Tensor2tensor: Can I get a word-alignment list through Transformer in nmt work?
Description
I want to get a word-alignment list in nmt system, but I don't know how to do this. Can this framework achieve my goal?
 dean248248
dean248248
All 2 comments
See the hello_t2t IPython notebook at Google Colab and in the "Display Attention" section choose "Input - Output" instead of "All" from the menu.
This will visualize the encoder-decoder attention, which is the closest thing to word alignment you can get out of the box (as far as I know).
As you can see, this is very different from the word alignment you expected:
- The attention is fuzzy, you would need to threshold it (or choose max) to get binary alignment (aligned or not aligned).
- There are multiple attention heads and most of them seem to be unrelated to word alignment.
- It is well known the attention may be shifted by one (esp. in case of LSTMs, which is not the case here, so I am not sure)
- I am afraid the visualization code contains a bug as the there are attention positions with no tokens shown or the other way round (try entering a different sentence).
- The attention is between subwords, not words. More precisely, it is between positions corresponding to subwords, but enc-dec attention connects the deepest layer, where the vector representation on each position represents theoretically the whole sentence (with different emphasis on different parts), not just the "current" subword.
Of course, you could train a new T2T model in the "old NMT way": restrict the number of enc-dec attention heads to 1, use words (with UNK) instead of subwords,... and get much worse MT quality, but with a better interpretable enc-dec attention.
 martinpopel
on 26 Jun 2018
martinpopel
on 26 Jun 2018
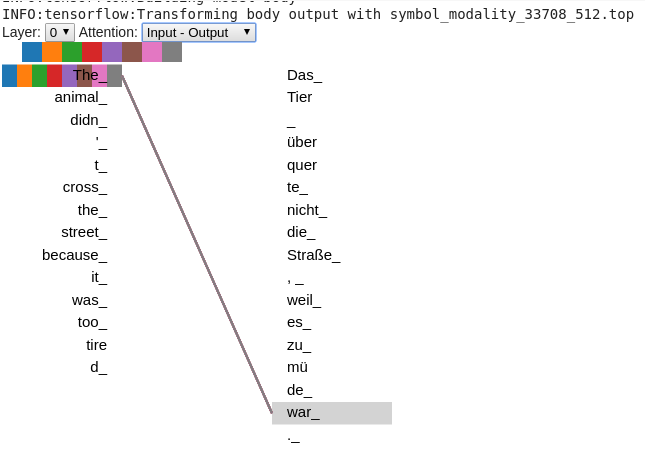
Using the same visualizer and the ipython notebook I get really bizarre attentions.
What could be the issue?
 tomsbergmanis
on 5 Jul 2018
tomsbergmanis
on 5 Jul 2018
Related issues
 thompsonb
·
3Comments
thompsonb
·
3Comments
 mehmedes
·
3Comments
mehmedes
·
3Comments
 sebastian-nehrdich
·
4Comments
sebastian-nehrdich
·
4Comments
 ndvbd
·
3Comments
ndvbd
·
3Comments
 kaushalshetty
·
3Comments
kaushalshetty
·
3Comments
Most helpful comment
See the hello_t2t IPython notebook at Google Colab and in the "Display Attention" section choose "Input - Output" instead of "All" from the menu.
This will visualize the encoder-decoder attention, which is the closest thing to word alignment you can get out of the box (as far as I know).
As you can see, this is very different from the word alignment you expected:
Of course, you could train a new T2T model in the "old NMT way": restrict the number of enc-dec attention heads to 1, use words (with UNK) instead of subwords,... and get much worse MT quality, but with a better interpretable enc-dec attention.