Taichi: [Bug][opengl] mpm99.py rendering failed
Describe the bug
Hi,
The mpm99.py can show FPS and background, but failed to completely render jelly, liquid and snow.
My computer using an Intel HD 4400 chip(integrated graphics). CPU is i3-4160 and OpenGL version is 4.3.
Log/Screenshots
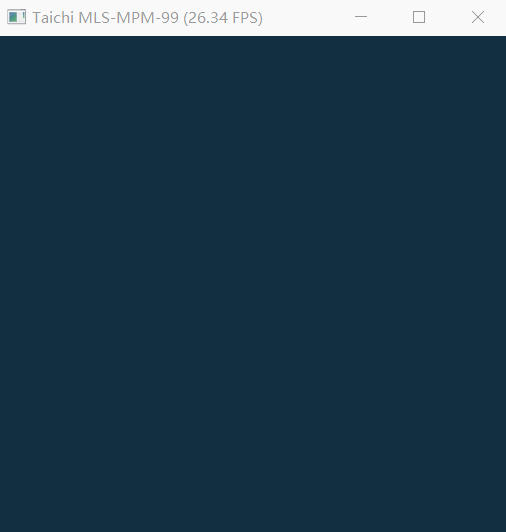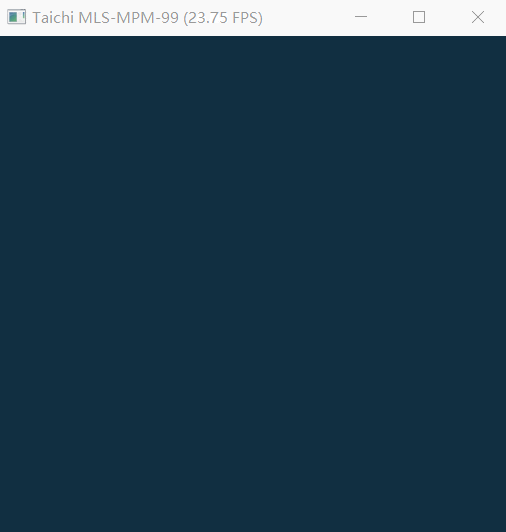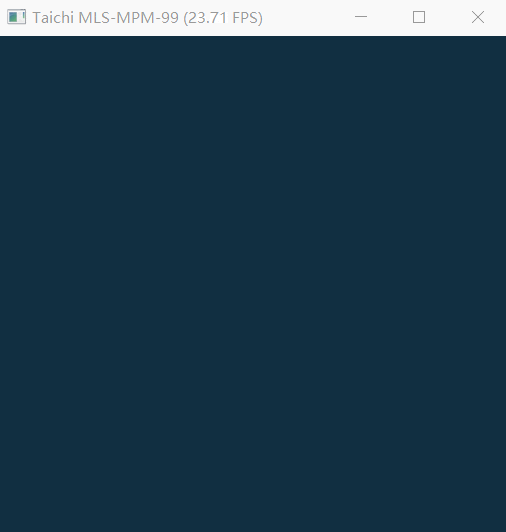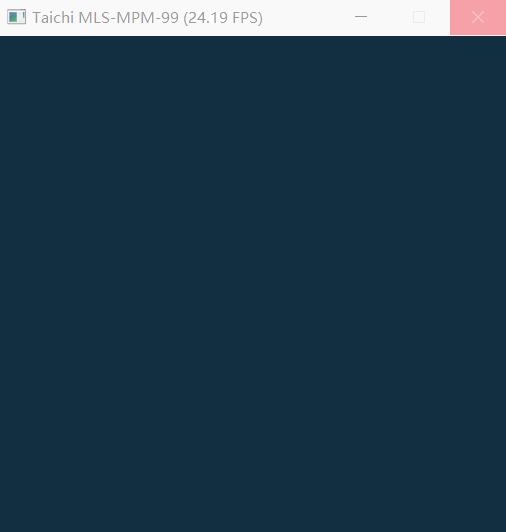
debug.log
To Reproduce
python examples\mpm99.py
If you have local commits (e.g. compile fixes before you reproduce the bug), please make sure you first make a PR to fix the build errors and then report the bug.
 zhiyaluo
zhiyaluo
All 15 comments
Could you also provide the Taichi version?
 k-ye
on 3 Jun 2020
k-ye
on 3 Jun 2020
Could you also run ti test -va opengl to check if OpenGL is functional on your machine?
 archibate
on 3 Jun 2020
archibate
on 3 Jun 2020
Could you also provide the Taichi version?
[Taichi] version 0.6.7, supported archs: [cpu, opengl], commit ca4d9dda, python 3.8.3
Thank you!
Could you also run ti test -va opengl to check if OpenGL is functional on your machine?
The result of ti test -va opengl is 125 failed, 264 passed, 1 warning in 551.79s
Thanks
zhiyaluo
on 4 Jun 2020
Here's a very similar issue: https://forum.taichi.graphics/t/error-graphics-on-windows-with-opengl/161/3.

Could you run examples/fractal.py to confirm that you have this strange border too?
archibate
on 4 Jun 2020
Here's a very similar issue: https://forum.taichi.graphics/t/error-graphics-on-windows-with-opengl/161/3.
Could you run examples/fractal.py to confirm that you have this strange border too?
I confirmed that fractal.py shows strange border. It seems to be the same problem as I'm having.
Thank you for checking.
Screenshot
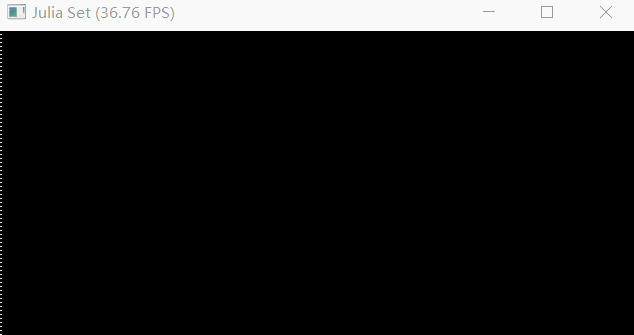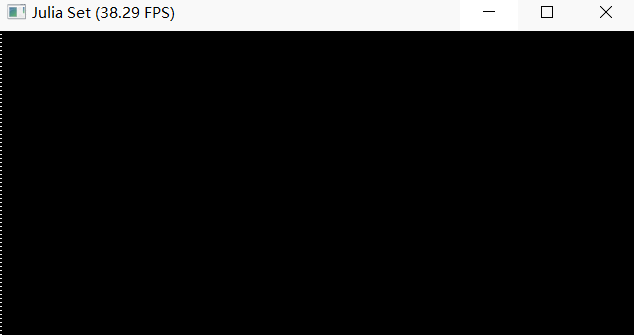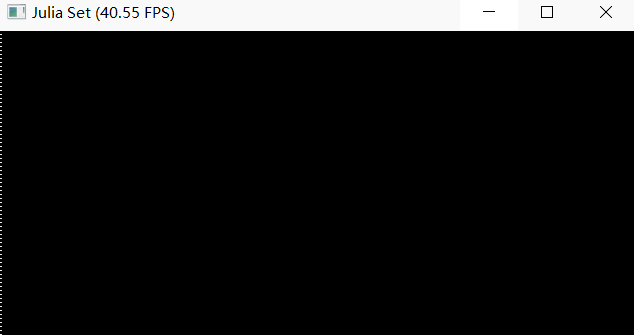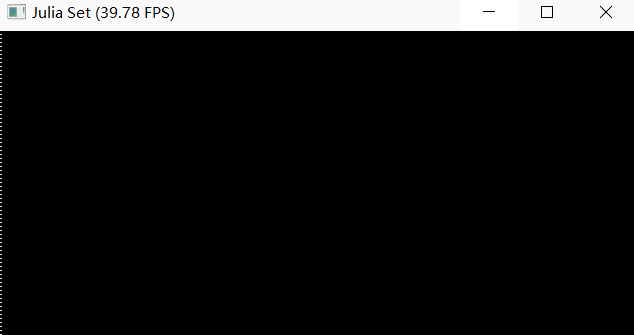
Debug log
[T 06/04/20 09:51:40.554] [program.cpp:taichi::lang::Program::Program@48] Program initializing...
[T 06/04/20 09:51:40.554] [memory_pool.cpp:taichi::lang::MemoryPool::MemoryPool@9] Memory pool created. Default buffer size per allocator = 1024 MB
[T 06/04/20 09:51:40.554] [llvm_context.cpp:taichi::lang::TaichiLLVMContext::TaichiLLVMContext@46] Creating Taichi llvm context for arch: x64
[T 06/04/20 09:51:40.554] [llvm_context.cpp:taichi::lang::TaichiLLVMContext::get_this_thread_data@620] Creating thread local data for thread 10148
[T 06/04/20 09:51:40.555] [llvm_context.cpp:taichi::lang::TaichiLLVMContext::TaichiLLVMContext@71] Taichi llvm context created.
[W 06/04/20 09:51:40.555] [program.cpp:taichi::lang::Program::Program@126] Out-of-bound access checking is only implemented on CPUs backends for now.
[T 06/04/20 09:51:40.555] [program.cpp:taichi::lang::Program::Program@134] Program (0x19c3859b6c0) arch=opengl initialized.
[D 06/04/20 09:51:40.555] [snode.cpp:taichi::lang::SNode::create_node@51] Non-power-of-two node size 640 promoted to 1024.
[D 06/04/20 09:51:40.555] [snode.cpp:taichi::lang::SNode::create_node@51] Non-power-of-two node size 320 promoted to 512.
[T 06/04/20 09:51:40.573] [C:\Users\luozhiya\AppData\Local\Programs\Python\Python38\lib\site-packages\taichi\lang\kernel.py:materialize@256] Materializing layout...
[T 06/04/20 09:51:40.951] [program.cpp:taichi::lang::Program::materialize_layout@279] materialize_layout called
[T 06/04/20 09:51:40.951] [program.cpp:taichi::lang::Program::materialize_layout@304] OpenGL root buffer size: 2097152 B
[T 06/04/20 09:51:40.960] [C:\Users\luozhiya\AppData\Local\Programs\Python\Python38\lib\site-packages\taichi\lang\kernel.py:__call__@463] Compiling kernel paint_c4_0...
[T 06/04/20 09:51:40.981] [constant_fold.cpp:taichi::lang::irpass::constant_fold@211] config.debug enabled, ignoring constant fold
[T 06/04/20 09:51:40.981] [constant_fold.cpp:taichi::lang::irpass::constant_fold@211] config.debug enabled, ignoring constant fold
[T 06/04/20 09:51:40.982] [constant_fold.cpp:taichi::lang::irpass::constant_fold@211] config.debug enabled, ignoring constant fold
[D 06/04/20 09:51:40.983] [opengl_api.cpp:taichi::lang::opengl::display_kernel_info@347] source of kernel [paint_c4_00] * 512:
#version 430 core
#extension GL_ARB_compute_shader: enable
precision highp float;
layout(packed, binding = 6) buffer runtime { int _rand_state_; };
layout(packed, binding = 0) buffer data_i32 { int _data_i32_[]; };
layout(packed, binding = 0) buffer data_f32 { float _data_f32_[]; };
layout(packed, binding = 0) buffer data_f64 { double _data_f64_[]; };
layout(packed, binding = 2) buffer args_i32 { int _args_i32_[]; };
layout(packed, binding = 2) buffer args_f32 { float _args_f32_[]; };
layout(packed, binding = 2) buffer args_f64 { double _args_f64_[]; };
void paint_c4_00()
{ // range for
// range known at compile time
int _tid = int(gl_GlobalInvocationID.x);
if (_tid >= 524288) return;
int _itv = 0 + _tid * 1;
int BA = 512;
int Bu = 0;
float Bp = 0.02;
int Bl = 1;
int Bg = 2;
float Bc = -0.8;
int B3 = 50;
int AY = 20;
float AG = 0.5;
int Au = 320;
float Ar = 0.2;
int O = _itv;
int P = (((0 + O) >> 9) & ((1 << 10) - 1));
int Q = (((0 + O) >> 0) & ((1 << 9) - 1));
int R = 640;
int S = -int(P < R);
int U = -int(Q < Au);
int V = S & U;
if (V != 0) {
float X = float(P);
float Y = float(Q);
float Z = _args_f32_[0 << 1];
float Aq = float(cos(Z));
float As = Aq * Ar;
float At = 0;
float Av = float(Au);
float Aw = X / Av;
float Ay = float(Bl);
float Az = Aw - Ay;
float AB = float(Bg);
float AC = Az * AB;
At = AC;
float AE = 0;
float AF = Y / Av;
float AH = AF - AG;
float AI = AH * AB;
AE = AI;
int AK = 0;
AK = Bu;
while (true) {
float AO = At;
float AP = AO * AO;
float AQ = AE;
float AR = AQ * AQ;
float AS = AP + AR;
float AU = float(Bu);
float AV = AS + AU;
float AW = float(sqrt(AV));
int AX = AK;
float AZ = float(AY);
int B0 = -int(AW < AZ);
int B2 = Bl & B0;
int B4 = -int(AX < B3);
int B6 = Bl & B4;
int B7 = B2 & B6;
if (B7 != 0) {
} else {
if (Bu == 0) break;
}
float Bb = AP - AR;
float Bd = Bb + Bc;
At = Bd;
float Bf = AQ * AO;
float Bh = float(Bg);
float Bi = Bf * Bh;
float Bj = Bi + As;
AE = Bj;
int EF = AX + Bl;
AK = EF;
}
int Bn = AK;
float Bo = float(Bn);
float Bq = Bo * Bp;
float Br = Ay - Bq;
int Bt = 0;
int Bv = Bt + 2097152 * Bu; // S0
int Bw = Bv + 0; // S1
int BB = P * BA;
int BC = Q + BB;
int BD = Bw + 4 * BC; // S1
int BE = BD + 0; // S2
_data_f32_[BE >> 2] = Br;
}
}
void main()
{
paint_c4_00();
}
layout(local_size_x = 1024 /* 512, 524288 */, local_size_y = 1, local_size_z = 1) in;
[T 06/04/20 09:51:40.983] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@117] glCompileShader IN
[T 06/04/20 09:51:40.984] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@119] glCompileShader OUT
[T 06/04/20 09:51:40.984] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@157] glLinkProgram IN
[T 06/04/20 09:51:40.985] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@159] glLinkProgram OUT
[T 06/04/20 09:51:41.023] [C:\Users\luozhiya\AppData\Local\Programs\Python\Python38\lib\site-packages\taichi\lang\kernel.py:__call__@463] Compiling kernel tensor_to_ext_arr_c8_0...
[T 06/04/20 09:51:41.025] [constant_fold.cpp:taichi::lang::irpass::constant_fold@211] config.debug enabled, ignoring constant fold
[T 06/04/20 09:51:41.025] [constant_fold.cpp:taichi::lang::irpass::constant_fold@211] config.debug enabled, ignoring constant fold
[T 06/04/20 09:51:41.026] [constant_fold.cpp:taichi::lang::irpass::constant_fold@211] config.debug enabled, ignoring constant fold
[T 06/04/20 09:51:41.026] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@117] glCompileShader IN
[T 06/04/20 09:51:41.026] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@119] glCompileShader OUT
[T 06/04/20 09:51:41.026] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@157] glLinkProgram IN
[T 06/04/20 09:51:41.027] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@159] glLinkProgram OUT
Hi YuBin,
I also own a windows PC with AMD card and encountered the same problem on it this evening. If you make a fix later I would love to cope with you for further testing.
Best,
 Eydcao
on 5 Jun 2020
Eydcao
on 5 Jun 2020
Great! Thank for narrowing down the range. So this issue is only for windows, not linux, right?
The strange things is @Eydcao and hrukalive reproduced this on AMD card, while @zhiyaluo reproduced this a Intel integrated card...
@zhiyaluo are you sure you're using the Intel card? Does your machine provide dual-card and the second one is AMD?
@Eydcao, could you run this test code for me when you have time? Many thanks :)
import taichi as ti
x = ti.var(ti.f32, 512)
@ti.kernel
def func():
for i in x:
x[i] = i + 1
print(x.to_numpy()) # [1 2 3 ... 510 511 512]
print(x[0]) # 1
print(x[511]) # 512
All the prints are 0.0 with your exact code. But I assume you intended to run func() right? If I add func() before the print, the result for openGL end is below. It seems that the problem is related to pointers/movement operation, since the +1 is applied every 4 indices?

Using cpu backend will give you normal result 1 to 512.
Eydcao
on 5 Jun 2020
Great! This is more than useful! Could you change ti.f32 to ti.f64, and I guess the result will be:
1 0 0 0 0 0 0 0 2 0 ...
If so, I think I have know what's going on there!
archibate
on 5 Jun 2020
Congrats that you may find the pattern, while a bit different from what you predicted. Now it +1 every 2 indices (instead of 8 as predicted). Nonetheless, that is the problem.
[ 1. 0. 2. 0. 3. 0. 4. 0. ...
I found more problems if you change ti.f32 to ti.i32/i64/u32/u64, some errors related to compiler and opengl back-end datatype compatibility will show up (more than one type of error). I will collect those info tomorrow morning ;) good night guys~
Eydcao
on 5 Jun 2020
Have a nice dream! Just for confirm, does
import taichi as ti
x = ti.var(ti.f64, 512)
@ti.kernel
def func():
for i in x:
x[i] = i + 1
a = x.to_numpy()
for i in range(16):
print(a[i], x[i])
prints the all same? So that we know if the data is shifted once again in to_numpy, and the actual shift of f32 can be ... 8/2?
archibate
on 5 Jun 2020
A brief summary to 3 different results of each datatype.
- i32/f32: the results after to_numpy (
ahere) shifts every 4 indices,xprints normally - f64:
ashifts every 2 indices,xprints normally - i64: the 2 screenshots below, seems to be error in
func_c4_00
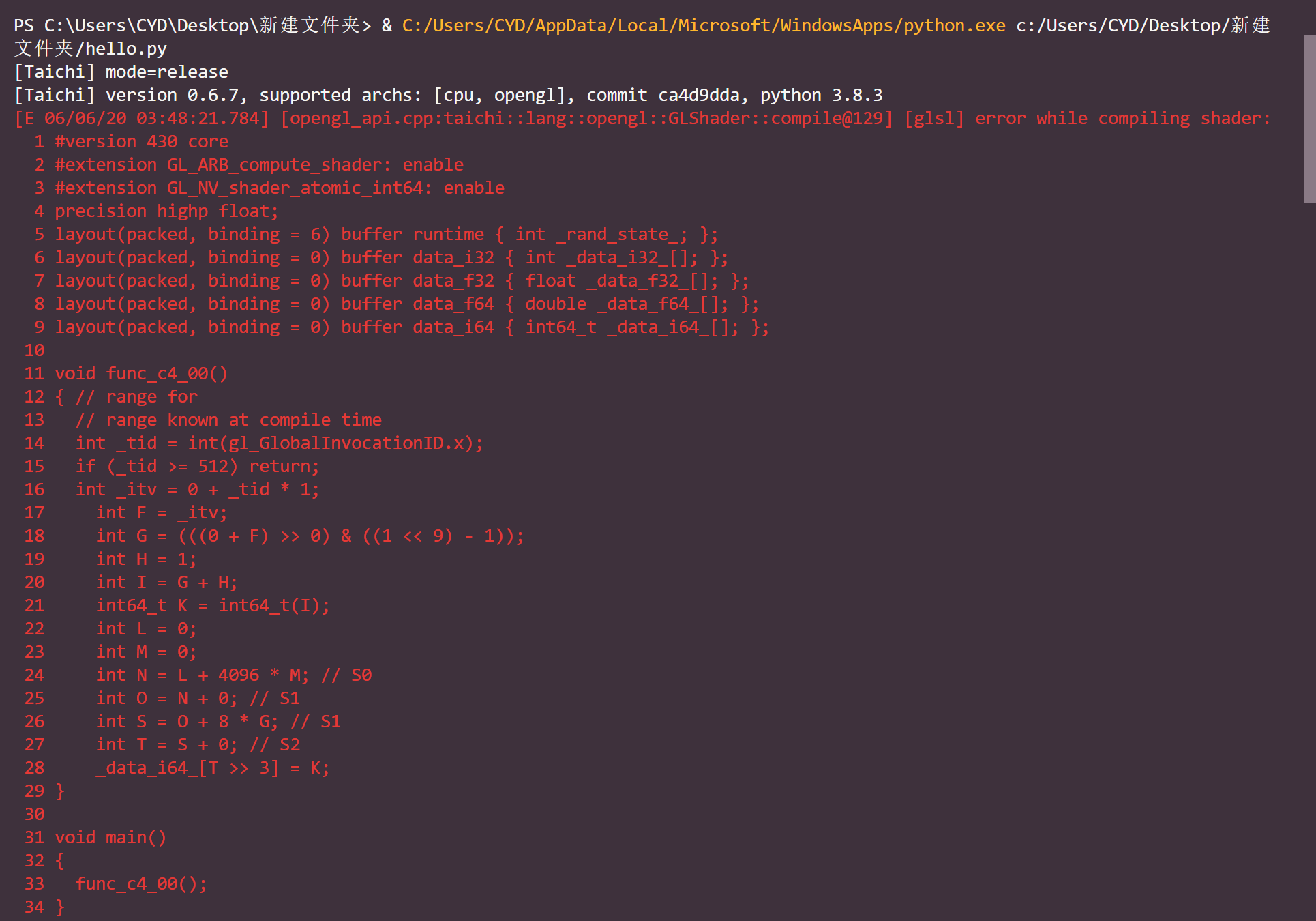
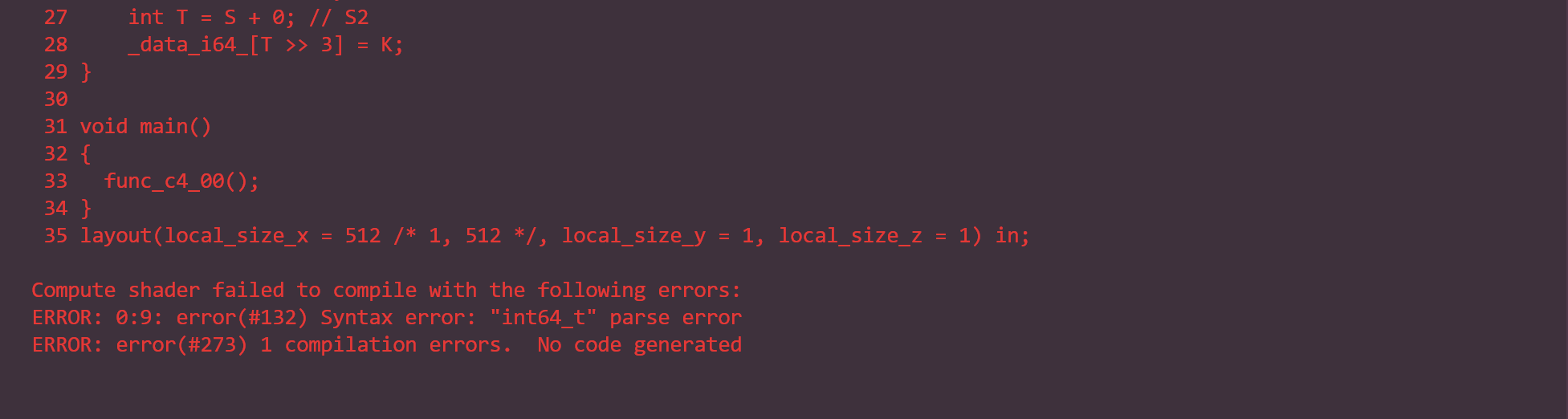
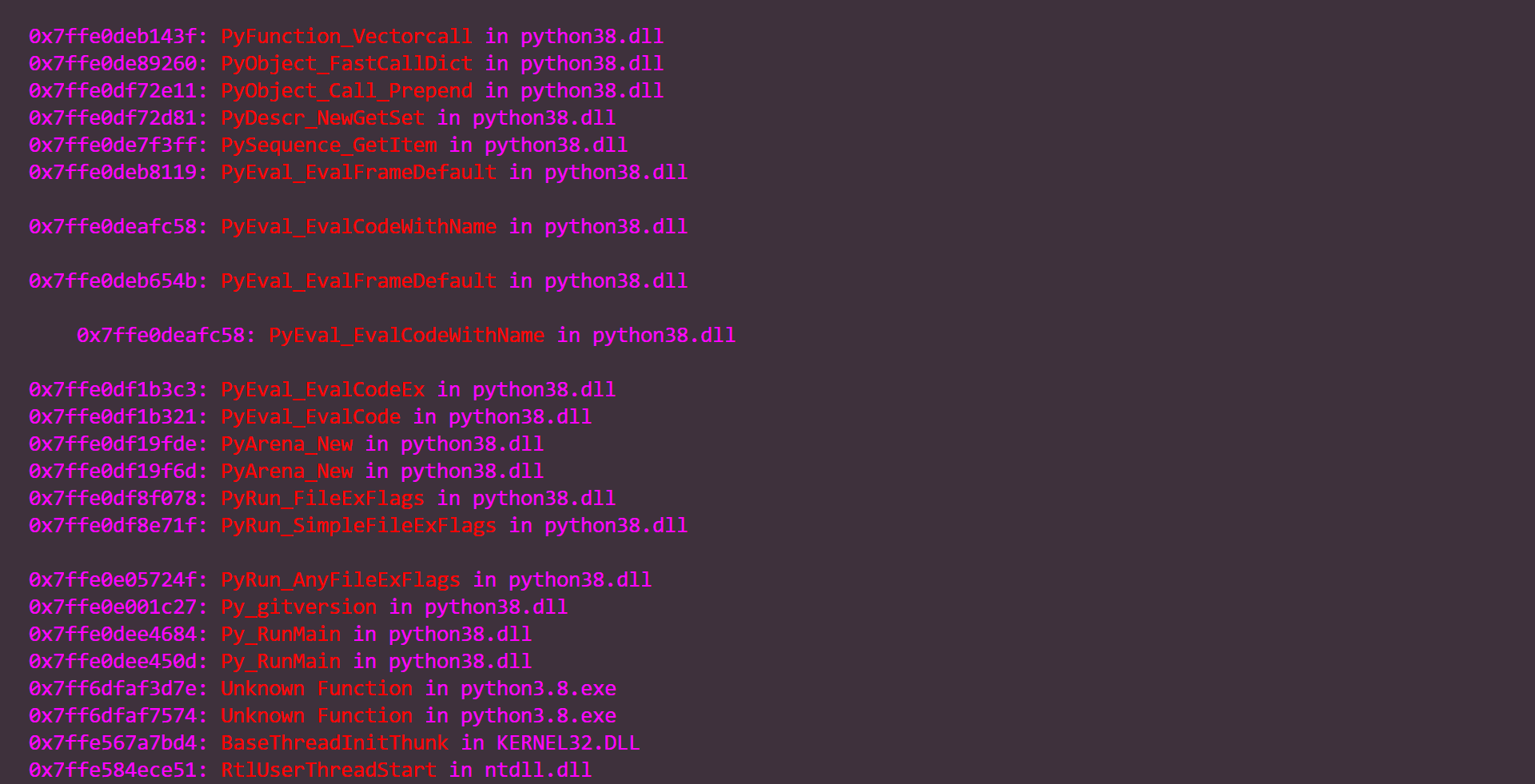
- all other int and unsigned: the 2 screenshots below, it says not supported (datatype) directly

Eydcao
on 6 Jun 2020
are you sure you're using the Intel card? Does your machine provide dual-card and the second one is AMD?
@archibate Well, I didn’t have time to touch the test machine this weekend. I will reply you on Monday of next week. Please wait.
zhiyaluo
on 6 Jun 2020
@archibate
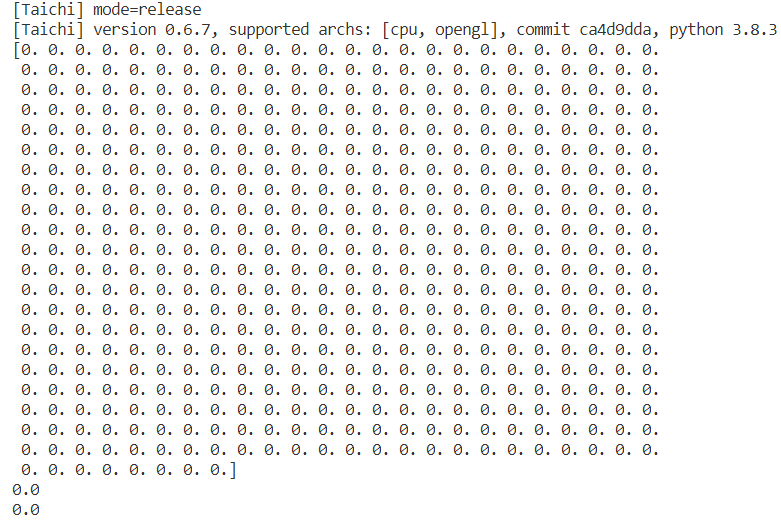
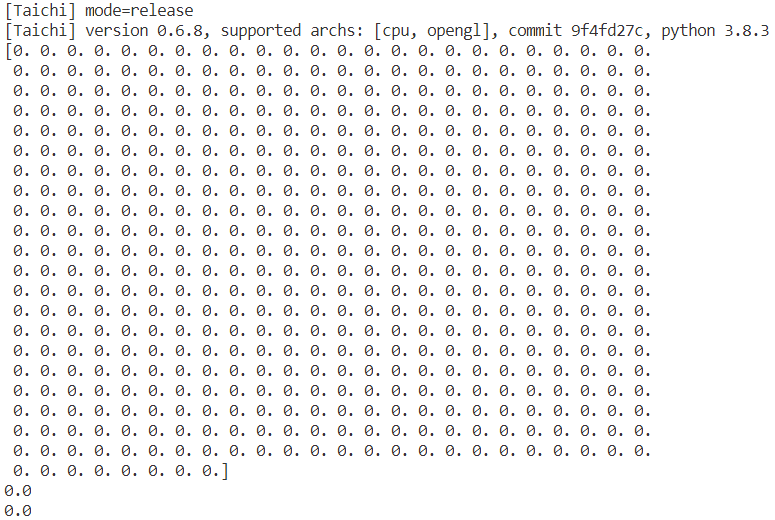
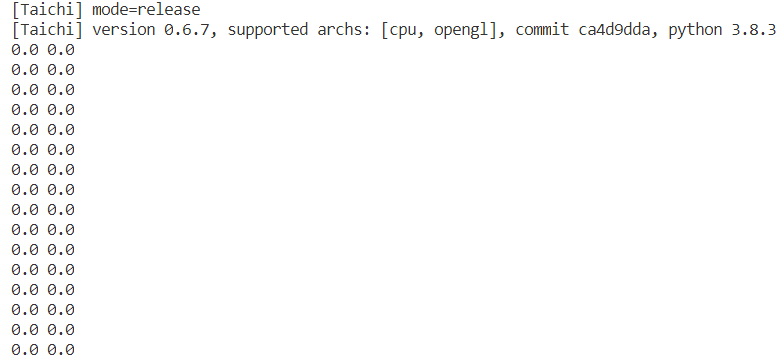
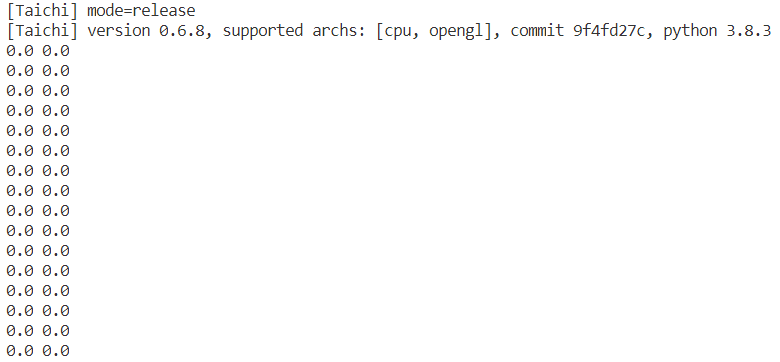
The test machine provide the Intel card only. This problem has been fixed in v0.6.8 version.
Thank you. Sorry about the delayed reply.
Device specifications of CPU and GPU.
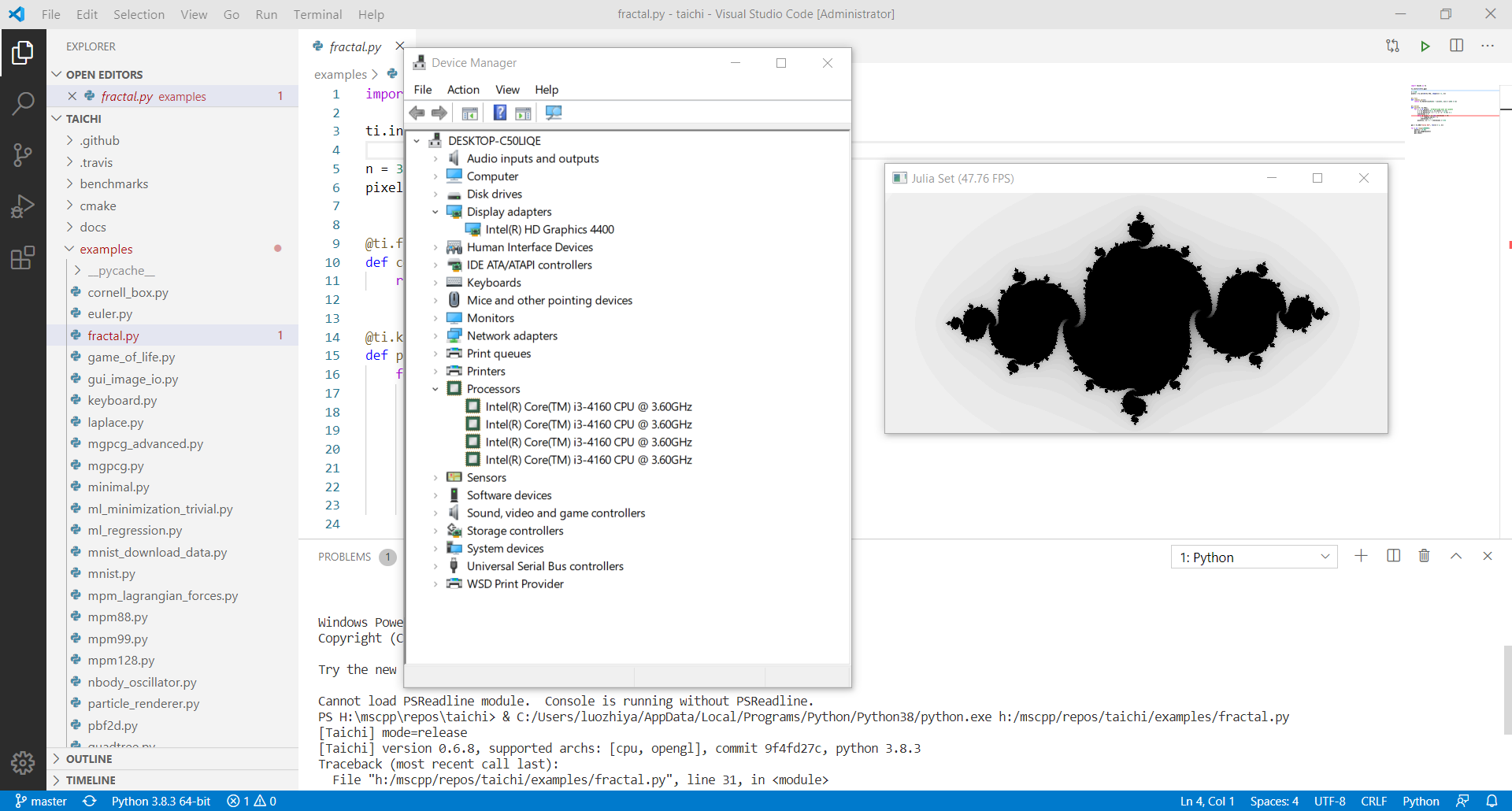
Run the test code in v0.6.7/v0.6.8 version.
import taichi as ti
x = ti.var(ti.f32, 512)
@ti.kernel
def func():
for i in x:
x[i] = i + 1
print(x.to_numpy()) # [1 2 3 ... 510 511 512]
print(x[0]) # 1
print(x[511]) # 512
import taichi as ti
x = ti.var(ti.f64, 512)
@ti.kernel
def func():
for i in x:
x[i] = i + 1
a = x.to_numpy()
for i in range(16):
print(a[i], x[i])
zhiyaluo
on 8 Jun 2020
Related issues
 KLozes
·
4Comments
KLozes
·
4Comments
 yuanming-hu
·
3Comments
archibate
·
4Comments
archibate
·
4Comments
yuanming-hu
·
3Comments
archibate
·
4Comments
archibate
·
4Comments
 Xayahp
·
3Comments
Xayahp
·
3Comments
Most helpful comment
Great! This is more than useful! Could you change
ti.f32toti.f64, and I guess the result will be:If so, I think I have know what's going on there!