Tendermint: WIP: Make consensus reactor more like state machine
Proposal by @milosevic.
Input/Ouput queues
Introduce bounded input / output queues
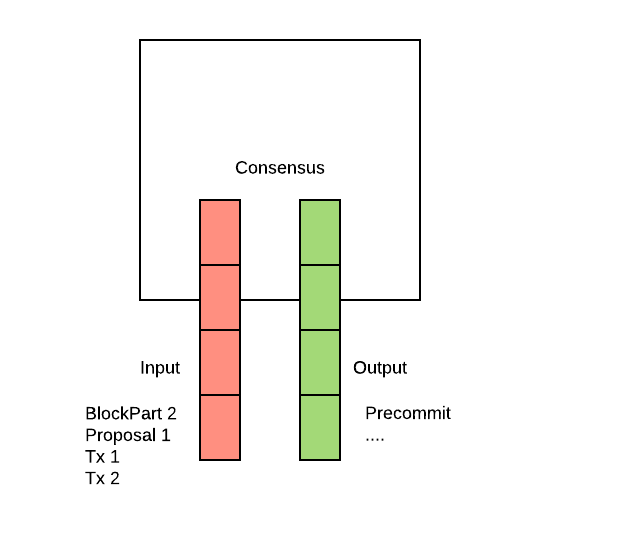
These queues exist right now in the form of MConnection#sendQueue and Reactor#Receive. Receive is ok. Testing requires setting up the whole consensus and not easy. Tracking of what's been send again is hard.
Move mempool txs into consensus
Combining with ^^, tx can be treated as any other incoming message. When a client sends a tx, we call mempool#CheckTx (which itself calls app) and, if CheckTx passes, we send it to consensus queue.
Handle votes in parallel
to speed up consensus. Right not we're processing them sequencially case mi = <-cs.peerMsgQueue
 melekes
melekes
All 23 comments
https://github.com/tendermint/tendermint/issues/630 is related .
 ebuchman
on 27 Apr 2018
ebuchman
on 27 Apr 2018
The goal should be to make it much easier to test more complex executions like the bug that showed up in https://github.com/tendermint/tendermint/issues/1575
ebuchman
on 17 May 2018
I gave this a bit more thought and have a proposal for how we can potentially restructure the reactors to be more testable without compromising on the requirements.
Basically, the requirements around the Reactor design are:
1) a successfully sent message is considered to be received (ie. we depend on TCP for acks)
2) favour receiving messages over sending them (ie. blocking sends should not prevent us from receiving new msgs)
(1) is easy - just use TCP.
For (2), we receive msgs from a central loop, and send msgs from various go-routines. Each reactor spawns go-routines for each peer and runs loops that check whether there are new messages to send - so blocking sends only block the next iteration of the loop, not the next Receive. This ensures we can always receive new messages, as required.
The problem with this structure is that it's very difficult to test because we don't have clear input-output mechanics and the go-routines often involve sleeps and/or tickers that aren't easy to control or serialize with calls to Receive.
I think I have a proposal that allows us to have a clearer input-output function without allowing Sends to block Receive. It is explained by the following data structures and comments:
type Reactor interface {
// Receive bytes from the peer layer
ReceiveMsgBytes(chID byte, src p2p.Peer, msgBytes []byte) (*ReactorResult, error)
// Receive a message or timeout internally
ReceiveMsg(chID byte, msg interface{}) (*ReactorResult, error)
}
// Determines when to call ReceiveMsg again
// and provides a list of messages to send to peers.
type ReactorResult struct {
Callback NextMsg // when to call ReceiveMsg again
Msgs []PeerMsg // send these messages to peers
}
// Defines when to call ReceiveMsg again.
// Could be right away, or after some duration.
type NextMsg struct {
Immediately bool // call ReceiveMsg right away if true
After time.Duration // call ReceiveMsg after this (0 for never)
Msg interface{} // pass this back to ReceiveMsg
}
// Send Payload to Peer
type Msg struct {
Peer p2p.Peer // send to this peer
Payload []byte // msg bytes
Callback func(err error) // call after sending msg
}
The idea here is that Receive returns information on what to do next, or an error.
If it returns an error, we stop the peer. This allows us to remove StopPeerForError calls from the reactors entirely, and instead just do it from the peer layer if an error is returned by Receive. This is also much nicer for testing if some behaviour causes us to disconnect from a peer, which is currently a lot more cumbersome and error prone.
The ReactorResult allows us to specify a list of msgs to send per peer (max one per peer). We try to send all those msgs at once. However we don't block on them. Each msg to send has a callback that we can call from the peer layer to indicate whether the send succeeded or not. This way, we avoid blocking the next Receive, and we can indicate back to the reactor whether it should consider the msg sent or not.
The ReactorResult can also return instructions for calling Receive again - either right away or after some duration. The "call right away" option simulates the tight go-routine loops we currently have, while the "call after duration" option simulates the tickers/timers we use in those go-routines.
Of course this leaves us lots of flexibility for what kind of concurrency we want to embrace in the msg sends and the next calls to the reactor.
Note, however, that the expectation is that if a Msg.Callback returns false then a future call to Receive will return the same msg to be resent.
This is similar to what would happen in the gossipDataRoutine for instance - we try to send a block part. If it goes through, great, mark that peer as having it. If it doesn't, oh well, we'll try to send again the next iteration through the loop.
ebuchman
on 26 May 2018
The ReactorResult allows us to specify a list of msgs to send per peer (max one per peer). We try to send all those msgs at once. However we don't block on them. Each msg to send has a callback that we can call from the peer layer to indicate whether the send succeeded or not. This way, we avoid blocking the next Receive, and we can indicate back to the reactor whether it should consider the msg sent or not.
This model is missing prioritization. With the existing reactor design, a message from peer A or peer B can cause the change the order of to-send messages to peer A according to priority.
 jaekwon
on 27 May 2018
jaekwon
on 27 May 2018
These queues exist right now in the form of MConnection#sendQueue and Reactor#Receive. Receive is ok. Testing requires setting up the whole consensus and not easy. Tracking of what's been send again is hard.
@melekes @milosevic Can you expand upon these?
I don't think a queue will help make things simpler. Rather I think it'll make the whole thing more complex. Instead of an outqueue, we have peerState. The "queue" is not the right data-structure for the job, imo, and so if we go ahead with this queue-ificastion, we'll just be casting ourselves into a model that won't fit future requirements that require more sophistication in prioritizing messages, that are far, far away from the notion of a queue.
jaekwon
on 27 May 2018
There must be another way that does a good job of abstracting the existing reactor system that doesn't involve forcing an out-queue, yet makes testing easier.
Sure, input/output queues easier to debug, but that doesn't make it the right abstraction.
jaekwon
on 27 May 2018
Instead of an outqueue, we have peerState.
hm.. these are different things. state is state, queue is a form of buffering or ordering outgoing data
note: in the end we're still dealing with queues - TCP read/write buffers. MConnection write/read buffers are queues.
The current design looks like this:
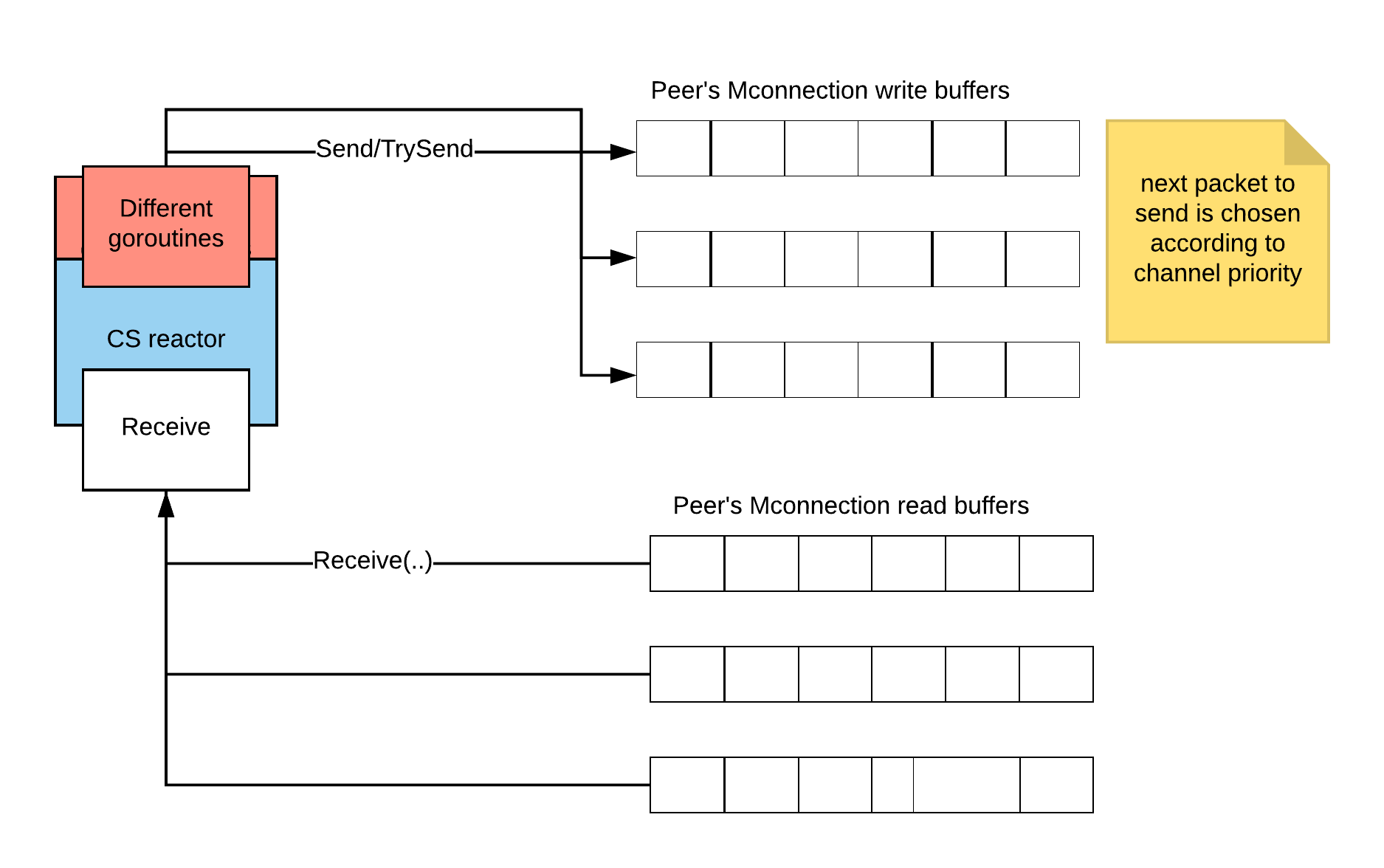
It's hard to test this as a black box because of all the small "sending" goroutines. Notice there is only one Receive(from), but many Send functions. Should there be one Send(to) function? I would say maybe. That way we can create a mocking function, which writes messages to some queue.
func (conR *ConsensusReactor) Send(chID byte, src p2p.Peer, msgBytes []byte) {
src.Send(chID, msgBytes)
}
// used for testing; in tests we inspect the order of msgs sent
func (conR *ConsensusReactor) MockSend(chID byte, src p2p.Peer, msgBytes []byte) {
msgsSent = append(msgsSend, msg{chID: chID, to: src, data: msgBytes})
}
Just to expand a bit on the current architecture. There is a single entry point in ConsensusReactor on the receiving side: Receive function. In Receive function we receive messages from our peers. Processing of received messages update RoundState (by enqueueing messages on internal channel), updates PeerRoundState for each peer and also send messages. Messages are also send in various broadcast routines (gossipDataRoutine, gossipVotesRoutine, queryMaj23Routine) that decides what message to send based on RoundState and PeerRoundState. So when a msg arrives there are quite some processing that takes place (concurrently) and this is quite tricky to understand and test.
Note that there are quite a few concerns being mixed here. First, core consensus logic. It is basically a deterministic state machine that defines set of rules based on received msgs and timeouts; it updates state and defines what new messages are created and should be gossiped. Second, gossip layer that decides what msgs should be sent based on the round state, peer state and a set of known messages. Third, receiving msgs (at the gossip layer) that updates peer state and sending of messages so others can also receive them, where outcome (success or failure) of msg sending also updates peer state (so we don't need to send this message again). Note that first two concerns can be seen as pure math functions: based on input (msgs and state) it tells you what msgs should be sent and what is the next state. Normally, there are no concurrency-related issues at these levels as they should be normally very fast and the best way to implement it is a single unit of execution (no concurrency). On the other side, third aspect about sending and receiving messages is where we are close to network and we want to take advantage of multiple unit of executions, but algorithmically should be relatively simpler as major complexity is handled at the first two levels. At third level we are making choices related to priority of messages to send/receive, how frequently we will resend messages, etc.
What I am not sure to understand about @ebuchman proposal is at what level (what concerns) it can be applied. Ideally, we should have a way to deal with different concerns separately at the code level. This should make understanding and testing easier.
 milosevic
on 28 May 2018
milosevic
on 28 May 2018
We had a little session back in Fullnode with @milosevic on this. On a high-level it seems favorable to decouple the concerns of the logic and the communication. As zarko described the state handling could be expressed in a purely functional way:
type inMsg interface {
// ...
}
type outMsg interface {
// ...
}
type consensusState struct {
// ...
}
type update func(state consensusState, input inMsg) (consensusState, []outMsg)
Assuming all events, even timing related (timeouts, ticks), are just another input message to the update function the logic can easily and efficiently be tested with a battery of table-driven tests as it doesn't depend on a complex object graph to be set up (it would be a DSL of sorts). On every iteration the new state could be passed to the gossip part which maintains concurrent handles for peers and distribute messages according to the new state, where receives from peers result in new input messages to the update function. In essence the reactor would shrink down to run the gossip layer, keep track of timing events and feed events into the state update and the updated result back into the gossip.
The ReactorResult allows us to specify a list of msgs to send per peer (max one per peer). We try to send all those msgs at once. However we don't block on them. Each msg to send has a callback that we can call from the peer layer to indicate whether the send succeeded or not. This way, we avoid blocking the next Receive, and we can indicate back to the reactor whether it should consider the msg sent or not.
It might be complelx to track if we hand out handles which can be called in remote places, to me it sounds this is some form of Ack mechanism. If that is the case it ought to be explicit in the interface of the reactor. Generally callback approaches haven't been working well in the past as ownership is past around freely and invocation are hard to control and trace.
 xla
on 28 May 2018
xla
on 28 May 2018
This model is missing prioritization. With the existing reactor design, a message from peer A or peer B can cause the change the order of to-send messages to peer A according to priority.
Prioritization still exists as before. It's a concern of the peer layer.
There must be another way that does a good job of abstracting the existing reactor system that doesn't involve forcing an out-queue, yet makes testing easier.
Sure, input/output queues easier to debug, but that doesn't make it the right abstraction.
I read up on the LMAX disruptor again. Seems like a quite fitting model for us:
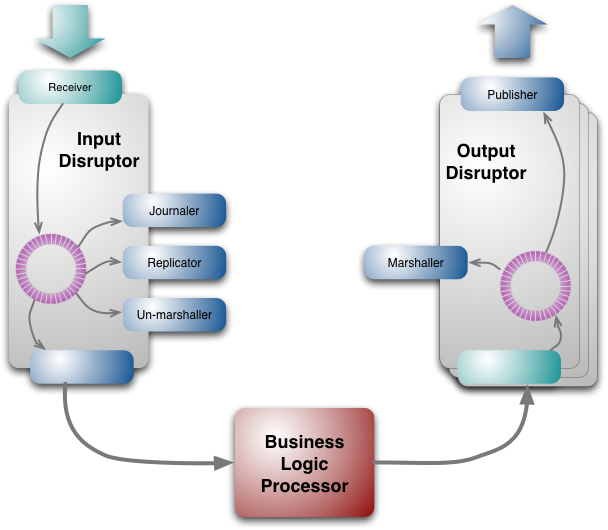
Here, the "Business Logic Processor" is the pure consensus state transition machine. It can take inputs and return outputs.
The input disruptor is what we basically have with the single Receive input. Great.
I think we have some flexibility on the output disruptors. Perhaps the most natural thing is to have one per peer. This might be a really nice way to handle the output of the ConsensusStateMachine - we just load the set of all msgs to send into the disruptors and let the peer layer read from them, and deal with sending them based on priority.
If the output disruptors guarantee delivery for us, then we don't need those ACK callbacks. That'd be great. But it means if the disruptor is full, then we end up blocking Receive. Of course, since we pre-allocate large memory spaces for the disruptors up front, a full disruptor is probably an indiciation of some larger issue and then it should be ok to block ...
One thing the disruptor model doesn't have is timers - so we'd need some way to register timers and add the ticks into the input disruptor.
ebuchman
on 28 May 2018
I really like the idea of the consensus state machine function returning a list of all new msgs to send to peers with every receive, and making it the concern of some other surrounding abstraction to deal with figuring out how and when to send those messages. That would do away with the "call the Receive again immediately" piece. We'd just need to deal with the timers, but that shouldn't be hard.
ebuchman
on 28 May 2018
Hear me out, there's a lot of ideas being thrown out here and some of them are good but I'm pretty sure that I'm not being heard.
Yes, a reactor node in general takes in messages and pushes messages out.
@milosevic First, core consensus logic. It is basically a deterministic state machine that defines set of rules based on received msgs and timeouts; it updates state and defines what new messages are created and should be gossiped. Second, gossip layer that decides what msgs should be sent based on the round state, peer state and a set of known messages. Third, receiving msgs (at the gossip layer) that updates peer state and sending of messages so others can also receive them, where outcome (success or failure) of msg sending also updates peer state (so we don't need to send this message again)
Core consensus logic is defined in consensus/state.go, and it is already well separated out from the reactor. So that is not being mixed. It is already set up to be tested via a WAL, so we're good there. Maybe by core consensus logic you are referring to consensus/reactor.go PeerState and PeerRoundState, but these are part of gossip. The purpose of PeerState and PeerRoundState is to determine what msgs should be sent and prioritized. It isn't a queue because a queue is not the right data-structure to represent what msgs need to be sent. See:
type PeerRoundState struct {
Height int64 `json:"height"` // Height peer is at
Round int `json:"round"` // Round peer is at, -1 if unknown.
Step RoundStepType `json:"step"` // Step peer is at
...
Prevotes *cmn.BitArray `json:"prevotes"` // All votes peer has for this round
Precommits *cmn.BitArray `json:"precommits"` // All precommits peer has for this round
...
}
I removed a lot of fields, but what you see there is Prevotes and Precommits as bitarrays, which mark which votes for the PeerRoundState(H/R) the peer has seen, and which votes we have sent. In a separate gossip goroutine launched for each peer, the goroutine takes a look at both our current state (which holds all the votes seen) and the marked bitarrays in PeerRoundState.Prevotes/Precommits to determine what votes to send next, and then blockingly writes it via Send.
The output channel (or TCP connections in general) is a kind of queue, so technically yes, the reactor is receiving input msgs and it is producing output msgs... But to implement the consensus reactor without concurrency would be a mistake. To optimize for this single-goroutine-input/output-reactor would require more complexity, not less, than what is already implemented with concurrency.
@milosevic Note that first two concerns can be seen as pure math functions: based on input (msgs and state) it tells you what msgs should be sent and what is the next state. Normally, there are no concurrency-related issues at these levels as they should be normally very fast and the best way to implement it is a single unit of execution (no concurrency). On the other side, third aspect about sending and receiving messages is where we are close to network and we want to take advantage of multiple unit of executions, but algorithmically should be relatively simpler as major complexity is handled at the first two levels. At third level we are making choices related to priority of messages to send/receive, how frequently we will resend messages, etc.
I don't agree that the first two concerns are pure math functions. Deciding what message should be sent depends on how well the receiving reactor is processing them (e.g. how slow the connection is). Depending on network performance (and we know that the network performance is a problem because the number of validators is capped as high as possible), we will have to drop some messages over others. Ergo, the second concern requires concurrency for optimum consensus performance. The way it's implemented, this is already taken into account -- there is a vote gossip goroutine that sends the highest priority message greedily. The prioritization is easy to understand: it's in the order as defined by gossipVotesRoutine()... that function spells out the priority.
So to sum up,
- the local consensus state + peer state acts as a prioritized outbox.
- to implement the same kind of prioritization using a single-goroutine-input-output-reactor would result in more complexity, not less. Instead of a function that returns the next highest-priority-message, you will need to implement a complex system that re-orders & dequeues messages.
Prioritization still exists as before. It's a concern of the peer layer.
That's not the prioritization I'm referring to. That prioritization at the MConnection layer can be abstracted away and forgotten about for the scope of this discussion... I'm referring to prioritization at a higher level.
jaekwon
on 29 May 2018
@melekes It's hard to test this as a black box because of all the small "sending" goroutines. Notice there is only one Receive(from), but many Send functions. Should there be one Send(to) function? I would say maybe. That way we can create a mocking function, which writes messages to some queue.
While you could test that, given a new vote that you've never seen (and which no peer has seen) that Receive() returns the same vote to send to every peer.
But what about all the msgs that you wanted to send before, but suddenly got deprioritized? For example, if you were going to send a Vote to a peer, but that peer tells us (before we write that Vote), that they have it via HasVote, or maybe they even sent us the whole Vote). Now we want to not send that Vote. How do we do this? By having Receive() also output a list of "anti-messages"? No, you want to have some peer-level state that tracks what state it's in, and the bitarray of votes that it's seen, etc. That's what PeerState is for.
So it's not sufficient to test a BlackBox(input) []output. You can, but you won't be testing the internals, such as PeerState, which you should be testing. Additionally, as mentioned, []output doesn't do justice to what needs to be implemented for prioritization, and if you try to fit the prioritization I talk about into a queue system, it will end up in more systematic complexity than the system we already have.
We could absolutely create a ConsensusReactor.Send hook, and with a bit of tooling we can send the ConsensusReactor some messages and wait until all channels and peer routines have cleared, and then test that all the messages that went through the hook look OK, and that all the states look OK.
Actually, that sounds like a good idea. I think we just want a way to (1) know that all messages have been processed and (2) (maybe simultaneously) a way to temporarily halt all goroutines, to be inspected for testing and debugging.
jaekwon
on 29 May 2018
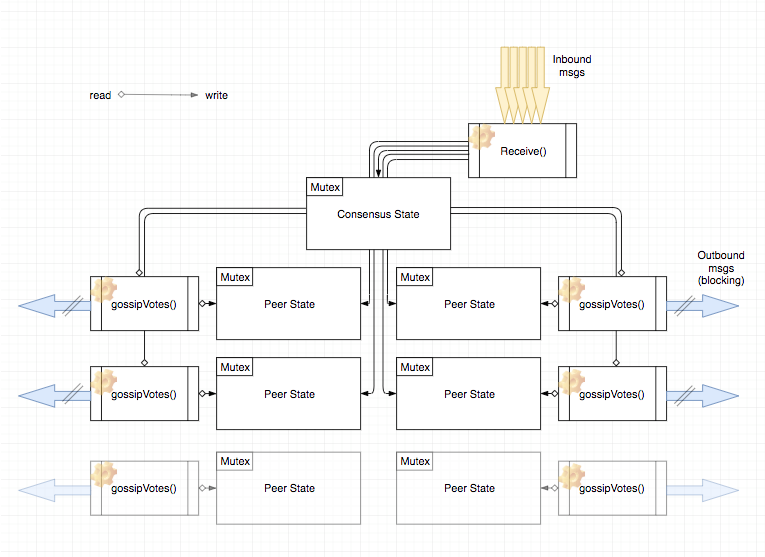
jaekwon
on 29 May 2018
Inbound msgs are quick to handle... they mostly just modify the ConsensusState and PeerState via simple updates. The real workhorse are the little goroutines per peer which also update each PeerState while they write outbound msgs. They run in a tight loop for as long as there are things worth sending.
We're capping our validators at 100 because performance here is a bottleneck with more validators. This architecture will scale out to much, much more, with more parallel cores.
AFAIK LMAX is not relevant, because it doesn't have the same logical requirements that our PeerState has. What we send to our peers is drastically different per peer, and depends on live factors... that's the antithesis of what I understand LMAX to be, which is a single-threaded execution system where all messages are pre-ordered in the input disruptor step, and the order of things to send to listeners is determined by nothing else. (input/output or exchange order txs are simple to model as a non-concurrent system).
While this makes it easy to test transaction logic of a state-machine... I don't think it fits the requirements of what we need to implement for a performant consensus reactor, which I assert should fit more like the graphic pasted above.
Blocking on a send (the blue arrows) for a peer, and then resuming the gossip routine (the for-loop in gossipVotesRoutine()) after send is complete (e.g. .Send() returns and is unblocked), is an efficient and simple way to deal with the concern of prioritization. While the send is blocking, all kinds of updates may happen from Receive()... since we were blocking anyways, there's no point ever computing other messages that we might want to send to the peer. Instead, the for-loop continues after the previous send, and we lazily figure out the next single best message to send. (this doesn't have to be so lazy... the behavior could chance, though the diagram would still be correct).
If in a consensus reactor proposal, there is no immediate causal link between network events (such as a .Send() returning) and re-derivation of the next msg to send... I am suspicious that it's compensating some other how via performance degradation or some other unnecessary complexity that isn't necessary in an architecture with gossip goroutines per peer.
This causal link makes or breaks frameworks. NodeJS was notable in using epoll to get massive concurrency on a callback system. Golang exposes the same power to the programmer via all the network methods via goroutines (something that most languages don't provide afaik.). So to not use goroutines and blocking network calls would be a mistake for our concurrency design problem.
jaekwon
on 29 May 2018
Although I like this discussion (lot of good things said here) I have doubt that issue is too general so it might be hard to move forward in a clear step. I don't think we need major refactor, almost everything we need is there, I just think that it might be possible to organise a code slightly different so it's easier to test different aspects in isolation. I will try to address @jaekwon concerns with concrete issues and potential improvements (when it's clear).
Core consensus logic is defined in consensus/state.go, and it is already well separated out from the reactor. So that is not being mixed. It is already set up to be tested via a WAL, so we're good there.
I agree that core consensus logic is in state.go and that it's well separated from the reactor. But testing of core consensus logic currently requires setting up complete ConsensusState. As @xla illustrated above, this part of the system could be seen as a function, and if we talk purely about correctness I don't understand why it can't be tested in isolation. The test should look like this: initialise a state of a process (RoundState) and then provide a process msg(s) or a timeout, and see if it transition in the right state and if it sends the right msg. We can test various scenarios just by providing various sequence of messages and timeouts.
Maybe by core consensus logic you are referring to consensus/reactor.go PeerState and PeerRoundState, but these are part of gossip. The purpose of PeerState and PeerRoundState is to determine what msgs should be sent and prioritized. It isn't a queue because a queue is not the right data-structure to represent what msgs need to be sent.
As you said, this is part of gossip, it's not core consensus logic. Given RoundState and PeerRoundState gossip algorithm should decide what is the next message that should be sent. Why we can't test this in isolation? Being able to do this might require adding Send api that can be mocked in test or extracting this logic (just the set of rules that defines what msg to send next) as a function and then testing is trivial.
But to implement the consensus reactor without concurrency would be a mistake. To optimize for this single-goroutine-input/output-reactor would require more complexity, not less, than what is already implemented with concurrency.
Completely agree with you here. This is actually what I was saying above. The actual sending and receiving of msgs on the wire should be implemented with concurrency. So there are several routines (as now) that in some sort of loop send/receive msgs. But what msg to send might not be concern of this routine so testing (and understanding) is easier. Imagine that you have a function that based on PeerState and PeerRoundState tells you what msg to send next. Why sending routine shouldn't call this function to get a msg and then send a msg? To be able to (unit) test this part of the code, we need to check that routines are sending some msgs, but we don't necessarily care which one as this is tested above.
I don't agree that the first two concerns are pure math functions. Deciding what message should be sent depends on how well the receiving reactor is processing them (e.g. how slow the connection is). Depending on network performance (and we know that the network performance is a problem because the number of validators is capped as high as possible), we will have to drop some messages over others. Ergo, the second concern requires concurrency for optimum consensus performance. The way it's implemented, this is already taken into account -- there is a vote gossip goroutine that sends the highest priority message greedily. The prioritization is easy to understand: it's in the order as defined by gossipVotesRoutine()... that function spells out the priority.
This is where it seems we disagree. I agree that deciding what msgs to send (prioritization) is critical, but don't understand why we can't model this as a pure function?
That's not the prioritization I'm referring to. That prioritization at the MConnection layer can be abstracted away and forgotten about for the scope of this discussion... I'm referring to prioritization at a higher level.
Agree.
the local consensus state + peer state acts as a prioritized outbox.
Agree. As explained above, the question I am having is what is the best way to unit test it, and my suggestion would be to separate what msg to send from how msgs are being sent. I guess that this shouldn't require major refactoring, just organising code slightly different.
to implement the same kind of prioritization using a single-goroutine-input-output-reactor would result in more complexity, not less. Instead of a function that returns the next highest-priority-message, you will need to implement a complex system that re-orders & dequeues messages.
Agree.
We could absolutely create a ConsensusReactor.Send hook, and with a bit of tooling we can send the ConsensusReactor some messages and wait until all channels and peer routines have cleared, and then test that all the messages that went through the hook look OK, and that all the states look OK. Actually, that sounds like a good idea. I think we just want a way to (1) know that all messages have been processed and (2) (maybe simultaneously) a way to temporarily halt all goroutines, to be inspected for testing and debugging.
Agree fully on goal, but I was hoping that we can avoid (halting all goroutines) by separating concerns as explained above.
...So to not use goroutines and blocking network calls would be a mistake for our concurrency design problem.
Agree here. @jaekwon There might be a misunderstanding because of the way we stated this issue as it was primarily about core consensus logic and not overall consensus reactor. It might be good idea to organise a meeting of @tendermint_team to clarify misunderstandings as I think we are pretty aligned, and to decide precisely on next steps. This issue sets up a good base for that meeting so we can synchronously agree how we want to proceed.
milosevic
on 29 May 2018
@milosevic I agree that core consensus logic is in state.go and that it's well separated from the reactor. But testing of core consensus logic currently requires setting up complete ConsensusState. As @xla illustrated above, this part of the system could be seen as a function, and if we talk purely about correctness I don't understand why it can't be tested in isolation. The test should look like this: initialise a state of a process (RoundState) and then provide a process msg(s) or a timeout, and see if it transition in the right state and if it sends the right msg. We can test various scenarios just by providing various sequence of messages and timeouts.
That sounds reasonable.
@milosevic This is where it seems we disagree. I agree that deciding what msgs to send (prioritization) is critical, but don't understand why we can't model this as a pure function?
I suppose it's possible, to have pure functions that spit out PeerState in the Receive() as pure mutations, but in the end we'd still want to keep track of each PeerState as its own object, attached to it a goroutine, and the PeerState referred to from the ConsensusState. Modeling the logic as pure functions wouldn't help per se, it's not much different than testing a mutable structure as long as the test harness is well designed (a design we should be exploring imo).
Whether you have func pure(a) b or func (o *b) impure(a), doesn't make much of a a difference overall, if the code is well structured.
In the live code, ultimately you still need multiple goroutines. Do we agree there?
My point is, I think we'd be better off testing a mutable object with well defined methods (e.g. mutate via methods and probe the state) than turning these state transitions into pure functions, when we want PeerState and ConsensusState.RoundState as state objects for the gossipVote routine to read (protected by mutexes).
Other than that, I see no way to use pure functions here except a convoluted way where we pass in network events (e.g. this peer did send the latest message) back into the msg input pipe (e.g. Receive), but that would be more complex than less efficient than having independent goroutines with mutex protected ConsensusState.RoundState and PeerState. Since we want the latter anyways, we might as well test impure state transitions.
jaekwon
on 29 May 2018
sounds like at the least we could benefit from reactor functions like:
msg := pickDataMsgForPeer(rs RoundState, prs PeerRoundState) ConsensusMessage
This would form the core pure function in the eg. gossipDataRoutine that would be called to figure out which message to send the peer next. If the msg is nil, we can sleep. Then we can more easily test situations like "if our round state is X and the peer state is Y, what data message should we send the peer"
ebuchman
on 30 May 2018
@jaekwon In the live code, ultimately you still need multiple goroutines. Do we agree there?
Absolutely. The point I was making is that testing part of logic does not necessarily require heavy setup and concurrency (that is needed in live code). Extracting it into a function is standard technique for doing it. I agree that we don't need to have pure functions per se, it can be done also with impure functions as if code is structured well.
Can we agree that next few steps could be:
1) type update func(state consensusState, input inMsg) (consensusState, []outMsg), and test of interests have form: initialise a state of a process (RoundState) and then provide a process msg(s) or a timeout, and see if it transition in the right state and if it sends the right msg. We can test various scenarios just by providing various sequence of messages and timeouts.
2) Part of gossip logic is refactored into:
msg := pickDataMsgForPeer(rs RoundState, prs PeerRoundState) ConsensusMessage, with tests like "if our round state is X and the peer state is Y, what data message should we send the peer".
If we have agreement there, we can create precise issues so it can be implemented. Note that this does not change current concurrency architecture at all, just make it a bit easier to test.
milosevic
on 30 May 2018
type update func(state consensusState, input inMsg) (consensusState, []outMsg)
Presumably here the []outMsg are specifically messages we just created and signed, like our own proposal/prevote/precommit, and nothing to do with gossiping msgs we've already received ?
ebuchman
on 30 May 2018
Presumably here the []outMsg are specifically messages we just created and signed, like our own proposal/prevote/precommit, and nothing to do with gossiping msgs we've already received ?
Exactly.
milosevic
on 1 Jun 2018
sounds great.
jaekwon
on 5 Jun 2018
ebuchman
on 5 Oct 2018
Related issues
melekes
·
30Comments
 yuomii
·
24Comments
yuomii
·
24Comments
 cwgoes
·
23Comments
cwgoes
·
23Comments
 zramsay
·
24Comments
zramsay
·
24Comments
 skdjango001
·
23Comments
skdjango001
·
23Comments
Most helpful comment
sounds like at the least we could benefit from reactor functions like:
This would form the core pure function in the eg. gossipDataRoutine that would be called to figure out which message to send the peer next. If the msg is nil, we can sleep. Then we can more easily test situations like "if our round state is X and the peer state is Y, what data message should we send the peer"