Terraform-provider-aws: aws_autoscaling_group fails when increasing number of instances
I recently tried to bump the number of instances in an AWS autoscaling group resource and ran into this bug.
Version:
Terraform v0.11.7
provider.aws v1.27.0
`Error: Error applying plan:
1 error(s) occurred:
module.app.aws_autoscaling_group.asg: 1 error(s) occurred:
aws_autoscaling_group.asg: Error waiting for AutoScaling Group Capacity: "82766e2f-new-app20180718145707823100000005": Waiting up to 30m0s: Need exactly 1 healthy instances in ASG, have 3. Most recent activity: {
ActivityId: "134592b7-c695-f45e-8cef-b3ef2fc30b7c",
AutoScalingGroupName: "82766e2f-new-app20180718145707823100000005",
Cause: "At 2018-07-18T15:10:27Z a user request update of AutoScalingGroup constraints to min: 3, max: 3, desired: 3 changing the desired capacity from 1 to 3. At 2018-07-18T15:10:50Z an instance was started in response to a difference between desired and actual capacity, increasing the capacity from 1 to 3.",
Description: "Launching a new EC2 instance: i-0cd19a8b939a11eeb",
Details: "{\"Subnet ID\":\"subnet-1afesfsfseds\",\"Availability Zone\":\"us-east-1a\"}",
EndTime: 2018-07-18 15:11:25 +0000 UTC,
Progress: 100,
StartTime: 2018-07-18 15:10:52.285 +0000 UTC,
StatusCode: "Successful"
}`
 bnm22
bnm22
All 6 comments
I am also seeing similar results when the number of instances decreases due to an update. For me, it only seems to happen if we have the wait_for_elb_capacity property set on the ASG resource. Verified behavior on numerous provider versions between v1.20.0 - v1.36.0 inclusive. Also verified behavior still exists on Terraform v0.11.8.
 johnctitus
on 18 Sep 2018
johnctitus
on 18 Sep 2018
Seeing this issue on Terraform v0.11.7 provider 1.42.0
module.app.aws_autoscaling_group.asg: Modifying... (ID: xxxxxxxx)
November 6th 2018 18:06:59Info
max_size: "3" => "6"
November 6th 2018 18:06:59Info
min_size: "3" => "6"
November 6th 2018 18:06:59Info
wait_for_elb_capacity: "3" => "6"
....
Error: Error applying plan:
November 6th 2018 18:37:01Error
1 error(s) occurred:
November 6th 2018 18:37:01Error
* module.app.aws_autoscaling_group.asg: 1 error(s) occurred:
November 6th 2018 18:37:01Error
* aws_autoscaling_group.asg: Error waiting for AutoScaling Group Capacity: "xxxxxxxx": Waiting up to 30m0s: Need exactly 3 healthy instances in ASG, have 6
 smastrorocco
on 7 Nov 2018
smastrorocco
on 7 Nov 2018
We are still seeing this issue:
...
max_size: "8" => "10"
min_size: "8" => "10"
...
Need exactly 8 healthy instances in ASG, have 10.
I saw this issue today with Terraform v0.12.18, AWS provider v2.48.0, while trying to increase min_size and wait_for_elb_capacity from 2 to 3. The relevant section of apply output (after 2 hours of Still modifying...), is:
Error: Error waiting for AutoScaling Group Capacity: "cluster-foo": Waiting up to 2h0m0s: Need exactly 2 healthy instances in ASG, have 3. Most recent activity: {
...
Cause: "At 2020-02-10T00:48:07Z a user request update of AutoScalingGroup constraints to min: 3, max: 4, desired: 3 changing the desired capacity from 2 to 3. At 2020-02-10T00:48:14Z an instance was started in response to a difference between desired and actual capacity, increasing the capacity from 2 to 3.",
...
The Need exactly <x> healthy instances in ASG message is referencing the existing instance count, not the new one. That specific message comes from the first if block in the capacitySatisfiedUpdate() function. The problem is with wantASG, which comes from the desired_capacity schema key.
The desired_capacity resource argument is optional and will default to min_size if not specified. I didn't set or change it on the Terraform resource, but because it's a property of the AWS resource it has a defined value. Terraform doesn't seem to be aware it will change, since the plan output shows the existing value for desired_capacity:
Terraform will perform the following actions:
# aws_autoscaling_group.cluster-foo will be updated in-place
~ resource "aws_autoscaling_group" "cluster-foo" {
...
default_cooldown = 300
desired_capacity = 2
enabled_metrics = []
...
max_instance_lifetime = 0
~ max_size = 3 -> 4
metrics_granularity = "1Minute"
~ min_size = 2 -> 3
...
wait_for_capacity_timeout = "2h"
~ wait_for_elb_capacity = 2 -> 3
tag {
...
The field is marked as Computed, but that apparently only applies on creation, not update.
I suspect a fix could be to check d.HasChange("desired_capacity") and, if not, skip the first if block in capacitySatisfiedUpdate(). I don't understand Terraform internals well though so perhaps there's a more fundamental issue with desired/min/max capacity calculation.
 lachlancooper
on 10 Feb 2020
lachlancooper
on 10 Feb 2020
Is this issue fixed? I am still seeing the below error when tried to increase the min and max number
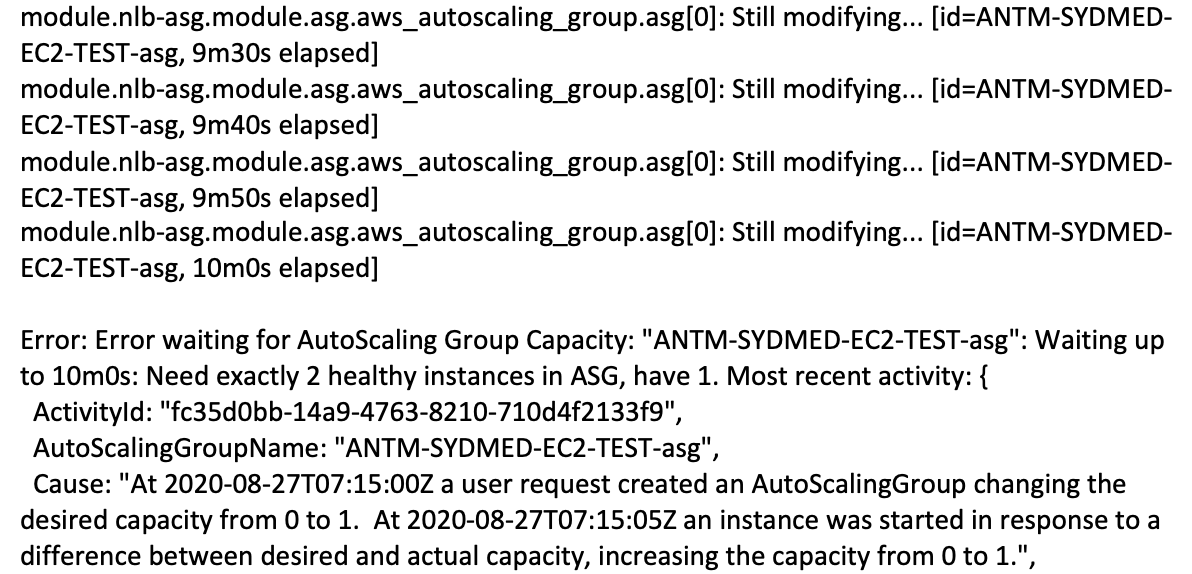
 KMahankali
on 27 Aug 2020
KMahankali
on 27 Aug 2020
Is this issue fixed? I am still seeing the below error when tried to increase the min and max number
No. I've proposed a fix in #12018 but it hasn't been reviewed yet.
lachlancooper
on 28 Aug 2020
Related issues
 hashibot
·
3Comments
hashibot
·
3Comments
 EmmN
·
3Comments
hashibot
·
3Comments
hashibot
·
3Comments
hashibot
·
3Comments
EmmN
·
3Comments
hashibot
·
3Comments
hashibot
·
3Comments
hashibot
·
3Comments
Most helpful comment
I saw this issue today with Terraform v0.12.18, AWS provider v2.48.0, while trying to increase
min_sizeandwait_for_elb_capacityfrom 2 to 3. The relevant section of apply output (after 2 hours ofStill modifying...), is:The
Need exactly <x> healthy instances in ASGmessage is referencing the existing instance count, not the new one. That specific message comes from the firstifblock in the capacitySatisfiedUpdate() function. The problem is withwantASG, which comes from thedesired_capacityschema key.The
desired_capacityresource argument is optional and will default tomin_sizeif not specified. I didn't set or change it on the Terraform resource, but because it's a property of the AWS resource it has a defined value. Terraform doesn't seem to be aware it will change, since the plan output shows the existing value fordesired_capacity:The field is marked as Computed, but that apparently only applies on creation, not update.
I suspect a fix could be to check
d.HasChange("desired_capacity")and, if not, skip the firstifblock incapacitySatisfiedUpdate(). I don't understand Terraform internals well though so perhaps there's a more fundamental issue with desired/min/max capacity calculation.