Stable-baselines: Basic CnnLstm policy not working with PPO on Atari Pong
Bug description
Simply changing the policy from CnnPolicy to CnnLstmPolicy when training PPO2 on Atari Pong makes training fail. Using the standard CnnPolicy the training reaches around max performance in 10M steps.
Code
Here is the code:
import os
import gym
import numpy as np
import matplotlib.pyplot as plt
from stable_baselines.common.policies import CnnLstmPolicy
from stable_baselines import PPO2
from stable_baselines.common.cmd_util import make_atari_env
from stable_baselines.common.evaluation import evaluate_policy
env = make_atari_env('PongNoFrameskip-v4', num_env=1, seed=0, wrapper_kwargs = {"frame_stack": False})
model = PPO2(CnnLstmPolicy, env, nminibatches=1, verbose=1, tensorboard_log="ppo2_atari_comparison")
# Train the agent
time_steps = 10000000
model.learn(total_timesteps=time_steps)
Additional notes
- Please note the result is the same if one both stacks frames or doesn't
- Do you have any hint to address this? On such simple tests it shouldn't be a matter of hyperparameters...
 alexpalms
alexpalms
All 11 comments
On such simple tests it shouldn't be a matter of hyperparameters...
Why not?
 araffin
on 14 May 2020
araffin
on 14 May 2020
:) why shouldn't be the same for the other architectures? Like mlp? Actually also MLP need accurate hyperparameters tuning in general, the more complex the problem, the more careful the process should be.
If it is only a matter of hyperparameters, which I am not sure it is as other issues on LSTM here demonstrate, it means to me the implementation is not robust enough.
Otherwise we should be worried also about seeds for RNG. Isn't it?
alexpalms
on 14 May 2020
why shouldn't be the same for the other architectures? Like mlp? Actually also MLP need accurate hyperparameters tuning in general, the more complex the problem, the more careful the process should be.
If you compare the mlp hyperparameters with the one you used for the lstm, there are major differences:
- the number of environments is not the same (usually a critical hyperparam)
- the batch size is not the same anymore but you did not change the learning rate neither...
which I am not sure it is as other issues on LSTM here demonstrate, it means to me the implementation is not robust enough.
we have some unit test to check that the lstm is actually doing something here: https://github.com/hill-a/stable-baselines/blob/master/tests/test_lstm_policy.py#L42
however, they may be some issues as usually framestacking + mlp is sufficient and faster (and therefore used instead) when some memory is needed.
makes training fail.
how bad is it? is it still random at the end?
araffin
on 14 May 2020
Thank you Antonin for taking the time to answer.
I tried very different things:
- I reduced the learning rate up to one order of magnitude.
- I kept the batch size always equal to 128 cause I was just using a single env (no parallel). Is this (the number of envs, so parallel), in your experience, so important? Is it because of the correlation of samples when using a single env?
And yes, it is really bad, basically 0 improvement, I am uploading a screen of TensorBoard where the standard one is the orange, and the 4 others are all LSTM:
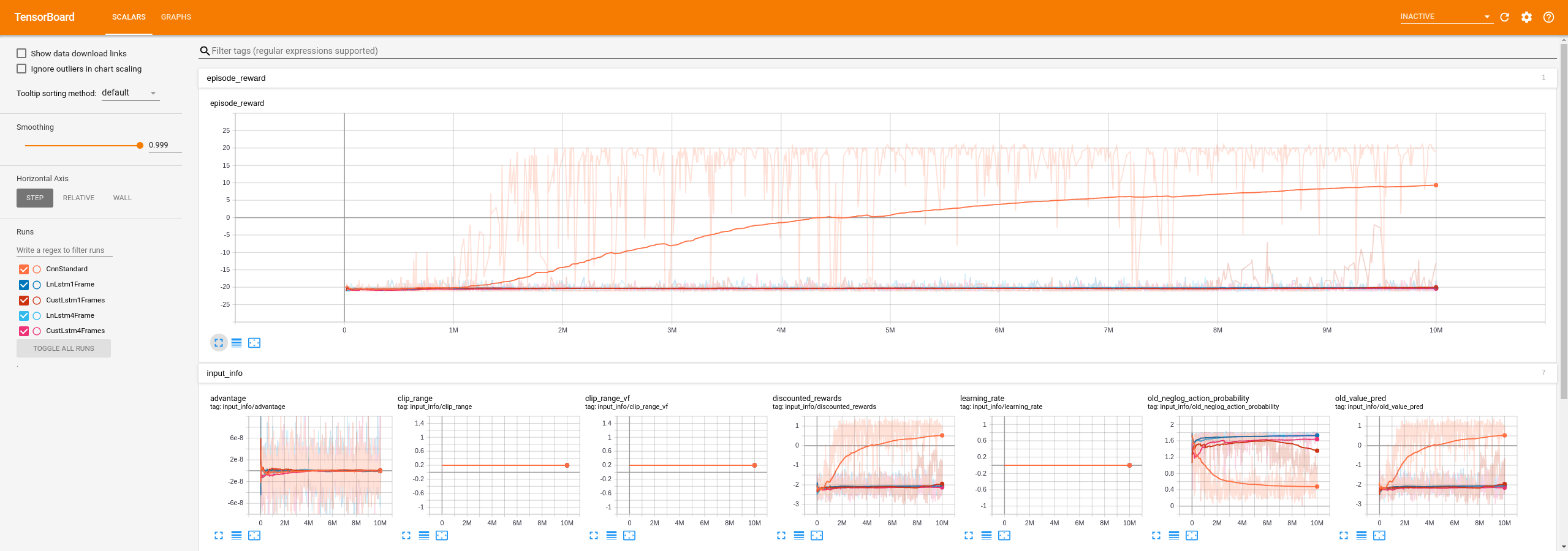
alexpalms
on 14 May 2020
I kept the batch size always equal to 128 cause I was just using a single env (no parallel). Is this (the number of envs, so parallel), in your experience, so important? Is it because of the correlation of samples when using a single env?
From my experience, number of envs is one of the most crucial parameters for PPO/A2C. More is better, and you usually need at least 4-8 parallel instances. This is likely even more important with LSTMs, as you need samples from multiple different trajectories for proper "close-to-the-average" updates.
 Miffyli
on 14 May 2020
Miffyli
on 14 May 2020
I totally get your point @Miffyli , it is just so weird the completely different behavior between a standard CnnPolicy and a CnnLSTM one for a "simple" environment. I mean you see the charts: no learning at all VS almost max performance, all other aspects being equal, included the number of envs (equal to 1)
alexpalms
on 14 May 2020
I'm currently doing a sanity check with the rl zoo in a colab notebook. The following hyperparams seems to work for me:
python train.py --algo ppo2 --env PongNoFrameskip-v4 -params policy:"'CnnLstmPolicy'" n_steps:128 cliprange_vf:-1 --eval-freq -1 --log-interval 100
| ep_reward_mean | -17.6 | after 716800 steps
| ep_reward_mean | -16.7 | after 819200 steps
| ep_reward_mean | -15.5 | 921600 steps
| ep_reward_mean | 0.68 | 1126400 steps
| ep_reward_mean | -10.5 | 1024000 steps
| ep_reward_mean | 11 | 1228800 steps
| ep_reward_mean | 12.8 | 1331200 steps
definitely some learning is happening.
Complete hyperparams:
OrderedDict([('cliprange', 'lin_0.1'),
('cliprange_vf', -1),
('ent_coef', 0.01),
('learning_rate', 'lin_2.5e-4'),
('n_envs', 8),
('n_steps', 128),
('n_timesteps', 10000000.0),
('nminibatches', 4),
('noptepochs', 4),
('policy', 'CnnLstmPolicy'),
('vf_coef', 0.5)])
It is using default atari pre-processing and frame-stacking (I did not take the time to deactivate it).
araffin
on 14 May 2020
Thank you @araffin for taking the time to check this, I will try to reproduce it on my side.
Few questions:
- Why you deactivated the value function clipping? I mean there is a particular reason for that?
- How come you did not change the cliprange parameter but instead of being equal to 0.2 (that is the default) it is ('cliprange', 'lin_0.1')?
alexpalms
on 14 May 2020
Without frame-stacking:
| ep_reward_mean | -19.4 | 512000 steps
| ep_reward_mean | -18.5 | 614400 steps
| ep_reward_mean | -11.1 | 716800 steps
| ep_reward_mean | 2.36 | 819200 steps
| ep_reward_mean | 12.2 | 921600 steps
How come you did not change the cliprange parameter but instead of being equal to 0.2 (that is the default) it is ('cliprange', 'lin_0.1')?
I'm using hyperparams from the zoo (cf doc)
Why you deactivated the value function clipping? I mean there is a particular reason for that?
not really, original ppo does not have such feature. And by experience, it does not help that much.
I guess we can close this issue?
araffin
on 14 May 2020
Yes please go ahead. Could you please just share a link to where I can find hyperparameters for the zoo?
alexpalms
on 14 May 2020
For Atari and PPO specifically, here (obtained with some hyperparameter search, I believe).
Miffyli
on 14 May 2020
Related issues
 JankyOo
·
3Comments
JankyOo
·
3Comments
 maystroh
·
3Comments
maystroh
·
3Comments
 Antalagor
·
3Comments
Antalagor
·
3Comments
 ktattan
·
3Comments
ktattan
·
3Comments
 H2SO4T
·
3Comments
H2SO4T
·
3Comments