Substrate: srml-contracts: charge for the size of loading storage
We allow for storing arbitrary sized values in storage for contracts. Obviously, we allow loading arbitrary sized values. This, however, might pose an issue for gas metering since with current available API we don't have a means of getting the size of the value before loading it.
ℹ️Note that this assumes the size of the value contributes a non-negligable amount.
Here are some ideas:
- srml-contracts can augument every value with another cell storing its size. This will make every load to perform 2 trie accesses and thus not desirable.
- gas can be taken after the loading is complete. However this opens up a possibility that with minimal amount of gas a malicious actor can perform loads of max possible sizes. Coupled with a
ext_callto another contract with capped gas this might be an issue. - a gas deposit can be taken upfront up to maximal size. Then, after loading and determining the size, we can refund the unused gas. (Note, that we were to add a user specified cap, it will be equivalent to the pt.2)
 pepyakin
pepyakin
All 6 comments
a gas deposit can be taken upfront up to maximal size
This implies that a user can't provide the exact amount of gas necessary for computation, but have to provide: gas that will be used + gas needed to load maximum size value
I feel like this property if accepted could be use for various similar mecanism: if we don't know the specific price in advance, charge the maximum and refund the actual price when you know it.
But then the amount of gas necessary to execute a call is amount of gas used + max(all mecanism that take gas and refund when knowing value) or more if those mecanism can operate in parallel in the code.
 thiolliere
on 27 Jun 2019
thiolliere
on 27 Jun 2019
I did some benchmarking on how storage value size and trie structure affect storage load times. To fetch a value from storage, it requires a trie traversal currently*. I ran some benchmarks against a Trie implemented over RocksDB on my laptop.
The idea is to vary both the byte size of the value and the number of trie nodes that need to be traversed to access it. There is a "branch nodes" parameter which is a divisor of 256 (since contract storage uses 256-bit keys) and a "value size" parameter. A trie database is initialized with values placed at keys with 32 \x00 bytes and 1 bit set. Essentially, this should create branch nodes along the left-most branch of the trie. Then a value of the specified byte size is written to the all-\x00 key. During the benchmark, this value is read repeatedly from storage without busting the RocksDB cache. The RocksDB cache size is set at the default, which is as it is in Substrate, though maybe this should also be varied in further experiments. You can see the code here.
The results are shown in these graphs:
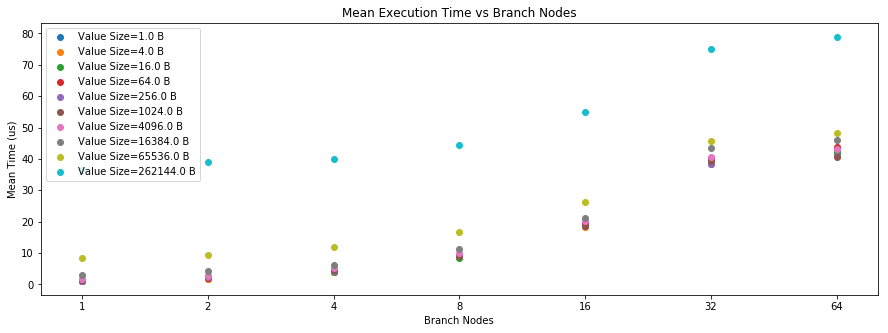
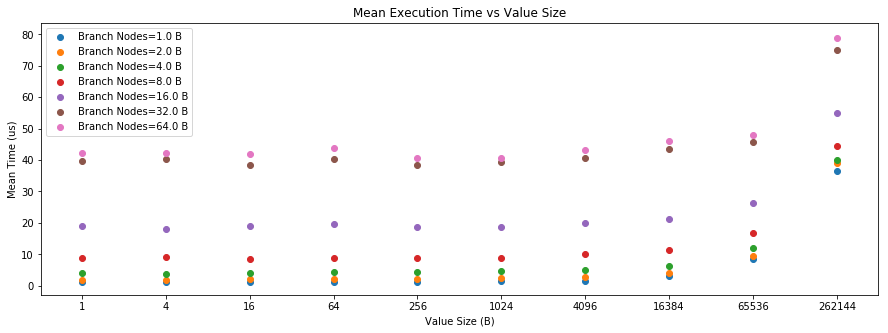
What you can see is that value size has some, but a pretty small impact, on read times for values <4 KiB - 64 KiB. Especially compared to the effect of the trie configuration, the impact seems pretty negligible.
For those curious why increasing branch nodes from 32 to 64 doesn't change the timing much, it's because the branch nodes are evenly spaced, each with an extension node afterward in the case of 32 branch nodes, so the total number of nodes traversed is the same.
Hardware: my laptop has an Intel i7-7700HQ CPU and NVMe storage.
So my conclusion is that we should cap value sizes at 4 KiB or 16 KiB and have the cost of ext_get_storage be independent of the value size. If anything, this suggests that the gas price is going to likely have to account for the worst-case scenario of 64 trie node lookups. Allowing values greater than 16 KiB is probably a bad idea anyway, as LSM databases like Rocks have relatively poor write performance for large values.
*This is not strictly necessary if there was an auxiliary index of keys directly to their trie value nodes or values if <32 bytes, but that's slightly tangential to this issue. Though if we had this index, we could store the value sizes in it as well, which is also a possible solution to this issue.
 jimpo
on 10 Jul 2019
jimpo
on 10 Jul 2019
Cool, so the initial assumption indeed doesn't hold! Then closing this issue in favor of https://github.com/paritytech/substrate/issues/2192 . Thanks, @jimpo this is super useful!
pepyakin
on 10 Jul 2019
Did you prime the RocksDB with data before running the benchmark to simulate a full DB (for some definition of full)? On parity ethereum we have some data suggesting that RockDB read performance suffer quite a lot as the database increases in size. FWIW our testing there also found that the payload size is not too significant a parameter as long as you stay below 16k.
 dvdplm
on 10 Jul 2019
dvdplm
on 10 Jul 2019
@dvdplm Hmm, I didn't fill the whole database, I just filled values along the trie path to the target value. Do you know if the degraded performance was because of a larger database or a larger trie (ie. more node traversals)? I just assumed the latter was going to make a bigger difference, but I could try a larger DB as well.
jimpo
on 10 Jul 2019
Another option to consider is to not allow arbitrary loads/stores of values but to use more file-like api, probably without a cursor notion.
So when you do load, on low-level you specify the position of the value and the length of the desired data with each call (this also can be used for partial loads of values).
So read(<key>, ptr) becomes read(<key>, ptr, 0, <value length>) for full value read
 NikVolf
on 10 Jul 2019
NikVolf
on 10 Jul 2019
Related issues
 lovesh
·
3Comments
lovesh
·
3Comments
 gavofyork
·
4Comments
gavofyork
·
4Comments
 tomaka
·
5Comments
tomaka
·
4Comments
tomaka
·
5Comments
tomaka
·
4Comments
 Mischi
·
5Comments
Mischi
·
5Comments
Most helpful comment
I did some benchmarking on how storage value size and trie structure affect storage load times. To fetch a value from storage, it requires a trie traversal currently*. I ran some benchmarks against a Trie implemented over RocksDB on my laptop.
The idea is to vary both the byte size of the value and the number of trie nodes that need to be traversed to access it. There is a "branch nodes" parameter which is a divisor of 256 (since contract storage uses 256-bit keys) and a "value size" parameter. A trie database is initialized with values placed at keys with 32 \x00 bytes and 1 bit set. Essentially, this should create branch nodes along the left-most branch of the trie. Then a value of the specified byte size is written to the all-\x00 key. During the benchmark, this value is read repeatedly from storage without busting the RocksDB cache. The RocksDB cache size is set at the default, which is as it is in Substrate, though maybe this should also be varied in further experiments. You can see the code here.
The results are shown in these graphs:
What you can see is that value size has some, but a pretty small impact, on read times for values <4 KiB - 64 KiB. Especially compared to the effect of the trie configuration, the impact seems pretty negligible.
For those curious why increasing branch nodes from 32 to 64 doesn't change the timing much, it's because the branch nodes are evenly spaced, each with an extension node afterward in the case of 32 branch nodes, so the total number of nodes traversed is the same.
Hardware: my laptop has an Intel i7-7700HQ CPU and NVMe storage.
So my conclusion is that we should cap value sizes at 4 KiB or 16 KiB and have the cost of
ext_get_storagebe independent of the value size. If anything, this suggests that the gas price is going to likely have to account for the worst-case scenario of 64 trie node lookups. Allowing values greater than 16 KiB is probably a bad idea anyway, as LSM databases like Rocks have relatively poor write performance for large values.*This is not strictly necessary if there was an auxiliary index of keys directly to their trie value nodes or values if <32 bytes, but that's slightly tangential to this issue. Though if we had this index, we could store the value sizes in it as well, which is also a possible solution to this issue.