitted a pull request, please leave a comment
Terraform Version and Provider Version
Terraform v0.12.24
provider.google v3.13.0
provider.kubernetes v1.11.1
Affected Resource(s)
kubernetes_namespace- the k8s cluster is in GKE launched with
google_container_clusterresource
Terraform Configuration Files
The GKE i created using the following
# the GKE cluster
resource "google_container_cluster" "k8s_cluster" {
# ...
private_cluster_config {
enable_private_nodes = true
enable_private_endpoint = false
master_ipv4_cidr_block = "172.16.0.0/28"
}
ip_allocation_policy { } # enables VPC-native
master_authorized_networks_config {
cidr_blocks {
{
cidr_block = "0.0.0.0/0"
display_name = "World"
}
}
}
# ...
}
# and then the GKE cluster node pool
resource "google_container_node_pool" "node_pool" {
# ...
cluster = google_container_cluster.k8s_cluster.name
# ...
}
Then i am calling the k8s namespace by the following
data "google_client_config" "google_client" {}
# following this example https://www.terraform.io/docs/providers/google/d/datasource_client_config.html#example-usage-configure-kubernetes-provider-with-oauth2-access-token
provider "kubernetes" {
version = "1.11.1"
load_config_file = false
host = google_container_cluster.k8s_cluster.endpoint
token = data.google_client_config.google_client.access_token
cluster_ca_certificate = base64decode(
google_container_cluster.k8s_cluster.master_auth.0.cluster_ca_certificate
)
}
resource "kubernetes_namespace" "namespaces" {
depends_on = [google_container_node_pool.node_pool]
for_each = ["my-ns"]
metadata {
name = each.value
}
}
And then i am running terraform apply SEVERAL times.
Expected Behavior
For the first run of terraform apply it should create everything normally with:
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
For every subsequent run of terraform apply it should refresh the states of all the resources like usual and then say:
No changes. Infrastructure is up-to-date.
Actual Behavior
The refresh of kubernetes_namespace namespace is failing intermittently - sometime it works sometimes it doesn't.
For the first run of terraform apply i got this all good: ✅✅✅
kubernetes_namespace.namespaces["my-ns"]: Creating...
kubernetes_namespace.namespaces["my-ns"]: Creation complete after 1s [id=my-ns]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
And then for the subsequent runs of terraform apply, it gets upto the refresh stage all fine: ✅✅✅
data.google_container_cluster.k8s_cluster: Refreshing state...
kubernetes_namespace.namespaces["my-ns"]: Refreshing state... [id=my-ns]
but then, either it passes or it fails _intermittently_ with the following error: ❌ ❌ ❌
Error: Get http://localhost/api/v1/namespaces/my-ns: dial tcp 127.0.0.1:80: connect: connection refused
Note that, this failuer is happenning _intermittently_. So it tells me that the public-private connectivity is fine. But then sometimes it's getting the connection sometimes it's not.
Where should i look into for this?
Steps to Reproduce
terraform apply
Important Factoids
My TFState file is in the GCS bucket. Not that it matters in this issue. But just FYI.
It's facing the following errors "intermittently"
# when creating
Error: Post http://localhost/api/v1/namespaces: dial tcp 127.0.0.1:80: connect: connection refused.
# when refreshing
Error: Get http://localhost/api/v1/namespaces/my-ns: dial tcp 127.0.0.1:80: connect: connection refused
# when deleting
Error: Delete http://localhost/api/v1/namespaces/my-ns: dial tcp 127.0.0.1:80: connect: connection refused
References
 syedrakib
syedrakib
All 12 comments
hello.... just checking in.
Anyone has any idea about this?
syedrakib
on 20 Apr 2020
hello... i have solved my problem adding load_config_file = false to my provider configuration
 andrecasacamapify
on 22 Apr 2020
andrecasacamapify
on 22 Apr 2020
i have also used load_config_file = false in my provider config. I stated that in my post also.
Were you facing intermittent failures as i wrote about?
syedrakib
on 22 Apr 2020
hey @syedrakib,
it seems you're querying private endpoint instead of the public one.
when you use enable_private_endpoint = false in private cluster config it means that it will create an additional public endpoint and you can get it from private_cluster_config[0].public_endpoint
try replacing host with google_container_cluster.k8s_cluster.private_cluster_config[0].public_endpoint so your config looks like the following snippet
provider "kubernetes" {
version = "1.11.1"
load_config_file = false
host = google_container_cluster.k8s_cluster.private_cluster_config[0].public_endpoint
token = data.google_client_config.google_client.access_token
cluster_ca_certificate = base64decode(
google_container_cluster.k8s_cluster.master_auth.0.cluster_ca_certificate
)
 vova-tarasov
on 23 Apr 2020
vova-tarasov
on 23 Apr 2020
Hi @vova-tarasov . I just check the TFState file and noticed that the value of google_container_cluster.k8s_cluster.private_cluster_config[0].public_endpoint and google_container_cluster.k8s_cluster.endpoint are exactly the same.
Hence, it's not querying the private_endpoint.
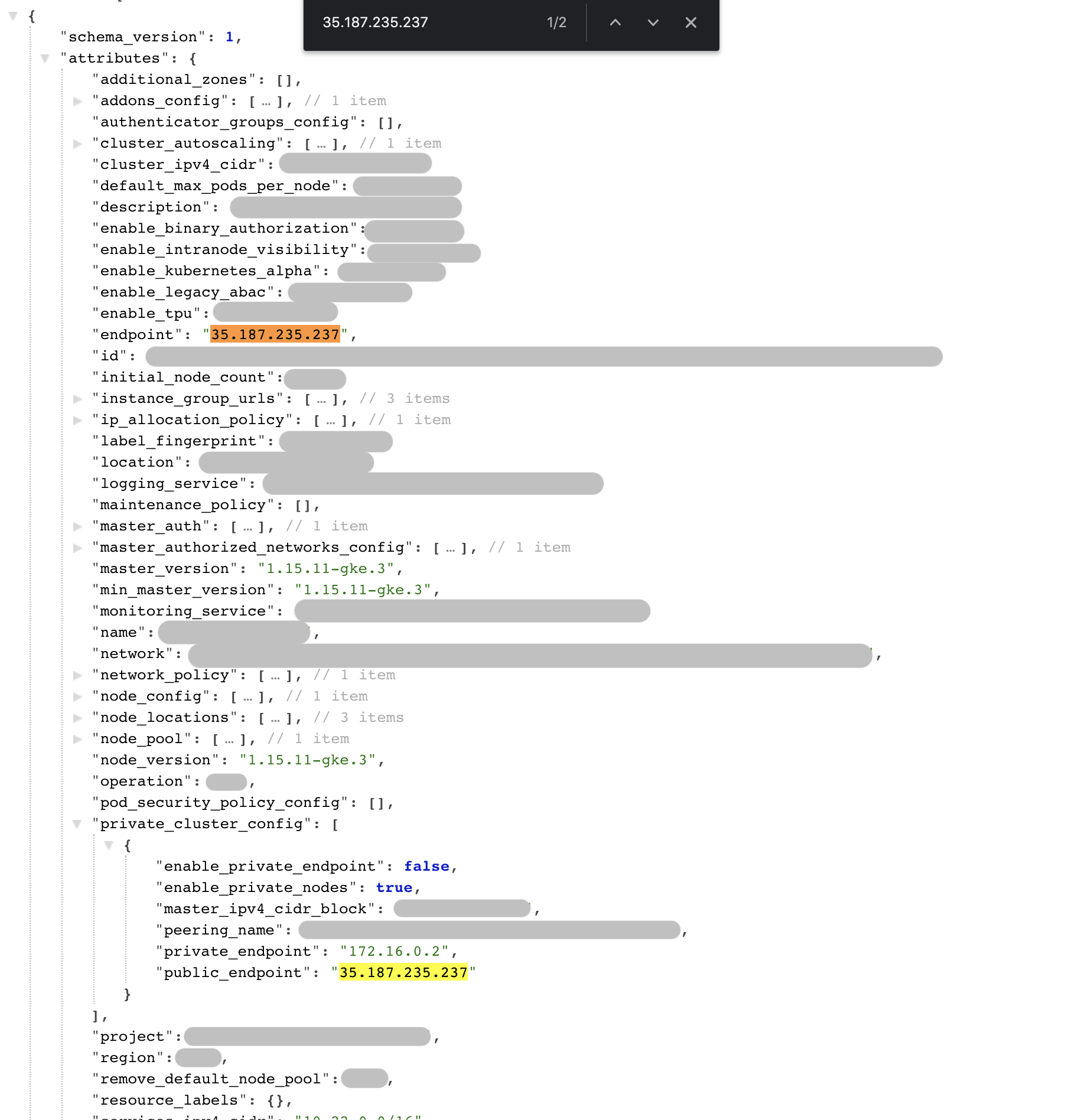
However, just for the sake of it, I changed the host value to google_container_cluster.k8s_cluster.private_cluster_config[0].public_endpoint and still got the following errors "intermittently":
# when creating
Error: Post http://localhost/api/v1/namespaces: dial tcp 127.0.0.1:80: connect: connection refused.
# when refreshing
Error: Get http://localhost/api/v1/namespaces/my-ns: dial tcp 127.0.0.1:80: connect: connection refused
# when deleting
Error: Delete http://localhost/api/v1/namespaces/my-ns: dial tcp 127.0.0.1:80: connect: connection refused
Sometimes it's hitting these errors sometimes it's not - "intermittently"
syedrakib
on 23 Apr 2020
@syedrakib can you reproduce this issue for us with TF_LOG set to TRACE (https://www.terraform.io/docs/internals/debugging.html) and share the logs with us so we can try to investigate this issue further?
 aareet
on 29 Apr 2020
aareet
on 29 Apr 2020
Dear @aareet . Here is the trace log with TF_LOG=TRACE in a updated link: https://www.dropbox.com/sh/e8i9hn7k8osar3k/AABENCs3MbcfTlCMjbcHVyJ8a
Sorry for the delay in response with this trace.
syedrakib
on 7 May 2020
I am just running terraform apply a few times.
Sometimes it's trying to reach: 35.198.227.163 and says Post https://35.198.227.163/api/v1/namespaces: dial tcp 35.198.227.163:443: i/o timeout
Sometimes it's trying to reach: localhost and says Post http://localhost/api/v1/namespaces: dial tcp 127.0.0.1:80: connect: connection refused
--- just by running terraform apply subsequently without changing anything in the modules or in the TF files.
I don't understand why is it behaving differently upon every terraform apply?
syedrakib
on 8 May 2020
On the first run of terraform apply, it successfully created the k8s namespace - with Host: 35.198.227.163
For several re-run of terraform apply it was fine and refreshed the namespace all well
Then on one of the runs of terraform apply (without modifying any TF file), it failed to refresh the k8s namespace - with host = localhost
Why the change from 35.198.227.163 to localhost is the problem.
Terraform is indeed getting "publicEndpoint": "35.198.227.163" from the k8s_cluster module (state id=projects/my_gcp_project_id/locations/asia-southeast1-a/clusters/gke-f2u5). But still the kubernetes provider is intermittently using localhost. Why so?
Updated link to log files: https://www.dropbox.com/sh/e8i9hn7k8osar3k/AABENCs3MbcfTlCMjbcHVyJ8a
The kubernetes provider i used is
provider "kubernetes" {
version = "1.11.1"
load_config_file = false
host = google_container_cluster.k8s_cluster.endpoint
token = data.google_client_config.google_client.access_token
cluster_ca_certificate = base64decode(google_container_cluster.k8s_cluster.master_auth.0.cluster_ca_certificate)
}
I seem to have a similar issue after upgrading from 1.9.0 to the latest 1.11.2. I am using EKS. One difference is that in my case the message:
Get "http://localhost/api/v1/namespaces/XXXX": dial tcp 127.0.0.1:80: connect: connection refused
occurs every time I run the plan.
 2tim
on 12 May 2020
2tim
on 12 May 2020
I'm also experiencing this issue, using 1.11.3. It's very consistent for me now, though was previously intermittent for a few patch levels now.
Edit: I found my problem was actually related to some refactoring into modules I was doing. I created a module that was using the provider, but I forgot to override the default provider configuration when I called that module. So, it was trying to use the default provider (which didn't actually exist anymore, due to refactoring to make specific providers that authenticated using different cluster's configuration details), and so there wasn't any configuration to say load_config_file = false, and it was picking up a local kubeconfig file in my path, and trying to connect to another cluster that no longer existed. Once I properly passed in configuration to point the module to use a Kubernetes provider that was properly configured to authenticate against the appropriate cluster, everything was cool again.
 mgrecar
on 27 May 2020
mgrecar
on 27 May 2020
I'm going to lock this issue because it has been closed for _30 days_ ⏳. This helps our maintainers find and focus on the active issues.
If you feel this issue should be reopened, we encourage creating a new issue linking back to this one for added context. If you feel I made an error 🤖 🙉 , please reach out to my human friends 👉 [email protected]. Thanks!
![hashibot[bot] picture](https://avatars.githubusercontent.com/in/8332?v=4&s=40) hashibot[bot]
on 30 Jul 2020
hashibot[bot]
on 30 Jul 2020
Related issues
 landorg
·
3Comments
hashibot[bot]
·
4Comments
landorg
·
3Comments
hashibot[bot]
·
4Comments
 OrangePieiep
·
3Comments
OrangePieiep
·
3Comments
 bugb
·
4Comments
bugb
·
4Comments
 marcincuber
·
3Comments
marcincuber
·
3Comments
Most helpful comment
I'm also experiencing this issue, using 1.11.3. It's very consistent for me now, though was previously intermittent for a few patch levels now.Edit: I found my problem was actually related to some refactoring into modules I was doing. I created a module that was using the provider, but I forgot to override the default provider configuration when I called that module. So, it was trying to use the default provider (which didn't actually exist anymore, due to refactoring to make specific providers that authenticated using different cluster's configuration details), and so there wasn't any configuration to say
load_config_file = false, and it was picking up a local kubeconfig file in my path, and trying to connect to another cluster that no longer existed. Once I properly passed in configuration to point the module to use a Kubernetes provider that was properly configured to authenticate against the appropriate cluster, everything was cool again.