Taichi: ti.grouped returning many copies of same indeces when called on sparse grid
Describe the bug
When ti.grouped is called on a sparse grid it returns many copies of each index. The code snippet I'm providing has a dense grid and a sparse grid, there should be 900 active nodes with dense grid, while ti.grouped returns 48841 active nodes with sparse grid due to it returning many copies of the same indeces over and over.
To Reproduce
Sorry this isn't 20 lines, the sparse grid stuff alone requires that much lol
import taichi as ti
import numpy as np
import triangle as tr
#ti.init(default_fp=ti.f64, arch=ti.gpu) # Try to run on GPU #GPU, parallel
ti.init(default_fp=ti.f64, arch=ti.cpu, cpu_max_num_threads=1) #CPU, sequential
#Sparse Grids
#---Params
dim = 2
invDx = 1.0 / 0.003
nGrid = ti.ceil(invDx)
grid_size = 4096
grid_block_size = 128
leaf_block_size = 16 if dim == 2 else 8
indices = ti.ij if dim == 2 else ti.ijk
#offset = tuple(-grid_size // 2 for _ in range(dim))
offset = tuple(0 for _ in range(dim))
#---Grid Shapes and Pointers
grid = ti.root.pointer(indices, grid_size // grid_block_size) # 32
block = grid.pointer(indices, grid_block_size // leaf_block_size) # 8
def block_component(c):
block.dense(indices, leaf_block_size).place(c, offset=offset) # 16 in 3D, 8 in 2D (-2048, 2048) or (0, 4096) w/o offset
pid = ti.field(int)
block.dynamic(ti.indices(dim), 1024 * 1024, chunk_size=leaf_block_size**dim * 8).place(pid, offset=offset + (0, ))
useSparse = True
grid_m1 = ti.field(dtype=float, shape=(nGrid, nGrid)) # grid node field 1 mass is nGrid x nGrid, each grid node has a mass for each field
if useSparse:
grid_m1 = ti.field(dtype=float)
block_component(grid_m1) # grid node field 1 mass is nGrid x nGrid, each grid node has a mass for each field
#Particle Structures
x = ti.Vector.field(dim, dtype=float) # position
mp = ti.field(dtype=float) # particle masses
particle = ti.root.dynamic(ti.i, 2**27, 2**19) #2**20 causes problems in CUDA (maybe asking for too much space)
particle.place(x, mp)
@ti.func
def stencil_range():
return ti.ndrange(*((3, ) * dim))
def addParticles():
N = 10
w = 0.2
dw = w / N
for i in range(N):
for j in range(N):
x[i*10 + j] = [0.4 + (i * dw), 0.4 + (j * dw)]
mp[i*10 + j] = 0.001
@ti.kernel
def build_pid():
ti.block_dim(64) #this sets the number of threads per block / block dimension
for p in x:
base = int(ti.floor(x[p] * invDx - 0.5))
ti.append(pid.parent(), base - ti.Vector(list(offset)), p)
@ti.kernel
def p2g():
ti.block_dim(256)
ti.no_activate(particle)
particleCount = 0
for I in ti.grouped(pid):
p = pid[I]
particleCount += 1
base = ti.floor(x[p] * invDx - 0.5).cast(int)
for D in ti.static(range(dim)):
base[D] = ti.assume_in_range(base[D], I[D], 0, 1)
fx = x[p] * invDx - base.cast(float)
w = [0.5 * (1.5 - fx) ** 2, 0.75 - (fx - 1) ** 2, 0.5 * (fx - 0.5) ** 2]
#P2G for mass
for offset in ti.static(ti.grouped(stencil_range())): # Loop over grid node stencil
gridIdx = base + offset
weight = 1.0
for d in ti.static(range(dim)):
weight *= w[offset[d]][d]
grid_m1[gridIdx] += weight * mp[p] #add mass to active field for this particle
@ti.kernel
def momentumToVelocity():
activeNodes = 0
for I in ti.grouped(grid_m1):
if grid_m1[I] > 0:
#print("I:", I, " m1:", grid_m1[I])
activeNodes += 1
print('activeNodes:', activeNodes)
addParticles()
grid.deactivate_all()
build_pid()
p2g()
momentumToVelocity()
Log/Screenshots
First is with useSparse = False, second is with useSparse = True
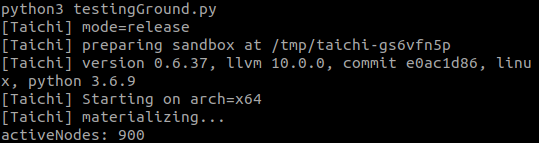
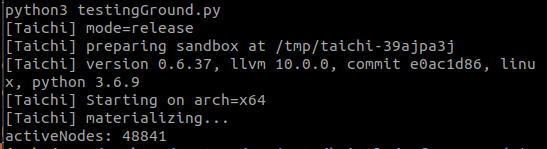
Additional comments
This is either a weird bug or I'm using sparse grids incorrectly due to lack of documentation :(
 JoshWolper
JoshWolper
All 2 comments
Sorry, I think this is definitely a documentation issue...
Note that pid and grid_m1 are stored under the same sparse SNode block. In build_pid() where you call ti.append(pid.parent(), base - ti.Vector(list(offset)), p), many cells in block have been activated already.
If you place grid_m1 into its own sparse data structure, then you should get 900 now. I.e.
if useSparse:
grid_m1 = ti.field(dtype=float)
grid2 = ti.root.pointer(indices, grid_size // grid_block_size) # 32
block2 = grid2.pointer(indices, grid_block_size // leaf_block_size) # 8
block2.dense(indices, leaf_block_size).place(grid_m1, offset=offset)
(I can't think of why exactly the indices will be duplicated in the original code for now, but at least the problem seems to be grouping pid and grid_m1 under the same parent)
 k-ye
on 18 Dec 2020
k-ye
on 18 Dec 2020
Thank you, this resolved the issue!! I'm a little unsure though why in taichi_elements/engine/mpm_solver.py the PID structure appears to be placed on the same SNode as grid_m, and the only difference is the order in which its placed as far as I can tell!
JoshWolper
on 18 Dec 2020
Related issues
 zdxpan
·
3Comments
zdxpan
·
3Comments
 g1n0st
·
3Comments
g1n0st
·
3Comments
 archibate
·
4Comments
archibate
·
3Comments
archibate
·
4Comments
archibate
·
3Comments
 yuanming-hu
·
4Comments
yuanming-hu
·
4Comments
Most helpful comment
Thank you, this resolved the issue!! I'm a little unsure though why in taichi_elements/engine/mpm_solver.py the PID structure appears to be placed on the same SNode as grid_m, and the only difference is the order in which its placed as far as I can tell!