Terraform-provider-google: GKE Node Pool status stuck as PROVISIONING
_This issue was originally opened by @mingsterism as hashicorp/terraform#23593. It was migrated here as a result of the provider split. The original body of the issue is below._
Hi guys, I'm running the below terraform script.
provider "google" {
version = "3.0.0"
project = "xxx"
region = "asia-southeast-1"
zone = "asia-southeast1-a"
}
resource "google_container_cluster" "primary" {
name = "my-gke-cluster"
location = "asia-southeast1-a"
remove_default_node_pool = true
initial_node_count = 1
}
resource "google_container_node_pool" "primary_nodes" {
name = "my-node-pool"
location = "asia-southeast1-a"
cluster = google_container_cluster.primary.name
node_count = 2
node_config {
preemptible = true
machine_type = "n1-standard-1"
metadata = {
disable-legacy-endpoints = true
}
oauth_scopes = [
"https://www.googleapis.com/auth/devstorage.read_only",
"https://www.googleapis.com/auth/logging.write",
"https://www.googleapis.com/auth/monitoring",
]
}
}
However am getting stuck with this error
2019/12/06 20:22:25 [ERROR] <root>: eval: *terraform.EvalSequence, err: Error reading NodePool "my-node-pool" from cluster "my-gke-cluster": Nodepool "my-node-pool" has status "PROVISIONING" with message ""
Error: Error reading NodePool "my-node-pool" from cluster "my-gke-cluster": Nodepool "my-node-pool" has status "PROVISIONING" with message ""
on cluster.tf line 16, in resource "google_container_node_pool" "primary_nodes":
16: resource "google_container_node_pool" "primary_nodes" {
On SO with others mentioning same problem as well
https://stackoverflow.com/questions/59208923/gke-node-pool-status-stuck-as-provisioning
Any suggestions?
thanks
 hashibot[bot]
hashibot[bot]
All 8 comments
Adding a breadcrumb for future searchers...
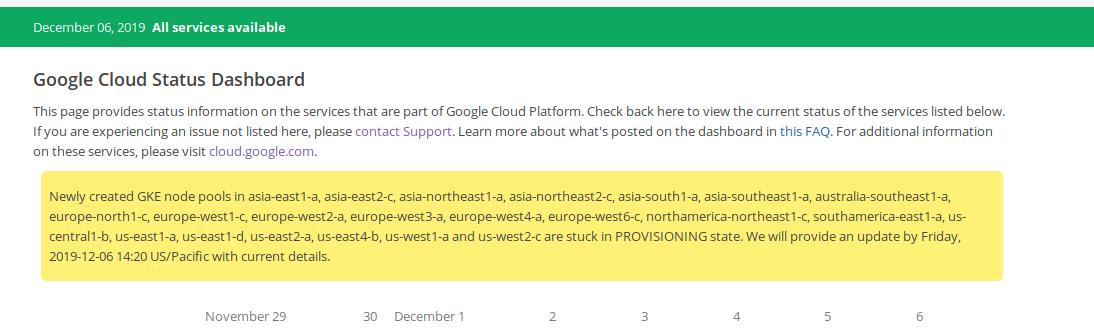
We've been working with GCP support since ~ 2019/12/05 20:00 UTC on this. As of 2019/12/06 19:00 UTC, the problem is ongoing.
Node pool creation _operations_ succeed (GCP's container operations api shows DONE). This allows Terraform to proceed past:
https://github.com/terraform-providers/terraform-provider-google/blob/2eb04684ddf7de1b2f860b922168d20727caeba1/google/resource_container_node_pool.go#L265-L267
Newly-created node pools show status: PROVISIONING which causes Terraform to bail out when trying to refresh state of the newly-created node pool:
https://github.com/terraform-providers/terraform-provider-google/blob/2eb04684ddf7de1b2f860b922168d20727caeba1/google/resource_container_node_pool.go#L298-L300
Comments in the linked SO article and some of the commentary in our open GCP support ticket make me think that this is occurring for some--but not all--users across several regions.
We've tried increasingly heavy-handed ways to turn things off and on again, but our GKE cluster in question seems perma-broken when trying to add node pools to it.
 StephenWithPH
on 6 Dec 2019
StephenWithPH
on 6 Dec 2019
Same for us, I tried multiple things, modules, resources, bumping versions but to no avail. Hopefully google will get it working soon.
 parabolic
on 6 Dec 2019
parabolic
on 6 Dec 2019
Same for us as well Nodepool has status "PROVISIONING" with message ""
 harishkashyap569
on 6 Dec 2019
harishkashyap569
on 6 Dec 2019
 StephenWithPH
on 6 Dec 2019
StephenWithPH
on 6 Dec 2019
@StephenWithPH appears correct, that this is a service issue and not provider-related.
However, I'd like the provider to handle situations like this a little better, and that's actually work I've already started. In addition to catching the service issue for users who would file, I'll use this issue to track slightly better mitigations for similar cases in the future.
 rileykarson
on 6 Dec 2019
rileykarson
on 6 Dec 2019
Just a small update, it seems that google has fixed the issue and I was able to do a plan/apply after the cluster has been created.
Thank you all for your support :)
parabolic
on 9 Dec 2019
https://github.com/GoogleCloudPlatform/magic-modules/pull/3077, https://github.com/GoogleCloudPlatform/magic-modules/pull/3114 should improve Terraform's behaviour in similar situations a little. After both those changes land, probably 3.10.0, we'd see clusters / pools stuck in a state like this get tainted on creation, and Terraform wouldn't error out if they already existed.
Additionally, the underlying API has been fixed for a while and I believe that there have been tests added to ensure that pools transition states when expected.
rileykarson
on 12 Feb 2020
I'm going to lock this issue because it has been closed for _30 days_ ⏳. This helps our maintainers find and focus on the active issues.
If you feel this issue should be reopened, we encourage creating a new issue linking back to this one for added context. If you feel I made an error 🤖 🙉 , please reach out to my human friends 👉 [email protected]. Thanks!
hashibot[bot]
on 28 Mar 2020
Related issues
 wmuizelaar
·
4Comments
wmuizelaar
·
4Comments
 ewbankkit
·
4Comments
ewbankkit
·
4Comments
 Zhann
·
3Comments
hashibot[bot]
·
3Comments
Zhann
·
3Comments
hashibot[bot]
·
3Comments
 mumblez
·
4Comments
mumblez
·
4Comments