Tensor2tensor: Session error when running distributed training
Hi
When I run distributed training following the guides in https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/docs/distributed_training.md,
I configure with 1 ps and 2 workers. The ps works ok, but all the workers show errors:
tensorflow.python.framework.errors_impl.NotFoundError: No session factory registered for the given session options: {target: "10.150.144.48:1111" config: allow_soft_placement: true graph_options { optimizer_options { } }} Registered factories are {DIRECT_SESSION, GRPC_SESSION}.
The details of this error is as follows:
2017-06-25 06:41:26.914625: E tensorflow/core/common_runtime/session.cc:69] Not found: No session factory registered for the given session options: {target: "10.150.144.48:1111" config: allow_soft_placement: true graph_options { optimizer_options { } }} Registered factories are {DIRECT_SESSION, GRPC_SESSION}.
{u'cluster': {u'ps': [u'10.150.144.48:3333'], u'worker': [u'10.150.144.48:1111', u'10.150.144.48:2222']}, u'task': {u'index': 0, u'type': u'worker'}}
Traceback (most recent call last):
File "/usr/local/bin/t2t-trainer", line 62, in <module>
tf.app.run()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/platform/app.py", line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File "/usr/local/bin/t2t-trainer", line 58, in main
schedule=FLAGS.schedule)
File "/usr/local/lib/python2.7/dist-packages/tensor2tensor/utils/trainer_utils.py", line 247, in run
output_dir=FLAGS.output_dir)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 210, in run
return _execute_schedule(experiment, schedule)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 47, in _execute_schedule
return task()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 275, in train
hooks=self._train_monitors + extra_hooks)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 669, in _call_train
monitors=hooks)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/util/deprecation.py", line 289, in new_func
return func(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 455, in fit
loss = self._train_model(input_fn=input_fn, hooks=hooks)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 1003, in _train_model
config=self._session_config
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 352, in MonitoredTrainingSession
stop_grace_period_secs=stop_grace_period_secs)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 648, in __init__
stop_grace_period_secs=stop_grace_period_secs)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 477, in __init__
self._sess = _RecoverableSession(self._coordinated_creator)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 822, in __init__
_WrappedSession.__init__(self, self._create_session())
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 827, in _create_session
return self._sess_creator.create_session()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 538, in create_session
self.tf_sess = self._session_creator.create_session()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 412, in create_session
init_fn=self._scaffold.init_fn)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/session_manager.py", line 273, in prepare_session
config=config)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/session_manager.py", line 178, in _restore_checkpoint
sess = session.Session(self._target, graph=self._graph, config=config)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 1292, in __init__
super(Session, self).__init__(target, graph, config=config)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.py", line 562, in __init__
self._session = tf_session.TF_NewDeprecatedSession(opts, status)
File "/usr/lib/python2.7/contextlib.py", line 24, in __exit__
self.gen.next()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/framework/errors_impl.py", line 466, in raise_exception_on_not_ok_status
pywrap_tensorflow.TF_GetCode(status))
tensorflow.python.framework.errors_impl.NotFoundError: No session factory registered for the given session options: {target: "10.150.144.48:1111" config: allow_soft_placement: true graph_options { optimizer_options { } }} Registered factories are {DIRECT_SESSION, GRPC_SESSION}.
ERROR:tensorflow:==================================
Object was never used (type <class 'tensorflow.python.framework.ops.Tensor'>):
<tf.Tensor 'report_uninitialized_variables_1/boolean_mask/Gather:0' shape=(?,) dtype=string>
If you want to mark it as used call its "mark_used()" method.
It was originally created here:
['File "/usr/local/bin/t2t-trainer", line 62, in <module>\n tf.app.run()', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/platform/app.py", line 48, in run\n _sys.exit(main(_sys.argv[:1] + flags_passthrough))', 'File "/usr/local/bin/t2t-trainer", line 58, in main\n schedule=FLAGS.schedule)', 'File "/usr/local/lib/python2.7/dist-packages/tensor2tensor/utils/trainer_utils.py", line 247, in run\n output_dir=FLAGS.output_dir)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 210, in run\n return _execute_schedule(experiment, schedule)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 47, in _execute_schedule\n return task()', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 275, in train\n hooks=self._train_monitors + extra_hooks)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 669, in _call_train\n monitors=hooks)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/util/deprecation.py", line 289, in new_func\n return func(*args, **kwargs)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 455, in fit\n loss = self._train_model(input_fn=input_fn, hooks=hooks)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 1003, in _train_model\n config=self._session_config', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 352, in MonitoredTrainingSession\n stop_grace_period_secs=stop_grace_period_secs)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 648, in __init__\n stop_grace_period_secs=stop_grace_period_secs)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 477, in __init__\n self._sess = _RecoverableSession(self._coordinated_creator)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 822, in __init__\n _WrappedSession.__init__(self, self._create_session())', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 827, in _create_session\n return self._sess_creator.create_session()', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 538, in create_session\n self.tf_sess = self._session_creator.create_session()', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 403, in create_session\n self._scaffold.finalize()', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 192, in finalize\n default_ready_for_local_init_op)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 254, in get_or_default\n op = default_constructor()', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 189, in default_ready_for_local_init_op\n variables.global_variables())', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/util/tf_should_use.py", line 170, in wrapped\n return _add_should_use_warning(fn(*args, **kwargs))', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/util/tf_should_use.py", line 139, in _add_should_use_warning\n wrapped = TFShouldUseWarningWrapper(x)', 'File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/util/tf_should_use.py", line 96, in __init__\n stack = [s.strip() for s in traceback.format_stack()]']
==================================
It seems {DIRECT_SESSION, GRPC_SESSION}.` is not registered, So can you help to see this problem?
 tobyyouup
tobyyouup
All 35 comments
@lukaszkaiser Could you please help discuss this problem, thanks a lot!
tobyyouup
on 26 Jun 2017
Could you please share the command lines you used to start each of the jobs?
 rsepassi
on 26 Jun 2017
rsepassi
on 26 Jun 2017
Ah, I believe I found the issue. Please try modifying the master command-line flag by prepending a grpc://, so e.g. --master=grpc://10.150.144.48:1111.
rsepassi
on 26 Jun 2017
Is this solved with the distributed training update in 1.0.8?
 lukaszkaiser
on 27 Jun 2017
lukaszkaiser
on 27 Jun 2017
@rsepassi
When I prepend grpc:// before master command-line, the above error disappears. But the worker just stop printing log after logging:
- `INFO:tensorflow:Total trainable variables size: 62454272
- INFO:tensorflow:Total embedding variables size: 16384
- INFO:tensorflow:Total non-embedding variables size: 62437888
- INFO:tensorflow:Computing gradients for global model_fn.
- INFO:tensorflow:Global model_fn finished.
- INFO:tensorflow:Create CheckpointSaverHook.`
And the worker PID cannot be found by nvidia-smi command. For the server, I am not sure if the server works normally Becaue after it shows:
- `2017-06-26 22:54:27.508880: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:3333}
- 2017-06-26 22:54:27.508926: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> 10.150.144.48:5555}
- 2017-06-26 22:54:27.510965: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:316] Started server with target: grpc://localhost:3333`
then be silent. But unlike the worker, the server PID can be found by the nvidia-smi command.
The script I use to start the ps and worker is:
`PROBLEM=wmt_ende_tokens_32k
MODEL=transformer
HPARAMS=transformer_base
DATA_DIR=$HOME/t2t_data
TMP_DIR=/tmp/t2t_datagen
TRAIN_DIR=./t2t_train_dis/$PROBLEM/$MODEL-$HPARAMS
mkdir -p $TRAIN_DIR
start worker
export CUDA_VISIBLE_DEVICES=0
nohup t2t-trainer --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIR --master=grpc://10.150.144.48:5555 --ps_replicas=1 --worker_replicas=1 --worker_gpu=1 --worker_id=0 --ps_gpu=1 --schedule=train --tf_config="{'cluster': {'ps': ['10.150.144.48:3333'], 'worker': ['10.150.144.48:5555']}, 'task': {'index': 0, 'type': 'worker'}}" > nohup.w1 2>&1 &
start ps
export CUDA_VISIBLE_DEVICES=1
nohup t2t-trainer --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIR --schedule=run_std_server --tf_config="{'cluster': {'ps': ['10.150.144.48:3333'], 'worker': ['10.150.144.48:5555']}, 'task': {'index': 0, 'type': 'ps'}}" > nohup.s1 2>&1 &
`
So what is the problem? The ps and server cannot be in the same machine but use different GPUs?
tobyyouup
on 27 Jun 2017
Please see the distributed training doc. TF_CONFIG is an envt var that needs to be set.
rsepassi
on 27 Jun 2017
And please upgrade to 1.0.8
rsepassi
on 27 Jun 2017
@rsepassi Yes, I have already upgraded to 1.0.8. And if I directly pass the TF_CONFIG envr var like "TF_CONFIG=$JOB_TF_CONFIG t2t-trainer $JOB_FLAGS --model=transformer ..." in the https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/docs/distributed_training.md,
It will show error that can not parse the json format, because the TF_CONFIG set like this is just a string var. So I add one line code in the t2t-trainer python file
if FLAGS.tf_config != "":
os.environ['TF_CONFIG']= json.dumps(eval(FLAGS.tf_config))
And add a para FLAG in "utils/trainer_utils.py":
flags.DEFINE_string("tf_config", "", "the tf_config envrt var")
And then it can find the TF_CONFIG envrt var. The start script is showed in the above. It still shows the problems that the worker be silent after printing some logs.
I still don't know the reason?
tobyyouup
on 28 Jun 2017
Another findings. The para FLAGS
flags.DEFINE_string("master", "", "Address of TensorFlow master.")
in the "utils/trainer_utils.py" should be set None, but not "", otherwise it will show errors when you start ps servers.
I don't know if you have encounter this problems, but I encountered and fixed it by changing it to None.
This problem is not related to the "worker being silent "problem I mentioned above, I still need help for that problem. Thanks a lot.
tobyyouup
on 28 Jun 2017
Is there any suggestions about this issues? @lukaszkaiser @rsepassi
tobyyouup
on 29 Jun 2017
Investigating...
rsepassi
on 29 Jun 2017
Ok, so a couple things with the fixes you used above:
- For the
TF_CONFIGenvironment variable to be parsed correctly, you need to wrap it in single quotes. e.g.
TF_CONFIG='{"cluster": {"ps": ["localhost:10001", "localhost:10002"], "worker": ["localhost:10000"]}, "task": {"index": 0, "type": "worker"}}'
No need for the additional tf_config command line flag.
masterneeds to be passed on the command line. Changing the default doesn't matter because you need to set it.
Here's an example invocation for the parameter server:
TF_CONFIG='{"cluster": {"ps": ["localhost:10001", "localhost:10002"], "worker": ["localhost:10000"]}, "task": {"index": 0, "type": "ps"}}' t2t-trainer --model=transformer --hparams_set=transformer_tiny --problems=algorithmic_identity_binary40 --data_dir=$HOME/t2t/data --output_dir=/tmp/distt2t -
-master=grpc://localhost:10002 --schedule=run_std_server
And for the worker:
TF_CONFIG='{"cluster": {"ps": ["localhost:10001", "localhost:10002"], "worker": ["localhost:10000"]}, "task": {"index": 0, "type": "worker"}}' t2t-trainer --model=transformer --hparams_set=transformer_tiny --problems=algorithmic_identity_binary40 --data_dir=$HOME/t2t/data --output_dir=/tmp/distt2t -
-master=grpc://localhost:10000 --schedule=run_std_server
I'm also seeing the issue of logging hanging, but I think part of the issue might be trying to bring up the cluster all on the same machine. Have you tried launching on multiple machines (e.g. on GCP or AWS)?
rsepassi
on 29 Jun 2017
@rsepassi Thanks. Firstly, the "--schedule" in the example invocation for the worker you provided should be "train", but not "run_std_server".
I have followed your configs and example invocation, and I also try with two machines, one for ps and one for worker. But the logging is still hanging for the worker. Have you ever run successfully with the distributed settings? I am looking forward to your reply to this distributed running issues, thanks.
tobyyouup
on 30 Jun 2017
@rsepassi Is there any suggestions? I really need you help, many thanks.
tobyyouup
on 4 Jul 2017
@rsepassi @lukaszkaiser I have also seen another issue https://github.com/tensorflow/tensor2tensor/issues/99 , which is definitely the same with mine. So I think there must be something wrong, probably I don't use it properly? Or some problem in the codes?
tobyyouup
on 6 Jul 2017
I have trouble reproducing it and Ryan is on vacation for now, sorry for the slow replies. He'll be back Monday, and I'll give it some more try today. If you have any more details, post it here so we have them too.
lukaszkaiser
on 6 Jul 2017
@lukaszkaiser @rsepassi
I have located where the worker hangs:
It's in the "with monitored_session.MonitoredTrainingSession(...) as mon_sess" code when the worker's experiment call the train function(-schedule=train) and then call fit function in BaseEstimator class (actually in function _train_model in file: /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py).
I add two tf.logging.info right before and after the create session command, the log before can print out but the log after cannot, this is actually will the worker hangs.
My script to start worker is
“TF_CONFIG='{"cluster": {"ps": ["10.150.144.48:10001"], "worker": ["10.150.144.44:10000"]}, "task": {"index": 0, "type": "worker"}}' t2t-trainer --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIR --master=grpc://10.150.144.44:10000 --worker_replicas=1 --worker_gpu=1 --worker_id=0 --ps_replicas=1 --ps_gpu=1 --schedule=train”
So I think this will help to locate the problems. I am looking for your reply, thanks.
tobyyouup
on 9 Jul 2017
I'm observing same thing with python 3.5.
More detailed hannging point is:
with monitored_session.MonitoredTrainingSession(...) in contrib/learn/python/learn/estimators/estimator.py which calls,
MonitoredSession.__init__(...) in python/training/monitored_session.py which calls,
_MonitoredSession.__init__(...) in python/training/monitored_session.py which calls,
_RecoverableSession.__init__(...) in python/training/monitored_session.py which calls,
_RecoverableSession.create_session(...) in python/training/monitored_session.py which calls,
_MonitoredSession._CoordinatedSessionCreator.create_session(...) in python/training/monitored_session.py which calls,
WorkerSessionCreater.create_session(...) in python/training/monitored_session.py which calls,
_WorkerSessionCreater.get_session_manager().wait_for_session(...) in python/training/monitored_session.py.
_WorkerSessionCreater.get_session_manager() returns <tensorflow.python.training.session_manager.SessionManager object> and the wait_for_session in python/training/session_manager.py calls
_try_run_local_init_op in python/training/session_manager.py which calls
_model_ready_for_local_init in python/training/session_manager.py which calls
_model_ready in python/training/session_manager.py which calls
ready in python/training/session_manager.py which calls
sess.run(op) in python/training/session_manager.py with the operation
Tensor("report_uninitialized_variables_1/boolean_mask/Gather:0", shape=(?,), dtype=string, device=/job:worker/task:1) and hangs. Hoping this will help. Thanks.
 deasuke
on 10 Jul 2017
deasuke
on 10 Jul 2017
Here's the stack just before calling TF_ExtendGraph in sess.run
File "/usr/local/bin/t2t-trainer", line 4, in <module> __import__('pkg_resources').run_script('tensor2tensor==1.0.10', 't2t-trainer'),
File "/usr/local/lib/python3.5/dist-packages/pkg_resources/__init__.py", line 739, in run_script self.require(requires)[0].run_script(script_name, ns)
File "/usr/local/lib/python3.5/dist-packages/pkg_resources/__init__.py", line 1507, in run_script exec(script_code, namespace, namespace),
File "/usr/local/lib/python3.5/dist-packages/tensor2tensor-1.0.10-py3.5.egg/EGG-INFO/scripts/t2t-trainer", line 83, in <module>,
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/platform/app.py", line 48, in run _sys.exit(main(_sys.argv[:1] + flags_passthrough)),
File "/usr/local/lib/python3.5/dist-packages/tensor2tensor-1.0.10-py3.5.egg/EGG-INFO/scripts/t2t-trainer", line 79, in main,
File "/usr/local/lib/python3.5/dist-packages/tensor2tensor-1.0.10-py3.5.egg/tensor2tensor/utils/trainer_utils.py", line 250, in run experiment_fn=exp_fn, schedule=schedule, output_dir=output_dir),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 210, in run return _execute_schedule(experiment, schedule),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 47, in _execute_schedule return task(),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 275, in train hooks=self._train_monitors + extra_hooks),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 665, in _call_train monitors=hooks),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/util/deprecation.py", line 289, in new_func return func(*args, **kwargs),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 455, in fit loss = self._train_model(input_fn=input_fn, hooks=hooks),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 1006, in _train_model config=self._session_config,
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/monitored_session.py", line 324, in MonitoredTrainingSession stop_grace_period_secs=stop_grace_period_secs),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/monitored_session.py", line 656, in __init__ stop_grace_period_secs=stop_grace_period_secs),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/monitored_session.py", line 484, in __init__ self._sess = _RecoverableSession(self._coordinated_creator),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/monitored_session.py", line 832, in __init__ _WrappedSession.__init__(self, self._create_session()),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/monitored_session.py", line 838, in _create_session return self._sess_creator.create_session(),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/monitored_session.py", line 546, in create_session self.tf_sess = self._session_creator.create_session(),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/monitored_session.py", line 453, in create_session max_wait_secs=30 * 60 # Wait up to 30 mins for the session to be ready.,
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/session_manager.py", line 404, in wait_for_session sess),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/session_manager.py", line 489, in _try_run_local_init_op is_ready_for_local_init, msg = self._model_ready_for_local_init(sess),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/session_manager.py", line 473, in _model_ready_for_local_init "Model not ready for local init"),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/training/session_manager.py", line 520, in _ready ready_value = sess.run(op),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/client/session.py", line 790, in run run_metadata_ptr),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/client/session.py", line 1000, in _run feed_dict_string, options, run_metadata),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/client/session.py", line 1137, in _do_run target_list, options, run_metadata),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/client/session.py", line 1144, in _do_call return fn(*args),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/client/session.py", line 1121, in _run_fn self._extend_graph(),
File "/usr/local/lib/python3.5/dist-packages/tensorflow/python/client/session.py", line 1182, in _extend_graph
Sorry for the delay all. Back from vacation. Thanks so much for the investigation. I'll be looking into this and will report back with what I find (and hopefully a fix soon).
rsepassi
on 10 Jul 2017
Ok, partial update:
tough little bug to track down but the fix is trivial:
Add "environment": "cloud" to the TF_CONFIG.
Here's an example invocation of 2 workers and 1 PS running in async training mode:
# Chief worker (worker 0)
TF_CONFIG='{"cluster": {"worker": ["localhost:5858", "localhost:5859"], "ps": ["localhost:10001"]}, "task": {"index": 0, "type": "worker"}, "environment": "cloud"}' t2t-trainer --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIR --master=grpc://localhost:5858 --ps_replicas=1 --worker_replicas=2 --worker_gpu=1 --worker_id=0 --ps_gpu=0 --schedule=train --hparams='batch_size=8,hidden_size=16,filter_size=32,num_heads=1,num_hidden_layers=1'
# worker 1
TF_CONFIG='{"cluster": {"worker": ["localhost:5858", "localhost:5859"], "ps": ["localhost:10001"]}, "task": {"index": 1, "type": "worker"}, "environment": "cloud"}' t2t-trainer --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIR --master=grpc://localhost:5859 --ps_replicas=1 --worker_replicas=2 --worker_gpu=1 --worker_id=1 --ps_gpu=0 --schedule=train --hparams='batch_size=8,hidden_size=16,filter_size=32,num_heads=1,num_hidden_layers=1'
# ps (which in async mode runs only on cpu, hence the clearing of CUDA_VISIBLE_DEVICES)
CUDA_VISIBLE_DEVICES= TF_CONFIG='{"cluster": {"worker": ["localhost:5858", "localhost:5859"], "ps": ["localhost:10001"]}, "task": {"index": 0, "type": "ps"}}' t2t-trainer --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIR --master=grpc://localhost:10001 --schedule=run_std_server
This gets past Session creation now, but there's another issue that seems to come up with variable initialization. Thought I'd share this partial fix in case you all could find a fix to the variable initialization issue before I did.
I'm seeing 2 failure modes:
FailedPreconditionError (see above for traceback): Attempting to use uninitialized value training/beta1_power; not always this variable.InvalidArgumentError (see above for traceback): WhereOp: Race condition between counting the number of true elements and writing them. When counting, saw 830 elements; but when writing their indices, saw 20 elements.The traceback shows that this WhereOp was constructed as part of thereport_uninitialized_variablesfunction.
rsepassi
on 12 Jul 2017
I updated an tried it. Every processes(ps, woker0, worker1) uses GPU memory. However, workers(both 0 and 1) reports a lot of (all, I think) variables are not initialized and they won't become ready.
Logically, ps owns training variables and workers fetch them to calculate gradients, right? So the fact that worker reports uninitialized variables is kind of unreasonable. Or does the error mean that ps failed to initialize training variables?
deasuke
on 12 Jul 2017
And after 1800sec passed, workers terminate with timeout.
tensorflow.python.framework.errors_impl.DeadlineExceededError: Session was not ready after waiting 1800 secs.
@rsepassi Following your instructions, I have definitely the same results with yours and @deasuke. it shows
INFO:tensorflow:Waiting for model to be ready. Ready_for_local_init_op: Variables not initialized: global_step, losses_avg/problem_0/total_loss,........
And after 1800sec, it shows:
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 323, in MonitoredTrainingSession
stop_grace_period_secs=stop_grace_period_secs)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 648, in __init__
stop_grace_period_secs=stop_grace_period_secs)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 477, in __init__
self._sess = _RecoverableSession(self._coordinated_creator)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 822, in __init__
_WrappedSession.__init__(self, self._create_session())
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 827, in _create_session
return self._sess_creator.create_session()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 538, in create_session
self.tf_sess = self._session_creator.create_session()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/monitored_session.py", line 447, in create_session
max_wait_secs=30 * 60 # Wait up to 30 mins for the session to be ready.
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/training/session_manager.py", line 415, in wait_for_session
"Session was not ready after waiting %d secs." % (max_wait_secs,))
tensorflow.python.framework.errors_impl.DeadlineExceededError: Session was not ready after waiting 1800 secs.
tobyyouup
on 12 Jul 2017
@deasuke, yes, the error is on the workers and not the PS because the worker is driving the graph (i.e. it has the Session client); that is, we wouldn't expect the PS to show the errors because it's just a dumb server that is there for the workers to use.
We want to make sure that the chief worker has as an init op the global variables initializer and actually attempts to run it. Will have to trace through that code path to make sure it's executing.
The relevant code path is in MonitoredTrainingSession. The Chief worker should use the ChiefSessionCreator which calls prepare_session (as opposed to a non-chief call to wait_for_session) on the SessionManagerwhich runs the init_op provided by the Scaffold. So we have to make sure the the Scaffolds init_op includes the global variables initializer.
rsepassi
on 12 Jul 2017
Alright, I've fixed the issue and verified that distributed training works! The fix will be in tonight's release; please try it and let me know if it works for you too.
rsepassi
on 12 Jul 2017
@rsepassi The new version has already been released? Seems I can not find any code changes according to several latest commits?
tobyyouup
on 14 Jul 2017
Sorry about that. v1.0.14 is now released and should have the issues fixed. Run t2t-make-tf-configs --masters=localhost:5000,localhost:5001 --ps=localhost:10000 to get the TF_CONFIG environment variables and command-line flags to pass to t2t-trainer. Let me know how it goes!
rsepassi
on 15 Jul 2017
Hi @rsepassi According to the new version, I can run ps and worker on a single machine successfully.
But When I run ps and and worker on two machines(2 ps and 2 worker, each machine with one ps and one worker). The worker with id=0(the first worker) show errors:
`
INFO:tensorflow:Saving checkpoints for 0 into t2t_train_dis/wmt_ende_tokens_32k/transformer-transformer_base/model.ckpt.
Traceback (most recent call last):
File "/usr/anaconda2/bin/t2t-trainer", line 83, in
tf.app.run()
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/platform/app.py", line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File "/usr/anaconda2/bin/t2t-trainer", line 79, in main
schedule=FLAGS.schedule)
File "/usr/anaconda2/lib/python2.7/site-packages/tensor2tensor/utils/trainer_utils.py", line 270, in run
experiment_fn=exp_fn, schedule=schedule, output_dir=output_dir)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 210, in run
return _execute_schedule(experiment, schedule)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 47, in _execute_schedule
return task()
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 275, in train
hooks=self._train_monitors + extra_hooks)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 665, in _call_train
monitors=hooks)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/util/deprecation.py", line 289, in new_func
return func(args, *kwargs)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 455, in fit
loss = self._train_model(input_fn=input_fn, hooks=hooks)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 1007, in _train_model
_, loss = mon_sess.run([model_fn_ops.train_op, model_fn_ops.loss])
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 505, in run
run_metadata=run_metadata)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 842, in run
run_metadata=run_metadata)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 798, in run
return self._sess.run(args, *kwargs)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 960, in run
run_metadata=run_metadata))
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/basic_session_run_hooks.py", line 368, in after_run
self._save(global_step, run_context.session)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/basic_session_run_hooks.py", line 384, in _save
self._get_saver().save(session, self._save_path, global_step=step)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/saver.py", line 1488, in save
raise exc
tensorflow.python.framework.errors_impl.NotFoundError: t2t_train_dis/wmt_ende_tokens_32k/transformer-transformer_base/model.ckpt-0_temp_02a6a6cf87a94843b039bf54f3fbf449/part-00000-of-00004.index
[[Node: save/MergeV2Checkpoints = MergeV2Checkpoints[delete_old_dirs=true, _device="/job:ps/replica:0/task:1/cpu:0"](save/MergeV2Checkpoints/checkpoint_prefixes, _recv_save/Const_0_S3639)]]Caused by op u'save/MergeV2Checkpoints', defined at:
File "/usr/anaconda2/bin/t2t-trainer", line 83, in
tf.app.run()
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/platform/app.py", line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File "/usr/anaconda2/bin/t2t-trainer", line 79, in main
schedule=FLAGS.schedule)
File "/usr/anaconda2/lib/python2.7/site-packages/tensor2tensor/utils/trainer_utils.py", line 270, in run
experiment_fn=exp_fn, schedule=schedule, output_dir=output_dir)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 210, in run
return _execute_schedule(experiment, schedule)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/learn_runner.py", line 47, in _execute_schedule
return task()
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 275, in train
hooks=self._train_monitors + extra_hooks)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/experiment.py", line 665, in _call_train
monitors=hooks)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/util/deprecation.py", line 289, in new_func
return func(args, *kwargs)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 455, in fit
loss = self._train_model(input_fn=input_fn, hooks=hooks)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py", line 1003, in _train_model
config=self._session_config
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 352, in MonitoredTrainingSession
stop_grace_period_secs=stop_grace_period_secs)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 648, in __init__
stop_grace_period_secs=stop_grace_period_secs)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 477, in __init__
self._sess = _RecoverableSession(self._coordinated_creator)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 822, in __init__
_WrappedSession.__init__(self, self._create_session())
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 827, in _create_session
return self._sess_creator.create_session()
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 538, in create_session
self.tf_sess = self._session_creator.create_session()
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 403, in create_session
self._scaffold.finalize()
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 205, in finalize
self._saver.build()
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/saver.py", line 1170, in build
restore_sequentially=self._restore_sequentially)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/saver.py", line 685, in build
save_tensor = self._AddShardedSaveOps(filename_tensor, per_device)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/saver.py", line 361, in _AddShardedSaveOps
return self._AddShardedSaveOpsForV2(filename_tensor, per_device)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/saver.py", line 343, in _AddShardedSaveOpsForV2
sharded_prefixes, checkpoint_prefix, delete_old_dirs=True)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/ops/gen_io_ops.py", line 185, in merge_v2_checkpoints
delete_old_dirs=delete_old_dirs, name=name)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/framework/op_def_library.py", line 767, in apply_op
op_def=op_def)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/framework/ops.py", line 2506, in create_op
original_op=self._default_original_op, op_def=op_def)
File "/usr/anaconda2/lib/python2.7/site-packages/tensorflow/python/framework/ops.py", line 1269, in __init__
self._traceback = _extract_stack()NotFoundError (see above for traceback): t2t_train_dis/wmt_ende_tokens_32k/transformer-transformer_base/model.ckpt-0_temp_02a6a6cf87a94843b039bf54f3fbf449/part-00000-of-00004.index
[[Node: save/MergeV2Checkpoints = MergeV2Checkpointsdelete_old_dirs=true, _device="/job:ps/replica:0/task:1/cpu:0"]]`
It shows the checkpoint "part-00000-of-00004.index" not exist, but this file actually exist. the file status is:
-rw-rw-r-- 1 root root 12 7月 15 18:41 part-00000-of-00004.data-00000-of-00001
-rw-rw-r-- 1 root root 177 7月 15 18:41 part-00000-of-00004.index
-rw-rw-r-- 1 root root 107839496 7月 15 18:41 part-00001-of-00004.data-00000-of-00001
-rw-rw-r-- 1 root root 15176 7月 15 18:41 part-00001-of-00004.index
the part 00002 and 000003 is on the second machine:
-rw-rw-r-- 1 root root 12 Jul 15 03:38 part-00002-of-00004.data-00000-of-00001
-rw-rw-r-- 1 root root 217 Jul 15 03:38 part-00002-of-00004.index
-rw-rw-r-- 1 root root 635314176 Jul 15 03:38 part-00003-of-00004.data-00000-of-00001
-rw-rw-r-- 1 root root 18960 Jul 15 03:38 part-00003-of-00004.index
The two ps and the second worker works normally, just the the first worker fails.
the script to start the ps and worker is:
`PROBLEM=wmt_ende_tokens_32k
MODEL=transformer
HPARAMS=transformer_base
DATA_DIR=./t2t_data_new
model_name=t2t_train_dis
TRAIN_DIR=$model_name/$PROBLEM/$MODEL-$HPARAMS
mkdir -p $TRAIN_DIRworker:
TF_CONFIG='{"environment": "cloud", "cluster": {"ps": ["10.150.147.74:10002", "10.150.144.48:10000"], "master": ["10.150.147.74:5002", "10.150.144.48:5000"]}, "task": {"index": 0, "type": "master"}}' t2t-trainer --master=grpc://10.150.147.74:5002 --ps_replicas=2 --worker_replicas=2 --worker_gpu=1 --worker_id=0 --worker_job='/job:master' --ps_gpu=1 --schedule=train --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIRTF_CONFIG='{"environment": "cloud", "cluster": {"ps": ["10.150.147.74:10002", "10.150.144.48:10000"], "master": ["10.150.147.74:5002", "10.150.144.48:5000"]}, "task": {"index": 1, "type": "master"}}' t2t-trainer --master=grpc://10.150.144.48:5000 --ps_replicas=2 --worker_replicas=2 --worker_gpu=1 --worker_id=1 --worker_job='/job:master' --ps_gpu=1 --schedule=train --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIR
ps:
TF_CONFIG='{"environment": "cloud", "cluster": {"ps": ["10.150.147.74:10002", "10.150.144.48:10000"], "master": ["10.150.147.74:5002", "10.150.144.48:5000"]}, "task": {"index": 0, "type": "ps"}}' t2t-trainer --master=grpc://10.150.147.74:10002 --schedule=run_std_server --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIRTF_CONFIG='{"environment": "cloud", "cluster": {"ps": ["10.150.147.74:10002", "10.150.144.48:10000"], "master": ["10.150.147.74:5002", "10.150.144.48:5000"]}, "task": {"index": 1, "type": "ps"}}' t2t-trainer --master=grpc://10.150.144.48:10000 --schedule=run_std_server --data_dir=$DATA_DIR --problems=$PROBLEM --model=$MODEL --hparams_set=$HPARAMS --output_dir=$TRAIN_DIR
So what is the problem?
tobyyouup
on 15 Jul 2017
So it's unclear to me why you have the checkpoint files split across machines. The TRAIN_DIR and DATA_DIR should be part of a shared filesystem (e.g. Elastic File System on AWS), i.e. they should point to the same exact directories for all jobs.
rsepassi
on 17 Jul 2017
@rsepassi So if I run on different physical machines, not shared filesystem in cloud environment, the code may not support this functions?
tobyyouup
on 18 Jul 2017
It definitely supports running on different physical machines. My concern is that I don't understand why you have partial checkpoints across multiple machines. The error you've pasted in is because the chief worker is trying to restore from checkpoint files that don't exist. Have you tried starting a fresh distributed training (i.e. a fresh TRAIN_DIR without any checkpoints)?
rsepassi
on 18 Jul 2017
Closing this issue as the initial problem has been solved. However, please do open a new issue if you run into problems with distributed training. Thank you!
rsepassi
on 2 Aug 2017
@rsepassi Hello ,I meet problem that I want to do synchronous training with two masters,
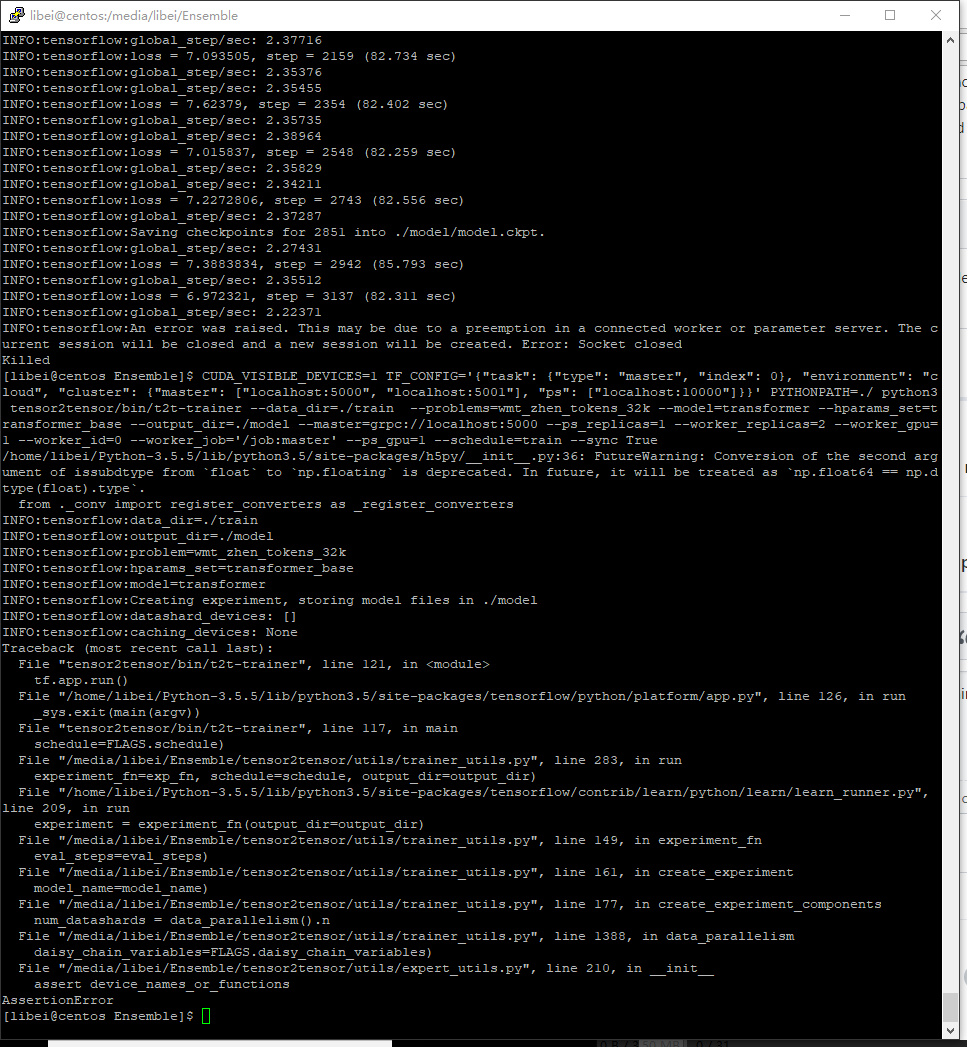 , if there any solutions ?
, if there any solutions ?
 libeineu
on 18 Jul 2018
libeineu
on 18 Jul 2018
And after 1800sec passed, workers terminate with timeout.
tensorflow.python.framework.errors_impl.DeadlineExceededError: Session was not ready after waiting 1800 secs.
have you solve the problem?
 ChChwang
on 10 May 2019
ChChwang
on 10 May 2019
Related issues
 thompsonb
·
3Comments
thompsonb
·
3Comments
 sugeeth14
·
3Comments
sugeeth14
·
3Comments
 mehmedes
·
3Comments
mehmedes
·
3Comments
 draplater
·
4Comments
draplater
·
4Comments
 peblair
·
4Comments
peblair
·
4Comments
Most helpful comment
Alright, I've fixed the issue and verified that distributed training works! The fix will be in tonight's release; please try it and let me know if it works for you too.