Tensorrt: How to use NMS with Pytorch model (that was converted to ONNX -> TensorRT)
All right, so, I have a PyTorch detector SSD with MobileNet. Since I failed to convert model with NMS in it (to be more precise, I converted it, but TRT engine is built in a wrong way with that .onnx file), I decided to leave NMS part to TRT.
In general, there are several ways to add NMS in TRT:
- Use graphsurgeon with TensorFlow model and add NMS as graphsurgeon.create_plugin_node
- Use CPP code for plugin (https://github.com/NVIDIA/TensorRT/tree/master/plugin/batchedNMSPlugin)
- Use DeepStream that has NMS plugin
But, I have a PyTorch model that I converted to onnx and then to TRT without any CPP code (Python only). My question is very simple: how can I combine my current pipeline with the CPP plugin for NMS?
 ivanpanshin
ivanpanshin
All 50 comments
You can use ONNX-GraphSurgeon to modify the ONNX model to include a plugin node. You can look at the onnx_packnet example for details.
 pranavm-nvidia
on 23 Sep 2020
pranavm-nvidia
on 23 Sep 2020
Wow, ONNX-GS, nice! And just to be 100% sure: it's possible to use ONNX-GS in the same way as the regular GS to use this CPP NMS plugin (https://github.com/NVIDIA/TensorRT/tree/master/plugin/batchedNMSPlugin), correct?
ivanpanshin
on 24 Sep 2020
Yes, correct. You can replace the old NMS subgraph/node with a new node whose op is set to the plugin name. There are two ways to do this, which I've outlined below.
Old-GS Style
In the simplest case, you can create the node and insert it into the graph like old GS, e.g.:
# Find tensors
tmap = graph.tensors()
boxes, scores, nms_out = tmap["boxes"], tmap["scores"], tmap["nms_out"]
# Disconnect old subgraph
boxes.outputs.clear()
scores.outputs.clear()
nms_out.inputs.clear()
attrs = {
"share_location": False,
"num_classes": 8,
# etc.
}
node = gs.Node(op="BatchedNMS_TRT", attrs=attrs,
inputs=[boxes, scores], outputs=[nms_out])
graph.nodes.append(node)
Layer + Register API
If you're reusing this across multiple models, or using the plugin multiple times in the model, then the layer/register API might simplify things.
First you'd register a function to insert the plugin:
@gs.Graph.register()
def trt_batched_nms(self, boxes_input, scores_input, nms_output,
share_location, num_classes): # and other attrs
boxes_input.outputs.clear()
scores_input.outputs.clear()
nms_output.inputs.clear()
attrs = {
"share_location": share_location,
"num_classes": num_classes,
# etc.
}
return self.layer(op="BatchedNMS_TRT", attrs=attrs,
inputs=[boxes_input, scores_input],
outputs=[nms_output])
And then in your models, you can use it without all the boilerplate:
tmap = graph.tensors()
# Can also get attributes from the original graph instead of hard-coding
graph.trt_batched_nms(tmap["boxes"], tmap["scores"],
tmap["nms_out"], share_location=True,
num_classes=81)
graph.trt_batched_nms(tmap["boxes2"], tmap["scores2"],
tmap["nms_out2"], share_location=False,
num_classes=4)
Hi, @pranavm-nvidia, I tried using the ONNX-GS method as you proposed and I've successfully replaced the NMS operator with BatchedNMS_TRT using the following code:
import onnx_graphsurgeon as gs
import onnx
import numpy as np
input_model_path = "model.onnx"
output_model_path = "model_gs.onnx"
@gs.Graph.register()
def trt_batched_nms(self, boxes_input, scores_input, nms_output,
share_location, num_classes):
boxes_input.outputs.clear()
scores_input.outputs.clear()
nms_output.inputs.clear()
attrs = {
"shareLocation": share_location,
"numClasses": num_classes,
"backgroundLabelId": 0,
"topK": 116740,
"keepTopK": 100,
"scoreThreshold": 0.3,
"iouThreshold": 0.6,
"isNormalized": True,
"clipBoxes": True
}
return self.layer(op="BatchedNMS_TRT", attrs=attrs,
inputs=[boxes_input, scores_input],
outputs=[nms_output])
graph = gs.import_onnx(onnx.load(input_model_path))
graph.inputs[0].shape=[1,1280,720,3]
print(graph.inputs[0].shape)
for inp in graph.inputs:
inp.dtype = np.int
input = graph.inputs[0]
tmap = graph.tensors()
graph.trt_batched_nms(tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1712:0"],
tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores/NonMaxSuppressionV5__1761:0"],
tmap["NonMaxSuppression__1763:0"],
share_location=False,
num_classes=4)
graph.trt_batched_nms(tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1712:0"],
tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_1/NonMaxSuppressionV5__1737:0"],
tmap["NonMaxSuppression__1739:0"],
share_location=False,
num_classes=4)
graph.trt_batched_nms(tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1712:0"],
tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1713:0"],
tmap["NonMaxSuppression__1715:0"],
share_location=False,
num_classes=4)
graph.trt_batched_nms(tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1712:0"],
tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_3/NonMaxSuppressionV5__1689:0"],
tmap["NonMaxSuppression__1691:0"],
share_location=False,
num_classes=4)
# Remove unused nodes, and topologically sort the graph.
# graph.cleanup()
# graph.toposort()
# graph.fold_constants().cleanup()
# Export the ONNX graph from graphsurgeon
onnx.checker.check_model(gs.export_onnx(graph))
onnx.save_model(gs.export_onnx(graph), output_model_path)
print("Saving the ONNX model to {}".format(output_model_path))
The problem I'm currently facing is that onnx.checker.check_model(gs.export_onnx(graph)) function returns following error:
onnx.onnx_cpp2py_export.checker.ValidationError:
Node (NonMaxSuppression__1763) has output size 0 not in range [min=1, max=1].
==> Context: Bad node spec:
input: "const_fold_opt__2119"
input: "Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_3/iou_threshold:0"
input:"Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/score_threshold:0"
name: "NonMaxSuppression__1763" op_type: "NonMaxSuppression"
````
---
I think that the problem is in `builtin_op_importers.cpp`, where I added this code similar to #523:
```c
{
DEFINE_BUILTIN_OP_IMPORTER(NonMaxSuppression)
// NonMaxSuppression is not supported opset below 10.
ASSERT(ctx->getOpsetVersion() >= 10, ErrorCode::kUNSUPPORTED_NODE);
nvinfer1::ITensor* boxes_tensor = &convertToTensor(inputs.at(0), ctx);
nvinfer1::ITensor* scores_tensor = &convertToTensor(inputs.at(1), ctx);
const int numInputs = inputs.size();
LOG_ERROR("no of inputs are "<<numInputs);
LOG_ERROR("node outsize and op type are "<<node.output().size()<< " type " << node.op_type());
const auto scores_dims = scores_tensor->getDimensions();
const auto boxes_dims = boxes_tensor->getDimensions();
LOG_ERROR("boxes dims "<< boxes_dims.nbDims << " dim3 has size "<<boxes_dims.d[2]);
const std::string pluginName = "BatchedNMS_TRT";
const std::string pluginVersion = "1";
std::vector<nvinfer1::PluginField> f;
/*
bool share_location = true;
const bool is_normalized = true;
const bool clip_boxes = true;
int backgroundLabelId = 0;
// Initialize.
f.emplace_back("shareLocation", &share_location, nvinfer1::PluginFieldType::kINT8, 1);
f.emplace_back("isNormalized", &is_normalized, nvinfer1::PluginFieldType::kINT8, 1);
f.emplace_back("clipBoxes", &clip_boxes, nvinfer1::PluginFieldType::kINT8, 1);
f.emplace_back("backgroundLabelId", &backgroundLabelId, nvinfer1::PluginFieldType::kINT32, 1);
*/
// Create plugin from registry
//nvinfer1::IPluginV2* plugin = importPluginFromRegistry(ctx, pluginName, pluginVersion, node.name$
nvinfer1::IPluginV2* plugin = createPlugin(node.name(), importPluginCreator(pluginName, pluginVers$
ASSERT(plugin != nullptr && "NonMaxSuppression plugin was not found in the plugin registry!",
ErrorCode::kUNSUPPORTED_NODE);
std::vector<nvinfer1::ITensor*> nms_inputs ={boxes_tensor, scores_tensor};
RETURN_FIRST_OUTPUT(ctx->network()->addPluginV2(nms_inputs.data(), nms_inputs.size(), *plugin));
}
Do you have an example of properly registering BatchedNMS_TRT as a plugin?
Also, do you have end to end example of replacing BatchedNMS with a TRT version?
 qraleq
on 4 Nov 2020
qraleq
on 4 Nov 2020
@qraleq You should not need to modify the parser at all in TRT 7.1 and later (for any plugin, not just NMS). Modifying the node in the ONNX model should be enough.
Since BatchedNMS_TRT is not technically a valid ONNX op, it's expected that ONNX checker will fail.
From the error message though, it seems like you might have missed one?
name: "NonMaxSuppression__1763" op_type: "NonMaxSuppression"
Do you have an example of properly registering BatchedNMS_TRT as a plugin?
BatchedNMS_TRT is shipped as a TRT plugin, so you do not need any extra steps to register it.
Also, do you have end to end example of replacing BatchedNMS with a TRT version?
I don't know of an end-to-end example that uses NMS specifically, but we do have an example of GroupNorm (onnx-packnet).
However, I think the code you have right now should be nearly working if you uncomment these 2 lines:
# graph.cleanup()
# graph.toposort()
You can try the resulting ONNX model with trtexec to check, and it should automatically pick up the plugin.
pranavm-nvidia
on 4 Nov 2020
@pranavm-nvidia Tnx for the fast response. I commented out the changes to the parser and rebuilt onnx-tensorrt. Now when I uncomment the two lines as you proposed, I get the following error when running with trtexec:
[11/04/2020-21:04:04] [W] [TRT] /home/f/Development/onnx-tensorrt/onnx2trt_utils.cpp:220: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[11/04/2020-21:04:04] [W] [TRT] /home/f/Development/onnx-tensorrt/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[11/04/2020-21:04:04] [W] [TRT] /home/f/Development/onnx-tensorrt/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[11/04/2020-21:04:04] [W] [TRT] /home/f/Development/onnx-tensorrt/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/ModelImporter.cpp:139: No importer registered for op: BatchedNMS_TRT. Attempting to import as plugin.
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3775: Searching for plugin: BatchedNMS_TRT, plugin_version: 1, plugin_namespace:
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3792: Successfully created plugin: BatchedNMS_TRT
[11/04/2020-21:04:04] [E] [TRT] onnx_graphsurgeon_node_0: PluginV2Layer must be V2DynamicExt when there are runtime input dimensions.
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/ModelImporter.cpp:139: No importer registered for op: BatchedNMS_TRT. Attempting to import as plugin.
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3775: Searching for plugin: BatchedNMS_TRT, plugin_version: 1, plugin_namespace:
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3792: Successfully created plugin: BatchedNMS_TRT
[11/04/2020-21:04:04] [E] [TRT] onnx_graphsurgeon_node_0: PluginV2Layer must be V2DynamicExt when there are runtime input dimensions.
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/ModelImporter.cpp:139: No importer registered for op: BatchedNMS_TRT. Attempting to import as plugin.
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3775: Searching for plugin: BatchedNMS_TRT, plugin_version: 1, plugin_namespace:
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3792: Successfully created plugin: BatchedNMS_TRT
[11/04/2020-21:04:04] [E] [TRT] onnx_graphsurgeon_node_0: PluginV2Layer must be V2DynamicExt when there are runtime input dimensions.
[11/04/2020-21:04:04] [E] [TRT] onnx_graphsurgeon_node_0: PluginV2Layer must be V2DynamicExt when there are runtime input dimensions.
[11/04/2020-21:04:04] [E] [TRT] onnx_graphsurgeon_node_0: PluginV2Layer must be V2DynamicExt when there are runtime input dimensions.
[11/04/2020-21:04:04] [E] [TRT] onnx_graphsurgeon_node_0: PluginV2Layer must be V2DynamicExt when there are runtime input dimensions.
While parsing node number 351 [Slice]:
ERROR: /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3154 In function importSlice:
[4] Assertion failed: -r <= axis && axis < r
[11/04/2020-21:04:04] [E] Failed to parse onnx file
[11/04/2020-21:04:04] [E] Parsing model failed
[11/04/2020-21:04:04] [E] Engine creation failed
[11/04/2020-21:04:04] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec # /usr/src/tensorrt/bin/trtexec --onnx=model_gs.onnx
Do you have an idea what might be wrong?
qraleq
on 4 Nov 2020
@qraleq Looks like your model is using dynamic shapes somewhere:
[11/04/2020-21:04:04] [E] [TRT] onnx_graphsurgeon_node_0: PluginV2Layer must be V2DynamicExt when there are runtime input dimensions.
Seems like the model input dimensions are fixed though, so it must be due to some intermediate layer whose dimensions can't be resolved at build time.
Can you try using the BatchedNMSDynamic_TRT plugin instead?
The good news is that it does seem to be finding the plugin correctly at least:
[11/04/2020-21:04:04] [I] [TRT] /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3792: Successfully created plugin: BatchedNMS_TRT
Also I think you'll probably need to populate the other parameters expected by the plugin (see here) or you might run into issues during inference.
pranavm-nvidia
on 4 Nov 2020
@pranavm-nvidia Yeah, I also figured that something "dynamic" is still leftover in the graph, but can't figure out what.
I tried to use BatchedNMSDynamic_TRT, but I get error saying:
[11/04/2020-21:32:10] [I] [TRT] /home/f/Development/onnx-tensorrt/ModelImporter.cpp:139: No importer registered for op: BatchedNMSDynamic_TRT. Attempting to import as plugin.
[11/04/2020-21:32:10] [I] [TRT] /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3775: Searching for plugin: BatchedNMSDynamic_TRT, plugin_version: 1, plugin_namespace:
[11/04/2020-21:32:10] [E] [TRT] INVALID_ARGUMENT: getPluginCreator could not find plugin BatchedNMSDynamic_TRT version 1
While parsing node number 834 [BatchedNMSDynamic_TRT]:
ERROR: /home/f/Development/onnx-tensorrt/builtin_op_importers.cpp:3777 In function importFallbackPluginImporter:
[8] Assertion failed: creator && "Plugin not found, are the plugin name, version, and namespace correct?"
I'm using TensorRT 7.1.3.0-1+cuda10.2 on Jetson AGX. How can I make sure that dynamic NMS gets recognized by the parser?
qraleq
on 4 Nov 2020
@qraleq The dynamic version was added in 7.2, so that would explain why it doesn't recognize it.
Would you be able to share the verbose trtexec logs (add --verbose) and/or your ONNX model?
pranavm-nvidia
on 4 Nov 2020
@pranavm-nvidia Please find the log attached.
log.txt
Can I send you the model directly somehow?
qraleq
on 4 Nov 2020
@qraleq You can email me the model/link to the model at [email protected]
Seems like it's this Resize that's introducing dynamic shapes:
ModelImporter.cpp:107: Parsing node: Resize__1007 [Resize]
ModelImporter.cpp:129: Resize__1007 [Resize] inputs: [Transpose__1002:0 -> (1, 3, 1280, 720)], [roi__998 -> ()], [roi__998 -> ()], [Concat__1006:0 -> (4)],
ModelImporter.cpp:183: Resize__1007 [Resize] outputs: [Resize__1007:0 -> (-1, -1, -1, -1)],
Note that the output of the previous layer has a fixed shape: Transpose__1002:0 -> (1, 3, 1280, 720)
Is it possible to express the resize using a constant sizes or scales input instead of rois? Then TRT would be able to compute the output shapes at build time
pranavm-nvidia
on 4 Nov 2020
@qraleq Please look at @pranavm-nvidia 's comment above to see if it fixes your problem.
 mk-nvidia
on 8 Dec 2020
mk-nvidia
on 8 Dec 2020
We discussed this offline, I believe @qraleq's issue is resolved now.
pranavm-nvidia
on 8 Dec 2020
@mk-nvidia Thank you for following up. @pranavm-nvidia was of great help and we resolved the issue! Best regards!
qraleq
on 9 Dec 2020
@pranavm-nvidia or anyone, can you help me figure out the problem. I appended a BatchedNMS plugin to the end of an onnx file and can visually see the result in netron but I got segmentation fault in trtexec. Here is the trtexec output:
/opt/TensorRT/targets/x86_64-linux-gnu/bin/trtexec --onnx=best.opt_nms.onnx --explicitBatch
&&&& RUNNING TensorRT.trtexec # /opt/TensorRT/targets/x86_64-linux-gnu/bin/trtexec --onnx=best.opt_nms.onnx --explicitBatch
[12/10/2020-13:21:36] [I] === Model Options ===
[12/10/2020-13:21:36] [I] Format: ONNX
[12/10/2020-13:21:36] [I] Model: best.opt_nms.onnx
[12/10/2020-13:21:36] [I] Output:
[12/10/2020-13:21:36] [I] === Build Options ===
[12/10/2020-13:21:36] [I] Max batch: explicit
[12/10/2020-13:21:36] [I] Workspace: 16 MiB
[12/10/2020-13:21:36] [I] minTiming: 1
[12/10/2020-13:21:36] [I] avgTiming: 8
[12/10/2020-13:21:36] [I] Precision: FP32
[12/10/2020-13:21:36] [I] Calibration:
[12/10/2020-13:21:36] [I] Refit: Disabled
[12/10/2020-13:21:36] [I] Safe mode: Disabled
[12/10/2020-13:21:36] [I] Save engine:
[12/10/2020-13:21:36] [I] Load engine:
[12/10/2020-13:21:36] [I] Builder Cache: Enabled
[12/10/2020-13:21:36] [I] NVTX verbosity: 0
[12/10/2020-13:21:36] [I] Tactic sources: Using default tactic sources
[12/10/2020-13:21:36] [I] Input(s)s format: fp32:CHW
[12/10/2020-13:21:36] [I] Output(s)s format: fp32:CHW
[12/10/2020-13:21:36] [I] Input build shapes: model
[12/10/2020-13:21:36] [I] Input calibration shapes: model
[12/10/2020-13:21:36] [I] === System Options ===
[12/10/2020-13:21:36] [I] Device: 0
[12/10/2020-13:21:36] [I] DLACore:
[12/10/2020-13:21:36] [I] Plugins:
[12/10/2020-13:21:36] [I] === Inference Options ===
[12/10/2020-13:21:36] [I] Batch: Explicit
[12/10/2020-13:21:36] [I] Input inference shapes: model
[12/10/2020-13:21:36] [I] Iterations: 10
[12/10/2020-13:21:36] [I] Duration: 3s (+ 200ms warm up)
[12/10/2020-13:21:36] [I] Sleep time: 0ms
[12/10/2020-13:21:36] [I] Streams: 1
[12/10/2020-13:21:36] [I] ExposeDMA: Disabled
[12/10/2020-13:21:36] [I] Data transfers: Enabled
[12/10/2020-13:21:36] [I] Spin-wait: Disabled
[12/10/2020-13:21:36] [I] Multithreading: Disabled
[12/10/2020-13:21:36] [I] CUDA Graph: Disabled
[12/10/2020-13:21:36] [I] Separate profiling: Disabled
[12/10/2020-13:21:36] [I] Skip inference: Disabled
[12/10/2020-13:21:36] [I] Inputs:
[12/10/2020-13:21:36] [I] === Reporting Options ===
[12/10/2020-13:21:36] [I] Verbose: Disabled
[12/10/2020-13:21:36] [I] Averages: 10 inferences
[12/10/2020-13:21:36] [I] Percentile: 99
[12/10/2020-13:21:36] [I] Dump refittable layers:Disabled
[12/10/2020-13:21:36] [I] Dump output: Disabled
[12/10/2020-13:21:36] [I] Profile: Disabled
[12/10/2020-13:21:36] [I] Export timing to JSON file:
[12/10/2020-13:21:36] [I] Export output to JSON file:
[12/10/2020-13:21:36] [I] Export profile to JSON file:
[12/10/2020-13:21:36] [I]
[12/10/2020-13:21:36] [I] === Device Information ===
[12/10/2020-13:21:36] [I] Selected Device: Quadro M1200
[12/10/2020-13:21:36] [I] Compute Capability: 5.0
[12/10/2020-13:21:36] [I] SMs: 5
[12/10/2020-13:21:36] [I] Compute Clock Rate: 1.148 GHz
[12/10/2020-13:21:36] [I] Device Global Memory: 4046 MiB
[12/10/2020-13:21:36] [I] Shared Memory per SM: 64 KiB
[12/10/2020-13:21:36] [I] Memory Bus Width: 128 bits (ECC disabled)
[12/10/2020-13:21:36] [I] Memory Clock Rate: 2.505 GHz
[12/10/2020-13:21:36] [I]
----------------------------------------------------------------
Input filename: best.opt_nms.onnx
ONNX IR version: 0.0.6
Opset version: 11
Producer name:
Producer version:
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
[12/10/2020-13:21:36] [W] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/onnx2trt_utils.cpp:220: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[12/10/2020-13:21:36] [W] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[12/10/2020-13:21:36] [W] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[12/10/2020-13:21:36] [W] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[12/10/2020-13:21:36] [W] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[12/10/2020-13:21:36] [W] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[12/10/2020-13:21:36] [W] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/onnx2trt_utils.cpp:246: One or more weights outside the range of INT32 was clamped
[12/10/2020-13:21:36] [I] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/ModelImporter.cpp:139: No importer registered for op: BatchedNMS_TRT. Attempting to import as plugin.
[12/10/2020-13:21:36] [I] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/builtin_op_importers.cpp:3775: Searching for plugin: BatchedNMS_TRT, plugin_version: 1, plugin_namespace:
[12/10/2020-13:21:36] [I] [TRT] /home/bozkalayci/github/TensorRT/parsers/onnx/builtin_op_importers.cpp:3792: Successfully created plugin: BatchedNMS_TRT
[12/10/2020-13:21:47] [I] [TRT] Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[12/10/2020-13:23:10] [I] [TRT] Detected 1 inputs and 4 output network tensors.
[12/10/2020-13:23:10] [I] Engine built in 94.3465 sec.
[12/10/2020-13:23:10] [I] Starting inference
Segmentation fault (core dumped)
Here are the code snippets to add the nms plugins :
def append_nms(graph, num_classes, scoreThreshold, iouThreshold, keepTopK):
out_tensors = graph.outputs
bs = out_tensors[0].shape[0]
num_priors = out_tensors[0].shape[1]
nms_attrs = {'shareLocation': True,
'backgroundLabelId': -1,
'numClasses': num_classes,
'topK': num_priors,
'keepTopK': keepTopK,
'scoreThreshold': scoreThreshold,
'iouThreshold': iouThreshold,
'isNormalized': True,
'clipBoxes': True}
num_detections = gs.Variable(name="num_detections", dtype=np.int32, shape=(bs, 1))
boxes = gs.Variable(name="boxes", dtype=np.float32, shape=(bs, keepTopK, 4))
scores = gs.Variable(name="scores", dtype=np.float32, shape=(bs, keepTopK))
classes = gs.Variable(name="classes", dtype=np.float32, shape=(bs, keepTopK))
nms = gs.Node(op="BatchedNMS_TRT", attrs=nms_attrs, inputs=out_tensors, outputs=[num_detections, boxes, scores, classes])
graph.nodes.append(nms)
graph.outputs = [num_detections, boxes, scores, classes]
return graph
def add_nms_to_onnx(model_file, num_classes, confidenceThreshold=0.3, nmsThreshold=0.6, keepTopK=100, opset=11):
graph = gs.import_onnx(onnx.load(model_file))
if opset == 11:
graph = process_pad_nodes(graph)
graph = append_nms(graph, num_classes, confidenceThreshold, nmsThreshold, keepTopK)
# Remove unused nodes, and topologically sort the graph.
graph.cleanup().toposort().fold_constants().cleanup()
# Export the onnx graph from graphsurgeon
out_name = model_file[:-5]+'_nms.onnx'
onnx.save_model(gs.export_onnx(graph), out_name)
print("Saving the ONNX model to {}".format(out_name))
add_nms_to_onnx(model_file, 10, confidenceThreshold=0.3, nmsThreshold=0.6, keepTopK=100, opset=11)
The output shapes of onnx file before appending the nms is like this:

 xonobo
on 10 Dec 2020
xonobo
on 10 Dec 2020
@xonobo Can you try getting a backtrace with gdb? Verbose logs would also help (add --verbose)
pranavm-nvidia
on 10 Dec 2020
used gdb with trtexec_debug and got not much info
[12/11/2020-10:17:31] [V] [TRT] Layer(PluginV2): (Unnamed Layer* 269) [PluginV2Ext], Tactic: 0, 935[Float(5733,1,4)], 936[Float(5733,10)] -> num_detections[Int32()], boxes[Float(100,4)], scores[Float(100)], classes[Float(100)]
[12/11/2020-10:17:31] [I] Engine built in 100.447 sec.
[12/11/2020-10:17:31] [V] [TRT] Allocated persistent device memory of size 602184192
[12/11/2020-10:17:31] [V] [TRT] Allocated activation device memory of size 31899648
[12/11/2020-10:17:31] [V] [TRT] Assigning persistent memory blocks for various profiles
[12/11/2020-10:17:31] [I] Starting inference
[New Thread 0x7fffd1b05700 (LWP 9132)]
Thread 6 "trtexec_debug" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x7fffd1b05700 (LWP 9132)]
0x0000000000000001 in ?? ()
(gdb)
verbose output states num_detections[Int32()].
Is this ok or should it be num_detections[Int32(1)]?
xonobo
on 11 Dec 2020
@pranavm-nvidia I am having the same issue as @qraleq with regards to dynamic shapes.
Specifically in my case, I am using SSD with mobilenetV2 trained in Tensorflow, and using TensorRT 7.1. I was able to configure the mapping between the NMS_TRT plugin and NonMaxSuppression by editing the cpp code, but when I now try to convert the onnx file to trt, I get the following error:
(Unnamed Layer* 1073) [PluginV2Ext]: PluginV2Layer must be V2DynamicExt when there are runtime input dimensions.
Could you please share your solution?
 jonakola
on 11 Dec 2020
jonakola
on 11 Dec 2020
@jonakola You should use the BatchedNMSDynamic_TRT plugin if you have dynamic shapes. This plugin is supported in TensorRT version > 7.2.
Since I'm using NVIDIA Jetsons which do not support this plugin at the moment, I ended up freezing the TensorFlow model to a fixed shape, and then everything worked out as supposed.
qraleq
on 11 Dec 2020
Thanks @qraleq . I am also using NVIDIA Jetsons. How did you accomplish fixing the shape in TF in your case? I started off with a frozen_inference_graph.pb (exported after training with TF object detection api) which I would have thought already freezes all variables and shapes.
jonakola
on 11 Dec 2020
@jonakola Explicitly define sizes when freezing the model from ckpt to pb.
Take a look here: https://github.com/tensorflow/models/blob/master/research/object_detection/export_inference_graph.py
and specifically:
flags.DEFINE_string('input_shape', None,
'If input_type is `image_tensor`, this can explicitly set '
'the shape of this input tensor to a fixed size. The '
'dimensions are to be provided as a comma-separated list '
'of integers. A value of -1 can be used for unknown '
'dimensions. If not specified, for an `image_tensor, the '
'default shape will be partially specified as '
'`[None, None, None, 3]`.')
@xonobo It's weird that one dimension is being cut out from each of the output shapes. Is it possible for you to share your model?
pranavm-nvidia
on 11 Dec 2020
Here I provide two onnx files. I zero outed all weights in order to make them small. The smaller model passes trtexec but the bigger one fails as I stated above. I appended the nms plugin to the models using the same python script.
xonobo
on 14 Dec 2020
@xonobo It looks like the topK parameter is out of range in the larger model:
Invalid parameter: NMS topK (5733) exceeds limit (4096)
Thanks for figuring out the problem but can you share your inspection way, I can not see any log report about the invalid parameter. If you found this case by using nvidia's internal tools can you add these invalid cases to public log reports in the next release.
Thanks a lot for your help.
xonobo
on 15 Dec 2020
Thank you for the previous help @qraleq. I am still unable to successfully convert my model from onnx to trt. Here are the specifics:
- Original model is SSD mobilenetV2 from TF 1 model zoo and tuned with my own images, frozen to a fixed shape as suggested above. I'm using TF 1.15.
- I am able to successfully convert from either saved_model or frozen_inference_graph.pb to onnx using tf2onnx 1.7.2 as follows
python3 -m tf2onnx.convert --saved-model saved_model --opset 11 --output prod.onnx
- Using the Layer + Register API mentioned previously, I am able to replace NonMaxSuppression ops with BatchedNMS_TRT plugin.
- After all this, converting to trt engine with onnx2trt tool fails with the following error:
Successfully created plugin: BatchedNMS_TRT
#assertionbatchedNMSPlugin.cpp,70
Looking at the batchedNMSPlugin.cpp file for TensorRT 7.1.3 tag, the error is raised in the BatchedNMSPlugin::getOutputDimensions function, specifically
ASSERT(inputs[0].nbDims == 3);
suggesting that the BatchedNMS plugin is not receiving an input with the shape it expects, which should be the detection boxes.
I'm using TensorRT 7.1 on Jetson Nano.
@pranavm-nvidia any ideas on what could be causing this?
jonakola
on 15 Dec 2020
@xonobo The friendlier error message will be included in the next version of TRT.
@jonakola The first input (boxes) is expected to have a shape of [batch_size, number_boxes, number_classes, number_box_parameters] (see here). Can you double check the input shape?
pranavm-nvidia
on 15 Dec 2020
@pranavm-nvidia the shape of the first input is returning None. Not sure why this is the case.
jonakola
on 15 Dec 2020
@pranavm-nvidia I tried some additional debugging but no luck. On inspecting the netron generated visualizations for the TF model and onnx models, I can see the correct shape for the 'boxes' tensor in the TF saved_model visualization ([4560,4]), but once I convert to onnx with the command I mentioned above, onnx is unable to get the shape of 'boxes', even after running the shape_inference function from the onnx library. I try to set the shape manually for this tensor using onnx_graphsurgeon, but still the conversion to TRT fails on the same assertion as above (inputs[0].nbDims == 3).
jonakola
on 16 Dec 2020
@jonakola The shapes in the ONNX model are mostly for user-convenience IMO (e.g. makes the model easier to understand when viewed). They don't have any impact on the real runtime dimensions, which are dependent on the input shapes and ops alone.
You can try checking TRT's verbose logs to see the actual shape of boxes. That might help narrow down the root cause. Another way would be to print out the input shapes from the plugin with gdb for example.
Another thing to try is running the ONNX model (before inserting plugin nodes) in ONNX-RT. You can use Polygraphy to do so (specifically, the run tool). That will help you determine whether the ONNX model is valid.
pranavm-nvidia
on 16 Dec 2020
@pranavm-nvidia on further debugging as you suggested, I'm able to see that the run time dimensions of 'boxes' are 2. Tracing this tensor back to the original TF model and referencing the TF docs for the non_max_suppression op, I see that 'boxes' in the TF model indeed is 2D by design ([num_boxes, bounding_box]) (https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/image/non_max_suppression). Now it seems that the NonMaxSuppression op in onnx expects a 3D tensor ([num_batches, spatial_dimension, 4]) (https://github.com/onnx/onnx/blob/rel-1.6.0/docs/Operators.md#NonMaxSuppression), and TRT also expects a 3D tensor as documented, with the shape [num_bounding_boxes, num_classes, bounding_box]. In summary, TRT looks like it expects an extra 'num_classes' dimension for the 'boxes' tensor, but it is not obvious where in the TF non max suppression subgraph a tensor with a matching shape to what TRT expects would be generated. Do you have any examples of successful SSD conversions from TF to TRT via onnx? The only end to end examples I have found use uff.
jonakola
on 17 Dec 2020
I have trained a yolov3-tiny model using this repo https://github.com/zzh8829/yolov3-tf2
I was able to append the BatchedNMSDynamic_TRT plugin using graphsurgeon, and ran trtexec to build the engine in tensorrt 7.2.1 on my personal environment. It worked.
But, I have to do this in Jetson Nano, which I realize does not have support for BatchedNMSDynamic plugin. How do I solve this issue? According to @qraleq , freezing the model with input shape specified should work. But I have used tensorflow 2.0, and I use the script from here to freeze the model : https://medium.com/@sebastingarcaacosta/how-to-export-a-tensorflow-2-x-keras-model-to-a-frozen-and-optimized-graph-39740846d9eb
How do I use BatchedNMSDynamic_TRT on Jetson Nano? And if that isnt possible, how do I work around this issue?
 kenrickfernandes
on 19 Dec 2020
kenrickfernandes
on 19 Dec 2020
@jonakola There's a separate op in TF that does take into account multiple classes: https://www.tensorflow.org/api_docs/python/tf/image/combined_non_max_suppression. If your model only has 1 class, then you should be able to unsqueeze the boxes/scores inputs to insert a 1-dimension for num_classes.
@kenrickfernandes If you're using a static input shape, you can use the BatchedNMS_TRT plugin rather than the dynamic shape variant.
pranavm-nvidia
on 28 Dec 2020
Thanks for figuring out the problem but can you share your inspection way, I can not see any log report about the invalid parameter. If you found this case by using Nvidia's internal tools can you add these invalid cases to public log reports in the next release.
Thanks a lot for your help.
Hello xonobo:
Have you convert your best.opt_trt_nms.onnx model to tensorrt successfully? I have encountered the same BatchedNMS_TRT plugin convert problems with you in my yolov3_dynamic_postprocess_nms.onnx model. The code
to add the NMS plugins is like yours.
The following is my adding-NMS-plugin code:
import onnx_graphsurgeon as gs
import onnx
import numpy as np
def append_nms(graph, num_classes, scoreThreshold, iouThreshold, keepTopK):
out_tensors = graph.outputs
bs = out_tensors[0].shape[0]
num_priors = out_tensors[0].shape[1]
nms_attrs = {'shareLocation': True,
'backgroundLabelId': -1,
'numClasses': num_classes,
'topK': 1024,
'keepTopK': keepTopK,
'scoreThreshold': scoreThreshold,
'iouThreshold': iouThreshold,
'isNormalized': True,
'clipBoxes': True}
nms_num_detections = gs.Variable(name="nms_num_detections", dtype=np.int32, shape=(bs, 1))
nms_boxes = gs.Variable(name="nms_boxes", dtype=np.float32, shape=(bs, keepTopK, 4))
nms_scores = gs.Variable(name="nms_scores", dtype=np.float32, shape=(bs, keepTopK))
nms_classes = gs.Variable(name="nms_classes", dtype=np.float32, shape=(bs, keepTopK))
nms = gs.Node(op="BatchedNMSDynamic_TRT", attrs=nms_attrs, inputs=out_tensors, outputs=[nms_num_detections, nms_boxes, nms_scores, nms_classes])
graph.nodes.append(nms)
graph.outputs = [nms_num_detections, nms_boxes, nms_scores, nms_classes]
return graph
def add_nms_to_onnx(model_file, num_classes, confidenceThreshold=0.3, nmsThreshold=0.6, keepTopK=100, opset=11):
graph = gs.import_onnx(onnx.load(model_file))
graph = append_nms(graph, num_classes, confidenceThreshold, nmsThreshold, keepTopK)
# Remove unused nodes, and topologically sort the graph.
graph.cleanup().toposort().fold_constants().cleanup()
# Export the onnx graph from graphsurgeon
out_name = model_file[:-5]+'_nms.onnx'
onnx.save_model(gs.export_onnx(graph), out_name)
print("Saving the ONNX model to {}".format(out_name))
if __name__ == "__main__":
model_file = "yolov3_dynamic_postprocess.onnx"
add_nms_to_onnx(model_file, 80, confidenceThreshold=0.3, nmsThreshold=0.6, keepTopK=100, opset=11)
and my onnx graph is as below(model file is too big to upload).
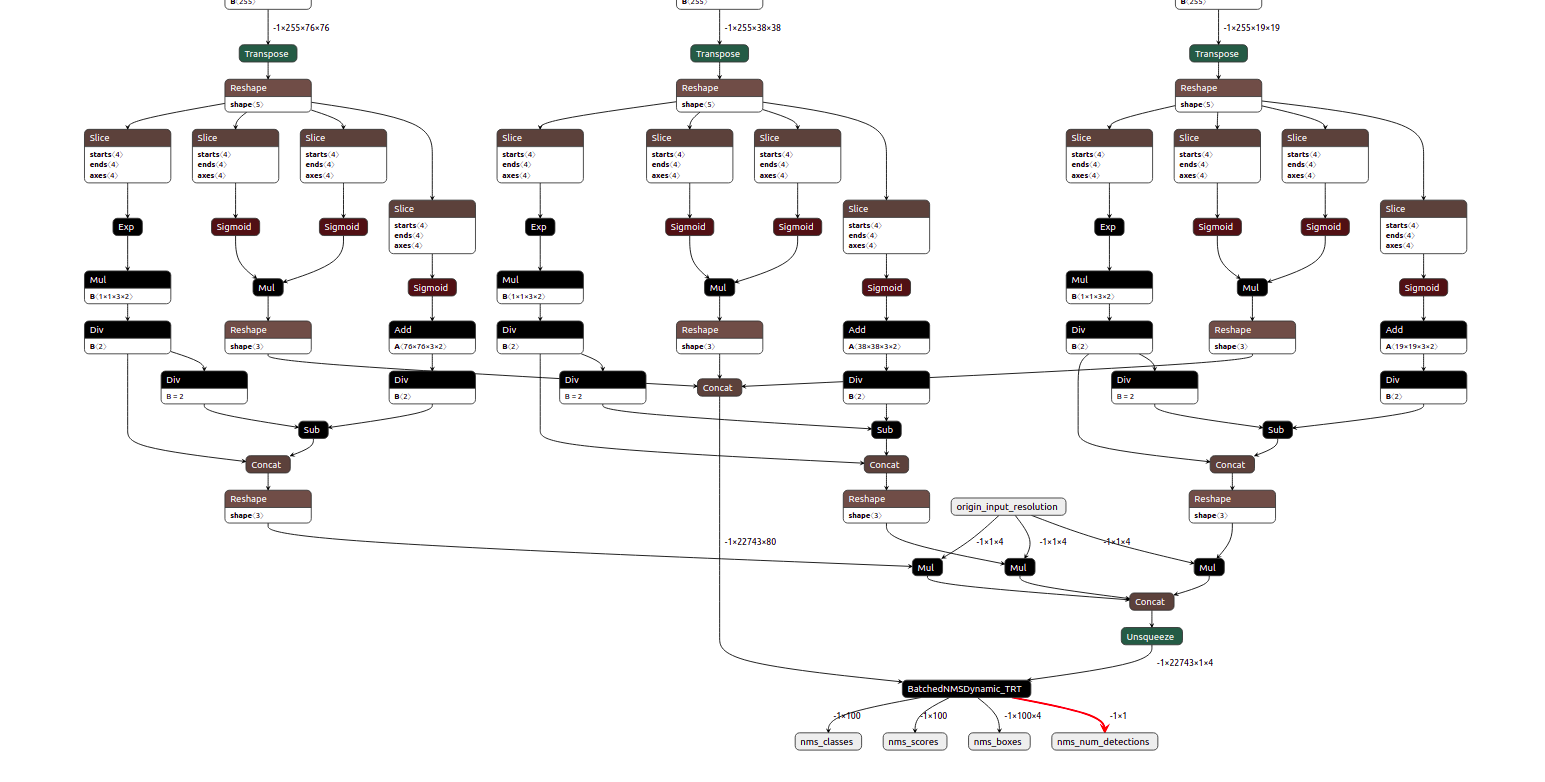
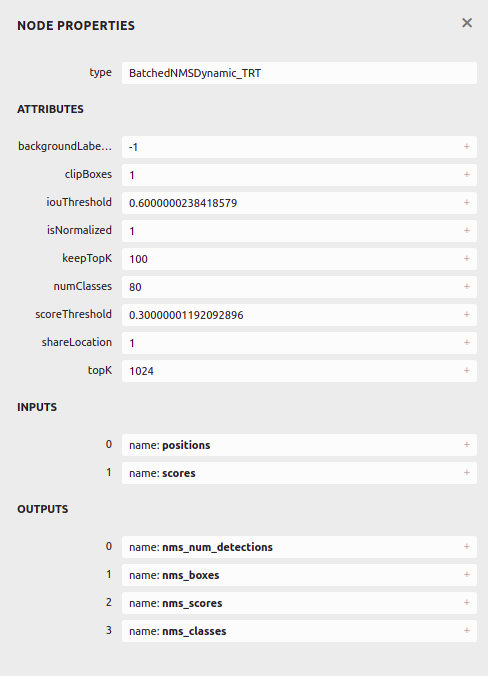
I put the onnx file in Google Drive
My convert environment is docker image(nvcr.io/nvidia/tensorrt:20.12-py3), tensorrt 7.2.2.
The GPU is Tesla M40. GPU Driver version is 455.38. CUDA version is 11.1
Look forward to your reply!
@pranavm-nvidia Can you give me some suggestions?
 MAhaitao999
on 30 Dec 2020
MAhaitao999
on 30 Dec 2020
@jonakola There's a separate op in TF that does take into account multiple classes: https://www.tensorflow.org/api_docs/python/tf/image/combined_non_max_suppression. If your model only has 1 class, then you should be able to unsqueeze the boxes/scores inputs to insert a 1-dimension for
num_classes.@kenrickfernandes If you're using a static input shape, you can use the
BatchedNMS_TRTplugin rather than the dynamic shape variant.
@pranavm-nvidia Unfortunately, when using BatchedNMS_TRT i get the "PluginV2Layer must be V2DynamicExt when there are dynamic shapes" even though the input shape is not dynamic. I guess it is because the shapes of the intermediate layers is dynamic. Is there no other way to use the dynamic plugin on jetson nano?
kenrickfernandes
on 30 Dec 2020
The suggestion here is mandatory for getting _batchedNMSPlugin_ to work with YOLOv4, at least for the standalone version. Even for static shape input, one must use "BatchedNMSDynamic_TRT" in lieu of "BatchedNMS_TRT" or else would incur the wrath of "PluginV2Layer must be V2DynamicExt...".
 jstumpin
on 14 Jan 2021
jstumpin
on 14 Jan 2021
Hi, @pranavm-nvidia, I tried using the ONNX-GS method as you proposed and I've successfully replaced the NMS operator with BatchedNMS_TRT using the following code:
import onnx_graphsurgeon as gs import onnx import numpy as np input_model_path = "model.onnx" output_model_path = "model_gs.onnx" @gs.Graph.register() def trt_batched_nms(self, boxes_input, scores_input, nms_output, share_location, num_classes): boxes_input.outputs.clear() scores_input.outputs.clear() nms_output.inputs.clear() attrs = { "shareLocation": share_location, "numClasses": num_classes, "backgroundLabelId": 0, "topK": 116740, "keepTopK": 100, "scoreThreshold": 0.3, "iouThreshold": 0.6, "isNormalized": True, "clipBoxes": True } return self.layer(op="BatchedNMS_TRT", attrs=attrs, inputs=[boxes_input, scores_input], outputs=[nms_output]) graph = gs.import_onnx(onnx.load(input_model_path)) graph.inputs[0].shape=[1,1280,720,3] print(graph.inputs[0].shape) for inp in graph.inputs: inp.dtype = np.int input = graph.inputs[0] tmap = graph.tensors() graph.trt_batched_nms(tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1712:0"], tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores/NonMaxSuppressionV5__1761:0"], tmap["NonMaxSuppression__1763:0"], share_location=False, num_classes=4) graph.trt_batched_nms(tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1712:0"], tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_1/NonMaxSuppressionV5__1737:0"], tmap["NonMaxSuppression__1739:0"], share_location=False, num_classes=4) graph.trt_batched_nms(tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1712:0"], tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1713:0"], tmap["NonMaxSuppression__1715:0"], share_location=False, num_classes=4) graph.trt_batched_nms(tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/NonMaxSuppressionV5__1712:0"], tmap["Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_3/NonMaxSuppressionV5__1689:0"], tmap["NonMaxSuppression__1691:0"], share_location=False, num_classes=4) # Remove unused nodes, and topologically sort the graph. # graph.cleanup() # graph.toposort() # graph.fold_constants().cleanup() # Export the ONNX graph from graphsurgeon onnx.checker.check_model(gs.export_onnx(graph)) onnx.save_model(gs.export_onnx(graph), output_model_path) print("Saving the ONNX model to {}".format(output_model_path))The problem I'm currently facing is that
onnx.checker.check_model(gs.export_onnx(graph))function returns following error:onnx.onnx_cpp2py_export.checker.ValidationError: Node (NonMaxSuppression__1763) has output size 0 not in range [min=1, max=1]. ==> Context: Bad node spec: input: "const_fold_opt__2119" input: "Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_3/iou_threshold:0" input:"Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/non_max_suppression_with_scores_2/score_threshold:0" name: "NonMaxSuppression__1763" op_type: "NonMaxSuppression"I think that the problem is in
builtin_op_importers.cpp, where I added this code similar to #523:{ DEFINE_BUILTIN_OP_IMPORTER(NonMaxSuppression) // NonMaxSuppression is not supported opset below 10. ASSERT(ctx->getOpsetVersion() >= 10, ErrorCode::kUNSUPPORTED_NODE); nvinfer1::ITensor* boxes_tensor = &convertToTensor(inputs.at(0), ctx); nvinfer1::ITensor* scores_tensor = &convertToTensor(inputs.at(1), ctx); const int numInputs = inputs.size(); LOG_ERROR("no of inputs are "<<numInputs); LOG_ERROR("node outsize and op type are "<<node.output().size()<< " type " << node.op_type()); const auto scores_dims = scores_tensor->getDimensions(); const auto boxes_dims = boxes_tensor->getDimensions(); LOG_ERROR("boxes dims "<< boxes_dims.nbDims << " dim3 has size "<<boxes_dims.d[2]); const std::string pluginName = "BatchedNMS_TRT"; const std::string pluginVersion = "1"; std::vector<nvinfer1::PluginField> f; /* bool share_location = true; const bool is_normalized = true; const bool clip_boxes = true; int backgroundLabelId = 0; // Initialize. f.emplace_back("shareLocation", &share_location, nvinfer1::PluginFieldType::kINT8, 1); f.emplace_back("isNormalized", &is_normalized, nvinfer1::PluginFieldType::kINT8, 1); f.emplace_back("clipBoxes", &clip_boxes, nvinfer1::PluginFieldType::kINT8, 1); f.emplace_back("backgroundLabelId", &backgroundLabelId, nvinfer1::PluginFieldType::kINT32, 1); */ // Create plugin from registry //nvinfer1::IPluginV2* plugin = importPluginFromRegistry(ctx, pluginName, pluginVersion, node.name$ nvinfer1::IPluginV2* plugin = createPlugin(node.name(), importPluginCreator(pluginName, pluginVers$ ASSERT(plugin != nullptr && "NonMaxSuppression plugin was not found in the plugin registry!", ErrorCode::kUNSUPPORTED_NODE); std::vector<nvinfer1::ITensor*> nms_inputs ={boxes_tensor, scores_tensor}; RETURN_FIRST_OUTPUT(ctx->network()->addPluginV2(nms_inputs.data(), nms_inputs.size(), *plugin)); }Do you have an example of properly registering BatchedNMS_TRT as a plugin?
Also, do you have end to end example of replacing BatchedNMS with a TRT version?
Here positioning the output clearing code inside the register function could cause unexpected behavior if there are common inputs and outputs for NMS nodes.
boxes_input.outputs.clear()
scores_input.outputs.clear()
nms_output.inputs.clear()
It's good to place it somewhere outside the function and do it only once for each input or output. I polished up @qraleq's code if anyone wants to use it. @jonakola maybe this is the issue ?
import onnx_graphsurgeon as gs
import onnx
import numpy as np
input_model_path = "model/onnxmodel/ssd-mobilenet-v2-fpnlite_updated.onnx"
output_model_path = "model/onnxmodel/ssd-mobilenet-v2-fpnlite_updated_nms3.onnx"
@gs.Graph.register()
def trt_batched_nms(self, boxes_input, scores_input, nms_output,
share_location, num_classes):
attrs = {
"shareLocation": share_location,
"numClasses": num_classes,
"backgroundLabelId": -1,
"topK": 1024,
"keepTopK": 100,
"scoreThreshold": 0.0001,
"iouThreshold": 0.6,
"isNormalized": True,
"clipBoxes": True
}
return self.layer(op="BatchedNMS_TRT", attrs=attrs,
inputs=[boxes_input, scores_input],
outputs=[nms_output])
graph = gs.import_onnx(onnx.load(input_model_path))
#graph.inputs[0].shape=[1,320,320,3]
print(graph.inputs[0].shape)
for inp in graph.inputs:
inp.dtype = np.float32
#input = graph.inputs[0]
tmap = graph.tensors()
boxt = "Unsqueeze__695:0"
scores_list = ["Unsqueeze__798:0", "Unsqueeze__764:0", "Unsqueeze__730:0", "Unsqueeze__696:0", "Unsqueeze__662:0", "Unsqueeze__628:0"]
nms_list = ["NonMaxSuppression__800:0", "NonMaxSuppression__766:0", "NonMaxSuppression__732:0", "NonMaxSuppression__698:0", "NonMaxSuppression__664:0", "NonMaxSuppression__630:0"]
def clear_tensors(boxt, scores_list, nms_list):
tmap[boxt].outputs.clear()
for score, nms in zip(scores_list, nms_list):
tmap[score].outputs.clear()
tmap[nms].inputs.clear()
def replace_op(boxt, scores_list, nms_list):
for score, nms in zip(scores_list, nms_list):
graph.trt_batched_nms(tmap[boxt],
tmap[score],
tmap[nms],
share_location=False,
num_classes=6)
clear_tensors(boxt, scores_list, nms_list)
replace_op(boxt, scores_list, nms_list)
# Remove unused nodes, and topologically sort the graph.
graph.cleanup()
graph.toposort()
# graph.fold_constants().cleanup()
# Export the ONNX graph from graphsurgeon
#onnx.checker.check_model(gs.export_onnx(graph))
onnx.save_model(gs.export_onnx(graph), output_model_path)
print("Saving the ONNX model to {}".format(output_model_path))
 t-T-s
on 25 Jan 2021
t-T-s
on 25 Jan 2021
Hi @pranavm-nvidia. Can you please take a look at this issue also. jetson-inference/issues/896# It's very similar to this. I should have posted it here. Thank you in advance.
t-T-s
on 25 Jan 2021
@t-T-s Do you know which assertion is failing? It may have already been fixed by this commit.
pranavm-nvidia
on 25 Jan 2021
Hello @pranavm-nvidia. Thank you for the quick reply. From the log line #assertionbatchedNMSPlugin.cpp,70 I think the assertion is in line 70. Also it's under BatchedNMSDynamicPlugin. I really don't want any dynamic input shapes. I don't know why it became dynamic.
t-T-s
on 25 Jan 2021
I'm not sure if that's the right line - that constructor is only called during engine deserialization. The parser calls createPlugin, which should be using the other constructor.
Are you sure this is the commit of TRT you built against? The lines may have shifted due to changes in the code.
Looking at your verbose logs, it seems more likely that this assertion is being violated since your second input is:
Unsqueeze__798:0 -> (1, 1, 59752)
I'm guessing that the assertion is an artifact of the implicit batch dimension implementation. In older versions of TRT, the batch dimension was not part of the network, and was instead implicitly prepended. That's why the assertion is expecting the input shape to be [number_boxes, number_classes] instead of [batch_size, number_boxes, number_classes]. The ONNX parser dropped support for implicit batch networks a while ago, so you'd probably want to use the BatchedNMSDynamic_TRT plugin even if you don't have dynamic input shapes.
pranavm-nvidia
on 25 Jan 2021
@pranavm-nvidia That's very insightful. I am actually using the Jetson Nano (Jetpack 4.4.1) with tensorRT version 7.1.3.0-1+cuda10.2. So I'm not sure how to update it to that particular commit. Actually the problem is with this line. I am very sorry for the mishap.
so you'd probably want to use the BatchedNMSDynamic_TRT plugin even if you don't have dynamic input shapes.
In this case I'm afraid the plugin is simply not available for the current version. Is there any workaround ? Thank you in advance.
t-T-s
on 25 Jan 2021
The BatchedNMSDynamic should be available on 7.1. AFAICT, there's nothing platform specific about it, so I'm not sure why it wouldn't be available on Jetpack. Maybe you can try building the plugin from source?
pranavm-nvidia
on 27 Jan 2021
Hi @pranavm-nvidia, I trying to convert object detection models from ONNX model Zoo (Faster-RCNN, Yolov3-10, and Yolov4) to TensorRT INT8 but getting several errors I think related to custom layers included in these models. Are there samples that show how to convert these models?. I am using TensorRT 7.0.0 (getting similar or related errors with TensorRT 7.2.1). See below the errors:
With TensorRT 7.0.0:
FasterRCNN-10.onnx
$ trtexec --onnx=onnx-tensorrt/models/FasterRCNN-10.onnx --explicitBatch --verbose
while parsing node number 413 [Resize -> "416"]:
--- Begin node ---
input: "388"
input: "415"
output: "416"
name: "415"
op_type: "Resize"
attribute {
name: "mode"
s: "nearest"
type: STRING
}
--- End node ---
ERROR: /workspace/onnx-tensorrt/builtin_op_importers.cpp:2540 In function importResize:
[8] Assertion failed: scales.is_weights() && "Resize scales must be an initializer!"
[01/27/2021-15:42:03] [E] Failed to parse onnx file
[01/27/2021-15:42:03] [E] Parsing model failed
[01/27/2021-15:42:03] [E] Engine creation failed
[01/27/2021-15:42:03] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec # trtexec --onnx=onnx-tensorrt/models/FasterRCNN-10.onnx --explicitBatch --verbose
YOLOV3-10
$ trtexec --onnx=onnx-tensorrt/models/yolov3-10.onnx
Input filename: onnx-tensorrt/models/yolov3-10.onnx
ONNX IR version: 0.0.5
Opset version: 10
Producer name: keras2onnx
Producer version: 1.5.1
Domain: onnx
Model version: 0
Doc string:
----------------------------------------------------------------
[01/27/2021-15:43:33] [W] [TRT] /workspace/onnx-tensorrt/onnx2trt_utils.cpp:235: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[01/27/2021-15:43:33] [W] [TRT] /workspace/onnx-tensorrt/onnx2trt_utils.cpp:261: One or more weights outside the range of INT32 was clamped
[01/27/2021-15:43:33] [W] [TRT] /workspace/onnx-tensorrt/onnx2trt_utils.cpp:261: One or more weights outside the range of INT32 was clamped
While parsing node number 467 [NonMaxSuppression]:
ERROR: /workspace/onnx-tensorrt/ModelImporter.cpp:134 In function parseGraph:
[8] No importer registered for op: NonMaxSuppression
[01/27/2021-15:43:34] [E] Failed to parse onnx file
[01/27/2021-15:43:34] [E] Parsing model failed
[01/27/2021-15:43:34] [E] Engine creation failed
[01/27/2021-15:43:34] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec # trtexec --onnx=onnx-tensorrt/models/yolov3-10.onnx
YOLOV4
$ trtexec --onnx=onnx-tensorrt/models/yolov4.onnx
Input filename: onnx-tensorrt/models/yolov4.onnx
ONNX IR version: 0.0.6
Opset version: 11
Producer name: tf2onnx
Producer version: 1.7.0
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
[01/27/2021-15:44:39] [W] [TRT] /workspace/onnx-tensorrt/onnx2trt_utils.cpp:235: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
While parsing node number 487 [Resize]:
ERROR: /workspace/onnx-tensorrt/builtin_op_importers.cpp:2520 In function importResize:
[8] Assertion failed: (transformationMode == "asymmetric") && "This version of TensorRT only supports asymmetric resize!"
[01/27/2021-15:44:39] [E] Failed to parse onnx file
[01/27/2021-15:44:39] [E] Parsing model failed
[01/27/2021-15:44:39] [E] Engine creation failed
[01/27/2021-15:44:39] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec # trtexec --onnx=onnx-tensorrt/models/yolov4.onnx
 vilmara
on 27 Jan 2021
vilmara
on 27 Jan 2021
@vilmara The Resize errors are limitations of TensorRT. @ttyio might be able to comment on those
As for the NMS, you can replace it with a plugin node as outlined in previous comments on this post. The TRT packages also include an onnx_packnet example that shows how to use plugins with ONNX models.
pranavm-nvidia
on 27 Jan 2021
@pranavm-nvidia, thanks for your prompt reply. Basically, it is recommended to work with YOLOV3-10 model and replace the NMS ops with the plugin node. Here some extra questions:
1 - What plugin should I use with YOLOV3-10: batchedNMSPlugin, nmsPlugin or batchedNMSDynamicPlugin?
2- Does yolov3_onn example show also how to use plugins with ONNX models as the example onnx_packnet?, which one should I try first?
vilmara
on 27 Jan 2021
@vilmara
- You'd probably want
BatchedNMSDynamic. You can find more information here (the README is for the non-dynamic variant, but the dynamic version has pretty much the same interface). - The ONNX model included in the
yolov3_onnxexample works out of the box with TRT, so it doesn't require plugins. I thinkonnx_packnetwould be a better place to start. Having said that, since your issue is specific to NMS, the code snippets shared in previous comments might be more useful than either of those two examples.
pranavm-nvidia
on 27 Jan 2021
@pranavm-nvidia, thanks I will try first with the code shared here. Also, are there some benchmarks or numbers that give me an idea about the expected performance with the unoptimized yolov3 model vs the optimized model with TensorRT NMS INT8?
vilmara
on 27 Jan 2021
I don't know if there are benchmarks for yolov3 + int8 specifically, but there are several numbers published from MLPerf Inference here. The official results show other frameworks as well.
pranavm-nvidia
on 27 Jan 2021
Hello @vilmara , there is known issue for resize in TRT, and we will fix in next major release, we also have a workaround, see more detail in https://github.com/NVIDIA/TensorRT/issues/974#issuecomment-754323987, thanks
 ttyio
on 28 Jan 2021
ttyio
on 28 Jan 2021
Related issues
 dhkim0225
·
6Comments
dhkim0225
·
6Comments
 float123
·
6Comments
float123
·
6Comments
 ycchanau
·
3Comments
ycchanau
·
3Comments
 peijason
·
3Comments
dhkim0225
·
4Comments
peijason
·
3Comments
dhkim0225
·
4Comments
Most helpful comment
@jonakola You should use the
BatchedNMSDynamic_TRTplugin if you have dynamic shapes. This plugin is supported in TensorRT version > 7.2.Since I'm using NVIDIA Jetsons which do not support this plugin at the moment, I ended up freezing the TensorFlow model to a fixed shape, and then everything worked out as supposed.