Tensorrt: BERT demo --fp16 build error: ERROR: (Unnamed Layer* 2) [PluginV2DynamicExt]: could not find any supported formats consistent with input/output data types
Description
While repeating the demo of BERT large
python3 builder.py -m /workspace/TensorRT/demo/BERT/models/fine-tuned/bert_tf_v2_large_fp16_128_v2/model.ckpt-8144 -o /workspace/TensorRT/demo/BERT/engines/bert_large_128.engine -b 1 -s 128 --fp16 -c /workspace/TensorRT/demo/BERT/models/fine-tuned/bert_tf_v2_large_fp16_128_v2
results in error:
[TensorRT] INFO: Using configuration file: /workspace/TensorRT/demo/BERT/models/fine-tuned/bert_tf_v2_large_fp16_128_v2/bert_config.json
[TensorRT] INFO: Found 394 entries in weight map
[TensorRT] ERROR: ../builder/cudnnBuilderGraphNodes.cpp (743) - Misc Error in reportPluginError: 0 (could not find any supported formats consistent with input/output data types)
[TensorRT] ERROR: ../builder/cudnnBuilderGraphNodes.cpp (743) - Misc Error in reportPluginError: 0 (could not find any supported formats consistent with input/output data types)
[TensorRT] INFO: build engine in 2.248 Sec
Traceback (most recent call last):
File "builder.py", line 691, in
main()
File "builder.py", line 682, in main
with build_engine(args.batch_size, args.workspace_size, args.sequence_length, config, weights_dict, args.squad_json, args.vocab_file, calib_cache, args.calib_num) as engine:
AttributeError: __enter__
If removing '--fp16' fp32 build works without a problem.
Thanks!
Environment
TensorRT Version: 7.1.3.4 (tar installation)
GPU Type: V100 PCIE 16GB
Nvidia Driver Version: 450.36.06
CUDA Version: 11.0
CUDNN Version: 8
Operating System + Version: ubuntu 16.04 4.4.0-184-generic
Python Version (if applicable): 3.7
TensorFlow Version (if applicable): 1.15
PyTorch Version (if applicable): 1.6
Baremetal or Container (if container which image + tag): baremetal
Relevant Files
Steps To Reproduce
I just followed the README in demo/BERT, except my environment is bare-metal not container.
 srqj
srqj
All 13 comments
Same problem,+10086
 MrRace
on 31 Jul 2020
MrRace
on 31 Jul 2020
Same problem,+10087.
 winself
on 6 Aug 2020
winself
on 6 Aug 2020
@srqj are you using master branch or the release/7.1 branch?
 ttyio
on 1 Sep 2020
ttyio
on 1 Sep 2020
@srqj @MrRace @winself can you please confirm you are using TOT (specifically if you have this commit: https://github.com/NVIDIA/TensorRT/commit/4b918415339e4210013021616cbb571b1776959c)
 rajeevsrao
on 1 Sep 2020
rajeevsrao
on 1 Sep 2020
@srqj are you using master branch or the
release/7.1branch?
I use the release/7.1
MrRace
on 2 Sep 2020
@srqj @MrRace @winself can you please confirm you are using TOT (specifically if you have this commit: 4b91841)
My builder.py :
 MrRace
on 2 Sep 2020
MrRace
on 2 Sep 2020
@srqj are you using master branch or the
release/7.1branch?
Thanks for your reply, yes I'm using the master branch 6be3234.
srqj
on 2 Sep 2020
@srqj @MrRace @winself can you please confirm you are using TOT (specifically if you have this commit: 4b91841)
Thanks for your reply! Yes, my branch (master 6be3234) contains the commit 4b91841.
srqj
on 2 Sep 2020
@srqj @MrRace @winself
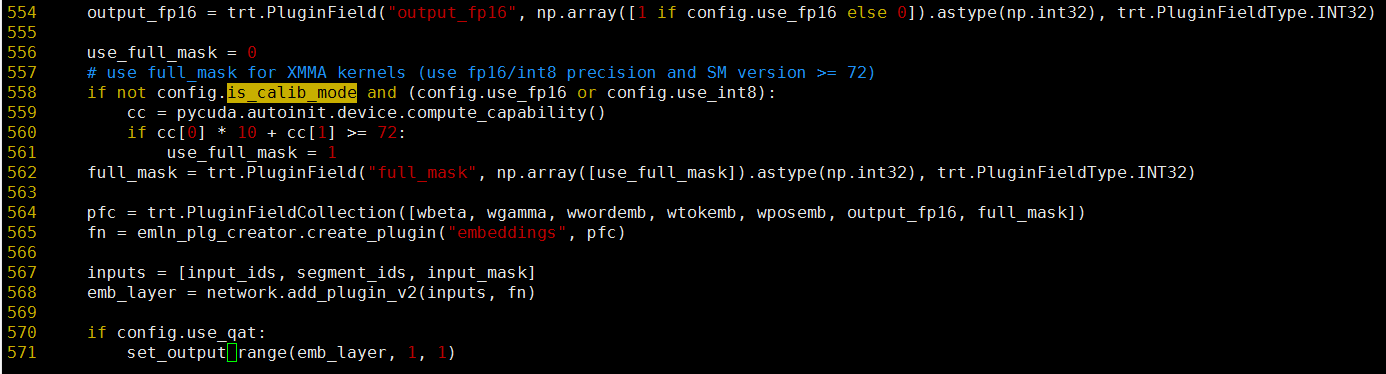
Add full_mask filed will pass the engine build step.
@ttyio @rajeevsrao Plz fix the bug.....
In embLayerNormPlugin.cpp, full_mask field is still used which is removed in 4b91841.
output_fp16 = trt.PluginField("output_fp16", np.array([1 if config.use_fp16 else 0]).astype(np.int32), trt.PluginFieldType.INT32)
full_mask = trt.PluginField("full_mask", np.array([1 if config.use_fp16 else 0]).astype(np.int32), trt.PluginFieldType.INT32)
mha_type = trt.PluginField("mha_type_id", np.array([get_mha_dtype(config)], np.int32), trt.PluginFieldType.INT32)
pfc = trt.PluginFieldCollection([wbeta, wgamma, wwordemb, wtokemb, wposemb, output_fp16, full_mask, mha_type])
fn = emln_plg_creator.create_plugin("embeddings", pfc)
 fumihwh
on 25 Oct 2020
fumihwh
on 25 Oct 2020
Hello @fumihwh , thanks for helping.
Here is more details:
In release/7.1, the multi-head-attention plugin can accelerated using fused kernel (using tensorcore) when match condition:
- precision is fp16 or int8
- slen is 128 or 384
- sm arch is Turing or Ampere
the the full_mask is used for embLayerNorm plugin to generate mask that support the tensorcore layout. And we have a bug in the release/7.1 , we only check the first two condition in the plugin.
We found this issue after TRT 7.1 is released to devzone, before open source 7.1 release. To keep the consistence between dev zone binary binary release and open source release, so we have to remove the sm arch check in the builder.py to make the script work, but actually we observe accuracy loss in Volta.
And the commit 4b91841 is checked in after the opensource 7.1 release, it contains fixes to other plugins/samples. However, It introduced an incompatible fix to check the sm arch for builder.py in bert. This is the reason why you see the error. We will revert this part to fix the issue in release/7.1. But the accuracy drop is still there because we will run a unfused multi-head-attention kernel run with a tensorcore mask layout...
@srqj @MrRace @winself , to get the decent accuracy, please use release/7.2, now we deprecated the fragile field full_mask, we have mha_type_id field to specify the type of multi-head-attention, and the mask layout is computed in one place only (inside the plugin implementation). Also we have more specified sequence length that support tensorcore if you are using Turing+ chips. Could you take a try? thanks!
ttyio
on 26 Oct 2020
@ttyio
I've tried nvcr.io/nvidia/tensorrt:20.10-py3(TensorRT 7.2.1), it works for me.
fumihwh
on 26 Oct 2020
@ttyio
I've tried nvcr.io/nvidia/tensorrt:20.10-py3(TensorRT 7.2.1), it works for me.
Thank you @fumihwh
ttyio
on 26 Oct 2020
I will close issue since we have policy to close issue with no activity for more than 3 weeks. Please reopen if you still have questions. Thanks!
ttyio
on 12 Jan 2021
Related issues
 aininot260
·
3Comments
aininot260
·
3Comments
 AlphaJia
·
3Comments
AlphaJia
·
3Comments
 lapolonio
·
5Comments
lapolonio
·
5Comments
 prathik-naidu
·
3Comments
prathik-naidu
·
3Comments
 WangXuanBT
·
3Comments
WangXuanBT
·
3Comments
Most helpful comment
@srqj @MrRace @winself
Add full_mask filed will pass the engine build step.
@ttyio @rajeevsrao Plz fix the bug.....
In
embLayerNormPlugin.cpp,full_maskfield is still used which is removed in 4b91841.