Tensor2tensor: [Tuning] Results are GPU-number and batch-size dependent
@lukaszkaiser
This is to illustrate what I have discussed on gitter.
Working with WMT EN-FR, I have observed the following.
You can replicate the paper results with "transformer -base" with 4 GPU.
The BLEUapprox looks like this: (batch-size 4096, warmup step 6000)

If I do the same on 3 GPU (batch size 4096 warmup step 8000), taking into account that I need to compare step 120K of 4GPU run vs 160K of the 3GPU run, I get this with a clear offset of 1 BLEU point.
The gap is never closed if we wait.
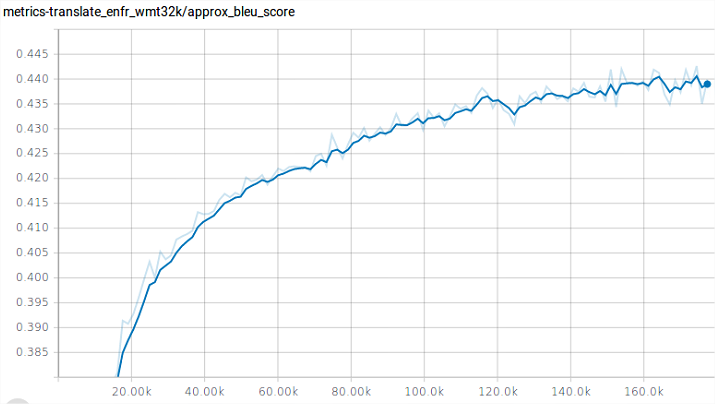
If I do the same on 2GPU, it's even lower, 1GPU same.
Also, I observed that it is very dependent on the batch size.
For instance if you lower to 3072 you don't get the same as with 4096
With 2048 even lower.
This makes impossible to replicate the Transformer BIG results since you can only fit a batch size of 2048 even on a GTX1080ti.
Hope this helps for better tuning.
 vince62s
vince62s
All 81 comments
My experience is exactly the same. Lower batch size (either nominally lower with the same number of GPUs or effectively lower because of smaller number of GPUs) results in worse results, even if I train long enough to compensate for the lower batch.
I remember people working with Nematus or OpenNMT were surprised by this behavior of Transformer/T2T because their experience was that lower batch size leads to better results in the end (but slower of course, thus they sometimes start training with big batch and then switch to lower batch for fine-tuning).
 martinpopel
on 27 Nov 2017
martinpopel
on 27 Nov 2017
@vince62s you mentioned that the gap is never closed even if you _wait_ to compensate the batch size difference.
Have you been able to compensate by decreasing learning rate when decreasing batch size ? As suggested here, maybe it would make sense to define the learning rate by multiplying it by x and y if batch size changes nominally (the same number of GPUs ) by x and/or effectively by y (different number of GPUs)?
 mehmedes
on 13 Dec 2017
mehmedes
on 13 Dec 2017
not sure, because adam / noam is supposed to be adaptive. all the tests I did (changing the lr) were not better.
All what I know is that there are 2 places where the number of replicas has an impact:
here warmup steps are multiplied by the number of gpu
https://github.com/tensorflow/tensor2tensor/blob/e3cd447aa605515753ebfc3dbf1a4d4c5ae32425/tensor2tensor/utils/optimize.py#L106
here the lr is divided by the sqrt of nb of gpu
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/model_builder.py#L219
vince62s
on 13 Dec 2017
I have nice TensorBoard BLEU curves illustrating that training with more GPUs converges faster to higher BLEU (which is what everyone expects). When answering the question whether N GPUs are N times faster (or less or more, which is what this issue is about), it depends whether we plot steps or hours on the x axis:

Here we can see e.g. that 8 GPUs (the topmost curve) achieved BLEU=24 after 68k steps of training, while 1 GPU (the bottom-most curve) needed something between 800k and 1050k steps to achieve (and never go below) the same BLEU. So 8 GPUs are more than 8 times faster when measuring the BLEU convergence vs training steps. However, one step takes less seconds with 1 GPU than with 8 GPUs, so I think it is more relevant to plot time instead of steps on the x axis (switch to "Relative" in TensorBoard).

Here we can see that 8 GPUs achieved BLEU=24 after 12 hours of training, while 1 GPU needed something between 84 and 108 hours.
So now the expectation 8*12=96 is within the measured range.
The best BLEU/number_of_GPUs curve seems to be achieved by two GPUs, which crossed the BLEU=24 line after something between 31 and 38 hours, so here the expectation 61-72 hours is clearly below the 1GPU range 84-108.
I am still waiting whether 1GPU can achieve as good results as 8GPU, after long enough time (several weeks). So the main question of this issue still remains unanswered.
All GPUs are of the exactly same type (1080 Ti). Of course, these results should be still taken with a grain of salt - it is just one testset (newstest2013), different testsets may give (slightly) different results.
martinpopel
on 13 Dec 2017
And more post (this time with base models instead of big) showing that you should always use the highest possible batch_size (comparing batch size 1500, 3000 and 4500, all three trained just on one GPU):

martinpopel
on 13 Dec 2017
Some results with T2T 1.3.2:
--problems=translate_ende_wmt32k --model=transformer --hparams_set=transformer_base_v2 --hparams=batch_size=8192,max_length=150 --worker_gpu=4
I'm running this on 4 P100 GPUs - As far as I understand the code --hparams=batch_size=8192 --worker_gpu=4 should be the same as --hparams=batch_size=4096 --worker_gpu=8
On news-test2014 (with averaging):
after 100k steps: 27.0 BLEU
after 200k steps: 27.4 BLEU
after 300k steps: 27.5 BLEU
This is not very close to the 28.2 BLEU reported here.
After reading vince62s post, maybe the t2t authors used worker replicas rather than --worker_gpu? In that case, shouldn't we be doing the same things to wramup_steps and learning rate with worker_gpu as with worker_replicas, ie. replacing num_worker_replicas in the code vince62s pointed to with something like worker_gpu*worker_replicas?
 fstahlberg
on 14 Dec 2017
fstahlberg
on 14 Dec 2017
I think you might be correct. I realize my above comment was misleading since I confused replicas and gpu.
Now that I see exactly what their intention was, your last suggestion make 100% sense.
@lukaszkaiser any insight ?
EDIT: actually not exactly, because if the "default" values are tuned for 8 GPU / 1 replica, then we would need to make a prorata for learning_rate and warmup_steps.
vince62s
on 14 Dec 2017
Second thought (actually maybe 1000th one).
When we do learning_rate /= math.sqrt(float(worker_replicas))
If this is calibrated / tuned for 1 replica and 8 gpu, it would mean that when we run on one machine with 4 GPU, we would actually need to INCREASE the learning rate (equivalent of replica = 0.5)
makes sense ?
vince62s
on 14 Dec 2017
Well, I think if it was calibrated for 1 replica we would be fine since dividing the learning rate or multiplying warmup_steps by worker_replicas would have no effect. My current thesis is that the default parameters are tuned for 8 replica, each with 1 GPU. In this case we need to decrease the learning rate and increase warmup steps in order to simulate the setting on a single machine with multiple GPUs. I am trying that right now...
fstahlberg
on 14 Dec 2017
Paper says one machine, 8 GPUs.
vince62s
on 15 Dec 2017
You are right.. that means I'm still deeply confused. @lukaszkaiser the exact training command for replicating the 28.2 BLEU would be very helpful.
fstahlberg
on 15 Dec 2017
If the gpu memory is not sufficient for the ideal batch size of 4096, @martinpopel suggested in #446 to use transfomer_big_single_gpu (orange) and to set the batch size as high as possible to get the best results.
After adjusting learning_rate and learning_rate_warmup_steps as @fstahlberg recommends , it looks like my loss curve for transfomer_big (red) will eventually cut the transfomer_big_single_gpu curve.

I adjusted learning_rate and learning_rate_warmup_steps based on transformer_v2 as follows:

mehmedes
on 15 Dec 2017
As I have commented elsewhere, I think that in the Attention is all you need paper they use batch_size=3072 (which multiplied by 8 gives the approx. 25000 tokens per batch reported in the paper). However, the number 3072 never appeared in the source code of transformer.py.
martinpopel
on 15 Dec 2017
For the best base model so far (28.2) I used 8 gpus with the default transformer_base. Some recent papers suggested scaling learning rate linearly or square-root-like with batch size, so according to them if we go down from 8 to 2 gpus we should scale learning rate down by 2x or 4x. Martin: could you try these? I'll try to reproduce the above results to make sure we understand it better. If it's indeed the case, then we should probably add automatic LR scaling...
 lukaszkaiser
on 18 Dec 2017
lukaszkaiser
on 18 Dec 2017
I would have said the contrary, ie the more GPUs the smaller LR since the batch size isx times bigger.
vince62s
on 18 Dec 2017
First a note: The graphs I posted above are all on the translate_encs_wmt32k task evaluated on the newstest2013 with the real BLEU, but I believe similar observations hold also for EnDe translation and other tasks.
Now I did some experiments with learning rate (and 1 GPU and a fixed batch size):
- lr=0.01 converges noticeably slower than the default lr=0.2 (4 BLEU worse even after 2 days of training).
- lr=0.3 (or higher) diverges after few hours, so I had to double the warmup steps. Afterwards, it is about the same as the default lr=0.2.
- lr=0.25, lr=0.1 and lr=0.05 are about the same as the default lr=0.2.
By "about the same" I mean that the learning curves cross each other frequently (the variance from checkpoint to checkpoint is higher than the difference). I will try even higher lr.
martinpopel
on 18 Dec 2017
My results from the very first post were with 1.2.9 if I recall well.
Re-running the same 4GPU experiment with 1.3.2 gives me worse results ....
Anything changed since ?
vince62s
on 18 Dec 2017
@martinpopel Have you had success with high learning rates? Increased learning rates seem to make up for lower batch size. I'm currently training a transformer_big model with a LR of 0,8 (warmup=32k) on 4 GPUs each with a batch size of 2000. So far this provides me with the greatest loss on 4x1080TIs.
I multiplied LR and warmup by the quotient of ideal batch size / available batch size.
mehmedes
on 21 Dec 2017
@mehmedes: No success with higher learning rates. I've tried lr=0.5 (and warmup 32k) and it is still about the same as other learning rates (except for lr=0.01 which is clearly worse). Then I tried lr=1 and it diverged (BLEU=0).
martinpopel
on 21 Dec 2017
@mehmedes did you through the end fo your training, how did it go ?
vince62s
on 22 Dec 2017
My training with LR=0.8 is still running. My loss curve hasn't flattened out yet, compared to previous models (see above) where I divided the LR by the ideal / available batch size ratio instead of multiplying it.

mehmedes
on 22 Dec 2017
@martinpopel did you test LR=0.5 on a single GPU or on multiple?
mehmedes
on 23 Dec 2017
@mehmedes: All my experiments with learning rate so far are on a single GPU.
As I think about it I am afraid there is no easy way (one magical formula) how to exactly compensate for a lower batch size (caused e.g. by less GPUs) with a learning rate scaling:
If we keep the same learning rate schedule then after x steps with 8 GPUs we have the same lr as with 1 GPU, although we have seen 8 times more examples. So it is tempting to set the lr 8 times bigger on 1 GPU to compensate, but this does not work. If the lr is too high in any moment, the learning diverges. We can (and should) fight this with more warmup steps on 1 GPU, but this is not really equivalent to the multi-GPU setting with less warmup steps (and smaller lr).
I think it also depends on how long do you plan (can afford) to train: there may be two hyperparameter setups, one outperforming the other only after N days or hours of training (this is the case of base vs. big). And this is related also to the training data size (training too long on small data leads to overtraining).
martinpopel
on 23 Dec 2017
@martinpopel yes, that's true.
What I find curious about T2T is that the LR impact behaves inverserly proportional.
In _Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour_ Facebook multiplies LR by 32 because they increase batch size by 32.
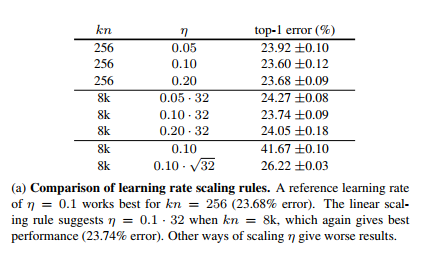
So far, I've made the experice in T2T that if I decrease the batch size by x, I need to multiply LR and warmup steps by x
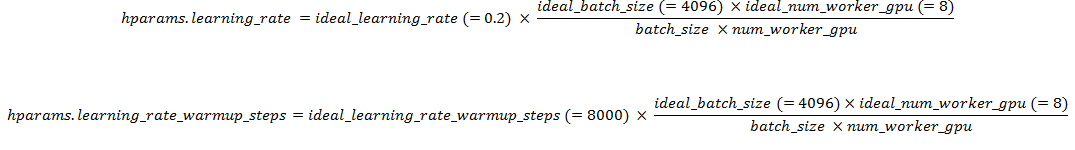
Any ideas, why?
mehmedes
on 23 Dec 2017
@fstahlberg I did a quick experiment.
I confirm your initial thought.
1GPU+BS4096 = 2GPU+BS2048 = 4GPU+BS1024
I am getting very close loss values and approx bleu values for these 3 scenarios.
maybe you can try with another seed and a bit longer they went up to 350K steps I think.
vince62s
on 23 Dec 2017
@vince62s yes that seems to be the case in all my experiments so far even with more training steps.
fstahlberg
on 24 Dec 2017
Hello , @vince62s @martinpopel @mehmedes , I am wonder how to print loss or bleus using tensor2tensor , I can run simple tensorbord demos with tf.Session() , but tensor2tensor only provides tf.contrib.learn.Experiment,which puzzles me a lot . Can u give some advice about using tensorbord in tensor2tensor ? Or just a small sample ? Really thanks .
 liesun1994
on 26 Dec 2017
liesun1994
on 26 Dec 2017
@liesun1994 If you run tensorboard like this, for example,
tensorboard --logdir $TRAIN_DIR --host localhost --port 2222
you should be able to access all evaluated values in your browser http://localhost:2222.
See #15.
mehmedes
on 26 Dec 2017
wooooooooooooooow, that would be nice!! thanks @mehmedes
liesun1994
on 27 Dec 2017
I made two additional runs. One with a higher learning rate (=3.0) and increased warmup steps (500k) [green] and one with a lower learning rate (=.05) and decreased warmup steps (=2k) [blue].
Both had a batch size of 2000 on 4 GPUs.
It seems as if one may profit by a lower learning rate by decreasing - instead of increasing - the warmup steps by the same factor as the learning rate.
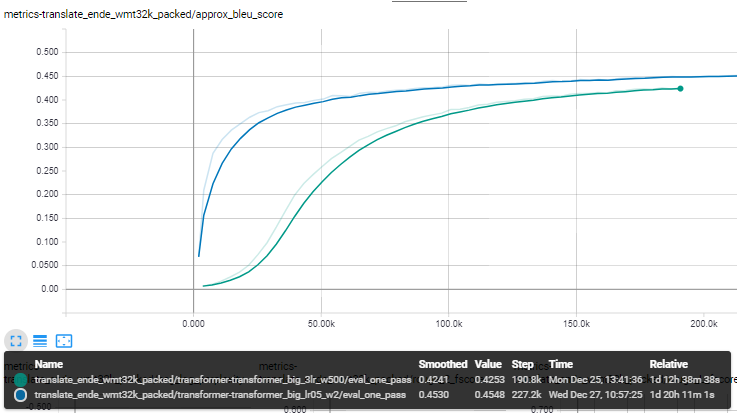
mehmedes
on 27 Dec 2017
@mehmedes but is it really the best result you got with 4 GPU ? or is this just a comparison between these 2.
vince62s
on 28 Dec 2017
@vince62s By decreasing learning rate _and_ warmup steps by the same factor, based on the ideal/available batch size ratio, I currently achieve the highest BLEU results with 4 GPUs!
I had another run with a learning rate of 0.8 and 32k warmup steps (red).
LR .05 with 2k warmup steps (blue) still outperforms.
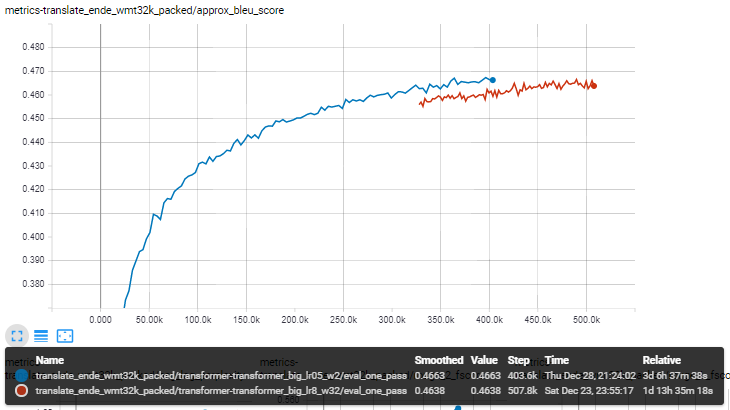
I'll test if this also works out with one GPU, where I'll need to decrease LR and warmup by around 32, for a GPU which fits batch of 1000 when training transformer_big.
mehmedes
on 28 Dec 2017
I now had further tries to compensate batch size reduction by decreasing / increasing learning rate and warmup.
The upper curve is a model with a batch size of 2048. The lower curves are all batch size 1024. Training was performed on one GPU.
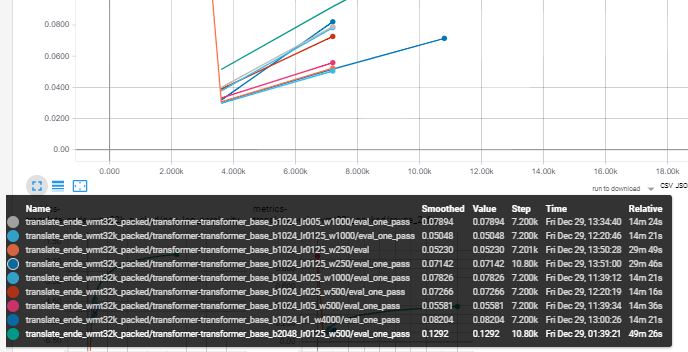
None of the settings actually made up for batch reduction. I increased learning rate and warmup by x2, x4, x8...
BUT:
What really made a difference was learning rate =.05 and warmup =2k (red curve)! This combination also provided me with the best results on a 4 GPU training setting as reported above. In the following graph the model with batch size 1024 (learning rate =.05 and warmup =2k) is en par with the 2048 batch size model!
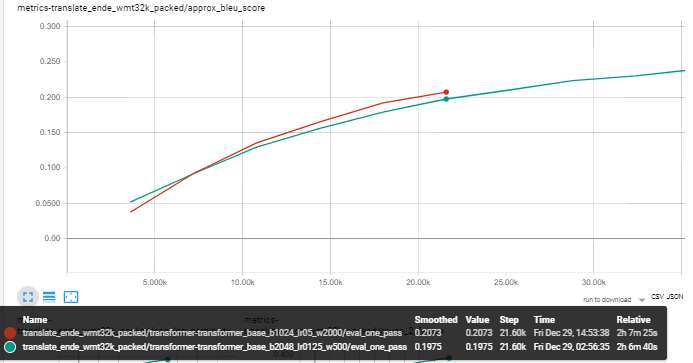
To be honest, I couldn't find a way to make linear adjustments which can be applied universally. For me, there's _just_ this learning rate =.05 and warmup =2k setting, which generally seems to allow batch size settings below the 8 GPU standard to make up for the batch size lack. (BTW - sorry for messing around with all my toing and froing in this thread)
I will try if it's possible with learning rate =.05 and warmup =2k to achieve 8 GPU results if you just wait long enough, as the standard learning rate and warmup settings didn't allow this for me.
mehmedes
on 29 Dec 2017
I don't seem to replicate this with ENFR.
Are you 100% sure all of this is comparable with the very last version of T2T (ie eval step 10000 making the full dev set for eval -- approx bleu is lower than before on only 10 batches) ?
I will let it run longer to see what happens.
vince62s
on 30 Dec 2017
I ran all the above on an individial 5M English -> German corpus with T2T 1.4.1.
mehmedes
on 30 Dec 2017
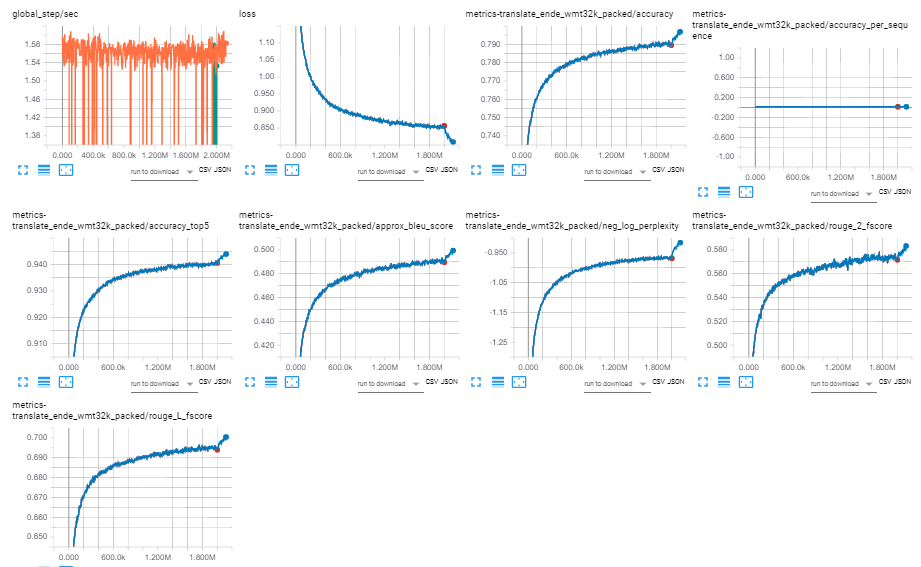
Besides lowering learning rate to .05 and warmup to 2k, increasing optimizer_adam_beta2 at the same time from the default 0.98 to 0.999 also seems to help with lower batch sizes. At least, that's what I experienced when loss with big models with the default optimizer_adam_beta2 would stop decreasing and models with optimizer_adam_beta2 that are closer to 1 would continue to decrease.
This may also be one of the factors, besides lower dropout (=.1, instead of .3) that contribute to better results, or maybe it's better to say faster convergence, with big_single_gpu, which also uses an adam_beta2 (=.998) that is closer to 1 than the default.
After changing adam_beta2 to (=.999) at step 2M, loss starts dropping considerably:
mehmedes
on 11 Jan 2018
Just did a quick test on the new adafactor optimizer and it seems to outperform adam:
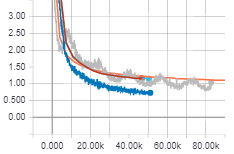
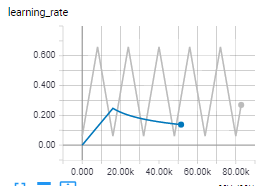
The orange curve is adam with noam.
The grey is adam with cyclical LR, which seems to help adam overcome saddle points and let's you forget about finding the right LR when not having the resources for the ideal batch size. (https://arxiv.org/abs/1506.01186 , https://arxiv.org/abs/1708.07120)
And the blue is adafactor, which outperforms all :D
BTW: Adafactor allows you to increase batch size from 2000 to 2500 on 1080 Ti!
I've been using the following hparams for the model, optimized with Adafactor, on 4 x 1080Ti each with a batch_size=2500:
@registry.register_hparams
def transformer_big_adafactor():
"""HParams for transfomer big model on WMT."""
hparams = transformer_base()
hparams.hidden_size = 1024
hparams.filter_size = 4096
hparams.num_heads = 16
hparams.layer_prepostprocess_dropout = 0.3
hparams.optimizer = "Adafactor"
hparams.epsilon = 1e-8
hparams.relative_decay_horizon = 0.2
hparams.absolute_decay_horizon = 100.0
hparams.use_locking = False
hparams.learning_rate_warmup_steps = 16000
return hparams
Didn't try it myself yet, but I think it might be useful for this issue: https://github.com/openai/gradient-checkpointing
 gsoul
on 15 Jan 2018
gsoul
on 15 Jan 2018
@mehmedes
I tried on the base model, smaller dataset (1M en fr) did no get better results vs adam/noam
did you score you try ?
vince62s
on 17 Jan 2018
That's true, I didn't get noticeable improvements on the base model as well.
The improvement Adafactor (green curve) provided was with the above mentioned hparams compared to transformer_big :
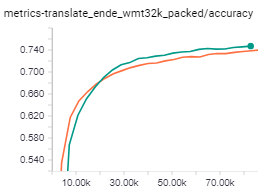
My training is still running, I'll keep you updated on the score after convergence.
mehmedes
on 17 Jan 2018
I am not so sure, but could we set warmup in terms of epoch rather then steps? That is, warmup steps = warmup epoch X steps/epoch
 lkluo
on 18 Jan 2018
lkluo
on 18 Jan 2018
@lkluo epoch depends on the size of your dataset. So you can manually calculate once the number of steps for your epoch, depending on your batch size. And then set warmup_steps accordingly.
gsoul
on 18 Jan 2018
The latest Adafactor release in T2T 1.4.3 yields a great training boost and allows a greater batch_size on the same hardware!
Using translate_ende_wmt32k_packed with a decreased packed_length=100 (btw thanks @martinpopel for the hint with decode_length!) , which allows constant input of 100 tokens, I'm able to use batch_size=3800 on a 11GB gpu, in contrast to batch_size=2500 in previous releases.
With the following hparams
@registry.register_hparams
def transformer_big_adafactor():
"""HParams for transfomer big model on WMT."""
hparams = transformer_base()
hparams.hidden_size = 1024
hparams.filter_size = 4096
hparams.num_heads = 16
hparams.layer_prepostprocess_dropout = 0.3
hparams.optimizer = "Adafactor"
hparams.epsilon = 1e-20
hparams.horizon_exponent = 0.8
hparams.anomaly_threshold = 2.0
hparams.use_locking = False
return hparams
the Adafactor model (red) outperforms my personal best result (orange) considerably:
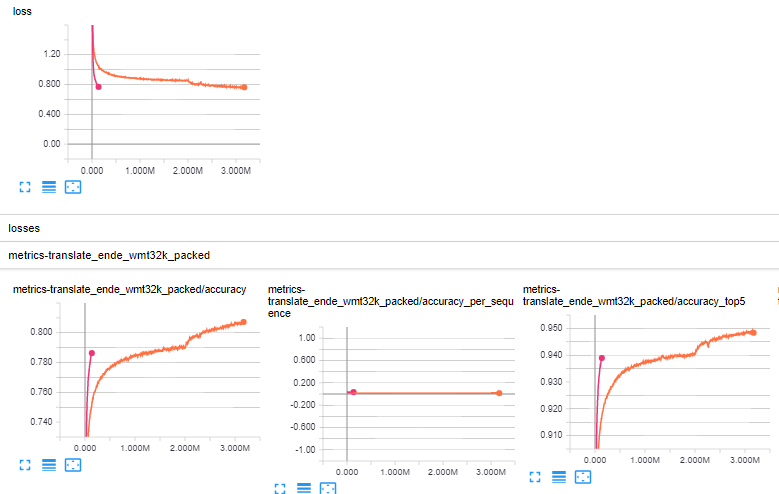
mehmedes
on 4 Feb 2018
@mehmedes (or t2t authors): Have you seen [in one of your previous experiments] improved BLEU scores after convergence by using Adafactor? Also, it would be interesting to compare Adam and Adafactor under the same batch size...
fstahlberg
on 4 Feb 2018
regarding the maximum batch_size on 11GB, I did these experiments:
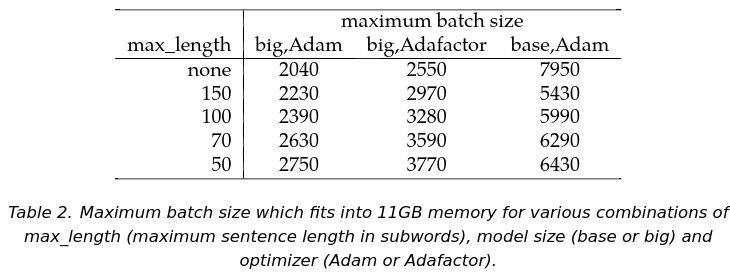
martinpopel
on 4 Feb 2018
@mehmedes seems to be able to fit 3800 on a big with Adafactor.
Maybe a change with TF1.5
Also shared_embedding or not may impact quite significantly.
vince62s
on 4 Feb 2018
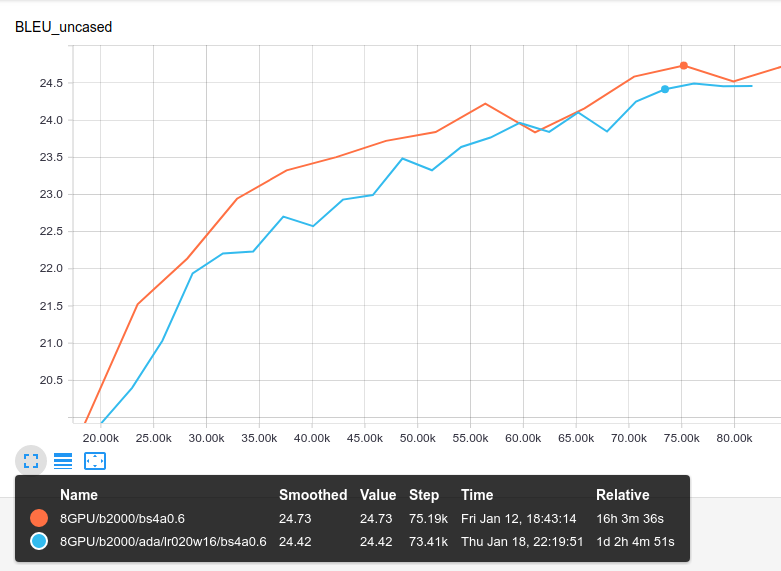
@fstahlberg I compared Adafactor and Adam with the same batch size in v1.4.2.
First on 8 GPUs with no max_length restriction: blue=Adafactor, orange=Adam
Then on 1 GPU with max_length=70: blue=Adafactor, green=Adam
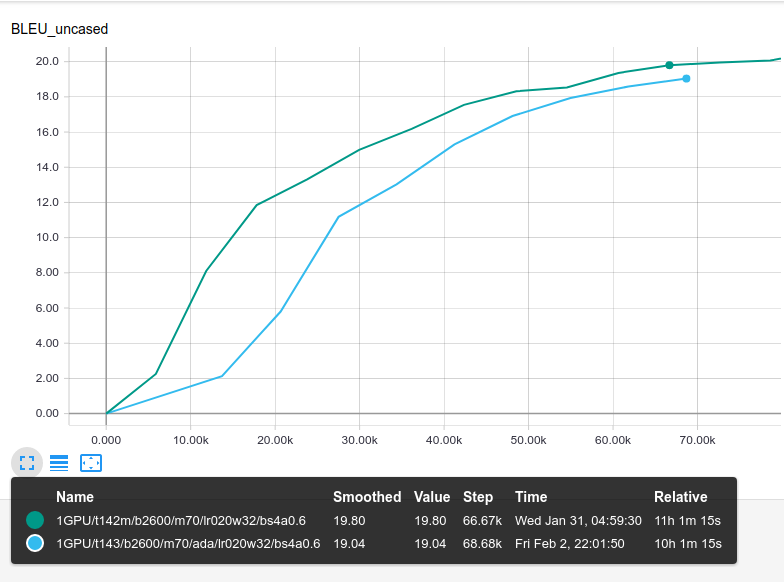
In both cases, Adam is slightly better in the early training stages.
I've tried Adafactor in v1.4.3 and it seems to give the same results (although its hyperparameters were changed). However, I was not able to compare this directly because it requires TF 1.5, whose precompiled binaries require CUDA 9.0, which requires a newer NVidia driver (384.69), which is unfortunately two times slower on 8GPUs than the old driver (375.66).
martinpopel
on 4 Feb 2018
seems to be able to fit 3800 on a big with Adafactor.
The numbers in my table are really the maximum, when increased by 10, the training fails (though sometimes after several hours of training). In case of Adafactor with max_length=50, batch_size 3780 failed immediately.
I did this with T2T 1.4.2, TF1.4 and haven't used any _packed problem - I guess this is the reason, why I was not able to achieve 3800 as you did.
martinpopel
on 4 Feb 2018
@martinpopel that was very detailed and helpful, thanks!
fstahlberg
on 4 Feb 2018
Let's return to the original question: When scaling an experiment from 1 GPU to N GPUs, how should we modify the hyperparameters, namely the learning_rate (LR) and learning_rate_warmup_steps (warmup)? Suppose, we have found the optimal hyperparams for a single GPU, so how to modify them for N GPUs (with --worker_gpu=N, that is synchronous single-machine parallelism)? This is a summary of my current knowledge:
- Scaling from 1 GPU to N GPUs while keeping the
batch_sizeis equivalent to scaling to a N times biggerbatch_sizewhile keeping the number of GPUs. Both means that the effective batch size is now N times bigger. In other words, when we scale up the number of GPUs N times and at the same time scale down the batch size N times, we should get exactly the same results. As @vince62s wrote, 1GPU+BS4096 = 2GPU+BS2048 = 4GPU+BS1024. I have confirmed this with my own experiments. - In most papers (e.g. Smith et al. 2017), the LR decay scheme is defined in terms of the number of epochs, i.e. number of training examples (total for all GPUs) on the x-axis. Thus when defining the LR scheme in T2T, I think we should multiply the steps (global_step) by the
batch_sizeand number of GPUs (and possibly divide by a constant, so we can keep the usual LR value 0.1 or 0.2 the default) before applyingnoamor any other LR scheme. This is not done currently in the code, but when scaling to from 1 to N GPUs with thenoamLR scheme, we can divide LR by sqrt(N) and divide warmup by N, which is mathematically exactly the same as multiplying steps by N, but it works only for thenoamscheme. This way, we have achieved that after seeing x training examples (either on 1 GPU or as a total for all N GPUs), the LR value will be the same. - However, according to Smith et al. 2017, Goyal et al. and other papers, when scaling up to a N times bigger effective batch size, one should also multiply the LR by N (and keep warmup intact) in order to keep the noise scale at the same level. So together with the previous bullet, the final advice is to multiply the LR by sqrt(N) and divide warmup by N.
- Goyal et al. train ResNet on ImageNet and use SGD with Momentum (i.e. not adaptive updates such as Adam). Smith et al. 2017 also train ImageNet and they don't use any warmup. It is not clear whether their conclusions hold also for Transformer in T2T with Adam.
- Even for a fixed problem (e.g.
translate_ende_wmt32k) it is not clear what are the optimal hyperparams for a single GPU. There are many other hyperparams which interplay with LR and warmup and number of GPUs, e.g. adam_beta2, using Adafactor, Nadam or AMSGrad instead of Adam, preventing training divergences withclip_grad_normrather than with increasing warmup or lowering LR, etc. Some setups are better than the baseline in the early phases of training, but worse after longer training. Some setups converge faster in BLEU per step, but each step is longer, so in the end the convergence in BLEU per hour is slower.
martinpopel
on 5 Feb 2018
@mehmedes Thank you for your experiment with the new optimizer. Could you share with rest of us the final converged score of training with Adafactor?
 1nsunym
on 7 Feb 2018
1nsunym
on 7 Feb 2018
- Goyal et al. say: "minibatch size cannot be scaled indefinitely: while results are stable for a large range of sizes, beyond a certain point accuracy degrades rapidly". In other words (and in other papers), there is a maximum learning rate, which cannot be surpassed, even if increasing the batch size. When surpassing the learning rate, the training diverges. My experiments with 8 GPUs confirm this, i.e. the above-mentioned advice "multiply the LR by sqrt(N) and divide warmup by N" does not work in practice.
- Chris Ying shows scaling of en-de translation in T2T up to 64 TPUs and effective batch size 1024k using "Adam optimizer - same learning rate schedule across configurations" without any notice of scaling the learning rate (although the previous slide mentions "linearly scale LR") nor warmup and the graph looks like the same final quality was achieved. So there is a way, but I am not aware of any publication with more details about the experiment. So the seemingly never-ending discussion in this issue may happily continue:-).
@1nsunym: My Adafactor experiments result in the same learning curve (except for the first few hours) as Adam. I suggest to open a new issue for possible further discussion of Adafactor not related to the topic of scaling to more GPUs and bigger batches.
martinpopel
on 9 Feb 2018
There is a paper on Adafactor submitted to ICML'18 with more experiments, I'm not sure if the conference process tolerates it, but if it's ok then it'll land on arxiv as soon as possible. In short: Adafactor does as well as Adam but with less memory use. I'd not expect it to be better than Adam, but then you have more memory. As for the TPU experiments: indeed, it scales almost perfectly and with Adam there was no need to change the learning rate.
lukaszkaiser
on 11 Feb 2018
The TPU hparams seem to work very well with GPU as well.
Using _packed and limiting input length to 100 from 256 tokens during data generation...
@registry.register_problem
class TranslateEndeWmt32kPacked(TranslateEndeWmt32k):
@property
def packed_length(self):
return 100
... using noise broadcast with adafactor...
@registry.register_hparams
def transformer_big_adafactor():
"""HParams for transfomer big model on WMT."""
hparams = transformer_base()
hparams.hidden_size = 1024
hparams.filter_size = 4096
hparams.num_heads = 16
hparams.layer_prepostprocess_dropout = 0.3
hparams.optimizer = "Adafactor"
hparams.attention_dropout_broadcast_dims = "0,1"
hparams.relu_dropout_broadcast_dims = "1"
hparams.layer_prepostprocess_dropout_broadcast_dims = "1"
return hparams
... and increasing --worker_gpu_memory_fraction=0.97
One can fit batch_size=4900! into a 1080 TI for training transformer_big
UPDATE: In T2T 1.5.3, you can even fit 6000 into 11GB while running big with tpu hparams and adafactor.
mehmedes
on 15 Feb 2018
@mehmedes what score did you get ?
vince62s
on 16 Feb 2018
I'm training on a personalized corpus. With big_single_gpu and the default params I achieved a BLEU score of ~49 after 3M steps, which was my best result so far.
With the params above, I achieved ~53. Evaluation performed with t2t-bleu
mehmedes
on 16 Feb 2018
@mehmedes
trying problems=translate_ende_wmt32k_packed model= transformer hparams=transformer_big_tpu worker_gpu=4 hparams="batch_size=6000"
OOM
even down to 3000 => OOM
Just curious, it seems similar to wht you did.
I am using TF 1.5.0 Cuda 9
EDIT: I missed the tweak 100 at generation .... I'll try again.
vince62s
on 1 Mar 2018
@vince62s you may also need to increase --worker_gpu_memory_fraction=0.978. Otherwise it may first train but then crash after a few hours. I had to stop my x server and run ubuntu from command line in order to allow T2T use the entire GPU memory -- and you shouldn't be running tensorboard in parallel on the same machine, which may also cause a crash.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.111 Driver Version: 384.111 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 00000000:02:00.0 Off | N/A |
| 46% 57C P2 235W / 250W | 11163MiB / 11164MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 108... Off | 00000000:03:00.0 Off | N/A |
| 45% 55C P2 253W / 250W | 11171MiB / 11172MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX 108... Off | 00000000:81:00.0 Off | N/A |
| 42% 53C P2 245W / 250W | 11171MiB / 11172MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX 108... Off | 00000000:82:00.0 Off | N/A |
| 33% 46C P2 252W / 250W | 11171MiB / 11172MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 16764 C /usr/bin/python 11153MiB |
| 1 16764 C /usr/bin/python 11161MiB |
| 2 16764 C /usr/bin/python 11161MiB |
| 3 16764 C /usr/bin/python 11161MiB |
+-----------------------------------------------------------------------------+
The params I use for batch_size=6000 are:
@registry.register_hparams
def transformer_big_adafactor():
hparams = transformer_big()
hparams.optimizer = "Adafactor"
hparams.learning_rate_schedule = "rsqrt_decay"
hparams.learning_rate_warmup_steps = 10000
hparams.attention_dropout_broadcast_dims = "0,1" # batch, heads
hparams.relu_dropout_broadcast_dims = "1" # length
hparams.layer_prepostprocess_dropout_broadcast_dims = "1" # length
return hparams
And during data generation you also need to use _packed problems with max_length=100:
@registry.register_problem
class TranslateEndeWmt32kPacked(TranslateEndeWmt32k):
@property
def packed_length(self):
return 100
Ok here are my last results on WMT ENDE32k
Base, Adafactor, batchsize 8192, 4 GPU [total 32768 which is more than the 25k of the paper)
Newstest 2014: after 100k steps, on avg10ckp = 26.70
after 500k steps on avg10ckp = 27.2, on avg20ckp = 27.35
Big, Adafactor, batchsize 5000, 4 GPU
Newstest 2014: after 200k steps, on avg20ckp = 27.6
after 300k steps on avg20ckp = 27.66
These results are still under the paper Base 100k steps 27.3, Big 300k steps 28.4
I would really love to know if you guys at GG Brain @lukaszkaiser @rsepassi still replicate
the paper results in the same conditions (100k steps for base, 300k steps for big) with the current code.
vince62s
on 6 Mar 2018
@vince62s 😆
liesun1994
on 6 Mar 2018
@vince62s #317 may helps u .
liesun1994
on 15 Mar 2018
Hi all, can i double check the scores you guys produced in your experiments? Are they with t2t-bleu or sacreBLEU (with or without --tok intl)? Thanks!
 duyvuleo
on 29 Mar 2018
duyvuleo
on 29 Mar 2018
Talking for myself, I always report BLEU from mteval13a.pl without intl tok, and this is the same as multi-bleu-detok.perl
As far as I know, this is what is usually reported in papers.
vince62s
on 29 Mar 2018
I report BLEU with t2t-bleu, which should be the same as mteval-v14.pl --international-tokenization and as sacrebleu -lc -tok intl (note the lc for lowercase, i.e. uncased). The international tokenization has higher correlation with human ranking (unless the sentences are ASCII only, in which case it has no effect, but hey we live in the 21st century and not all languages are ASCII only), but I agree it is not used in all papers. Unfortunately, there is no single most popular BLEU variant used in papers - some use cased, some uncased, some use multi-bleu.perl with detokenization, some with detokenization and tokenize.perl...
My advice is to use sacreBLEU and always report its signature. Note that sacreBLEU can report also the chrF metric.
martinpopel
on 29 Mar 2018
Thanks @vince62s and @martinpopel for your replies.
In my case, scores with t2t-bleu and sacrebleu -tok intl are (a bit) higher than the ones without "-tok intl" (in English -> French, 2-3 BLEU scores are higher). This makes the comparisons with the existing SOTAs unfair, and I will not know whether I trained the system in a proper way. That makes me confusing.
duyvuleo
on 30 Mar 2018
Just use sacreBleu without -tok intl and without -lc and you will be comparable I think.
vince62s
on 30 Mar 2018
@martinpopel : I saw you draw this picture (BLEU_uncased) in tensorboard: https://user-images.githubusercontent.com/724617/33940325-d217ba74-e00e-11e7-9996-5132b62d51dc.png
But I just have "approx_bleu_score" curve. Is "approx_bleu_score" the curve of trainning set? How to get the "BLEU_uncased" curve of test set?
 DC-Swind
on 12 Apr 2018
DC-Swind
on 12 Apr 2018
@DC-Swind: approx_bleu is computed on the dev set, but using the internal subword tokenization, so it is not replicable (and it is not reliable because of using gold reference last word). I use t2t-bleu and t2t-translate-all for plotting the (real) BLEU curves.
martinpopel
on 12 Apr 2018
@martinpopel : There is no event file was generated by t2t-blue and t2t-translate-all , how to get the curve in tensorboard? Could you provide the detailed command? I just want to plot a single BLEU curve of test set for a specified model (which is stored in the $TRAIN_DIR)
DC-Swind
on 13 Apr 2018
@DC-Swind: t2t-bleu creates the event file if called with proper parameters, see https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/bin/t2t_bleu.py#L27-L53
martinpopel
on 13 Apr 2018
Is there anyone who tried greater batch sizes than recommended to see whether it is possible to gain better performance than in the paper? With accumulation of gradients, one can arbitrarily increase the batch size. Was my question already answered before?
 AranKomat
on 24 Apr 2018
AranKomat
on 24 Apr 2018
The effect of batch size is discussed in this paper. The maximum batch size depends on the GPU memory (and optimizer - with Adafactor we can afford bigger batches, see Table 2 of the paper). The conclusions are: "for the BASE model, a higher batch size gives better results, although with diminishing returns. With the BIG model, we see quite different results."
With accumulation of gradients, one can arbitrarily increase the batch size.
Yes, I had this idea as well: accumulate gradients from N batches and do just one update of weights afterwards, simulating N times bigger batch (or N times more GPUs). I think it is worth trying, but someone would need to implement it first. There will be a question of how to compute the number of steps (which influences the learning rate schedule). However, I am not sure super-big batches will improve the convergence speed. Still, it may be useful for simulating multi-GPU experiments on a single GPU (so that after buying more GPUs, I will already know what are the optimal hyperparams).
martinpopel
on 24 Apr 2018
Thanks for your response. As you said, I'm simulating such a situation (for language modeling with Transformer) with a single GPU at the expense of time per iteration (for this reason, achieving convergence isn't realistic). I hope someone will figure out how much performance gain it is possible with a huge batch size with multiple GPUs.
AranKomat
on 24 Apr 2018
We have an upcoming ACL paper where we use this idea for neural machine translation with target side syntax. It turns out that using large batch sizes is even more important when generating long output sequences. I'll post a link to arXiv when ready. There is also a t2t implementation:
https://github.com/fstahlberg/tensor2tensor/blob/master/tensor2tensor/utils/largebatch_optimizer.py
Like the normal AdamOptimizer, but the n argument in the constructor is what you are describing: simulating n times more GPUs at the cost of n times more training iterations.
However, this is still t2t 1.3.1. I haven't had time to polish the code and update t2t to see if it still works. But I can do that and make a PR.
Regarding the original question: From my experience it is a good idea to try to match the number_of_gpus*batch_size setup, and n can compensate for reducing either of these values. I haven't seen gains from even larger batches.
fstahlberg
on 25 Apr 2018
@fstahlberg I really appreciate your feedback, and I'm looking forward to reading your paper. Generating a long sequence (though not for translation) is something I'm currently working on, so that's very beneficial to learn about. Maybe increasing the batch size enhances the generalizability of text transduction model, which alleviates the issue of exposure bias in generating long sequences? I'm eager to hear from you about any of these as well as bit more relevant details about your paper.
AranKomat
on 25 Apr 2018
does someone have a recent comparison between 4 and 8 GPU for the same set of hparam
(batch size 4096, warmup steps 8000, lr 2 -- ie. default)
vince62s
on 28 May 2018
This recent paper achieved 5x speedup on translation using Transformer with various techniques, including batch size of 400k and mixed precision: Scaling Neural Machine Translation. Furthermore, it achieved BLEU of 29.3 and 43.2 on En-De and En-Fr, respectively. For those of us who don't have many GPUs, the use of diet variables of utils/diet.py would be helpful to increase the batch size if that thing works. Has anybody tried diet variables? Does it really work as expected?
AranKomat
on 10 Jun 2018
@AranKomat: Please note that in the aforementioned paper one crucial factor in the speed up is switching from single to half precision and that the hardware is V100, which achieves 14TFLOPs in single precision and 112TFLOPs!! in half precision. The P100, which was used in the T2T paper, would "only" increase from 9TFLOPs to 18TFLOPs when switching to half precision. The hardware should also be considered when evaluating the speed up.
The 1080Ti, for example, is faster on calculating single precision than on half precision!
mehmedes
on 17 Jun 2018
@mehmedes I didn't notice that there was such as huge difference between V100 and P100 in terms of half precision TFLOPS! But I believe Table 1 accounts for the difference by citing the BLEU and speed with V100. Maybe using diet variables wouldn't benefit much in this case if half precision is already used.
AranKomat
on 18 Jun 2018
Hi @fstahlberg
Has your paper been published?
We have an upcoming ACL paper where we use this idea for neural machine translation with target side syntax. It turns out that using large batch sizes is even more important when generating long output sequences. I'll post a link to arXiv when ready. There is also a t2t implementation:
 xerothermic
on 16 Jul 2019
xerothermic
on 16 Jul 2019
Hi @xerothermic yes, we have used it in
https://www.aclweb.org/anthology/P18-2051
for syntax and in
https://www.aclweb.org/anthology/W18-6427
for a WMT18 submission.
fstahlberg
on 16 Jul 2019
Related issues
 ndvbd
·
3Comments
ndvbd
·
3Comments
 apeterswu
·
3Comments
apeterswu
·
3Comments
 draplater
·
4Comments
draplater
·
4Comments
 KayShenClarivate
·
3Comments
KayShenClarivate
·
3Comments
 bezigon
·
4Comments
bezigon
·
4Comments
Most helpful comment
Let's return to the original question: When scaling an experiment from 1 GPU to N GPUs, how should we modify the hyperparameters, namely the
learning_rate(LR) andlearning_rate_warmup_steps(warmup)? Suppose, we have found the optimal hyperparams for a single GPU, so how to modify them for N GPUs (with--worker_gpu=N, that is synchronous single-machine parallelism)? This is a summary of my current knowledge:batch_sizeis equivalent to scaling to a N times biggerbatch_sizewhile keeping the number of GPUs. Both means that the effective batch size is now N times bigger. In other words, when we scale up the number of GPUs N times and at the same time scale down the batch size N times, we should get exactly the same results. As @vince62s wrote, 1GPU+BS4096 = 2GPU+BS2048 = 4GPU+BS1024. I have confirmed this with my own experiments.batch_sizeand number of GPUs (and possibly divide by a constant, so we can keep the usual LR value 0.1 or 0.2 the default) before applyingnoamor any other LR scheme. This is not done currently in the code, but when scaling to from 1 to N GPUs with thenoamLR scheme, we can divide LR by sqrt(N) and divide warmup by N, which is mathematically exactly the same as multiplying steps by N, but it works only for thenoamscheme. This way, we have achieved that after seeing x training examples (either on 1 GPU or as a total for all N GPUs), the LR value will be the same.translate_ende_wmt32k) it is not clear what are the optimal hyperparams for a single GPU. There are many other hyperparams which interplay with LR and warmup and number of GPUs, e.g. adam_beta2, using Adafactor, Nadam or AMSGrad instead of Adam, preventing training divergences withclip_grad_normrather than with increasing warmup or lowering LR, etc. Some setups are better than the baseline in the early phases of training, but worse after longer training. Some setups converge faster in BLEU per step, but each step is longer, so in the end the convergence in BLEU per hour is slower.