Stable-baselines: [Question] Callback for GAIL
Hello!
I am training GAIL on Pendulum-v0. The expert data for Pendulum-v0 is available in expert_path. I am trying to save the model using the Callback documentation as reference. Here’s the code:
import gym
import tensorflow as tf
from stable_baselines import GAIL, SAC, TRPO, PPO2
from stable_baselines.gail import ExpertDataset, generate_expert_traj
from stable_baselines.common.callbacks import CheckpointCallback, EvalCallback
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
if __name__=='__main__':
expert_path = 'stable_baselines/gail/dataset/expert_pendulum.npz'
dataset = ExpertDataset(expert_path=expert_path, traj_limitation=10, verbose=0)
model = GAIL('MlpPolicy', 'Pendulum-v0', dataset, verbose=0)
checkpoint_callback = CheckpointCallback(save_freq=1000, save_path='./logs/', name_prefix='gail')
model.learn(total_timesteps=2000, callback=checkpoint_callback)
Here's the traceback:
Traceback (most recent call last):
File "checking_callback.py", line 18, in <module>
main()
File "checking_callback.py", line 15, in main
model.learn(total_timesteps=2000, callback=checkpoint_callback)
File "C:\IL_UAV\GAIL-TF-SB\stable_baselines\gail\model.py", line 54, in learn
return super().learn(total_timesteps, callback, log_interval, tb_log_name, reset_num_timesteps)
File "C:\IL_UAV\GAIL-TF-SB\stable_baselines\trpo_mpi\trpo_mpi.py", line 455, in learn
ob_expert, ac_expert = self.expert_dataset.get_next_batch()
File "C:\IL_UAV\GAIL-TF-SB\stable_baselines\gail\dataset\dataset.py", line 151, in get_next_batch
if dataloader.process is None:
AttributeError: 'NoneType' object has no attribute 'process'
Some comments and queries:
- The callback runs without errors if GAIL is replaced with an RL algorithm (i.e. removing the
datasetparameter & replacing GAIL with TRPO, SAC, PPO2, etc.) I believe the error has to do with the way CheckpointCallback'ssave_pathparameter works specifically for GAIL. - I ran the same code with EvalCallback. The result is the same, and it turns out the error has to do with
best_model_save_path(remove this parameter and the code runs fine). - Should I be using CustomCallback and
rollouts instead? If yes, could you give me a specific example code? Thanks!
PS: I am new to both Stable Baselines and RL
System Info
- Windows 10
- Python 3.7.0
- Tensorflow 1.14.0
 prabhasak
prabhasak
All 16 comments
Thanks for the detailed issue!
@prabhasak The GAIL in stable-baselines is bit of an oddball and might not be well supported with new features. I suggest you try out other implementations meanwhile, e.g. this one.
@araffin Can you take a look at this? Sounds like GAIL is not well supported with callbacks, but then again I am not sure how much we want to support it.
 Miffyli
on 27 Apr 2020
Miffyli
on 27 Apr 2020
Thank you for the suggestion, @Miffyli! I am relying heavily on Baselines-Zoo for my imitation learning experiments. How wise and straightforward would it be to move to the implementation you recommended? Asking for a research student short on time!
prabhasak
on 27 Apr 2020
Hmm if by "relying on" you mean you are using pre-trained models of rl-zoo, you _could_ export the model parameters into numpy arrays, and then load from there in the other framework (you can read on exporting models here). _If_ the model architectures are same in both frameworks, then this shouldn't be a bigger problem and should be rather straight-forward to do, depending on what the target framework allows (e.g. does it make loading parameters from numpy arrays easy).
Do note that you will likely have different results with different frameworks, even if you match the hyperparameters. It can be very difficult to exactly replicate the results with different pieces of code.
Miffyli
on 27 Apr 2020
Oops, I hesitated mentioning it: I'm only using rl-zoo's train.py script + hyperparameters to generate my own, personalized experts (Step 1 of GAIL). Step 2 is where I face issues with callback.
Essentially, I would have to switch from rl-zoo to CHAI (your suggestion) for generating my experts. Any thoughts on how easy or advantageous CHAI would be over rl-zoo+SB? Apologies for the long convo!
prabhasak
on 27 Apr 2020
I expect other (up-to-date) implementations, and especially that one, to be easier to use for your personal use-case. While the stable-baselines works to an extent, it has not been updated in a while, and it is bit of an odd-ball among other algorithms (and thus receives less attention than the rest).
I will keep this issue open to track the callback issues with GAIL.
Miffyli
on 27 Apr 2020
@prabhasak , another possible avenue is to generate a dataset of expert trajectories using an agent from SB and use that to train an agent using other projects. The first part is fairly trivial using stable-baselines.gail.generate_expert_traj. The expert dataset contains a list of states, actions, rewards, a flag that shows the beginning of an episode and a list of returns for each episode.
 PartiallyTyped
on 27 Apr 2020
PartiallyTyped
on 27 Apr 2020
@PartiallyTyped yes, I am using exactly that. RL-zoo just helps me set hyperparameters and personalize things. Thanks!
prabhasak
on 28 Apr 2020
Hi @araffin, tagging you in case you missed this. Could you please have a look at it? This bug is the only obstacle between me and a ton of interesting results! 😅 (Personally, EvalCallback for GAIL is a higher priority than CheckpointCallback)
prabhasak
on 8 May 2020
I've seen that one but I have no time for now (open sourcing v3 and finishing 2 papers currently...)
 araffin
on 8 May 2020
araffin
on 8 May 2020
I know what is happening...
When saving the model, prepare_pickling() is called and delete the dataloader...
A better solution for you would be to use get_parameters() and save the weights unless you want to save the complete model.
Should be solved by #847
araffin
on 9 May 2020
Thank you! I would like to use EvalCallback to save the best model. But I also need the complete model (oops).
PS: Thank you so much for the quick response, and the commit!
prabhasak
on 10 May 2020
Thank you! I would like to use EvalCallback to save the best model. The complete model (oops).
847 solves both issues as they were related to the same problem (continuing training after saving).
araffin
on 10 May 2020
Hello,
Thank you @araffin! However, it turns out GAIL has its own frequency for saving the model? (multiples of 1024). Looks like CheckPointCallback's save_freq and EvalCallback's eval_freq values are not used at all. Could you please look into this? It would be helpful to save the model at any frequency, like for the RL models. I've attached a sample code to run, and images of evaluating the GAIL model at 1000, 3000 steps, respectively (check eval_num_timesteps in the images).
import gym
import tensorflow as tf
from stable_baselines import GAIL, SAC, TRPO, PPO2
from stable_baselines.gail import ExpertDataset, generate_expert_traj
from stable_baselines.common.callbacks import CheckpointCallback, EvalCallback, CallbackList
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
if __name__=='__main__':
expert_path = 'stable_baselines/gail/dataset/expert_pendulum.npz'
dataset = ExpertDataset(expert_path=expert_path, traj_limitation=10, verbose=1)
model = GAIL('MlpPolicy', 'Pendulum-v0', dataset, verbose=0)
env = gym.make('Pendulum-v0')
checkpoint_callback = CheckpointCallback(save_freq=2000, save_path='./logs/', name_prefix='gail')
eval_callback = EvalCallback(env, eval_freq=2000, best_model_save_path='./logs/',log_path='./logs/', verbose=1)
callback = CallbackList([checkpoint_callback, eval_callback])
model.learn(total_timesteps=10000, callback=callback)
When eval_freq is 1000:
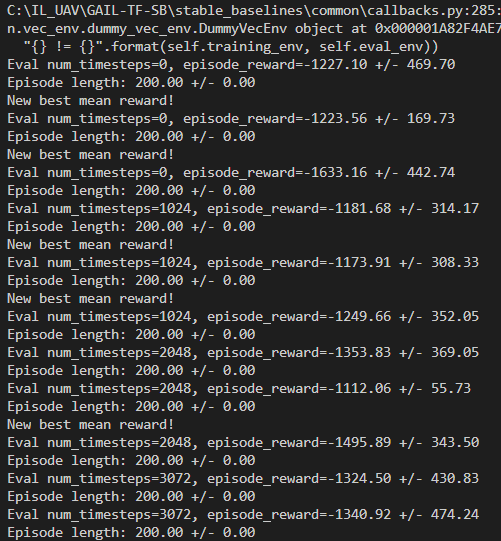
When eval_freq is 3000:

prabhasak
on 15 May 2020
However, it turns out GAIL has its own frequency for saving the model?
GAIL is using TRPO and this fact is mentioned in the doc ;)
"You should know that PPO1 and TRPO update self.num_timesteps after each rollout (and not each step) because they rely on MPI."
araffin
on 15 May 2020
Ahh. Is there any workaround for this? I need to evaluate the GAIL model for my custom env at a particular eval_freq, to check if 'solved' over N consecutive episodes (translates to eval_freq = N x avg_episode_len).
Ex: For CartPole-v1, 'solved' is defined as mean reward of 475 over 100 consecutive episodes (translates to eval_freq = 100 x 500).
Right now, GAIL evaluates model only in multiples of 1024, so I'm guessing the best bet is to find the nearest multiple to my eval_freq? (but the increment in the multiples isn't linear, as you can see in the attached image from before)
prabhasak
on 15 May 2020
Ahh. Is there any workaround for this?
You need to customize SB a bit and pass the callback in https://github.com/hill-a/stable-baselines/blob/c4c31cb5687800cf102054f0935aa09e7545159f/stable_baselines/common/runners.py#L58
We don't do that because this would break the code if users use MPI with more than 1 node.
You can also change timesteps_per_batch but this not recommended if it deteriorates the performance.
araffin
on 17 May 2020
Related issues
 H2SO4T
·
3Comments
H2SO4T
·
3Comments
 Antalagor
·
3Comments
Antalagor
·
3Comments
 junhyeokahn
·
3Comments
junhyeokahn
·
3Comments
 ktattan
·
3Comments
ktattan
·
3Comments
 acyclics
·
3Comments
acyclics
·
3Comments