Tensor2tensor: Why add positional embedding instead of concatenate?
Apart from saving some memory, is there any reason we are adding the positional embeddings instead of concatenating them. It seems more intuitive concatenate useful input features, instead of adding them.
From another perspective, how can we be sure that the Transformer network can separate the densely informative word embeddings and the position information of pos encoding?
 Akella17
Akella17
All 5 comments
Interesting questions with no simple answers. Just a few comments:
- I would guess someone has already tried summing PE (positional embeddings/encoding) and WE (word embeddings) instead of concatenating, but I am not aware of any publications with results and comparison. Technically it is simple: you need to add a projection layer to squeeze the dimension to the original size, which means extra parameters, but this should not be a problem for training (and memory-wise it should be fine as well). Alternatively, you could train WE and PE with smaller dimensions, so their concatenation has the original hidden size. In both ways, you can experiment with giving more dimensions to WE than to PE (and making sure PE uses all the dimensions effectively, see below).
By default, T2T uses max_timescale=10,000, i.e. the 10,001st word has the same PE as the first word. However, with the maximum sequence length of about 20 and hidden_size=512 (for transformer_base, and 1024 for big), most of the dimensions are used only by WE and the contribution of PE is almost constant (either 0 or 1). See a visualization of PE taken from https://jalammar.github.io/illustrated-transformer/#representing-the-order-of-the-sequence-using-positional-encoding
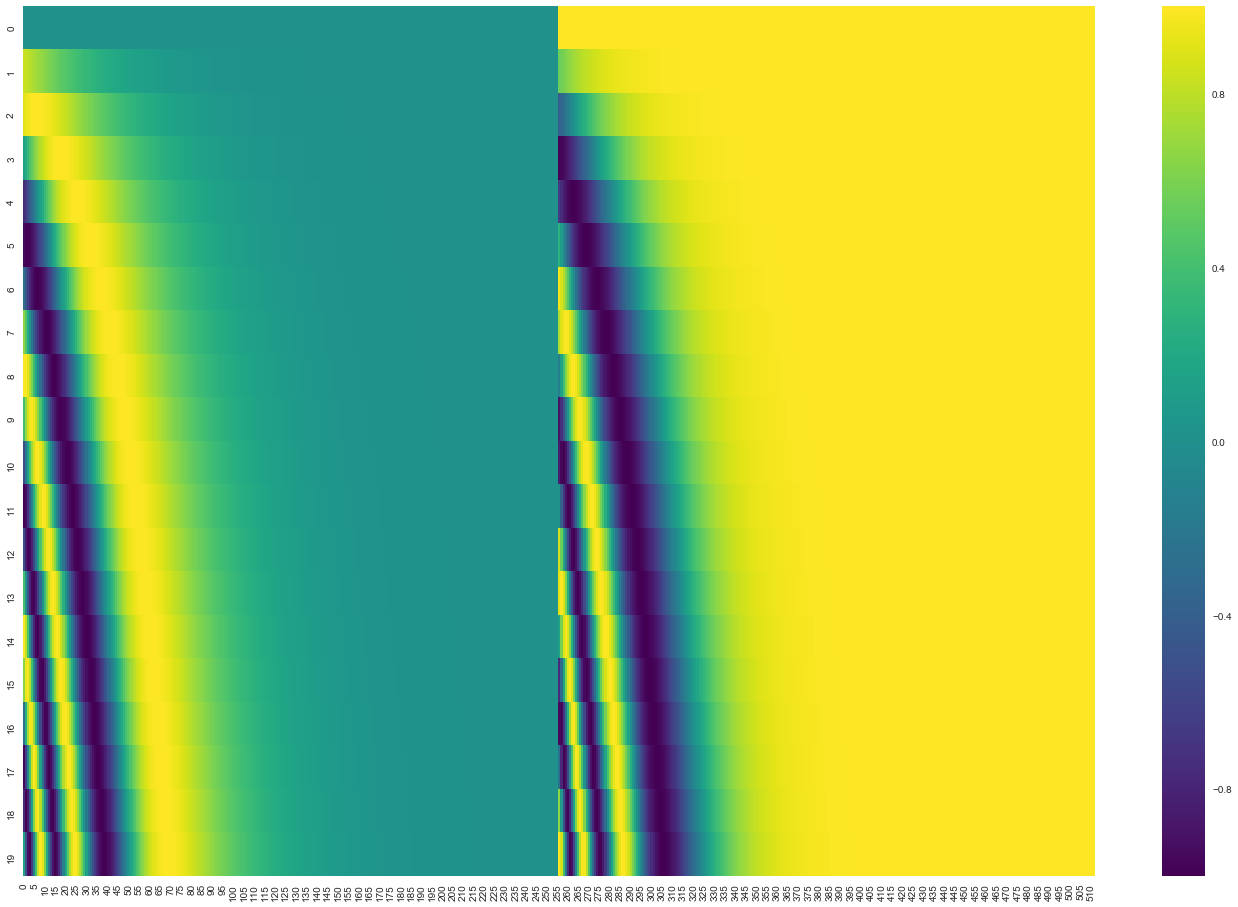
Note that in Transformer, WE are trained from scratch with the PE summing, so it is probable that WE are trained so they don't encode any important information in the first few dimensions because these dimensions are used intensively by PE. Thus, when using not-too-long sequences, the current T2T code is (or _can be_, see below) effectively very similar to concatenation and it would be easy to separate the PE and WE information.
- Based on your question "how can we be sure that the Transformer network can separate [WE and PE]", it seems you consider the separability as an advantage. But what if the interaction between WE and PE (in some dimensions) caused by summing is beneficial for the final Transformer? Maybe some WE properties should be encoded differently for words which are on a specific position (modulo sin/cos period) in a sentence. I have seen positive effects (and sometimes also negative) of summing over concatenation in various tasks, e.g. summing left-to-right and right-to-left LSTM states or summing character-based and word-based embeddings. It is difficult for me to imagine examples of synergy caused by summing WE and PE, but that may be just a limitation of my imagination. Note that thanks to skip connections, PE+WE information is propagated to further layers of Transformer encoder, where syntactic phenomena are handled (I am thinking about MT), thus there are more opportunities for the synergy.
- It would be very interesting to explore this and what are the properties of WE trained with different versions of Transformer (relative to e.g. word2vec WE). And comparing it also with the relative-position Transformer.
 martinpopel
on 30 May 2019
martinpopel
on 30 May 2019
Hey, thanks for the detailed reply. When WE are learnable parameters, I agree that the transformer training might model them such that the information of WE and PE is preserved (recoverable by transformer) even after addition. Like you suggested, maybe the transformer might also learn useful features from the addition of WE and PE.
However, my original doubt still persists. Why not just concatenate? Like you suggested, we can add a projection layer to bring the input dimension to transformer hidden size. The advantage of an additional layer is that is can model more complicated relationships b/w WE and PE (including simple addition obviously). However, this advantage comes at the cost of additional parameters, which in most cases is a trivial increment to memory consumption, given the size of a (practical) transformer.
Akella17
on 1 Jun 2019
If you find a good answer for not contaminating can you please refer to it in here.
 Khaled-Abdelhamid
on 28 May 2020
Khaled-Abdelhamid
on 28 May 2020
While we're discussing the relative merits of "concat then project to D" or "project to D and sum", couldn't we go one step further and decide the mixture of WE and PE via attention? Each projects keys and values, query is projected from global context or from WE.
 sooheon
on 16 Oct 2020
sooheon
on 16 Oct 2020
Perhaps because theses sums form a cloud around a point in word embedding carrying information about position occurrences. Think, for example, of the an word in a 1D embedding and suppose that words are evenly spaced: 1.0, 2.0, 3.0, ... If you sum a sequence of equally spaced small numbers that represent distances from sequence beginning to one of them, let's say, 0.01, 0.02, 0.03, ..., you'll have a cluster of position information around the number that encodes the word. For instance, 1.01, 1.02, 1.05, ..., encode the same word in different positions. If the granularity of the encodings is different you can get such result.
 CarlosEduardoSaMotta
on 3 Dec 2020
CarlosEduardoSaMotta
on 3 Dec 2020
Related issues
 draplater
·
4Comments
draplater
·
4Comments
 activatedgeek
·
4Comments
activatedgeek
·
4Comments
 mehmedes
·
3Comments
mehmedes
·
3Comments
 mirkobronzi
·
4Comments
mirkobronzi
·
4Comments
 anglil
·
5Comments
anglil
·
5Comments
Most helpful comment
Hey, thanks for the detailed reply. When WE are learnable parameters, I agree that the transformer training might model them such that the information of WE and PE is preserved (recoverable by transformer) even after addition. Like you suggested, maybe the transformer might also learn useful features from the addition of WE and PE.
However, my original doubt still persists. Why not just concatenate? Like you suggested, we can add a projection layer to bring the input dimension to transformer hidden size. The advantage of an additional layer is that is can model more complicated relationships b/w WE and PE (including simple addition obviously). However, this advantage comes at the cost of additional parameters, which in most cases is a trivial increment to memory consumption, given the size of a (practical) transformer.