supervisorctl status returns exit code 3 for STOPPED state
When I run supvervisorctl status command, it will exit with code 3, but I can't see any error message
 Aya-Yang
Aya-Yang
All 15 comments
Reproduce Instructions
Create a config file supervisord.conf:
[supervisord]
nodaemon = true
[inet_http_server]
port = 127.0.0.1:9001
[supervisorctl]
serverurl = http://127.0.0.1:9001
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[program:cat]
command = /bin/cat
autostart = false
Start supervisord in the foreground with that config:
$ supervisord -c supervisord.conf
In another terminal, run supervisorctl status:
$ supervisorctl -c supervisord.conf status
cat STOPPED Not started
$ echo $?
3
 mnaberez
on 8 Apr 2019
mnaberez
on 8 Apr 2019
This was introduced in Supervisor 4.0.0 and is caused by these lines added in PR #668:
supervisorctl status will set exit code 3 any time a subprocess is in states.STOPPED_STATES. These are: STOPPED, EXITED, FATAL, and UNKNOWN.
cc: @lukeweber
mnaberez
on 8 Apr 2019
same here
I had to workaround travis
https://github.com/sielaq/PanteraS/blob/master/.travis.yml#L44
 sielaq
on 9 Apr 2019
sielaq
on 9 Apr 2019
:+1:
We have deployment scripts that run supervisorctl status > /dev/null && echo $? to check if supervisor is working properly - and found that 4.0.0 returns 3 because we have some old+busted apps that are perpetually in a stopped state.
For now we will downgrade to a 3.x.x version that works for us, but good to know we're not crazy!(?).
Some updated documentation on this would be great, how could I contribute?
Remember kids: pin your dependency version numbers to something stable!
EDIT: Actually, we find this behavior in 3.3.4 too(?) so our solution is to merely change our deploy script to execute supervisorctl version instead of status and check for exit code 0.
(This is how we validate that supervisor is running and healthy before we attempt a deploy)
 noahlz
on 9 Apr 2019
noahlz
on 9 Apr 2019
EDIT: Actually, we find this behavior in 3.3.4 too(?) so our solution is to merely change our deploy script to execute supervisorctl version instead of status and check for exit code 0.
The PR with this change was not merged into the 3.x branch. The change being discussed here, that supervisorctl status sets the exit code to 3 if a process is in the STOPPED state, was introduced in 4.0.0.
I tested the last 3.x release (3.4.0) and the version you claim is affected (3.3.4) using the reproduce instructions above. For both versions, echo $? shows 0 as it always did in Supervisor 3.x.
mnaberez
on 9 Apr 2019
Supervisor 4.0.0 is a new major release of Supervisor. The major version number was bumped from 3.x to 4.x to communicate breaking changes. Please see the changelog for a list of changes in 4.0.0. One of the changes in 4.0.0 is that supervisorctl now sets exit codes for more conditions.
In Supervisor 3.x, very few conditions caused the exit code to be non-zero. For example, you could supervisorctl start zope and if zope failed to start, the exit code would still be 0. There were several tickets and many commenters requesting that supervisorctl be changed to set meaningful exit codes when possible. So, supervisorctl was overhauled to do this, and those changes were released in 4.0.0. Scripts that expect the exit code of supervisorctl to almost always be 0 will need to be updated.
This ticket is specifically about supervisorctl status setting exit code 3 whenever a process is in the STOPPED state. If you believe this specific behavior is incorrect and/or causes you trouble, please leave a detailed comment why.
mnaberez
on 10 Apr 2019
Apologies, some confusion over here. 3.4.0 definitely doesn't show the behavior.
$ sudo supervisorctl status
<novus service> STOPPED Apr 09 11:50 PM
$ echo $?
0
$ sudo supervisorctl version
3.4.0
Our infra is just a bit messed up and even though we downgraded from 4.0.0 to a prior version, we still needed to force the supervisord process to restart in order for it to use the 3.4.0 version.
Thanks!
noahlz
on 10 Apr 2019
It has been two full months since this issue was reported. There have been no additional comments here, and no related issues reported, in that time.
Many users requested that supervisorctl set exit codes to make automating it easier. The change was made in a major release (4.0). The change will not be reverted. Users who need the old behavior where supervisorctl does not set exit codes will need to stay on a 3.x version.
mnaberez
on 11 Jun 2019
@mnaberez I fail to see how this ...:
The major version number was bumped from 3.x to 4.x to communicate breaking changes. Please see the changelog for a list of changes in 4.0.0. One of the changes in 4.0.0 is that supervisorctl now sets exit codes for more conditions.
[...]
This ticket is specifically about supervisorctl status setting exit code 3 whenever a process is in the STOPPED state. If you believe this specific behavior is incorrect and/or causes you trouble, please leave a detailed comment why.
... is "shown" here:
- ``supervisorctl`` will now set its exit code to a non-zero value when an
error condition occurs. Previous versions did not set the exit code for
most error conditions so it was almost always 0. Patch by Luke Weber.
I understand that you have improved this, but, I don't see why supervisorctl status would return 3 on services that I haven't autostarted / called ever since registering. I am not sure what the correct fix would be.
- I would like that, when I am trying to check service's status, that I am greeted with
$?=0whensupervisorctl"feels" that everything is "business as usual" and "no internal errors"? - Then, there are other issues that are coming: How am I to discern when e.g. this
<class ''xmlrpclib.Fault''>, <Fault 6: ''SHUTDOWN_STATE''>failure (https://github.com/Supervisor/supervisor/issues/48), from (IMHO) a "valid" state (like the one described above)?
 stdedos
on 11 Jun 2019
stdedos
on 11 Jun 2019
I fail to see how this ...:
... is "shown" here:
At this point, this issue has been open for discussion for two full months with no additional feedback. I understand you do not agree with the precise wording of the changelog, but the exit codes will not be reverted. Many users requested them. The current implementation was in the git master branch for almost a year before it was released, and no feedback then either.
I would like that, when I am trying to check service's status, that I am greeted with $?=0 when supervisorctl "feels" that everything is "business as usual" and "no internal errors"?
It doesn't have a way to divine what "business as usual" means so instead it uses the exit code to communicate the process status from a predefined list. If the processes are all running then you get 0, if a process is stopped then you get 3.
Then, there are other issues that are coming: How am I to discern when e.g. this
, failure (#48), from (IMHO) a "valid" state
An exit code of 0 means all subprocesses are running. An exit code of something else means the exit codes need to be compared to see what the issue might be. If 3, then a process is stopped. If some other value, then something else is happening.
mnaberez
on 11 Jun 2019
[...]
, and no feedback then either.
In my case, I was pulling it as apk add supervisor. I recently found out it pulled python2 however; so now I tried pip3, which then "informed" me of all this. I understand that limited feedback causes this, and I apologise for that
It doesn't have a way to divine what "business as usual" means.
If I do systemctl status on my Ubuntu, it won't give me non-zero status because e.g. apache is stopped (especially if it's stopped / non-started by me).
I understand that supervisors task might be different though (manage a single [?] containarized service?), so, I am definitely not saying to revert the change.
However, there are tools that depend on "success" exit code (i.e. 0), like Ansible, that need to be handled appropriately.
An exit code of 0 means all subprocesses are running. An exit code of something else means the exit codes need to be compared to see what the issue might be. If 3, then a process is stopped. If some other value, then something else is happening.
So, does that mean "definitely" that: supervisorctl status gives $?=3 when "everything is okay", except that there are managed services that are stopped in some way?
I could teach Ansible that failed_when: supervisorctl_status.rc not in [0,3]; however, it makes it complicated to check then if a service is in an "unexpected" vs expected stop state.
Color-reading this:
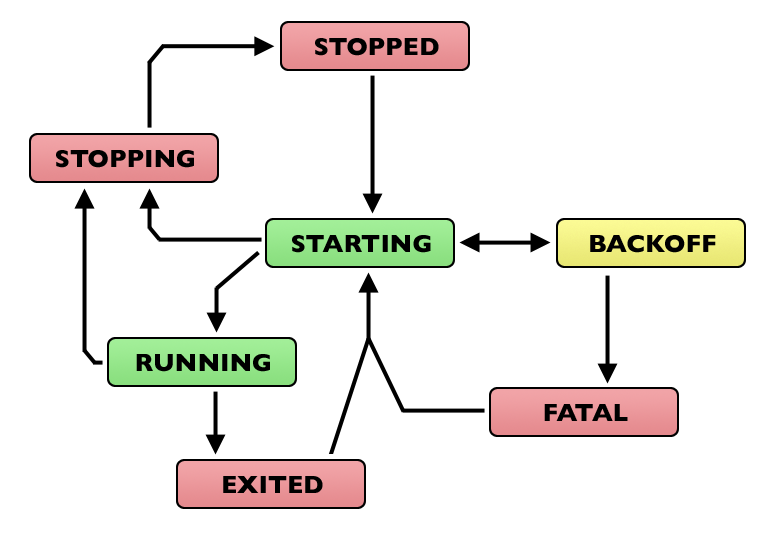
It seems that there is no expected vs unexpected discrimination on stopped states (I _obviously_ read the text too, but, handling appears to be as described)
stdedos
on 11 Jun 2019
Previous discussion about this included in these, maybe useful for background: https://github.com/Supervisor/supervisor/issues/24, https://github.com/Supervisor/supervisor/pull/620
Actual change: https://github.com/Supervisor/supervisor/pull/668
I did this work about 4 years ago, so forgive me if I miss a detail, and the issue has been around since 2011. One should be able to monitor a single process by supplying the name of the process you're interested in of list of them which might help, i.e. supervisorctl status foo baz not including your bad process name that never runs that you don't want status on(why monitor it if it's never running right?).
The previous state, was that even if you couldn't connect to the supervisord daemon, then supervisorctl would return 0 with a difficult to parse error string, which was definitely a problem for many(see tickets and related tickets).
So we tried to make things a bit more useful by standardizing on:
http://refspecs.linuxbase.org/LSB_3.0.0/LSB-PDA/LSB-PDA/iniscrptact.html
Aggregated status was always a bit of a question. I think if supervisord wanted to model it's status command on systemctl then adding is-enabled, is-available, and is-failed would be good additions for the future. In the interim, if you wanted a safer behavior that detected failure cases at the status level, and don't mind stopped processes, ignoring 3 is maybe an option. If you want the original behavior, you probably better be parsing the text output and then you should probably ignore the status as it was almost always 0 anyways.
Would be nice to ground a feature request maybe in a specific need. I don't believe that in a majority of cases where people check for status=0 they're actually getting something more than a false sense of security, and maybe verification that python and supervisorctl is installled.
 lukeweber
on 11 Jun 2019
lukeweber
on 11 Jun 2019
I am going to reopen this issue. This is not a reversal of any decision. My intention is to make it easier for this discussion to continue for a while since there is new activity.
mnaberez
on 11 Jun 2019
@lukeweber
supervisorctl status foo baz not including your bad process name that never runs that you don't want status on(why monitor it if it's never running right?).
In this case, I want supervisors status (hence the supervisorctl status). And so far, the approach I am taking in my project is: autostart necessary services (e.g. sshd), and on-demand start whatever is needed / bundled in (e.g. apache).
I may be able to use the supervisor.d/*.conf scheme with conditional copies, but it was easier for a spike to "just have all the definitions there"
Would be nice to ground a feature request maybe in a specific need.
Yes, this is why I am discussing (and explicitly not to ask to revert #668, but rather more "finely define it"). So far, I have only spiked its usage, so at the very most, I can provide a "formal" use case (second part of https://github.com/Supervisor/supervisor/issues/1223#issuecomment-500738348).
I don't believe that in a majority of cases where people check for status=0 they're actually getting something more than a false sense of security, and maybe verification that python and supervisorctl is installled.
Returning always zero is a bad thing. The other problem is that, only 0 is "the one true all good" exit code, and then the rest indicate some kind of "not as expected" behavior.
However, overloading exit codes can be equally bad:
- If
supervisor's objective was "systemctlbut smaller and simpler", then "overloading" exit code to say if there are stopped services would be wrong. - If
supervisor's objective is to provide service management for minimilistic docker containers, where all defined services are defined as MUST be up, then returning non-zero is mandatory.
If [2] is true, it would be nice that there is an explicit mention somewhere that 'supervisorctl status'.rc == 3 is that and only that. And make sure not to "mangle" LSBInitErrorCode.UNIMPLEMENTED_FEATURE with LSBStatusErrorCode.NOT_RUNNING (since both of them return 3)
stdedos
on 12 Jun 2019
I just ran into this. We deploy stuff using Salt and salt uses supervisorctl status to get list of running/configured apps. Exit code 3 breaks this as salt considers any exit code other than 0 to be a failure.
I can understand why exit codes may be used as a way of communicating the status of processes (although I don't agree with the approach). However, I feel STOPPED and STOPPING should be excluded from list of _bad_ exit codes. If a process is FATAL or BACKOFF then it makes sense to send a 3 exit code but it seems unfair to "fail" a command (non-zero exit code) if some processes have been stopped on user request.
 redbaron4
on 5 Jul 2019
redbaron4
on 5 Jul 2019
Related issues
 flaugher
·
30Comments
flaugher
·
30Comments
 ojii
·
20Comments
ojii
·
20Comments
 jvanasco
·
46Comments
jvanasco
·
46Comments
 lra
·
60Comments
lra
·
60Comments
 mminer
·
41Comments
mminer
·
41Comments
Most helpful comment
I just ran into this. We deploy stuff using Salt and salt uses
supervisorctl statusto get list of running/configured apps. Exit code 3 breaks this as salt considers any exit code other than 0 to be a failure.I can understand why exit codes may be used as a way of communicating the status of processes (although I don't agree with the approach). However, I feel
STOPPEDandSTOPPINGshould be excluded from list of _bad_ exit codes. If a process isFATALorBACKOFFthen it makes sense to send a3exit code but it seems unfair to "fail" a command (non-zero exit code) if some processes have been stopped on user request.