Synapse: @kyrias's HS on develop is leaking inbound FDs and filling up with CRITICAL endpoint errors
sierra:borklogs matthew$ cat homeserver.log | grep CRITICAL -A20 | grep '^[a-zA-Z]' | grep -v Traceback | sort | uniq -c
31 AlreadyCalledError
601 IndexError: pop from empty list
Superficially it looks like the number of 'pop from empty list' errors matches the number of leaked inbound connections. Actual failed requests look like:
2017-01-07 13:55:10,882 - synapse.access.https.8448 - 59 - INFO - PUT-53227- 91.134.136.82 - 8448 - Received request: PUT /_matrix/federation/v1/send/1483649379640/
2017-01-07 13:55:10,985 - synapse.metrics - 162 - INFO - PUT-53227- Collecting gc 0
2017-01-07 13:55:11,058 - twisted - 131 - INFO - PUT-53227- Starting factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f388017d8c0>
2017-01-07 13:55:11,061 - twisted - 131 - INFO - PUT-53227- Starting factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f3882e401b8>
2017-01-07 13:55:11,063 - twisted - 131 - INFO - PUT-53227- Starting factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f387faaba70>
2017-01-07 13:55:11,065 - twisted - 131 - INFO - PUT-53227- Starting factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f388fd86290>
2017-01-07 13:55:11,068 - twisted - 131 - INFO - PUT-53227- Starting factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f3889b140e0>
2017-01-07 13:55:11,375 - twisted - 131 - INFO - PUT-53227- Stopping factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f3882e401b8>
2017-01-07 13:55:11,412 - twisted - 131 - INFO - PUT-53227- Stopping factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f387faaba70>
2017-01-07 13:55:11,456 - twisted - 131 - CRITICAL - PUT-53227- Unhandled error in Deferred:
2017-01-07 13:55:11,457 - twisted - 131 - CRITICAL - PUT-53227-
2017-01-07 13:55:11,458 - twisted - 131 - CRITICAL - PUT-53227- Unhandled error in Deferred:
2017-01-07 13:55:11,458 - twisted - 131 - CRITICAL - PUT-53227-
2017-01-07 13:55:11,467 - twisted - 131 - INFO - PUT-53227- Starting factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f3882e401b8>
2017-01-07 13:55:11,474 - twisted - 131 - INFO - PUT-53227- Starting factory <twisted.web.client._HTTP11ClientFactory instance at 0x7f387faaba70>
2017-01-07 13:55:11,625 - twisted - 131 - CRITICAL - PUT-53227- Unhandled error in Deferred:
2017-01-07 13:55:11,625 - twisted - 131 - CRITICAL - PUT-53227-
2017-01-07 13:55:11,789 - synapse.federation.transport.server - 138 - INFO - PUT-53227- Request from kolm.io
2017-01-07 13:55:11,873 - synapse.federation.transport.server - 244 - INFO - PUT-53227- Received txn 1483649379640 from kolm.io. (PDUs: 0, EDUs: 1, failures: 0)
2017-01-07 13:55:12,235 - synapse.access.https.8448 - 91 - INFO - PUT-53227- 91.134.136.82 - 8448 - {kolm.io} Processed request: 1352ms (336ms, 10ms) (21ms/4) 11B 200 "PUT /_matrix/federation/v1/send/1483649379640/ HTTP/1.1" "Synapse/0.18.6-rc3"
Presumably the 'Starting factory' are bogus log contexts though...
 ara4n
ara4n
All 56 comments
The actual stack traces are:
2017-01-07 13:55:11,625 - twisted - 131 - CRITICAL - PUT-53227- Unhandled error in Deferred:
2017-01-07 13:55:11,625 - twisted - 131 - CRITICAL - PUT-53227-
Traceback (most recent call last):
File "/home/synapse/twisted/src/twisted/internet/defer.py", line 150, in maybeDeferred
result = f(*args, **kw)
File "/home/synapse/twisted/src/twisted/internet/endpoints.py", line 849, in iterateEndpoint
checkDone()
File "/home/synapse/twisted/src/twisted/internet/endpoints.py", line 839, in checkDone
winner.errback(failures.pop())
IndexError: pop from empty list
@kyrias - it looks from your logs like you're on a dev version of twisted (my copy of endpoints.py on twisted 16.6.0 doesn't match the line numbers of your stack trace at all, and the server is announcing itself as Server: TwistedWeb/16.6.0dev0, and you're also running the develop branch of synapse.
Given the stack trace has nothing to do with synapse in it, and is instead stuff to do with iterating over twisted endpoints, my guess is that this is related to the ipv6 stuff; either a bug in the changes to synapse for ipv6, or something weird in your dev version of twisted.
Can you try against non-dev twisted please? I'll also try running arasphere on synapse develop (although it doesn't have ipv6 currently) in case i can repro problems there.
ara4n
on 8 Jan 2017
Having poked at it more it seems like somehow using HostnameEndpoint is causing it, but I'm not sure what exactly, and haven't looked at the twisted code yet.
@Glyph Any thoughts?
 kyrias
on 8 Jan 2017
kyrias
on 8 Jan 2017
@kyrias - thanks for bringing this to my attention. I have a rough idea what _might_ be causing the pop from empty list issue; "leaking inbound FDs" really worries me, but it might be a side-effect caused by the unexpected failure type breaking error handling (either within Twisted or in your code).
I'm going to mark this as a potential blocker on our issue tracker - https://twistedmatrix.com/trac/ticket/8963 - can you test with 16.7rc1 specifically to make sure this issue affects the release and wasn't introduced just on trunk?
 glyph
on 9 Jan 2017
glyph
on 9 Jan 2017
For what it's worth I've spent my entire Sunday night looking at this, the last 4 hours straight, and... I've got nothing. I also had @markrwilliams and @mithrandi poking at it and all of us are scratching our heads at how on earth this code https://github.com/twisted/twisted/blob/88a71947b41af21065f7fdfa56a3ffe22a7f5c57/src/twisted/internet/endpoints.py#L817-L886 can result in that traceback. I've tried a half a dozen unit tests that all succeeded.
Is there anything else relevant in your environment which might be interesting? Very slow or very fast networks? A custom name resolver installed on your reactor? We're looking at "cosmic rays" and "a bug in malloc" at this point :).
glyph
on 9 Jan 2017
Thanks for looking into it! Currently running twisted 16.7.0rc1 and synapse v0.18.7-rc2-33-g2f4b2f47, and have it set to listen only to 0.0.0.0.
Nothing that I can think off of the top of my head, alas. Not _very_ fast, just tested and got 773.23 Mbit/s down and 407.13 Mbit/s up. Don't have any code changes, so shouldn't be!
kyrias
on 9 Jan 2017
@glyph I can probably get you access to the manhole ssh service in synapse if that would help though.
kyrias
on 9 Jan 2017
@kyrias I don't know that it would, but at this point I am just at a loss, so it might help to at least be able to inspect the runtime configuration of the reactor.
glyph
on 9 Jan 2017
I've rewritten HostnameEndpoint more or less from scratch. It was a bit more involved than I thought! The new implementation is a rough sketch, but @kyrias, if you could try running with this branch, and it fails, the traceback will at least implicitly explain _why_ it's failing. If it works perfectly then we will have learned something from that as well :).
https://github.com/twisted/twisted/compare/trunk...glyph:statemachine-hostnameendpoint
glyph
on 11 Jan 2017
Success, in that it seems to be working perfectly as far as I can see! Going to monitor the open FD count over the next few hours to see how that progresses as well.
kyrias
on 11 Jan 2017
OK, so, as I understand it, based on IRC conversations, "leaking inbound FDs" is not actually a _new_ bug, and is not provoked by Twisted; the HostnameEndpoint traceback is addressed by my branch (which I guess I should test and submit to Twisted for real now?)
@hawkowl and I are considering just skipping this 16.7 release entirely and trying again for a 17.1. Perhaps we can do that as soon as we have this state-machine change integrated?
glyph
on 12 Jan 2017
I'm fairly certain that the pop from empty list error is caused by debug_deferred the current implementation of HostnameEndpoint assumes that Deferred.callback is synchronous and behaves incorrectly when that assumption is broken.
@kyrias: Do you have full_twisted_stacktraces set (or are some turning on debug_deferreds?
 tomprince
on 12 Jan 2017
tomprince
on 12 Jan 2017
@tomprince Yes. Oh my goodness. Yes. That would explain it. That would explain _all_ of it. The reimplementation is also explicitly less sensitive to timing because it explicitly enumerates all its inputs and can be left in a given state through a reactor tick with no ill effect.
Synapse devs: you can't do this. I am kind of shocked it's working as well as it is, but re-entrancy of Deferreds is an important semantic distinction. _Lots_ of Twisted code might break. Even your own code might not work quite like what you think.
You do not need to callLater(0 a Deferred's callback to get error handling. If errors are getting swallowed, that is a potential GC interaction that needs to be addressed, but there are several ways you can unwind errors without changing the semantics of .callback and .errback.
glyph
on 12 Jan 2017
Ah, indeed it is. Hadn't even thought about checking what it actually did.
kyrias
on 12 Jan 2017
Oops. I had somehow assumed that option was hidden, full of warnings and off for almost everything. Sorry for any time wasted digging into this! I'm nuking that option with fire in #1802 .
I believe the motivation for it was that stack traces were lost if a @defer.inlineCallbacks function threw an exception before the first yield. I'm not sure if its fixed or not in Twisted 16, but if there's a way of fixing it then I'd be interested.
Sorry and thanks again!
 erikjohnston
on 12 Jan 2017
erikjohnston
on 12 Jan 2017
@erikjohnston Thanks very much.
No worries about the time digging into this. Most of the time was spent on the HostnameEndpoint re-implementation, which we _will_ be merging at some point; I'm just really glad we don't have to apply it in a rush for reasons we don't fully understand.
glyph
on 12 Jan 2017
I believe the motivation for it was that stack traces were lost if a @defer.inlineCallbacks function threw an exception before the first yield. I'm not sure if its fixed or not in Twisted 16, but if there's a way of fixing it then I'd be interested.
That sounds like the sort of thing that might have been an issue maybe 6 or 7 years ago at this point, but I can't even remember fixing it at this point. However, this program:
from twisted.logger import globalLogBeginner, textFileLogObserver
from twisted.internet.defer import inlineCallbacks
import sys
@inlineCallbacks
def oops():
x = 1 / 0
yield x
globalLogBeginner.beginLoggingTo([textFileLogObserver(sys.stdout)])
oops()
produces this output, with every version of Twisted back to 15.5 at least:
2017-01-12T02:52:46-0800 [twisted.internet.defer#critical] Unhandled error in Deferred:
2017-01-12T02:52:46-0800 [twisted.internet.defer#critical]
Traceback (most recent call last):
File "raisebeforefirstyield.py", line 11, in <module>
oops()
File "/Users/glyph/Projects/Twisted/src/twisted/internet/defer.py", line 1445, in unwindGenerator
return _inlineCallbacks(None, gen, Deferred())
--- <exception caught here> ---
File "/Users/glyph/Projects/Twisted/src/twisted/internet/defer.py", line 1299, in _inlineCallbacks
result = g.send(result)
File "raisebeforefirstyield.py", line 7, in oops
x = 1 / 0
exceptions.ZeroDivisionError: integer division or modulo by zero
So I'm pretty sure that the tracebacks you want are present and accounted for :)
glyph
on 12 Jan 2017
Awesome!
... with every version of Twisted back to 15.5 at least
Given that some of the packaged versions use system installations of twisted, I wouldn't at all be surprised if we had seen this on things like 15.4.
erikjohnston
on 12 Jan 2017
looks like we had to add debug_deferreds around Twisted 15.1.0 based on the deps at the time of the commit 7639c3d9e53cdb6222df6a8e1b12bc2a40612367
ara4n
on 12 Jan 2017
Note that twisted still throws away stacktraces unless there is an errback attached to the deferred. So
from twisted.logger import globalLogBeginner, textFileLogObserver
from twisted.internet.defer import inlineCallbacks
import logging
import sys
import twisted
print "Twisted:", twisted.__version__
logging.basicConfig(level=logging.DEBUG)
@inlineCallbacks
def oops():
x = 1 / 0
yield
@inlineCallbacks
def foo():
yield oops()
@inlineCallbacks
def bar():
try:
yield foo()
except:
logging.exception("Caught exception")
globalLogBeginner.beginLoggingTo([textFileLogObserver(sys.stdout)])
bar()
Just gives
Twisted: 16.6.0
ERROR:root:Caught exception
Traceback (most recent call last):
File "stacktrace.py", line 22, in bar
yield foo()
ZeroDivisionError: integer division or modulo by zero
 NegativeMjark
on 12 Jan 2017
NegativeMjark
on 12 Jan 2017
can we fix this by putting errbacks on everything? @glyph, is this desired behaviour?
In other news, @kyrias and jeremy on #matrix-dev are still both leaking FDs despite turning off the deferred debugging stuff.
ara4n
on 12 Jan 2017
@ara4n The problem is stdlib logging. This is one of the reasons that Twisted has its own logging system :). Adjusted to this:
from twisted.logger import globalLogBeginner, textFileLogObserver, Logger
from twisted.internet.defer import inlineCallbacks
import sys
import twisted
print "Twisted:", twisted.__version__
log = Logger()
@inlineCallbacks
def oops():
x = 1 / 0
yield x
@inlineCallbacks
def foo():
yield oops()
@inlineCallbacks
def bar():
try:
yield foo()
except:
log.failure("oops")
globalLogBeginner.beginLoggingTo([textFileLogObserver(sys.stdout)])
bar()
you get this traceback instead
Twisted: 16.6.0dev0
2017-01-12T13:56:59-0800 [__main__#critical] oops
Traceback (most recent call last):
File "/Users/glyph/Projects/Twisted/src/twisted/internet/defer.py", line 1445, in unwindGenerator
return _inlineCallbacks(None, gen, Deferred())
File "/Users/glyph/Projects/Twisted/src/twisted/internet/defer.py", line 1299, in _inlineCallbacks
result = g.send(result)
File "what.py", line 16, in foo
yield oops()
File "/Users/glyph/Projects/Twisted/src/twisted/internet/defer.py", line 1445, in unwindGenerator
return _inlineCallbacks(None, gen, Deferred())
--- <exception caught here> ---
File "/Users/glyph/Projects/Twisted/src/twisted/internet/defer.py", line 1299, in _inlineCallbacks
result = g.send(result)
File "what.py", line 11, in oops
x = 1 / 0
exceptions.ZeroDivisionError: integer division or modulo by zero
@glyph ah ha!! thank you :D
ara4n
on 13 Jan 2017
Right: to diagnose the leaking FD issue we did a parallel tcpdump on arasphere.net (unaffected) and kyriasis.com (affected) for a 25 minute window. It seems that normally client requests get timed out from the clientside after 240s, however with @markrwilliams' TCP logging patch applied we can see that the server also thinks it's trying to time out idle connections after 60s.
The stuck FDs seem to be federation connections which send a few requests, and then after 60s the server claims to timeout the connection, but in practice the TCP socket remains established. The client then tries to reuse the socket, sending a full frame of SSL data which gets ACKed at the TCP layer... but nothing at the TLS or HTTP layers, presumably because twisted is no longer reading from the socket. This wedges the client (albeit only on 0.18.5 and earlier, which lack application layer clientside timeouts; there is now a 3 minute app-layer clientside timeout added in #1725) - and meanwhile the server doesn't clean up the socket either. So it leaks forever.
This matches the observation that the stuck connections are only from synapse 0.18.5 and earlier (predominantly 0.18.5, because the remaining 0.18.5 instances are still sending rogue federation traffic).
So, questions are:
- why isn't the 60s serverside connection timeout working?
- how come arasphere.net and others never seem to hit this failure mode? (we've got one other user, though, Jeremy on #matrix-dev, who is seeing the same misbehaviour)
ara4n
on 13 Jan 2017
on arasphere I can clearly see connections where there is a gap of >60s between requests on the same TCP stream, but the connection is still cleared correctly by the client after 240s. i.e. the server doesn't seem to try to timeout the connections after 60s. this is on twisted 16.6.0 release.
ara4n
on 13 Jan 2017
@kyrias downgraded to twisted 15.5.0 and it stopped leaking, so @glyph: i think there is a fairly serious bug in the server initiated timeout code on trunk (which i believe is what @kyrias was on previously).
ara4n
on 13 Jan 2017
OK, if this is a Twisted regression in HTTP flow control, we might want to loop in @Lukasa as well.
glyph
on 13 Jan 2017
The most obvious problem here is that we call loseConnection, not abortConnection. This means that if we have for any reason stopped the transport writing, or the client isn't reading, we won't actually drop the connection.
The simplest resolution here is probably to change the timeout logic to abort the connection, rather than lose it. There's no good reason to want to wait for the client's OK if we timed them out. This would be pretty easily prototyped by changing HTTPChannel.timeoutConnection to call self.abortConnection, rather than calling up to the superclass implementation.
 Lukasa
on 13 Jan 2017
Lukasa
on 13 Jan 2017
@Lukasa would you expect loseConnection to be sending /anything/ to the client? I'm surprised that nothing gets sent to the client at all, and then the next time the client tries to write, it's tarpitted.
ara4n
on 13 Jan 2017
@ara4n I mean, the answer is maybe?
The fact that the client is tarpitted suggests that the server could think that the client isn't reading from its socket, which would cause it to call pauseProducing on the client. Is that happening? Is the client consuming its responses?
Lukasa
on 13 Jan 2017
@Lukasa Here's a pcap as seen by the server (the matching synapse & twisted logs are available if desired):
No. Time Source srcport Destination dstport Protocol Length Info
1 22:08:20.911866 64.137.178.67 40314 212.71.254.33 8448 TCP 74 40314→8448 [SYN] Seq=0 Win=29200 Len=0 MSS=1460 SACK_PERM=1 TSval=61963255 TSecr=0 WS=128
2 22:08:20.911943 212.71.254.33 8448 64.137.178.67 40314 TCP 74 8448→40314 [SYN, ACK] Seq=0 Ack=1 Win=28960 Len=0 MSS=1460 SACK_PERM=1 TSval=29823467 TSecr=61963255 WS=128
3 22:08:20.995097 64.137.178.67 40314 212.71.254.33 8448 TCP 66 40314→8448 [ACK] Seq=1 Ack=1 Win=29312 Len=0 TSval=61963276 TSecr=29823467
4 22:08:21.341872 64.137.178.67 40314 212.71.254.33 8448 TLSv1.2 259 Client Hello
5 22:08:21.341921 212.71.254.33 8448 64.137.178.67 40314 TCP 66 8448→40314 [ACK] Seq=1 Ack=194 Win=30080 Len=0 TSval=29823596 TSecr=61963363
6 22:08:21.370537 212.71.254.33 8448 64.137.178.67 40314 TLSv1.2 1514 Server Hello
7 22:08:21.370556 212.71.254.33 8448 64.137.178.67 40314 TLSv1.2 1514 Certificate[TCP segment of a reassembled PDU]
8 22:08:21.370699 212.71.254.33 8448 64.137.178.67 40314 TLSv1.2 1028 Server Key ExchangeServer Hello Done
9 22:08:21.453436 64.137.178.67 40314 212.71.254.33 8448 TCP 66 40314→8448 [ACK] Seq=194 Ack=1449 Win=32128 Len=0 TSval=61963391 TSecr=29823605
10 22:08:21.453481 64.137.178.67 40314 212.71.254.33 8448 TCP 66 40314→8448 [ACK] Seq=194 Ack=3859 Win=36992 Len=0 TSval=61963391 TSecr=29823605
11 22:08:22.385988 64.137.178.67 40314 212.71.254.33 8448 TLSv1.2 384 Client Key Exchange, Change Cipher Spec, Encrypted Handshake Message
12 22:08:22.392843 212.71.254.33 8448 64.137.178.67 40314 TLSv1.2 292 New Session Ticket, Change Cipher Spec, Encrypted Handshake Message
13 22:08:22.475750 64.137.178.67 40314 212.71.254.33 8448 TCP 66 40314→8448 [ACK] Seq=512 Ack=4085 Win=39936 Len=0 TSval=61963646 TSecr=29823912
14 22:08:23.755594 64.137.178.67 40314 212.71.254.33 8448 TLSv1.2 1562 Application Data, Application Data
15 22:08:23.755643 212.71.254.33 8448 64.137.178.67 40314 TCP 66 8448→40314 [ACK] Seq=4085 Ack=2008 Win=34176 Len=0 TSval=29824320 TSecr=61963966
16 22:08:23.766593 212.71.254.33 8448 64.137.178.67 40314 TLSv1.2 461 Application Data, Application Data
17 22:08:23.849407 64.137.178.67 40314 212.71.254.33 8448 TCP 66 40314→8448 [ACK] Seq=2008 Ack=4480 Win=42752 Len=0 TSval=61963990 TSecr=29824324
18 22:09:04.526280 64.137.178.67 40314 212.71.254.33 8448 TLSv1.2 1820 Application Data, Application Data
19 22:09:04.526346 212.71.254.33 8448 64.137.178.67 40314 TCP 66 8448→40314 [ACK] Seq=4480 Ack=3762 Win=37632 Len=0 TSval=29836552 TSecr=61974159
20 22:09:04.594728 212.71.254.33 8448 64.137.178.67 40314 TLSv1.2 461 Application Data, Application Data
21 22:09:04.677660 64.137.178.67 40314 212.71.254.33 8448 TCP 66 40314→8448 [ACK] Seq=3762 Ack=4875 Win=45696 Len=0 TSval=61974197 TSecr=29836572
22 22:10:40.766333 64.137.178.67 40314 212.71.254.33 8448 TLSv1.2 1523 Application Data, Application Data
23 22:10:40.766396 212.71.254.33 8448 64.137.178.67 40314 TCP 66 8448→40314 [ACK] Seq=4875 Ack=5219 Win=40576 Len=0 TSval=29865424 TSecr=61998219
(raw pcap: http://matrix.org/~matthew/remmy-port-40314.pcap)
The relevant bits of the logs are:
2017-01-12 22:08:20,996 - twisted - 131 - INFO - - Connection.__init__ | fileno: 1271 | addrs: local: ('212.71.254.33', 8448), remote: ('64.137.178.67', 40314)
...
2017-01-12 22:08:21,369 - twisted - 131 - INFO - - Connection.write | fileno: 1271 | addrs: local: ('212.71.254.33', 8448), remote: ('64.137.178.6
7', 40314)
...
2017-01-12 22:08:23,756 - synapse.access.https.8448 - 59 - INFO - PUT-72305- 64.137.178.67 - 8448 - Received request: PUT /_matrix/federation/v1/send/1484011296102/
2017-01-12 22:08:23,759 - synapse.federation.transport.server - 138 - INFO - PUT-72305- Request from shitposters.club
2017-01-12 22:08:23,760 - synapse.federation.transport.server - 244 - INFO - PUT-72305- Received txn 1484011296102 from shitposters.club. (PDUs: 1, EDUs: 0, failures: 0)
2017-01-12 22:08:23,763 - synapse.federation.federation_server - 158 - INFO - PUT-72305- Discarding PDU $148425889689BYCZr:xndr.de from invalid origin shitposters.club
2017-01-12 22:08:23,766 - synapse.access.https.8448 - 91 - INFO - PUT-72305- 64.137.178.67 - 8448 - {shitposters.club} Processed request: 9ms (3ms, 0ms) (2ms/2) 11B 200 "PUT /_matrix/federation/v1/send/1484011296102/ HTTP/1.1" "Synapse/0.18.5"
...
2017-01-12 22:09:04,527 - synapse.access.https.8448 - 59 - INFO - PUT-72400- 64.137.178.67 - 8448 - Received request: PUT /_matrix/federation/v1/send/1484011296275/
2017-01-12 22:09:04,532 - synapse.federation.transport.server - 138 - INFO - PUT-72400- Request from shitposters.club
2017-01-12 22:09:04,534 - synapse.federation.transport.server - 244 - INFO - PUT-72400- Received txn 1484011296275 from shitposters.club. (PDUs: 1, EDUs: 0, failures: 0)
2017-01-12 22:09:04,536 - synapse.federation.federation_server - 158 - INFO - PUT-72400- Discarding PDU $14842589420sQHoC:schnuffle.de from invalid origin shitposters.club
...
2017-01-12 22:10:04,580 - twisted - 131 - INFO - - Timing out client: IPv4Address(TCP, '64.137.178.67', 40314)
I can't decrypt the pcap as it's using ephemeral DH, but judging by the frames flying around I'm going to assume that you can see the two client-server requests... and then nothing happens at 22:10:04 as the server does the timeout, and then at 22:10:40 you see a new request from the client which is ACKed at TCP but no response otherwise, ever again, from the server.
So, TL;DR: yes, the client is consuming its responses.
ara4n
on 13 Jan 2017
Ah goddamn it, I think I can see the bug.
Are you happy to patch your Twisted install? If so, can you edit twisted/web/http.py:2009 (which should currently be policies.TimeoutMixin.timeoutConnection(self) to instead read self.loseConnection()?
Lukasa
on 13 Jan 2017
(Thanks for the pcap file by the way, that ruled out a whole slew of problems which let me narrow right down onto this.)
Lukasa
on 13 Jan 2017
Oh, and in case it wasn't clear: can you then try to repro? ;)
My thinking here, for those following along: a weird quirk of TLSMemoryBIOProtocol is that if you call loseConnection on it, it won't actually do the TLS shutdown if it has a producer registered. For this reason, HTTPChannel.loseConnection explicitly unregisters itself from its transport before it calls loseConnection on that transport, so that the connection shutdown proceeds as expected. This was all added as part of Twisted issue 8868 to resolve the problem of non-reading clients.
At the time no change was applied to the timeout mixin because I didn't see a need. However, rereading the timeout mixin I notice that it doesn't call self.loseConnection but instead self.transport.loseConnection. This, explicitly, does not unregister itself from its transport first, which means that we fall right into the behaviour mentioned above: the TLSMemoryBIOProtocol is ready to shut down, but won't do it until its producer is unregistered. Meanwhile, the HTTPChannel is still registered as a producer. The request should be being delivered to the HTTPChannel, but any response writes will block because write is a no-op on TLSMemoryBIOProtocol while it's trying to disconnect. So HTTPChannel goes on its merry way processing data and handing responses to TLSMemoryBIOProtocol, which happily accepts the bytes and then immediately throws them in the trash, waiting for an unregister that will never come.
Lukasa
on 13 Jan 2017
i'm just trying to help coordinate here :) @kyrias, would it be possible to try patching it?
ara4n
on 13 Jan 2017
My thinking here, for those following along: a weird quirk of TLSMemoryBIOProtocol is that if you call loseConnection on it, it won't actually do the TLS shutdown if it has a producer registered.
It's good thinking that I think I've confirmed.
Here's my example program:
import sys
from synapse.app.homeserver import setup
from synapse.http.matrixfederationclient import (
MatrixFederationHttpClient, _JsonProducer)
from twisted.internet import defer, task
def neverStartProducing(self, consumer):
return defer.Deferred()
_JsonProducer.startProducing = neverStartProducing
@defer.inlineCallbacks
def main(reactor, configuration_path):
hs = setup(['-c', configuration_path])
client = MatrixFederationHttpClient(hs)
yield client.put_json("localhost:8448",
"/_matrix/federation/v1/event/xyz/")
task.react(main, sys.argv[1:])
This sends a request over TLS to the local home server that never completes. If you set a break point in HTTPChannel.timeoutConnection just before policies.TimeoutMixin.timeoutConnection(self), you'll end up here. _appSendBuffer is empty, but _producer is not! And indeed the connection exists after it's supposed to be timed out.
Changing HTTPChannel.timeoutConnection to call self.loseConnection totally fixes it. Well done, @Lukasa :)
 markrwilliams
on 13 Jan 2017
markrwilliams
on 13 Jan 2017
I can confirm that it does seem to be fixed by that for me as well, though I'm going to let it run for a couple hours and report back after that just in case there's anything else going on, heh.
kyrias
on 13 Jan 2017
=D Ok, so don't congratulate me too much @markrwilliams: I introduced the bug. ;)
I'm going to file this as a Twisted issue and propose a patch. We shouldn't consider this closed until @kyrias is satisfied, of course, but I believe that this is definitely a bug, even if it isn't this one.
Lukasa
on 13 Jan 2017
See Twisted issue 8992.
Lukasa
on 13 Jan 2017
As a separate note, we should consider whether timeouts should terminate the connection ungracefully. I'm inclined to say that they should, but it's a pretty substantial change.
Lukasa
on 13 Jan 2017
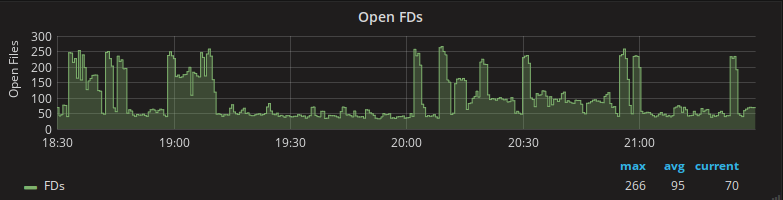
That's the open FDs over the last 3 hours, which I'm pretty happy with!
@Lukasa I guess it depends on the timeout. If possible a graceful termination would pretty much always be preferable, but this is of course not always possible, hm.
kyrias
on 13 Jan 2017
@kyrias This is one of my ongoing concerns about TimeoutMixin: I really want two timeouts. I want the 60s idle timeout, followed by a 15s "if the connection isn't gone by now then totally destroy it" timeout. If @glyph is ok with that idea, I'd like to consider landing that patch in 17.0.
Lukasa
on 13 Jan 2017
That does sound like a good solution to me.
kyrias
on 13 Jan 2017
@Lukasa I am definitely OK with that idea.
glyph
on 13 Jan 2017
Oh, hey, past me was clearly a genius.
Lukasa
on 13 Jan 2017
Right - i think @kyrias's woes are solved for now by running twisted 16.6.0 release rather than trunk.
Meanwhile we have two other instances which look a bit like this bug:
- Schnuffle on #matrix-dev has reported leaking FDs, but believes it's due to a logging misconfiguration (i'm not sure of the details). I'm going to open this as a new bug if it persists.
- Jeremy on #matrix-dev has leaking inbound FDs too, looking identical to @kyrias's symptoms, but with Twisted 15.2 and Synapse 0.18.7. However, he's running on an Ubuntu VPS on Azure, which apparently 'times out TCP connections after 4 minutes'. If Azure's timeout mechanism is to just silently drop the conntrack entry after 4 minutes (i.e. not send any RSTs), this could well cause idle sockets to leak given the server-side timeout problems above. So for now I'm going to ignore this until the server-side timeout bug is fixed.
So on the Matrix side, i'm going to close this one up - huge thanks to @kyrias, @glyph, @markrwilliams, @mithrandi and @lukasa for getting to the bottom of the various woes.
Finally, the Twisted server-side timeout bug is being tracked on https://twistedmatrix.com/trac/ticket/8992, which looks now to have been merged, so we should all be good \o/
ara4n
on 15 Jan 2017
Right - i think @kyrias's woes are solved for now by running twisted 16.6.0 release rather than trunk.
... but @Lukasa 's patch which was supposed to fix this (https://github.com/twisted/twisted/pull/676/files) only made it into twisted 17.1.0, so this doesn't entirely make sense.
 richvdh
on 10 Mar 2017
richvdh
on 10 Mar 2017
@richvdh The code that needed fixing never made it into a final release. 16.6 was before the breakage was introduced. There were some 16.7rc releases that had some issue and never lead to a release. Then 17.1 was released with the fixes.
tomprince
on 10 Mar 2017
@tomprince: that matches my understanding. Just saying, I am surprised that the problem went away for @kyrias.
richvdh
on 10 Mar 2017
i think the reason @richvdh is surprised is because he hit the same misbehaviour today on 16.2. however, i'm wondering if this because 16.2 was missing some other timeout behaviour (as opposed to the stuff which broke in the illfated 16.7 release, which kyrias was running before he reverted to 16.6 and everything got better).
ara4n
on 11 Mar 2017
I thought we conclusively diagnosed this as debug_deferred completely breaking the semantics of Deferreds?
glyph
on 11 Mar 2017
@glyph: that was certainly a cause for brokenness, but leaks were being observed even when it was disabled, per https://github.com/matrix-org/synapse/issues/1778#issuecomment-272296360.
I don't think there is cause for concern here - there is no reason to believe that leaks are still present in twisted 17.1. I just remain a bit mystified as to why kyrias' server would be fixed by a change (downgrade from trunk?) to 16.6.
Rereading now, I wonder if kyrias was actually using 16.6 patched with the fix to 8992.
richvdh
on 11 Mar 2017
Oops
richvdh
on 11 Mar 2017
@ara4n: yes, I did find leaks on 16.3, which surprised nobody except me, having failed to grok 8992 correctly. I don't know if the leaks I was seeing were due to 8992 (though they certainly looked similar), or some other bug which has been fixed along the way. Either way, 17.1 seems happy.
richvdh
on 11 Mar 2017
This is slightly problematic, because to be sure of avoiding leaks, you either need twisted 15.5, which we no longer support in synapse, or 17.1, which is much too new for any of the distros to have yet. I wonder what the chances of getting a patch to 8992 into jessie-backports is.
richvdh
on 11 Mar 2017
Oh, I'm apparently an idiot. I just read this properly:
16.6 was before the breakage was introduced
Nevertheless, we still have a problem in that (some) 16.x versions of twisted seem to leak fds, and those versions may well correspond to what's in some distros.
Sorry for all the noise. I should read more carefully.
richvdh
on 11 Mar 2017
Related issues
ara4n
·
5Comments
 AnwariasEu
·
3Comments
AnwariasEu
·
3Comments
 WGH-
·
4Comments
WGH-
·
4Comments
 APwhitehat
·
4Comments
APwhitehat
·
4Comments
 intelfx
·
3Comments
intelfx
·
3Comments
Most helpful comment
I'm fairly certain that the
pop from empty listerror is caused by debug_deferred the current implementation ofHostnameEndpointassumes thatDeferred.callbackis synchronous and behaves incorrectly when that assumption is broken.@kyrias: Do you have
full_twisted_stacktracesset (or are some turning ondebug_deferreds?